
Kubernetes学习笔记——Kubernetes入门
一、K8s核心概念
- Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8S。
- Kubernetes用于容器化应用程序的部署,扩展和管理,目标是让部署容器化应用简单高效。
k8s(Kubernetes)作为容器编排生态圈中重要一员,是Google大规模容器管理系统borg的开源版本实现,它提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用。当前Kubernetes支持GCE、vShpere、CoreOS、OpenShift、Azure等平台,除此之外,也可以直接运行在物理机上。kubernetes是一个开放的容器调度管理平台,不限定任何一种言语,支持java/C++/go/python等各类应用程序 。
kubernetes是一个完备的分布式系统支持平台,支持多层安全防护、准入机制、多租户应用支撑、透明的服务注册、服务发现、内建负载均衡、强大的故障发现和自我修复机制、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力,完善的管理工具,包括开发、测试、部署、运维监控,一站式的完备的分布式系统开发和支撑平台。
二、K8s集群架构与组件
1、K8s架构图
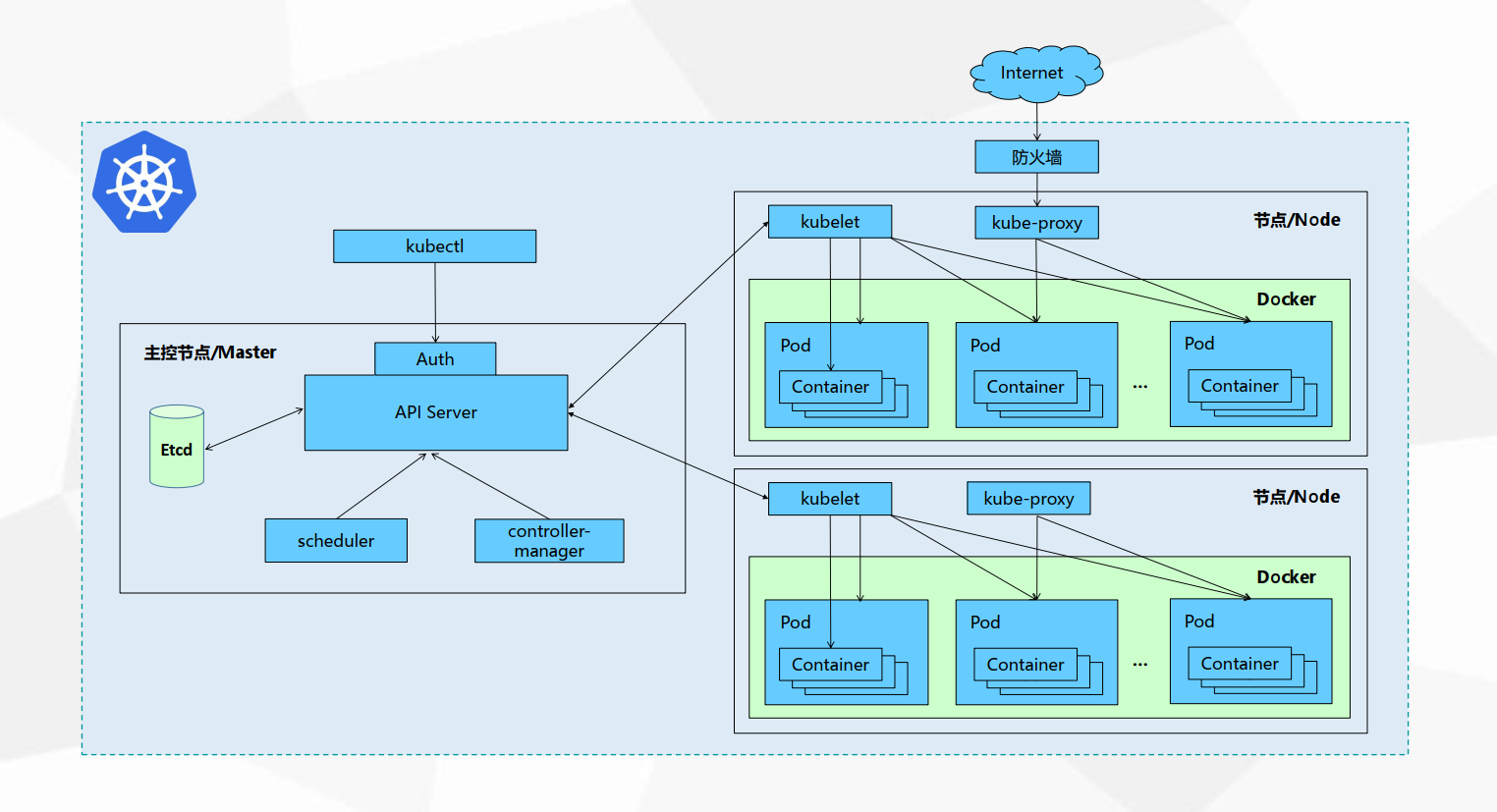

APISERVER:所有服务访问统一入口
ControllerManager:维持副本期望数目
Scheduler::负责介绍任务,选择合适的节点进行分配任务
ETCD:键值对数据库 储存K8S集群所有重要信息(持久化)
Kubelet:直接跟容器引擎(docker)交互实现容器的生命周期管理
Kube-proxy:负责写入规则至 IPTABLES、IPVS 实现服务映射访问的
COREDNS:可以为集群中的SVC创建一个域名IP的对应关系解析
DASHBOARD:给 K8S 集群提供一个 B/S 结构访问体系
INGRESS CONTROLLER:官方只能实现四层代理,INGRESS 可以实现七层代理
FEDERATION:提供一个可以跨集群中心多K8S统一管理功能
PROMETHEUS:提供K8S集群的监控能力
ELK:提供 K8S 集群日志统一分析介入平台2、K8s组件
2.1、Master组件
- **kube-apiserver**
Kubernetes API,集群的统一入口,各组件协调者,以RESTful API提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
- **kube-controller-manager**
处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
- **kube-scheduler**
根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
- **etcd**
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
2.2、Node组件
**kubelet**
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
- **kube-proxy**
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。
- **docker或rocket**
容器引擎,运行容器。
3、K8s基本概念
**Pod**
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享网络命名空间
- Pod是短暂的
**Controllers**
- Deployment : 无状态应用部署
- StatefulSet : 有状态应用部署
- DaemonSet : 确保所有Node运行同一个Pod
- Job : 一次性任务
- Cronjob : 定时任务
