
Sqoop 和 DataX的简单使用方法
Sqoop
通过jdbc连接Mysql查看数据库列表
bin/sqoop list-databases --connect jdbc:mysql://hadoop101:3306/ --username root --password 1234
导入数据
在Sqoop中,“导入”概念指:从关系型数据库(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做导入,即使用 import 关键字。
全数据导入(mysql_to_hdfs)
只要是参数名 + 参数值的格式,所有位置都是可调的。
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student
--target-dir /origin_data/gmall \
--delete-target-dir \
--num-mappers 1 \ # 默认启动的map数为4个
--fields-terminated-by '\t'
参数解读:
- bin/sqoop:表示启动sqoop
- import:表示导入,导出为export
- --connect:连接的数据库
- --username:用户名
- --password:密码
- --table:表名=>你要导哪个表
- --target-dir:目标文件路径,如果没有就会创建=>你要导到哪里,对应hdfs上的路径
- --delete-target-dir:如果存在目标路径,就删除=>Sqoop底层走的是MR,MR在执行数据导入时,是不允许存在目标路径的
- --num-mappers:指定mapper 数
- --fields-terminated-by:指定分隔符
全数据导入只要指定好表就行了,不需要指定字段
查询导入
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--target-dir /origin_data/gmall \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t' \
--query 'select name, age from student where id>2 and $CONDITIONS;'
查询导入对比全数据导入是把--table 参数换成了--query 参数
- --query:写查询SQL的语句,并且最后要包含
where $CONDITIONS条件,否则会报错执行不成功。- 如果query里的SQL语句是“ ” 括起来的,需要改成
where \ $CONDITIONS
- 如果query里的SQL语句是“ ” 括起来的,需要改成
$CONDITIONS参数其实是保证Sqoop 在传递数据时保证数据的有序性,因为实际开发中,传输的数据不止一条,执行的Mapper 程序也不止一个。
导入指定列
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--columns name,age \
--table student \
--target-dir /origin_data/gmall \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
对比上面,又增加了--columns 参数,这样只会导入对应--table 表里的--columns 列的数据。
查询条件导入
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student \
--target-dir /origin_data/gmall \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t' \
--where "id=1"
增加--where 参数,这样只会导入对应--table 表里,并且满足--where 条件的数据。
RDBMS导入Hive
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student \
--num-mappers 1 \
--fields-terminated-by '\t' \
--hive-import \
--hive-overwrite \
--hive-table student_hive
该过程分为两步,第一步将数据导入到HDFS,第二步将导入到HDFS的数据迁移到Hive 仓库。自动创建的hive表是内部表。
参数解读:
-
--hive-import:因为该过程分为两段,所以要添加此参数
-
--hive-overwrite:表示进行数据覆写
-
--hive-table:指定hive表=>默认为default数据库,要想指定其他数据库就数据库名.表名
众所周知:Hive底层是用HDFS 存储的,也可以直接指定Hive 在HDFS上的存储位置,进行mysql_to_hdfs 的操作
RDBMS导入Hbase
确保Hbase已有对应的表属性
bin/sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student \
--columns "id,name,age" \
--column-family "info" \
--hbase-row-key "id" \
--hbase-create-table \
--hbase-table "hbase_student" \
--num-mappers 1 \
--split-by id
Hbase是列存储
导出数据
在Sqoop中导出的概念指的是:从大数据集群(HDFS,HIVE,HBASE)导出到非大数据集群(RDBMS)
bin/sqoop export \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student \
--export-dir /origin_data/gmall \
--num-mappers 1 \
--input-fields-terminated-by '\t'
脚本打包
一般sqoop 脚本已.opt结尾
mkdir opt
vim opt/job_HDFS2RDBMS.opt
- 编写sqoop脚本
export \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 1234 \
--table student \
--export-dir /origin_data/gmall \
--num-mappers 1 \
--input-fields-terminated-by '\t'
- 执行脚本
bin/sqoop --options-file opt/job_HDFS2RDBMS.opt
