
Flink的窗口(Window)操作
Flink高级api
1. Flink四大基石
- Flink之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。

1.1 Checkpoint
这是Flink最重要的一个特性。
Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。
Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而Flink则把这个算法发扬光大了。
Spark最近在实现Continue streaming,Continue streaming的目的是为了降低处理的延时,其也需要提供这种一致性的语义,最终也采用了Chandy-Lamport这个算法,说明Chandy-Lamport算法在业界得到了一定的肯定。
https://zhuanlan.zhihu.com/p/53482103
1.2 State
提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括ValueState、ListState、MapState,BroadcastState。
1.3 Time
除此之外,Flink还实现了水位线(Watermark)的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
水位线是 Flink 流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理
1.4 Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
2. Flink-Window操作
2.1 为什么需要Window
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
2.2 Window的分类



2.2.1 按照time和count分类
time-window:时间窗口:根据时间划分窗口,如:每xx分钟统计最近xx分钟的数据
count-window:数量窗口:根据数量划分窗口,如:每xx个数据统计最近xx个数据

2.2.2 按照slide和size分类
窗口有两个重要的属性: 窗口大小size和滑动间隔slide,根据它们的大小关系可分为:
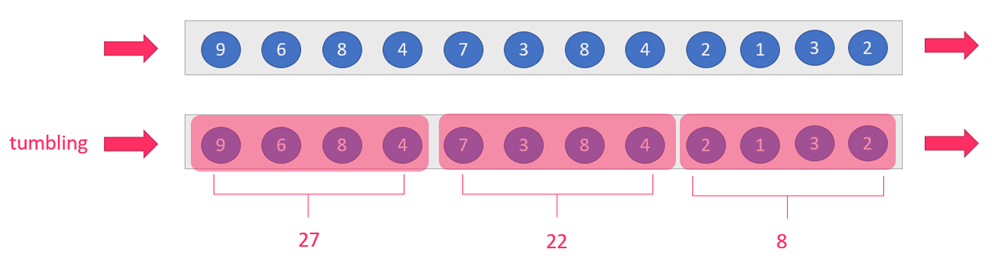
tumbling-window:滚动窗口:size=slide,如:每隔10s统计最近10s的数据
sliding-window:滑动窗口:size>slide,如:每隔5s统计最近10s的数据
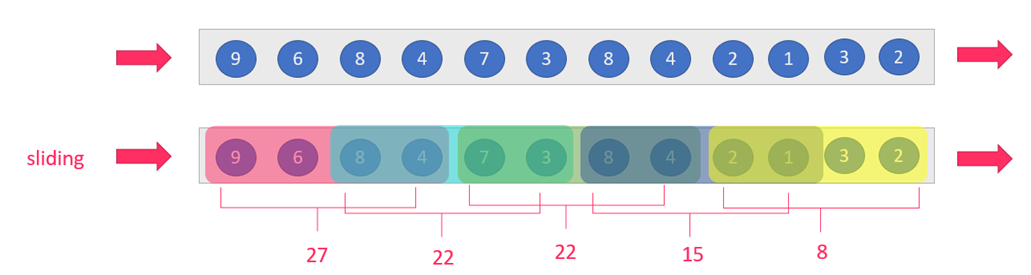
注意:当size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所有开发中不用
2.3 总结
按照上面窗口的分类方式进行组合,可以得出如下的窗口:
1.基于时间的滚动窗口tumbling-time-window--用的较多
2.基于时间的滑动窗口sliding-time-window--用的较多
3.基于数量的滚动窗口tumbling-count-window--用的较少
4.基于数量的滑动窗口sliding-count-window--用的较少
注意:Flink还支持一个特殊的窗口:Session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算
3. Window的API
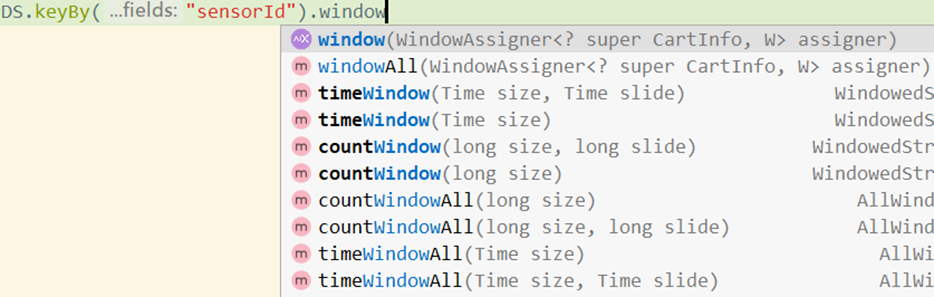
3.1 window和windowAll
- 使用keyby的流,应该使用window方法
- 未使用keyby的流,应该调用windowAll方法

