
RDD依赖关系
介绍
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
- 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的 数据分区。
- 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。像上面的代码,就是resultRDD依赖于mapRDD依赖于wordRDD依赖于fileRDD。
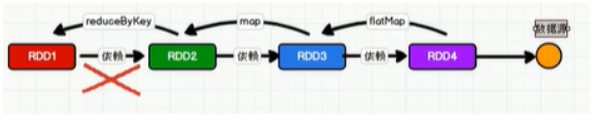
RDD是会不保存数据的,当某一步出现了错误,RDD就会根据血缘关系将数据重新读取进行计算。
展现血缘关系
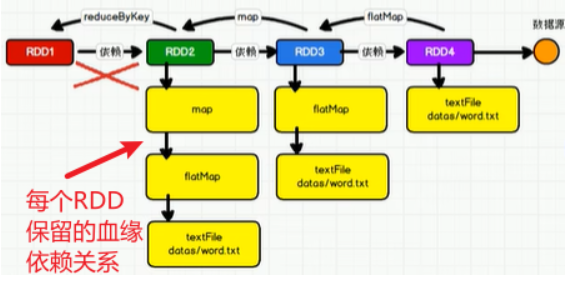
当RDD2到RDD1出现错误时,就会根据血缘关系找到数据源,然后重新计算。
来看看下面具体代码
package com.pzb.rdd.dep
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO
* @author 海绵先生
* @date 2023/4/9-10:52
*/
object Spark01_RDD_Dep {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Dep_Test")
val sc = new SparkContext(conf)
val RDD4: RDD[String] = sc.textFile("./datas/word.txt")
// toDebugString方法是打印RDD的 血缘关系
println(RDD4.toDebugString)
println("*************************")
val RDD3: RDD[String] = RDD4.flatMap(_.split(" "))
println(RDD3.toDebugString)
println("*************************")
val RDD2: RDD[(String, Int)] = RDD3.map((_, 1))
println(RDD2.toDebugString)
println("*************************")
val RDD1: RDD[(String, Int)] = RDD2.reduceByKey(_ + _)
println(RDD1.toDebugString)
println("*************************")
RDD1.collect().foreach(println)
}
}
打印结果
(2) ./datas/word.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dep.scala:16 []
| ./datas/word.txt HadoopRDD[0] at textFile at Spark01_RDD_Dep.scala:16 []
*************************
(2) MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dep.scala:20 []
| ./datas/word.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dep.scala:16 []
| ./datas/word.txt HadoopRDD[0] at textFile at Spark01_RDD_Dep.scala:16 []
*************************
(2) MapPartitionsRDD[3] at map at Spark01_RDD_Dep.scala:23 []
| MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dep.scala:20 []
| ./datas/word.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dep.scala:16 []
| ./datas/word.txt HadoopRDD[0] at textFile at Spark01_RDD_Dep.scala:16 []
*************************
(2) ShuffledRDD[4] at reduceByKey at Spark01_RDD_Dep.scala:26 []
+-(2) MapPartitionsRDD[3] at map at Spark01_RDD_Dep.scala:23 []
| MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dep.scala:20 []
