
CPU性能分析和指标
一、CPU的构成:
1.【lscpu】

2.【vmstst】

buff 缓冲:降低和磁盘交互的频率,比如垃圾桶,满了倒垃圾
cache 缓存:更快的取数据,比如家里的药箱,只有常用的药
二、CPU利用率.【top】{他是一个时间百分比,一般的监控是cpu利用的总和,并不能分析是有效利用还是无效利用,要去服务器上看是不是us和sy高}
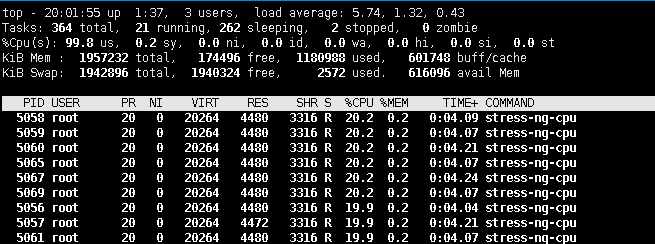
看下面图:PID这一行的%CPU是逻辑和的利用率,双核可以达到200%,4核的话可以到400%
图中的load是平均时间内1分钟5分钟15分钟内的任务数
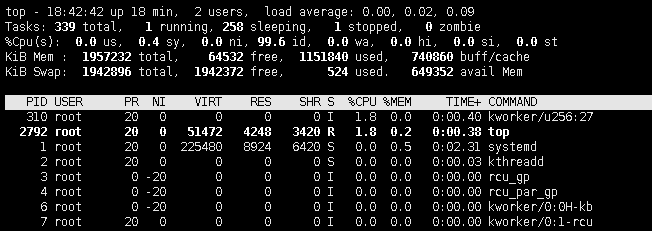
在期间 敲 1
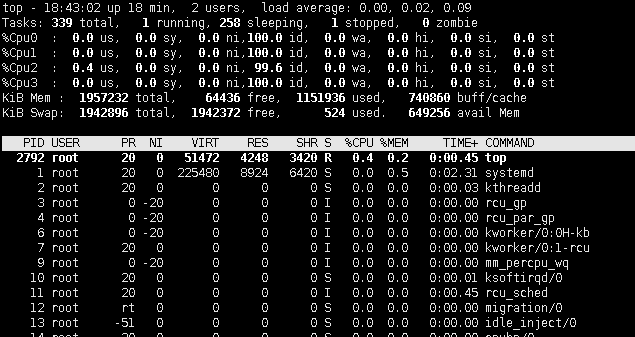
1.cpu(s):物理核 cps逻辑核
2. us:用户空间
sy:系统空间
ni:进程优先级切换(优先级高的进程会抢占cpu,切换多ni就会高)
id:空闲,wa:等待IO读写(磁盘和网络)
wa:IO等待(网络和磁盘,wa过高说明磁盘网络出现异常)
hi:硬中断(硬件引起的,比如磁盘,网络,键盘,hi超出10%说明cpu有很严重的问题)
si:软中断 (cpu陷入到内核空间执行读写数据),他是内核层面的,si很高的话,一定是在做数据读写,可能是死循环,可能在写日志(日志级别低、内核层面的系统调用,此时需要打印内核层面的设备日志)
st:虚拟机,用的不多,不用管
us和sy是有效利用率【us高也可能是代码问题,sync和yield会导致高】
其他都是无效利用率
dmesg | grep sda 硬盘
dmesg | more 内核
dmesg | grep eth 网卡日志
dmesg | head -20 输出前 20 行设备日志
dmesg | tail -20 输出后 20 行日志
dmesg | grep -i memory 查看内存日志
dmesg | grep -i usb 查看 usb 日志
dmesg -c 清空缓冲日志
watch "dmesg | tail -20" 实时监控设备日志
日志中出现关键字 oom kill ddos等就是有问题了,就要分析
比如这个,内存溢出,杀死了进程

这个例子就是写日志,但是没有空间写了,导致si很高
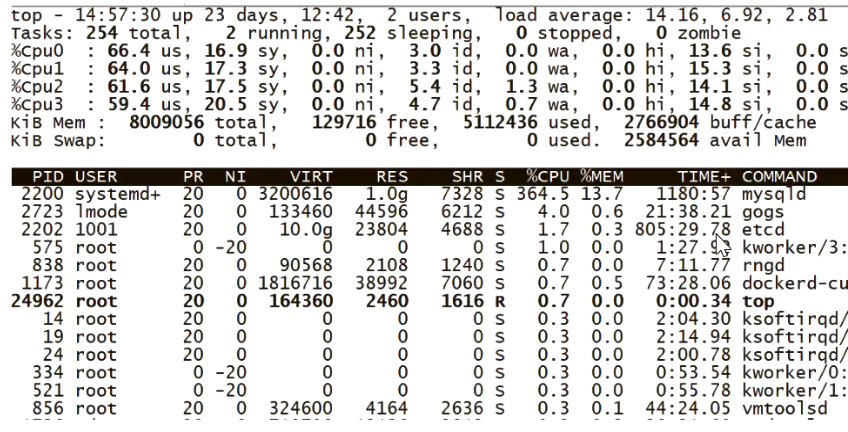
3.【watch -d cat /proc/interrupts】查看硬中断
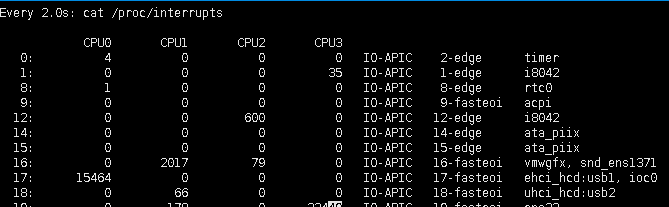
左边的数字是中断号,最右边的是硬件名称,对应绑定的cup
4.【watch -d cat /proc/softirqs】查看软中断
【ethtool -1 eth0】网卡队列
三、进程和线程
1.进程:分配资源
2.线程:任务调度
a.cpu线程【执行调度】
1.cpu的核数表示一次性可以调度的任务数
2.cpu时间片分配
a.2核调度2个任务
b.2核调度20个任务,其中18个任务排队
c.任务越多时间片越少,切换越快,(切换一定伴随cpu中断)导致cpu消耗很高,当时间片用完cpu会切换到下一个任务【被动切换】,下图in是中断,cs是切换
b和c一起就是cpu的上下文切换,计数器【存储任务位置】和寄存器【存储任务数据】
【pidstat -w -p {PID}】查看上下文切换数据