3.2 WindowAssigner
- window/windowAll 方法接收的输入是一个 WindowAssigner, WindowAssigner 负责将每条输入的数据分发到正确的 window 中,Flink提供了很多各种场景用的WindowAssigner:
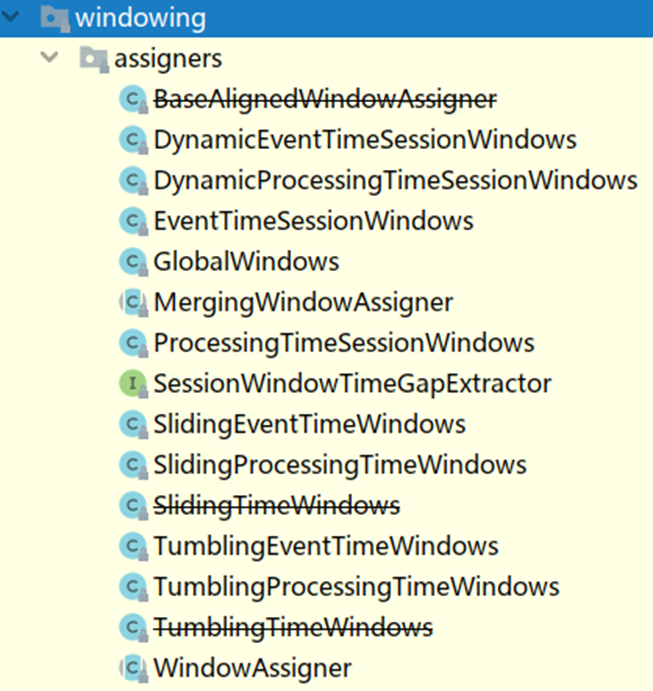
如果需要自己定制数据分发策略,则可以实现一个 class,继承自 WindowAssigner。
3.3 API调用示例
source.keyBy(0).window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
或
source.keyBy(0)..timeWindow(Time.seconds(5))
4. 案例演示-基于时间的滚动和滑动窗口
4.1 需求
nc -lk 9999
有如下数据表示:
信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滚动窗口
需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滑动窗口
4.2 代码实现
package com.gec.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* Desc
* nc -lk 9999
* 有如下数据表示:
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
* 需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滚动窗口
* 需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滑动窗口
*/
public class WindowDemo01_TimeWindow {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
DataStreamSource<String> socketDS = env.socketTextStream("node1", 9999);
//3.Transformation
//将9,3转为CartInfo(9,3)
SingleOutputStreamOperator<CartInfo> cartInfoDS = socketDS.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//分组
//KeyedStream<CartInfo, Tuple> keyedDS = cartInfoDS.keyBy("sensorId");
// * 需求1:每5秒钟统计一次,最近5秒钟内,各个路口/信号灯通过红绿灯汽车的数量--基于时间的滚动窗口
//timeWindow(Time size窗口大小, Time slide滑动间隔)
SingleOutputStreamOperator<CartInfo> result1 = cartInfoDS
.keyBy(CartInfo::getSensorId)//CartInfo::getSensorId是一具lambda表达式的简化写法,相当于c -> c.getSensorId()
//.timeWindow(Time.seconds(5))//当size==slide,可以只写一个,另外,timeWindow已被官方标为弃用
//.timeWindow(Time.seconds(5), Time.seconds(5))
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum("count");
// * 需求2:每5秒钟统计一次,最近10秒钟内,各个路口/信号灯通过红绿灯汽车的数量--基于时间的滑动窗口
SingleOutputStreamOperator<CartInfo> result2 = cartInfoDS
.keyBy(CartInfo::getSensorId)
//.timeWindow(Time.seconds(10), Time.seconds(5))
// 基于处理时间的窗体,如果是给予EventTime,就要加水位线(后面课程)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.sum("count");
//4.Sink
/*
1,5
2,5
3,5
4,5
*/
//result1.print();
result2.print();
//5.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
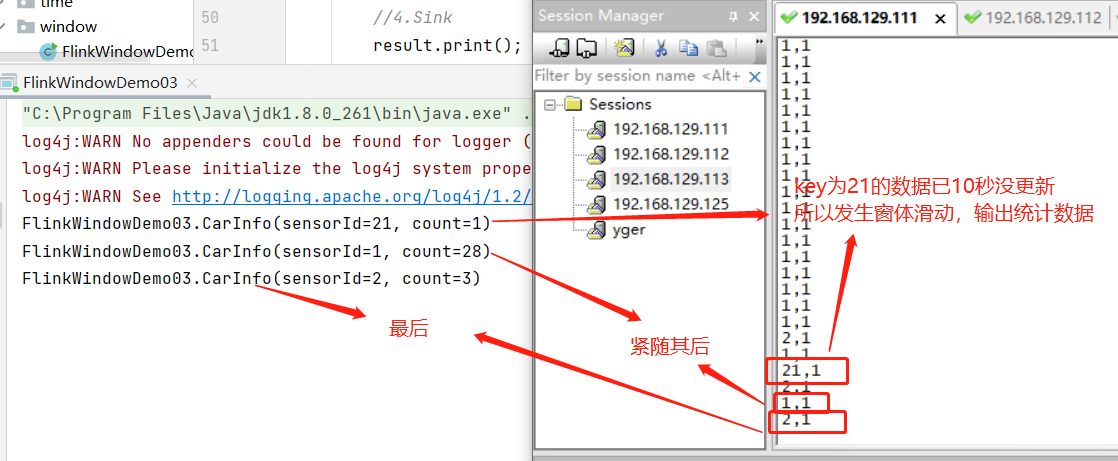
5. 案例演示-基于数量的滚动和滑动窗口
5.1 需求
需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计--基于数量的滑动窗口
5.2 代码实现
package com.gec.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Desc
* nc -lk 9999
* 有如下数据表示:
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
* 需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
* 需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计--基于数量的滑动窗口
*/
public class WindowDemo02_CountWindow {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
DataStreamSource<String> socketDS = env.socketTextStream("node1", 9999);
//3.Transformation
//将9,3转为CartInfo(9,3)
SingleOutputStreamOperator<CartInfo> cartInfoDS = socketDS.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//分组
//KeyedStream<CartInfo, Tuple> keyedDS = cartInfoDS.keyBy("sensorId");
// * 需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
//countWindow(long size, long slide)
SingleOutputStreamOperator<CartInfo> result1 = cartInfoDS
.keyBy(CartInfo::getSensorId)
//size:窗体的长度:5L(相同key的最近5条)
//slide:滑动的条件:3L(近3条相同key数据)
//.countWindow(5L, 5L)
.countWindow( 5L)//不相同的key达到5条数据是不会触发的
.sum("count");
// * 需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计--基于数量的滑动窗口
//countWindow(long size, long slide)
SingleOutputStreamOperator<CartInfo> result2 = cartInfoDS
.keyBy(CartInfo::getSensorId)
//近5条里面有3条相同key值的数据
.countWindow(5L, 3L)
.sum("count");
//4.Sink
//result1.print();
/*
1,1
1,1
1,1
1,1
2,1
1,1
*/
result2.print();
/*
1,1
1,1
2,1
1,1
2,1
3,1
4,1
*/
//5.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
6. 案例演示-会话窗体
6.1 需求
- 设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算
6.2 代码实现
package com.gec.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* Desc
* nc -lk 9999
* 有如下数据表示:
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
* 需求:设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算(前提是上一个窗口得有数据!)
*/
public class WindowDemo03_SessionWindow {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