| ./datas/word.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dep.scala:16 []
| ./datas/word.txt HadoopRDD[0] at textFile at Spark01_RDD_Dep.scala:16 []
*************************
(Hello,2)
(Scala,1)
(Spark,1)
- (2)表示的是有两个分区
- 为什么会有个HadoopRDD,因为textFile的底层调用的是Hadoop的textFile方法
- 为什么Shuffled阶段会将血缘关系分开,因为Spark的Shuffle是要落地磁盘的,到时是直接从磁盘中取数
展现依赖关系
package com.pzb.rdd.dep
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO
* @author 海绵先生
* @date 2023/4/9-10:52
*/
object Spark02_RDD_Dep {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Dep_Test")
val sc = new SparkContext(conf)
val RDD4: RDD[String] = sc.textFile("./datas/word.txt")
// dependencies方法是打印RDD的 依赖关系
println(RDD4.dependencies)
println("*************************")
val RDD3: RDD[String] = RDD4.flatMap(_.split(" "))
println(RDD3.dependencies)
println("*************************")
val RDD2: RDD[(String, Int)] = RDD3.map((_, 1))
println(RDD2.dependencies)
println("*************************")
val RDD1: RDD[(String, Int)] = RDD2.reduceByKey(_ + _)
println(RDD1.dependencies)
println("*************************")
RDD1.collect().foreach(println)
}
}
打印结果
List(org.apache.spark.OneToOneDependency@2c0b4c83)
*************************
List(org.apache.spark.OneToOneDependency@62db0521)
*************************
List(org.apache.spark.OneToOneDependency@37d871c2)
*************************
List(org.apache.spark.ShuffleDependency@41eb94bc)
*************************
(Hello,2)
(Scala,1)
(Spark,1)
其中OneToOneDependency被认为窄依赖
ShuffleDependency被认为宽依赖
窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner, val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
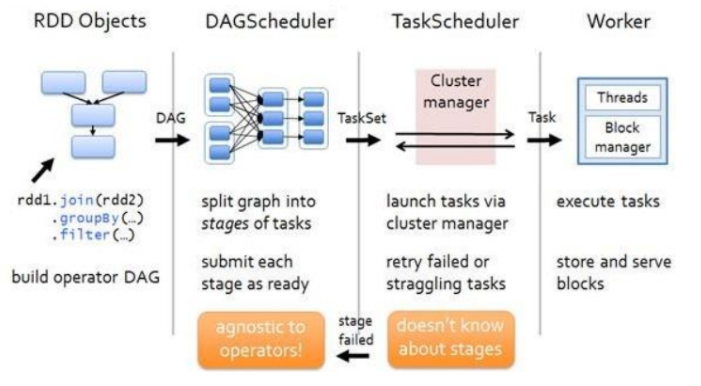
任务阶段
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向, 不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
任务阶段跟Shuffle 阶段有关,任务阶段数 = Shuffle个数 + 1
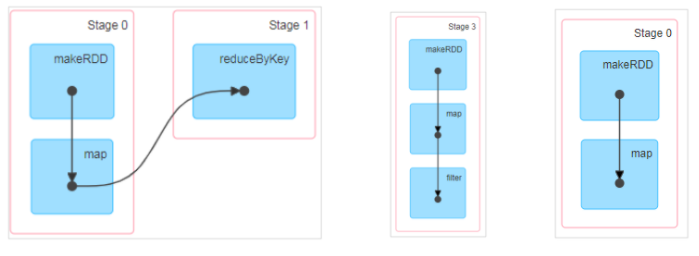
RDD阶段划分源码
???

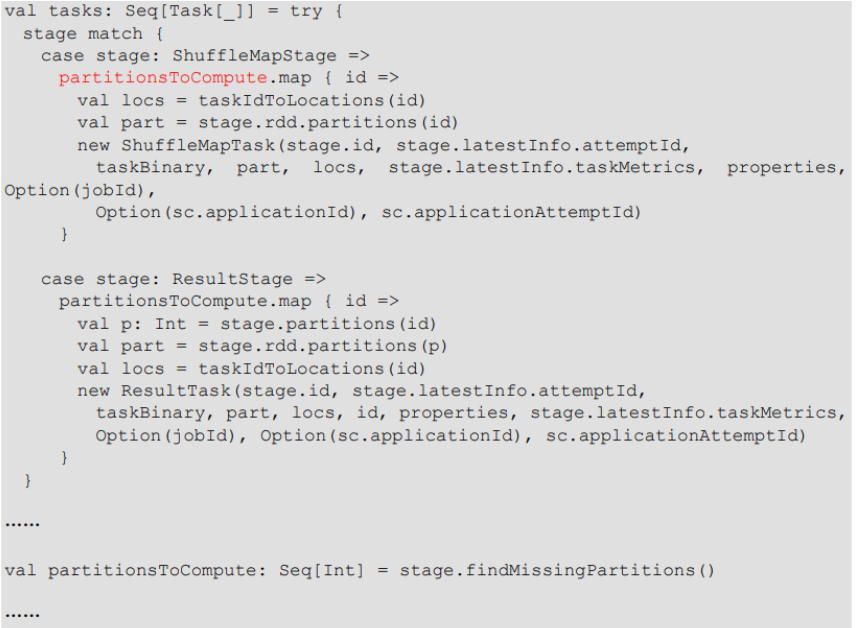
RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Action 算子就会生成一个 Job;
- Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
- Task:一个 Stage 阶段中,最后一个 RDD 的
分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系
RDD 任务划分源码
???


 浙公网安备 33010602011771号
浙公网安备 33010602011771号