

PySpark判断Hdfs文件路径是否存在
背景
从ScalaSpark代码转PySpark代码,同时实现连续读多个文件,避免因某些路径不存在导致程序终止。
在Scala的Spark中可以直接导下面两个模块的包
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs._
然后调用方法就可以实现对hdfs的文件判断了
val fs = FileSystem.get(conf)
fs.exists(new Path(pathStr))
但PySpark并不能这么实现(我太菜了)
查略网上方法
(第一种)[https://www.cnblogs.com/midworld/p/15734257.html]
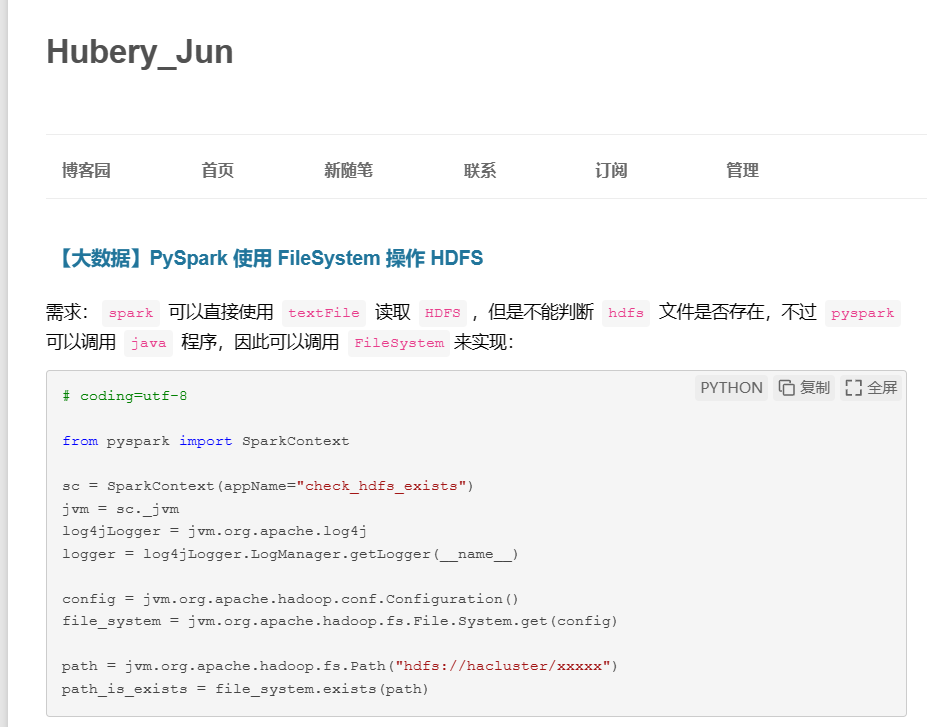
Pass
(第二种)[https://deepinout.com/pyspark/pyspark-questions/113_pyspark_pyspark_how_to_check_if_a_file_exists_in_hdfs.html]

看着还不错,但我的生产环境导不了这个类,可能pySpark是做了更改的,结果就是不行,Pass/(ㄒoㄒ)/~~
总结
在查略了各种方法都没实现后,突然想到了try-catch最基础的办法,然后我看了下Scala版的Spark源代码,发现也有用到try-catch来实现的

随后开启了不常规操作
for path in path_list:
try:
print(path,spark.read.parquet(path).count())
except:
print(path + ":路径不存在")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号