控制器是更高级层次对象,用于部署和管理Pod。
**Service**
- 防止Pod失联
- 定义一组Pod的访问策略
**Label **
标签,附加到某个资源上,用于关联对象、查询和筛选
**Namespaces **
命名空间,将对象逻辑上隔离
三、kubectl命令行管理工具
1、kubectl管理命令概要
kubectl --help 查看帮助信息
kubectl create --help 查看create命令帮助信息
| 命令 | 描述 |
| -------------- | ------------------------------------------------------ |
| create | 通过文件名或标准输入创建资源 |
| expose | 将一个资源公开为一个新的Service |
| run | 在集群中运行一个特定的镜像 |
| set | 在对象上设置特定的功能 |
| get | 显示一个或多个资源 |
| explain | 文档参考资料 |
| edit | 使用默认的编辑器编辑一个资源。 |
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源。 |
| rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 |
| scale | 扩容或缩容Pod数量,Deployment、ReplicaSet、RC或Job |
| autoscale | 创建一个自动选择扩容或缩容并设置Pod数量 |
| certificate | 修改证书资源 |
| cluster-info | 显示集群信息 |
| top | 显示资源(CPU/Memory/Storage)使用。需要Heapster运行 |
| cordon | 标记节点不可调度 |
| uncordon | 标记节点可调度 |
| drain | 驱逐节点上的应用,准备下线维护 |
| taint | 修改节点taint标记 |
| describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod中打印一个容器日志。如果Pod只有一个容器,容器名称是可选的 |
| attach | 附加到一个运行的容器 |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个本地端口到一个pod |
| proxy | 运行一个proxy到Kubernetes API server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
| apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同的API版本之间转换配置文件 |
| label | 更新资源上的标签 |
| annotate | 更新资源上的注释 |
| completion | 用于实现kubectl工具自动补全 |
| api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) |
| help | 所有命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |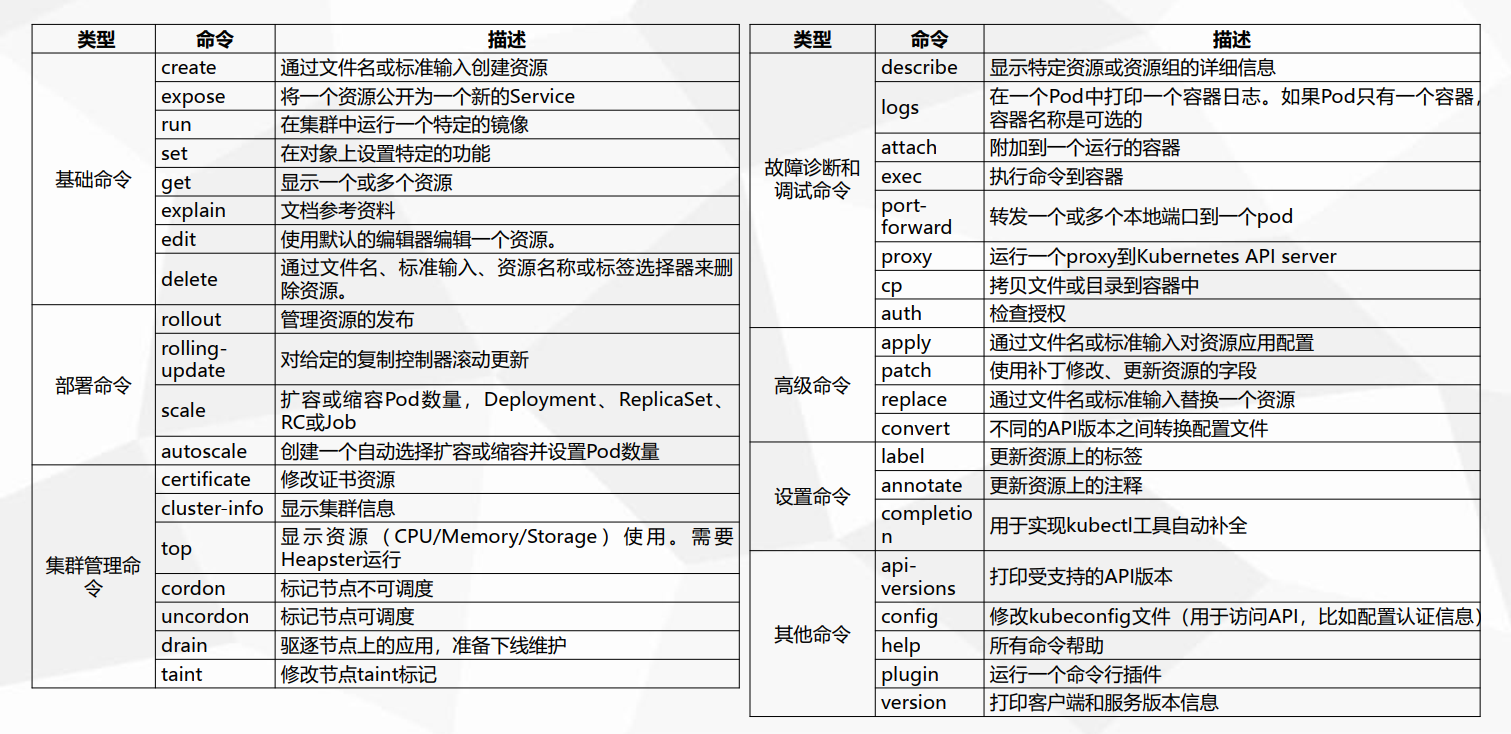
2、kubectl管理应用程序生命周期
1、部署应用
[root@k8s-master1 ~]# kubectl create deployment web --image=nginx:1.14
deployment.apps/web created
[root@k8s-master1 ~]# kubectl get deploy,pods
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web 1/1 1 1 38s
NAME READY STATUS RESTARTS AGE
pod/my-pod 1/2 NotReady 17 95m
