
18_webpack代码分离
什么是代码分离
代码分离(Code Splitting)是webpack一个非常重要的特性
他主要的目的是将代码分离到不同的bundle中,之后我们可以按需加载,或者并行加载这些文件
比如默认情况下,所有的JS代码(业务代码,第三方依赖,展示没有用到的模块)在首页全部都加载
就会影响首页的加载速度
代码分离可以分出更小的bundle,以及控制资源加载优先级,提供代码的加载性能
webpack中常用的代码分离有三种
入口起点:使用entry配置手动代码分离
防止重复:使用Entry Dependencies或者SplitChunksPlugin去重和分离代码
动态导入:通过模块的内联函数调用来分离代码
Entry Dependencies(入口依赖)
入口手动分离代码
entry: { main: "./src/main.js", index: "./src/index.js", }, output: { path: resolveApp("./build"), filename: "[name].bundle.js", },
但是这样子会有缺点
如:我在main.js引入了lodash库,在index.js也引入了lodash这个库,那么webpack在打包后的index.js中有一份lodash,main.js中也有一份lodash,相当于生成了两份lodash
我们不想在打包后的每个引用第三方依赖的js文件中都把第三方的依赖都打包进去,这个时候我们就需要对第三方代码进行一个分离
entry: {
//也可以写成一个数组 main: { import: "./src/main.js", dependOn: "lodash" }, index: { import: "./src/index.js", dependOn: "lodash" }, lodash: "lodash", },
那么这个时候,lodash就会生成一个单独的js文件,webpack会通过模块化加载lodash
假如我在main和index文件又引入了dayjs第三方库的时候,我们还需要对dayjs进行分离,那么改如何设置呢?
我们可以这样设置:
entry: { main: { import: "./src/main.js", dependOn: ["lodash", "dayjs"] }, index: { import: "./src/index.js", dependOn: ["lodash", "dayjs"] }, lodash: "lodash", dayjs: "dayjs", },
也可以这样设置:
entry: { //他们两个依赖的库是一样的话可以添加一个shared属性 main: { import: "./src/main.js", dependOn: "shared" }, index: { import: "./src/index.js", dependOn: "shared" }, shared: ["lodash", "dayjs"], },
当我们build的时候会给我们生成一个LICENSE.txt文件,那么我们如何去掉呢?
const TerserPlugin = require("terser-webpack-plugin");
// 和entry同级
optimization: {
minimizer: [
new TerserPlugin({
extractComments: false,
}),
],
},
Split Chunks
它是使用 SplitChunksPlugin来实现的
因为该插件webpack已经默认安装和集成,所以我们并不需要单独安装,直接使用该插件
只需要提供SplitChunksPlugin相关的配置信息即可
webpack提供了SplitChunksPlugin默认的配置,我们也可以手动来修改它的配置:
比如默认配置中,chunks仅仅针对于异步(async)请求,我们可以设置为initial或者all
如:我们使用import语句导入的dayjs和lodash,他们相当于是同步的,所以该插件并不会对他进行任何的分离,所以我们需要修改其中的chunks值
require()和import()就是异步加载js文件所以该插件会对导入的其js代码进行分离
optimization: { minimizer: [ new TerserPlugin({ extractComments: false, }), ], splitChunks: { // async:require,import函数 // initial:同步导入如:import语句 // all:异步/同步都支持 chunks: "all", }, },
你会发现在我们的build文件夹已经生成了一个叫xxx(数字).bundle.js文件,就已经对代码进行了一个分离
因为我们所有的分离都是使用SplitChunksPlugin来实现的,所以我们需要对它的配置有所了解
splitChunks: { // async:require,import函数 // initial:同步导入如:import语句 // all:异步/同步都支持 chunks: "all", // 最小值:默认值为:20000kb,如果我们拆分出来一个包,那么拆分出来的这个包的大小最小为minSize,如果达不到就不拆分了 // minSize的优先级大于maxSize的优先级 minSize: 2000, // 将大于maxSize的包拆分成不小于minSize的包, maxSize: 2000, // minChunks表示引入的包,至少被引入了一次 minChunks: 1, // 缓存组:b把匹配的文件打包到vendors中 // 把来自node_modules文件夹的代码(第三方库)打包到vendors中 // 当匹配到了lodash不会立即做一个输出,先缓存,等到把所有的匹配都加载完成之后,一起用filename命名的名字一起做一个输出 cacheGroups: { vendors: {
//这里意思是操作系统可能是使用/或者\所以就要使用如下写法 test: /[\\/]node_modules[\\/]/, filename: "[id]_vendors.js", //优先级,如果vendors和default都满足的情况下,它会优先使用default priority: -20, },
//如果bar下的包没有达到minSize是不会分包的,默认minsize=20kb /* bar: { test: /bar/, filename: "[id]_bar.js", }, */ default: { //很少设置 如果有一个文件被多入口引用了两次,会被打包成一个单独的文件,很少使用,因为现在都是spa页面 minChunks: 2, filename: "common_[id].js", //优先级 一般是负数 priority: -10, }, }, },
这些配置我们一般都不需要进行配置的,使用默认的就好了。
动态导入(dynamic import)
另外一个代码拆分是动态导入时,webpack提供了两种实现动态导入的方式
使用ECMAScript中的import()语法来完成,也是目前推荐的方式
使用webpack遗留的require.ensure,目前已经不推荐使用
在vue中同步打包出来的文件最多的就4个
1.main.bundle.js
2.vendors_chunks.js
3.common_chunks.js
4.runtime.js
无论你的splitChunksPlugin设置的是什么,webpack都会对异步导入的代码进行分离
打包过后的文件名字来自于哪里呢?