DataX
DataX是一个异构数据源离线同步工具
DataX与Sqoop需要根据需求选择对应的同步工具
DataX3.0框架设计
DataX采用Framework(主体) + plugin(插件) 架构构建。将数据源读取和写入抽象为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reder和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 安装
下载DataX工具包:
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
运行官方案例(需提取安装python):
# datax的bin目录下执行下面语句
python datax.py /export/servers/datax/job/job.json
DataX工作流程

DataX在执行数据表同步时,会先将整个数据封装成一个Job
Job:单个数据同步的作业,称为一个Job,一个Job启动一个进程。
Task:进行同步时,DataX会启动Split模块对数据进行切分,切分成几块就有多少个Task,对于MySQL的表来说,默认一张表一个Task。Task是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
TaskGroup:Scheduler调度模块会对Task进行分组,每个Task组称为一个TaskGroup。每个TaskGroup负责以一定的并发度运行其所分得得Task,单个TaskGroup得并发度为5(代表一个TaskGroup最多可同时执行5个Task)。
Reduer->Channel->Writer:每个Task启动后,都会固定启动Reader->Channel->Writer的线程来完成同步工作
使用案例
StremReader&StreamWriter
bin/datax.py -r streamreader -w streamwriter
StremReader&StreamWriter是一个空的json模板
输出结果:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2016, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": "" //设置要传输多少条数据
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "", // 编码格式
"print": true // 是否打印输出到控制台
}
}
}
],
"setting": {
"speed": {
"channel": ""// 设置并发度,输出的数据条数 = 并发度 * 设置的传输数据条数
}
}
}
}
根据模板编写配置文件
在job目录下创建stream2stream.json文件
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
"type":"string",
"value":"zhangsan"
},
{
"type":"string",
"value":18
}
],
"sliceRecordCount": "10"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行文件:
python bin/datax.py job/stream2stream.json
print结果:

统计结果:
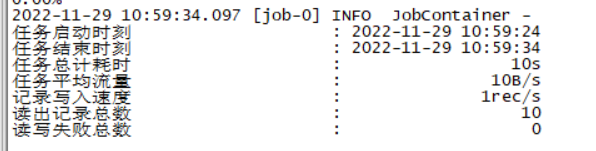
mysql2hdfs
查看官方模板:
bin/datax.py -r mysqlreader -w hdfswriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [], //需要同步的列名集合,使用JSON数组描述自带信息, *代表所有列
"connection": [
{
"jdbcUrl": [], // jdbcUrl:对数据库的JDBC连接信息,使用JSON数组描述,支持多个连接地址
"table": []//需要同步的表,支持多个
【"querySql:[]"】//可选项,自定义SQL获取数据,配置后,mysqllreader直接忽略table、column、where
}
],
"password": "", //数据库用户名对应的密码
"username": "", //数据库用户名
"where": ""//也是可选项,筛选条件
【"splitPk":""】//也是可选项,数据分片字段,一般是主键,仅支持整型。作用:类似flink里的解决数据倾斜方法。
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [], //写入数据的字段,这里的[]不能填写*。其中填写name指定字段名,type指定字段数据类型
"compress": "", //hdfs文件压缩类型,默认不填写意味着没有压缩
"defaultFS": "", //hdfs文件系统namenode节点地址,格式:hdfs://ip:端口号 一般hadoop2.x的默认端口号为8020,3.x的为9820
"fieldDelimiter": "", // 字段分隔符
"fileName": "", // 写入文件名
"fileType": "", // 文件类型,目前只支持用户配置的"text"或"orc"
"path": "", //存储到Hadoop hdfs文件系统的路径信息
"writeMode": ""// hdfs写入前数据清理处理模式。是追加(append)还是清空再写(nonConflict)
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
上面【】内容是自加的,如果要使用,记得去除【】和注意上下文的格式。
关于mysql写入hdfs的注意事项
-
hdfs是只支持单写入,即一个文件只能由一个对象进行写入。
-
如果设置了多并发度,那么被写入的文件后面是会添加.xxx的后缀的。
-
当一个Task写入失败时,hdfs会删除其他Task写入成功的文件,来确保数据一致性。
实战
在job目录下创建mysql2hdfs.json文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop111:3306/datax"
],
"table": [
"student"
]
}
],
"password": "1234",
"username": "root",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://hadoop111:8020",