pod/web-65b7447c7-t95c5 1/1 Running 0 38s2、暴露应用
[root@k8s-master1 ~]# kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web
service/web exposed
[root@k8s-master1 ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 29d
web NodePort 10.0.0.70 <none> 80:30680/TCP 22s3、应用升级
[root@k8s-master1 ~]# kubectl set image deployment/web nginx=nginx:1.15
deployment.apps/web image updated
#查看升级状态
[root@k8s-master1 ~]# kubectl rollout status deployment/web
deployment "web" successfully rolled out4、应用回滚
#查看发布记录
[root@k8s-master1 ~]# kubectl rollout history deployment/web
deployment.apps/web
REVISION CHANGE-CAUSE
1 <none>
2 <none>
#回滚最新版本
[root@k8s-master1 ~]# kubectl rollout undo deployment/web
deployment.apps/web rolled back
#回滚到指定版本
[root@k8s-master1 ~]# kubectl rollout undo deployment/web --revision=25、扩容/缩容
[root@k8s-master1 ~]# kubectl scale deployment web --replicas=10
deployment.apps/web scaled
[root@k8s-master1 ~]# kubectl get deploy,pods
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web 4/10 10 4 8m29s
NAME READY STATUS RESTARTS AGE
pod/my-pod 1/2 CrashLoopBackOff 18 103m
pod/web-65b7447c7-2kx8w 1/1 Running 0 2m43s
pod/web-65b7447c7-5gtm2 1/1 Running 0 16s
pod/web-65b7447c7-5rc2k 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-9fm4z 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-btj8b 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-k5j7z 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-lxpkj 1/1 Running 0 16s
pod/web-65b7447c7-nt5hm 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-t4sss 0/1 ContainerCreating 0 16s
pod/web-65b7447c7-tn4k4 1/1 Running 0 16s6、删除
[root@k8s-master1 ~]#
[root@k8s-master1 ~]# kubectl delete deploy/web
[root@k8s-master1 ~]# kubectl get deploy,pods
No resources found in default namespace.四、资源编排(YAML)
1、容器编排概念
1、K8S是如何对容器编排?