默认情况下如果你没有告诉他,打包过后的文件叫什么名字,它会根据output.filename来进行命名,但是我这里的filename设置的是 [name].bundle.js ,为什么我的name是一个数字,这个数字来自哪里,它来自optimization的属性中有一个叫chunkIds,他就来自这里
optimization.chunkIds配置
optimization.chunkIds配置用于告知webpack模块的id采用什么算法生成
boolean = false string: 'natural' | 'named' | 'size' | 'total-size' | 'deterministic'再一个如果打包后id没有发生变化浏览器会使用缓存,不会重新下载一次的
output: { path: resolveApp("./build"), filename: "[name].bundle.js", chunkFilename: "[name].chunk.js", },
我们可以使用我们的魔法注释(magic comments)
代码的懒加载
动态import使用最多的一个场景是懒加载(比如路由懒加载)
封装一个component.js,返回一个component对象
我们可以在一个按钮点击时,加载这个对象
当我们点击了的时候会帮我做两件事情
1.下载JS文件
2.浏览器解析执行JS代码
这样子太慢了,只能当我点击了的时候才会去下载代码解析代码进行执行
我想,等浏览器闲下来的时候,帮我们去下载代码,当我点击了按钮的时候,不用去帮我们去下载文件了,直接加载文件并执行
我们可以在import函数中加入另外一个魔法注释(magic comments):webpackPrefetch:true
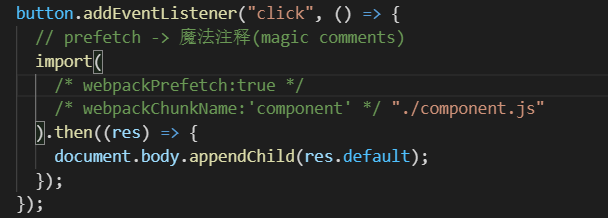

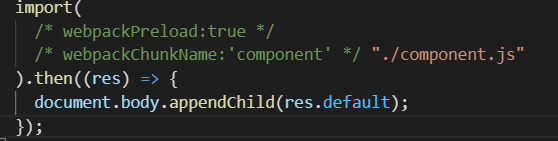
还可以使用另外一个魔法注释:Preload
webpackPreload:true
它在我们控制台是看不见它提前下载的,这是因为这个东西的下载是跟随我们的父脚本一块下载下来的
什么是父脚本:当前的component.js文件源代码是在index.js中导入的,那么在下载index.js的时候会把预加载的component.js一块下载下来,他们是并行的
官方解释
preload chunk 会在父 chunk 加载时,以并行方式开始加载。prefetch chunk 会在父 chunk 加载结束后开始加载。
preload chunk 具有中等优先级,并立即下载。prefetch chunk 在浏览器闲置时下载。
preload chunk 会在父 chunk 中立即请求,用于当下时刻。prefetch chunk 会用于未来的某个时刻。
实际上这样做,Webpack替我们在head内添加了这样一行:
<link rel="prefetch" as="script" href="component.js">
optimization.runtimeChunk配置
配置runtime相关的代码是否抽取到一个单独的chunk中
runtime相关的代码指的是在运行环境中,对模块进行解析、加载模块信息相关的代码
比如我们的component通过import函数相关的代码加载,就是通过runtime代码完成的
由于这个知识点有点不是很好理解,请先看这篇文章:(37条消息) webpack中hash、chunkhash和contenthash三者的区别__Lunay的博客-CSDN博客_contenthash hash
如:我们入口为index.js,index.js文件中又使用import函数引入了component.js
这是我们配置的hash值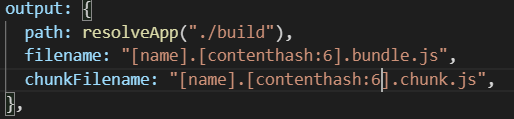
因为是import函数引入的,所以他会单独打包成chunk一个文件,index.js为入口文件也会打包成一个单独的chunk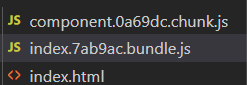
在我们的index.06e.bundle.js文件中的代码,可以看到有一个hash值,刚好对应的就是我们的component的chunkname

因为index.js是主文件,他里面引入了component这个文件的,并且把hash值给保留下来了
当我们如果改动了component的东西,文件内容变了那么component生成的hash也会改变,component的hash改变了,index.js对应的chunk保留的component的chunk的hash也改变了所以,两个文件都发生了改变。
那么我们怎么解决这个问题呢?
我们可以把index.js对应的chunk里面记录的hash值单独提取出来,单独打包,那么index.js对应的chunk就不会记录着component的chunk的hahs值就不会出现这种问题
对应的配置就是我们的runtimeChunk
对应的值:
true/multiple:如果是多入口的时候,它会生成多个runtime来保存对应的hash
single:不管多入口还是单入口,始终只生成一个runtime来保存对应的hash
对象形式:它会帮我们生成一个包
runtimeChunk: { name: `runtime-my`, },
函数形式:它会生成多个包,因为entrypoint是不同的
runtimeChunk: { name(entrypoint) { return `runtime-${entrypoint.name}`; }, },
在实际操作的时候我发现了一个问题,当年你设置了多入口的时候,在设置runtimeChunks为true,或者函数形式,或者multiple的时候会报一些奇奇怪怪的错误,有谁能解答么