DataStreamSource<String> socketDS = env.socketTextStream("node1", 9999);
//3.Transformation
//将9,3转为CartInfo(9,3)
SingleOutputStreamOperator<CartInfo> cartInfoDS = socketDS.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//需求:设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算(前提是上一个窗口得有数据!)
SingleOutputStreamOperator<CartInfo> result = cartInfoDS.keyBy(CartInfo::getSensorId)//还是按相同key值来统计的
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.sum("count");
//4.Sink
result.print();
//5.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
7. 窗口函数
简单来说,窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream。具体看下图
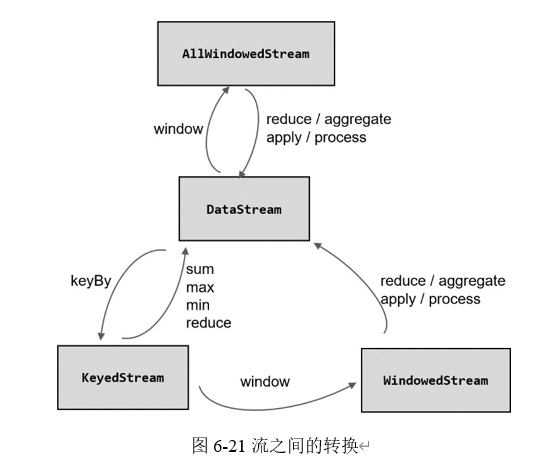
窗口函数可以分为两类
- 增量聚合函数(incremental aggregation functions)
- 全窗口函数(full window functions)
7.1 增量聚合函数
7.1.1 归约函数(ReduceFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
归约函数类似于前面的reduce/sum的作用相似,调的参数都是ReduceFunction接口。
package com.peng.process;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
/**
* @author 海绵先生
* @Description TODO
* @date 2022/11/10-17:15
*/
public class ProcessWindowFunctionDemo01 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// source
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(10))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTimestamp();
}
})
);
// 将数据转换成二元组,方便计算
stream.map(new MapFunction<Event, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
return Tuple2.of(value.getUrl(), 1L);
}
})
//1. 按照url分组,统计窗口内每个url的访问量
.keyBy(data -> data.f0)
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
env.execute();
}
}
7.1.2 聚合函数(AggregateFunction)
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
-
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
-
add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
-
getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态, 然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
-
merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
package com.peng.window;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
import java.util.HashSet;
/**
* @author 海绵先生
* @Description TODO 开窗统计pv和uv,两者相除得到 pv:点击次数 uv:用户访问次数
* @date 2022/11/11-10:22
*/
public class WindowAggregateFunctionDemo02 {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// source
DataStreamSource<Event> dataStreamSource = env.addSource(new ClickSource());
SingleOutputStreamOperator<Event> stream = dataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTimestamp();
}
}));
stream.print();
// 所有数据放在一起统计 把key指定位true,就是把所有数据汇总到一起(实际中要注意数据倾斜的问题)
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new MyAggregateFunction())
.print();
env.execute();
}
public static class MyAggregateFunction implements AggregateFunction<Event, Tuple2<Long, HashSet<String>>, Double>{
@Override
public Tuple2<Long, HashSet<String>> createAccumulator() {
return Tuple2.of(0L, new HashSet<>());
}
@Override
public Tuple2<Long, HashSet<String>> add(Event value, Tuple2<Long, HashSet<String>> accumulator) {
// 每来一条数据,pv个数 + 1, 将user放入HashSet中
accumulator.f1.add(value.getUser());
return Tuple2.of(accumulator.f0 + 1, accumulator.f1);// 返回:每来条数据就加1,不同用户
}
@Override
public Double getResult(Tuple2<Long, HashSet<String>> accumulator) {
return (double)accumulator.f0 / accumulator.f1.size();// 最后返回结果:总数据 / 不同用户人数
}
@Override
public Tuple2<Long, HashSet<String>> merge(Tuple2<Long, HashSet<String>> a, Tuple2<Long, HashSet<String>> b) {
return null;
}
}
}
Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法, 可以直接基于WindowedStream 调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与 KeyedStream 的简单聚合非常相似。它们的底层,其实都是通过AggregateFunction 来实现的。
7.2 全窗口函数
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
在 Flink 中,全窗口函数也有两种:WindowFunction 和 ProcessWindowFunction。
7.2.1 窗口函数
WindowFunction 可以拿到当前窗口相关的信息,它其实是老版本的通用窗口函数接口。我们可以基于WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
// WindowFunction是一个接口,继承 Function, Serializable接口
new WindowFunction<IN, OUT, KEY, W extends Window>{}
//第一个参数:输入数据类型,第二个参数:输出数据类型,第三个参数:KEY值数据类型,第四个参数:窗体时间类型
源码:

7.2.2 处理窗口函数
ProcessWindowFunction不关可以拿到窗口的信息、Key的信息,还能拿到当前的水位线,进行时间的相关操作。
ProcessWindowFunction的实现与WindowFunction不同,调的是.process
方法。
package com.peng.window;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
/**
* @author 海绵先生
* @Description TODO 自定义实现ProcessWindowFunction方法
* @date 2022/11/11-15:56
*/
public class ProcessWindowFunctionDemo01 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// source
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTimestamp();
}
})
);
stream.print("input");
// 使用ProcessWindowFunction计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new MyProcessWindowFunction())
.print();
env.execute();
}
//ProcessWindowFunction是一个抽象类,继承于AbstractRichFunction
public static class MyProcessWindowFunction extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{//第一个参数:输入数据类型,第二个参数:输出数据类型,第三个参数:KEY值数据类型,第四个参数:窗体时间类型
// 窗口结束时调用process方法
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
// 用一个HashSet保存user->作用:去重
HashSet<String> userSet = new HashSet<>();
// elements中遍历数据,放到set中去重
for (Event event : elements) {
userSet.add(event.getUser());
}
int uv = userSet.size();
//结合窗口信息
long start = context.window().getStart();
long end = context.window().getEnd();
out.collect("窗口" + new Timestamp(start) + "~" + new Timestamp(end)
+ "UV值为:" + uv);
}
}
}
ProcessWindowFunction里面有一个process抽象方法,需要自己实现