在K8S集群中,容器并非最小的单位,K8S集群中最小的调度单位是Pod,容器则被封装在Pod之中。由此可知,一个容器或多个容器可以同属于在一个Pod之中。
2、Pod是怎么创建出来的? Pod并不是无缘无故跑出来的,它是一个抽象的逻辑概念,那么Pod是如何创建的呢?Pod是由Pod控制器进行管理控制,其代表性的Pod控制器有Deployment、StatefulSet等。
3、Pod资源组成的应用如何提供外部访问的? Pod组成的应用是通过Service这类抽象资源提供内部和外部访问的,但是service的外部访问需要端口的映射,带来的是端口映射的麻烦和操作的繁琐。为此还有一种提供外部访问的资源叫做Ingress(进口 / 准许进入 / 进入权 / 入境)。
4、Service又是怎么关联到Pod呢? 在上面说的Pod是由Pod控制器进行管理控制,对Pod资源对象的期望状态进行自动管理。而在Pod控制器是通过一个YAML的文件进行定义Pod资源对象的。在该文件中,还会对Pod资源对象进行打标签,用于Pod的辨识,而Servcie就是通过标签选择器,关联至同一标签类型的Pod资源对象。这样就实现了从service-->pod-->container的一个过程。
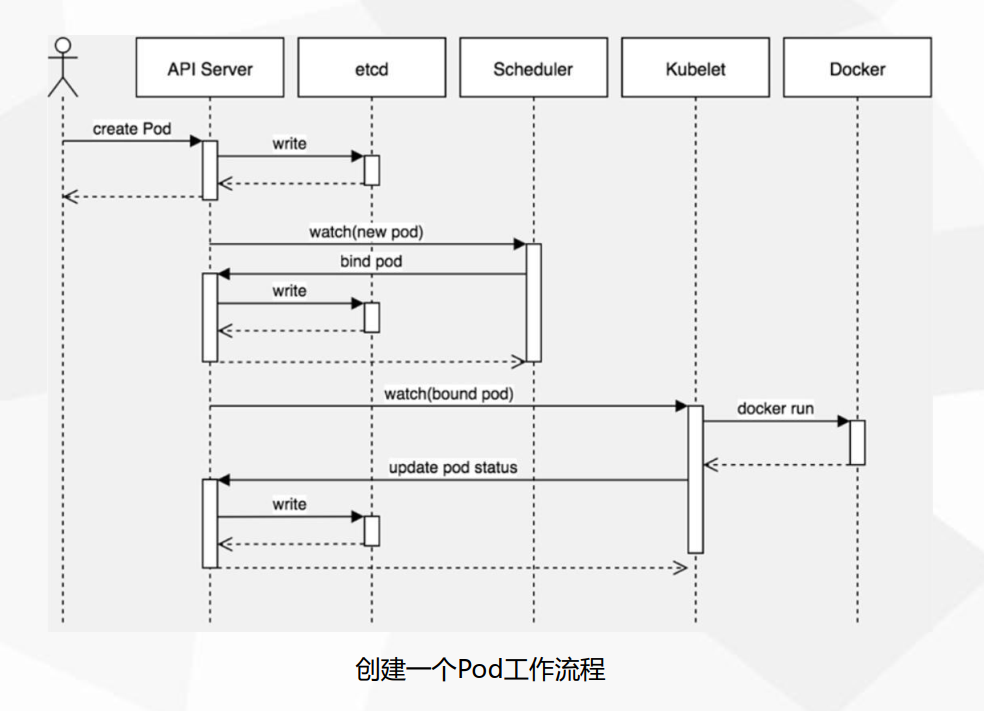
5、Pod的怎么创建逻辑流程是怎样的?