cswch 主动切换 (内存不足,io有问题) nvcswch 被动切换(时间片用完了)
c.load
A.平均时间内,系统同步处理的任务数,对应1分钟5分钟15分钟
B.从左到右,递减【负载在增加】反之【负载正在降低】
C.如果双核load现在是2 目前是满载状态,load大于核数,说明是过载状态,是可以处理的,是在排队处理 【vmstst 1 10】
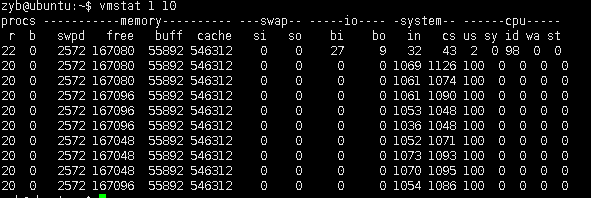
(1) load=r+b
(2) r -->runnable 等待资源 running 等待获取线程锁
(3) b -->black 拿到了线程锁, 处于不可中断的状态
D.举个例子:【stress-ng -c 20 -t 100】 此时查看top
b.应用线程【被调度】:将数据编译成cpu可以识别的内存指令,提交cpu,cpu去调度,cpu的核数越多,同步调度的任务数就越多
1.tomcat
2.nginx
3.mysql
c.特殊任务对cpu的消耗
1.tomcat长连接到期,线程释放
2.nginx 惊群,线程批量启动和休眠
d.系统调用
敲top,处于用户空间,敲下之后需要内核空间申请数据,切换到内核空间,内核空间会给出一个api让用户调用,在切换到用户空间调用api。->一次调用,两次切换
【strace -o strace.log -tt -p {线程号、进程号}】系统调用日志
e.进程优先级
1.NI:优先级系数,范围-20到+19 【在top下面敲 r 回车 进程号 回车 NI的系数 回车】
2.PR:值越高,优先级越低
3.优先级越高,进程获取的cpu时间片越多,可以抢占cpu
打java堆栈脚本 bash show-busy-java-threads 上传到服务器,执行可以看到消耗cpu最高的几个线程打出来
总结几个常见的问题:
1.us高:可能是算法问题,函数sync【刷磁盘】和yield【放弃cpu】可能会导致
2.sy高:a.日志频繁读写,如日志权限不够或者路径不存在(cpu利用率会满),日志级别问题。
b.内核故障,如内存问题和网络问题(打印内存日志【dmesg | more】可以看出)
c.频繁的系统调用 【strace -o strace.log -tt -p {线程号、进程号}】系统调用日志
3.利用率过低
a.压力不够
b.参数配置-连接池
(1)数据库连接数
(2)中间件队列
(3)tcp队列
c.网络阻塞
(1)tcp
(2)socket
(3)本地网管
(4)防火墙
4.内核使用不均衡
进程绑定cpu taskset -pc 0-3 pid 进程绑定逻辑核(进程重启时效)
5.无效利用
ni过高:修改进程优先级
wa过高:磁盘分析,网卡分析(切片多不多,cpu轮询数据包的总量)
6.hi 磁盘、网卡(网卡队列,网卡中断绑定)
7.si 内核中断,参考sy
CPU常用命令
mpstat
mpstat -P {cpu l ALL}
mpstat -I SCPU 1 统计软中断
pidstat -w -p 查看进程上下文切换
sar -u 1 5 采集cpu使用率
sar -q 1 5 采集进程队列和负载状态
ps aux | sort -k3nr |head -n 10 按照按照消耗CPU前10排序的进程
perf top 定位cpu热点
watch "dmesg | tail -20" 实时监控设备日志
taskset -pc 0-3 pid 进程绑定逻辑cpu
echo 1 > /sys/devices/system/cpu/cpu1/online 开启逻辑cpu
strace -o strace.log -tt -p 【pid】打印内核日志
sync【刷磁盘】
yield【放弃cpu】
watch -d cat /proc/softirqs 实时查看软中断
watch -d cat /proc/interrupts 统计进程中断的方式
sysstat
mpstat【cpu】
vmstat【cpu】
iostat【磁盘】
netstat【网络】
pidstat【进程】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号