还有一个抽象类Context,上下文里定义了很多方法,可供自己调用

两种窗口函数结合
单个aggregate虽然高效,但是没有窗口信息,windowfunction虽然有窗口信息,但延迟高,因此flink官方提供了将两者结合的方法

aggregate()方法提供了不同参数的选择
package com.peng.window;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
/**
* @author 海绵先生
* @Description TODO 结合Aggregate和Window两种窗口函数
* @date 2022/11/11-17:06
*/
public class AggregateFunctionDemo01 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// source
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTimestamp();
}
})
);
stream.print("input");
// 使用ProcessWindowFunction计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
//aggregate:将UvAgg()的结果直接传给UvCountResult()
.aggregate(new UvAgg(), new UvCountResult())
.print();
env.execute();
}
// 自定义AggregateFunction,增量聚合计算
public static class UvAgg implements AggregateFunction<Event, HashSet<String>, Long>{
@Override
public HashSet<String> createAccumulator() {
return new HashSet<>();
}
@Override
public HashSet<String> add(Event value, HashSet<String> accumulator) {
accumulator.add(value.getUser());
return accumulator;
}
@Override
public Long getResult(HashSet<String> accumulator) {
return (long)accumulator.size();
}
@Override
public HashSet<String> merge(HashSet<String> a, HashSet<String> b) {
return null;
}
}
// 自定义ProcessWindowFunction,包装窗口信息
public static class UvCountResult extends ProcessWindowFunction<Long, String, Boolean, TimeWindow>{
@Override
public void process(Boolean aBoolean, Context context, Iterable<Long> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
Long uv = elements.iterator().next();// uv就是上一步传过来的值
out.collect("窗口" + new Timestamp(start) + "~" + new Timestamp(end)
+ "UV值为:" + uv);
}
}
}
8. 窗口的其他API
一般对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供了其他一些可选的API,让我们可以更加灵活地控制窗口行为。
8.1 Trigger
基于WindowedStream 调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
Trigger 是窗口算子的内部属性,每个窗口分配器(WindowAssigner)都会对应一个默认的触发器;对于 Flink 内置的窗口类型,它们的触发器都已经做了实现。例如,所有事件时间窗口,默认的触发器都是EventTimeTrigger;类似还有 ProcessingTimeTrigger 和 CountTrigger。所以一般情况下是不需要自定义触发器的。
Trigger 是一个抽象类,自定义时必须实现下面四个抽象方法:
-
onElement():窗口中每到来一个元素,都会调用这个方法。
-
onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
-
onProcessingTime ():当注册的处理时间定时器触发时,将调用这个方法。
-
clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
......还有其他

 浙公网安备 33010602011771号
浙公网安备 33010602011771号