"fieldDelimiter": "|",
"fileName": "student.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行操作:
[root@hadoop111 datax]# python bin/datax.py job/mysql2hdfs.json
查看结果:
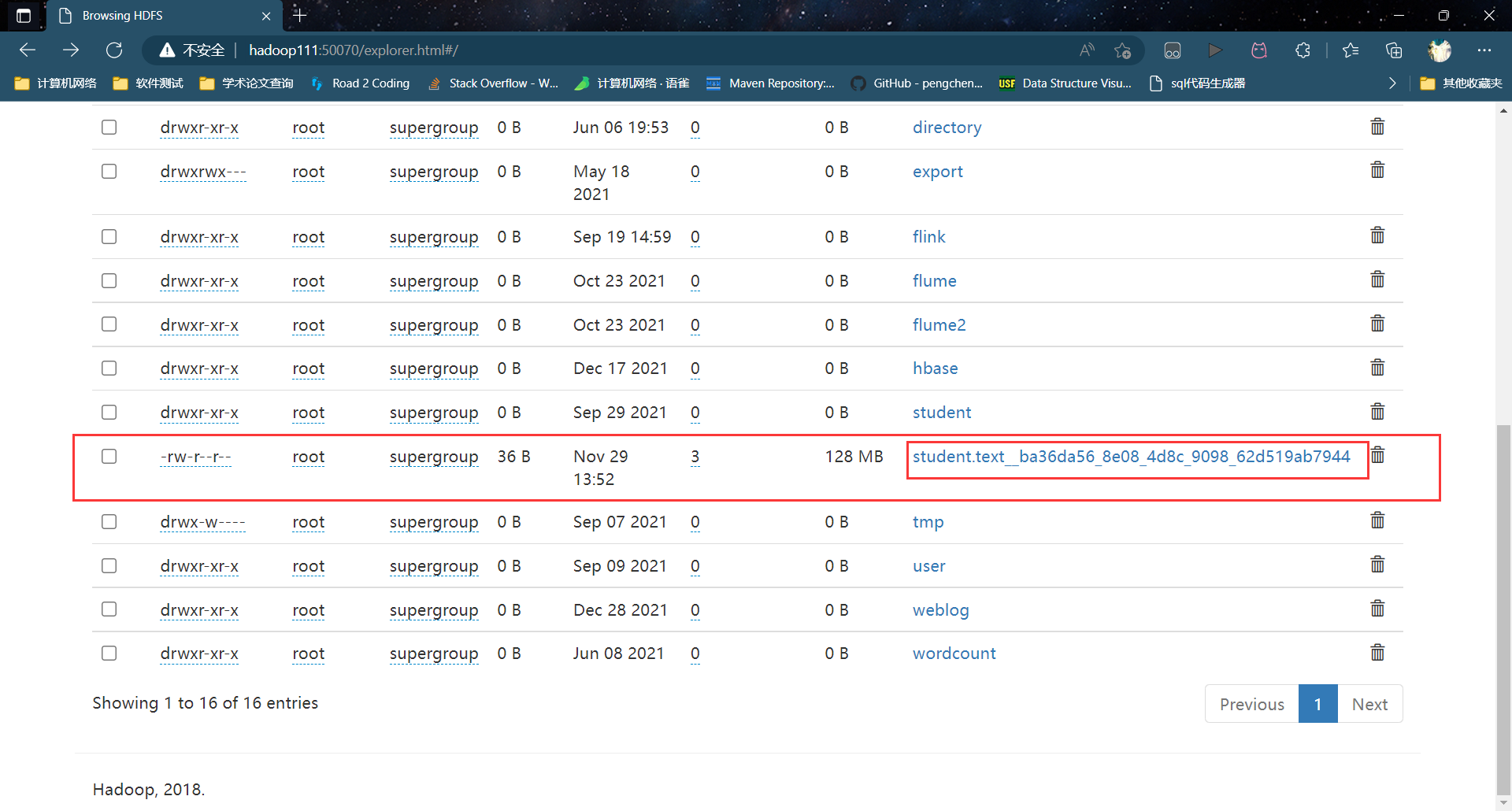
在文件名后自动添加了后缀名
设置hdfs的HA机制
以上面为例,只需在json添加“hadoopConfig”参数即可。ns,nn1,nn2只是代称
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop111:3306/datax"
],
"table": [
"student"
]
}
],
"password": "1234",
"username": "root",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://hadoop111:8020",
"hadoopConfig":{
"dfs.nameservices": "ns",
"dfs.ha.namenodes.ns": "nn1,nn2",
"dfs.namenode.rpc-address.ns.nn1": "主机名:端口",
"dfs.namenode.rpc-address.ns.nn2": "主机名:端口",
"dfs.client.failover.proxy.provider.ns":
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"fieldDelimiter": "|",
"fileName": "student.text",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
hdfs2mysql
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": ["*"],
"defaultFS": "hdfs://hadoop111:8020",
"encoding": "UTF-8",
"fieldDelimiter": "|",
"fileType": "text",
"path": "/student.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop111:3306/datax",
"table": ["student"]
}
],
"password": "1234",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
oracle2mysql
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl":
["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}
],
"password": "000000",
"username": "atguigu"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/oracle",
"table": ["student"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
oracle2hdfs
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl":
["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}
],
"password": "000000",
"username": "atguigu"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "oracle.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mongoDB2hdfs
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "atguigu",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url", "type":"string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "mongo.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mongoDB2mysql
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "atguigu",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test",
"table": ["atguigu"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
sqlServer2hdfs
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "sqlserver.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
sqlServer2mysql
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
DataX使用优化
➢ job.setting.speed.channel : channel 并发数
➢ job.setting.speed.record : 2 全局配置 channel 的 record 限速
➢ job.setting.speed.byte:全局配置 channel 的 byte 限速
➢ core.transport.channel.speed.record:单个 channel 的 record 限速
➢ core.transport.channel.speed.byte:单个 channel 的 byte 限速
总结
DataX起始就是编写响应的json文件,然后运行bin/datax.py + 对应的json文件,完成数据的传输。
有什么不会写的json文件,都可用python bin/datax.py -r ... -w ... 来查看对应文件的编写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号