Hive自定义UDF、UDAF、UDTF函数实例与区别
Hive中有三种自定义函数
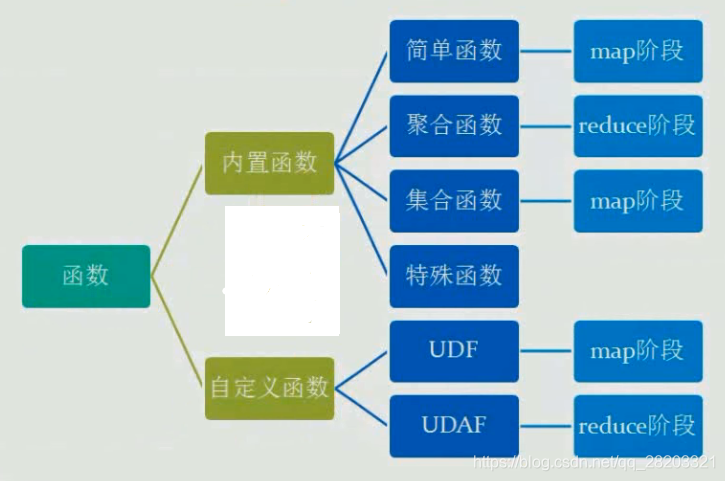
分类
1、用户定义函数(user-defined function)UDF;
2、用户定义聚集函数(user-defined aggregate function,UDAF);
3、用户定义表生成函数(user-defined table-generating function,UDTF)。
介绍
UDF操作作用于单个数据行,并且产生一个数据行作为输出。大多数函数都属于这一类(比如数学函数和字符串函数)。
UDAF 接受多个输入数据行,并产生一个输出数据行。像COUNT和MAX这样的函数就是聚集函数。
UDTF 操作作用于单个数据行,并且产生多个数据行-------一个表作为输出。lateral view explore()
简单来说:
UDF:返回对应值,一对一
UDAF:返回聚类值,多对一
UDTF:返回拆分值,一对多
一、定义UDF具体实现
- 创建一个maven工程
maven工程的创建不多做赘述,网上很多
- 添加pom文件的依赖
添加依赖主要是添加hive-exec这个jar包的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.hopson</groupId>
<artifactId>hive-udf-weekofyear</artifactId>
<version>1.0-SNAPSHOT</version>
<!--添加CDH的仓库-->
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
</repositories>
<properties>
<projcet.build.sourceEncoding>UTF-8</projcet.build.sourceEncoding>
<hadoop.version>3.0.0-cdh6.2.1</hadoop.version>
<hive.version>2.1.1-cdh6.2.1</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
</dependencies>
</project>
- UDF函数编写
UDF函数自定义主要是继承hive-exec中UDF这个类,重写evaluate方法实现UDF自定义。
package org.hopson;
import org.junit.Test;
import org.apache.hadoop.hive.ql.exec.UDF;
public class helloUdf extends UDF {
public String evaluate (String input){
return "Hello:"+input;
}
//本地测试
@Test
public void Test() throws ParseException {
String evaluate = evaluate("2018-12-31");
System.out.println(evaluate);
}
}
4.导入hive 自定义jar包
继承UDF借口
实现evaluate方法
5.临时函数的使用
进入hive的交互shell中
1. 创建存放jar的目录
[hdfs@dp-hadoop-3 jar]# rz
2. 上传自定义udf的jar
hive> add jar /home/hadoop/jar/hive-udf-weekofyear-1.0-SNAPSHOT.jar
3. 创建临时函数
hive> create temporary function sayhelloUDF as 'org.hopson.helloUdf ';
4. 验证
hive> select sayhelloUDF ("Hello World!");
6.永久函数的使用:
1. 创建存放jar的目录
hdfs dfs -mkdir -p /user/hiveUDF;
2. 把自定义函数的jar上传到hdfs中.
hdfs dfs -put hive-udf-weekofyear-1.0-SNAPSHOT.jar ' /user/hiveUDF/';
7. 创建永久函数
hive> create function sayhelloUDF as 'org.hopson.helloUdf' using jar 'hdfs:///path/user/hiveUDF/hive-udf-weekofyear-1.0-SNAPSHOT.jar';
8. 验证
hive> select sayhelloUDF ("Hello World");
hive> show functions;
二、定义UDAF具体实现
1、实现UFAF的步骤
引入如下两下类
import org.apache.hadoop.hive.ql.exec.UDAF
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator
函数类需要继承UDAF类,计算类Evaluator实现UDAFEvaluator接口
Evaluator需要实现UDAFEvaluator的init、iterate、terminatePartial、merge、terminate这几个函数。
a)init函数实现接口UDAFEvaluator的init函数。
b)iterate接收传入的参数,并进行内部的迭代。其返回类型为boolean。
c)terminatePartial无参数,其为iterate函数遍历结束后,返回遍历得到的数据,terminatePartial类似于 hadoop的Combiner。
d)merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean。
e)terminate返回最终的聚集函数结果。
2、实例:
package org.hopson;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class Avg extends UDAF {
public static class AvgState {
private long mCount;
private double mSum;
}
public static class AvgEvaluator implements UDAFEvaluator {
AvgState state;
public AvgEvaluator() {
super();
state = new AvgState();
init();
}
/**
* init函数类似于构造函数,用于UDAF的初始化
*/
public void init() {
state.mSum = 0;
state.mCount = 0;
}
/**
* iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean
* @param
* @return
*/
public boolean iterate(Double o) {
if (o != null) {
state.mSum += o;
state.mCount++;
}
return true;
}
/**
* terminatePartial无参数,其为iterate函数遍历结束后,返回轮转数据, * terminatePartial类似于hadoop的Combiner
* @return
*/
public AvgState terminatePartial() {
// combiner
return state.mCount == 0 ? null : state;
}
/**
* merge接收terminatePartial的返回结果,进行数据merge操作,
* @param
* @return其返回类型为boolean
*/
public boolean merge(AvgState avgState) {
if (avgState != null) {
state.mCount += avgState.mCount;
state.mSum += avgState.mSum;
}
return true;
}
/**
* terminate返回最终的聚集函数结果
* @return
*/
public Double terminate() {
return state.mCount == 0 ? null : Double.valueOf(state.mSum / state.mCount);
}
}
}
3、Hive中使用UDAF
将java文件编译成hive-udaf-avg.jar
进入hive客户端添加jar包
hive>add jar /home/hadoop/hive-udaf-avg.jar
创建临时函数
hive>create temporary function udaf_avg 'org.hopson.Avg'
查询语句
hive>select udaf_avg(people.age) from people
销毁临时函数
hive>drop temporary function udaf_avg
4、总结
通过上面的介绍,可以看到UDAF的用法与UDF的区别了,UDF虽然可以接收多个入参,但是参数个数是固定的(其实也可以不固定,只要evaluate方法的参数类型是变长参数即可,但是一般不这么用),而UDAF的入参是元素个数不固定的集合,这个集合只要可遍历(使用Evaluator的iterate方法遍历)即可,上面的入参是people表的所有age列。
UDF是对只有单条记录的列进行的计算操作,而UDFA则是用户自定义的聚类函数,是基于表的所有记录进行的计算操作。
三、定义UDTF具体实现
UDTF(User-Defined Table-Generating Functions)用来解决输入一行输出多行(one-to-many
maping)的需求。
1.继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF。
2.实现initialize(),process(),close()三个方法。
3.UDTF首先会调用initialize()方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
4.初始化完成后会调用process()方法,对传入的参数进行处理,可以通过forward()方法把结果返回。
5.最后调用close()对需要清理的方法进行清理。
示例:
使用UDTF对"Key:Value"这种字符串进行切分,返回结果为Key,Value两个字段。
package org.hopson;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class UDTFExplode extends GenericUDTF{
@Override
public void close() throws HiveException {
// TODO Auto-generated method stub
}
@Override
public StructObjectInspector initialize(ObjectInspector[] args)
throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
String[] test = input.split(";");
for(int i=0; i<test.length; i++) {
try {
String[] result = test[i].split(":");
forward(result);
} catch (Exception e) {
continue;
}
}
}
}
1.打包发送到服务器。
2.添加到Hive环境中:
hive (hive)> add jar /usr/local/src/hive-udtf-explode.jar
Added /usr/local/src/udtf.jar to class path
Added resource: /usr/local/src/udtf.jar
3.创建临时函数:
hive (hive)> create temporary function explode_map as 'org.hopson.org.hopson';
OK
Time taken: 0.0080 seconds
4.查询(UDTF有两种使用方式,一种是直接放到select后面,另外一种是和lateral view一起使用):
hive (hive)> select explode_map('name:lavimer;age:23') as (col1,col2) from employees;
//MapReduce
OK
col1 col2
name lavimer
age 23
name lavimer
age 23
name lavimer
age 23
注:不可以添加其他字段使用,如下:
select a, explode_map(properties) as (col1,col2) from src
不可以嵌套调用:
select explode_map(explode_map(properties)) from src
不可以和group by/cluster by/distribute by/sort by一起使用:
select explode_map(properties) as (col1,col2) from src group by col1, col2
可以和lateral view一起使用:
hive (hive)> select user.id,employees.col1,employees.col2 from user lateral view explode_map('name:lavimer,age:23') employees as col1,col2;
//MapReduce...
OK
id col1 col2
1 name lavimer
1 age 23
2 name lavimer
2 age 23
3 name lavimer
3 age 23
注:此方法更为方便使用。执行过程相当于单独执行了两次抽取,然后union到一个表里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号