(1)客户端提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
(2)API Server处理用户请求,存储Pod数据到etcd。
(3)调度器通过API Server查看未绑定的Pod。尝试为Pod分配主机。
(4)过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
(5)主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
(6)选择主机:选择打分最高的主机,进行binding操作,结果存储到etcd中。
(7)kubelet根据调度结果执行Pod创建操作: 绑定成功后,scheduler会调用APIServer的API在etcd中创建一个boundpod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步boundpod信息,一旦发现应该在该工作节点上运行的boundpod对象没有更新,则调用Docker API创建并启动pod内的容器。2、YAML文件格式说明
YAML 是一种简洁的非标记语言。
语法格式:
- 缩进表示层级关系
- 不支持制表符“tab”缩进,使用空格缩进
- 通常开头缩进 2 个空格
- 字符后缩进 1 个空格,如冒号、逗号等
- “---” 表示YAML格式,一个文件的开始
- “#”注释3、YAML文件创建资源对象
在K8S部署一个应用的YAML内容大致分为两部分:
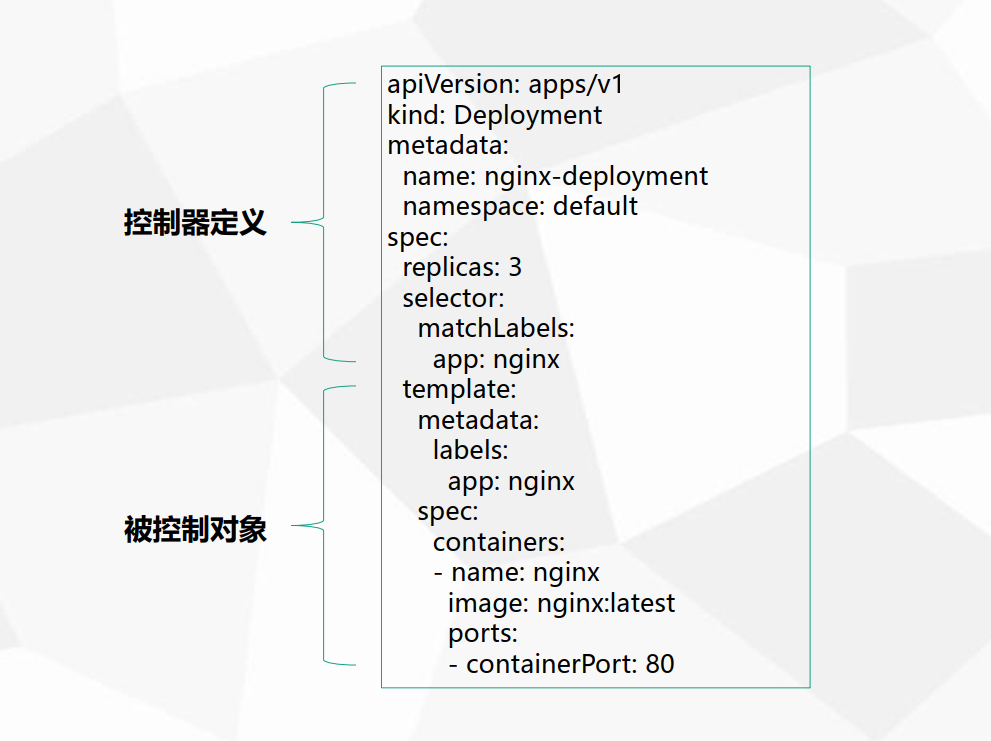
控制器定义:定义控制器属性
被控制对象:Pod模板,定义容器属性

4、YAML文件编写
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,类型Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure] # Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string可以用命令生成YAML,这样比较方便。
使用 kubectl create命令生成yaml文件(未部署的项目):
[root@k8s-master1 ~]# kubectl create deployment nginx --image=nginx:1.14 -o yaml --dry-run> my-deploy.yaml参数解释:
-o yaml 指定我们的yaml文件
--dry-run=client 干跑,并不实际在k8s中执行
> 重定向
my-deploy.yaml yaml文件名yaml文件已经生成,我们可以看一下:
[root@k8s-master1 ~]# cat my-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.14
name: nginx
resources: {}
status: {}使用 kubectl get 命令导出yaml文件(已部署的项目)
kubectl get deploy nginx -o yaml > my-deploy1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2021-05-18T07:53:04Z"
generation: 1
labels:
app: nginx-prod
name: nginx-prod
namespace: default
resourceVersion: "50579"
uid: f67aa9b8-d1b4-4d0d-9d53-8f5ab4eab9b9
spec:
progressDeadlineSeconds: 600
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx-prod
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: nginx-prod
spec:
containers:
- image: nginx:latest
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 3
conditions:
- lastTransitionTime: "2021-05-18T07:54:44Z"
lastUpdateTime: "2021-05-18T07:54:44Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2021-05-18T07:53:04Z"
lastUpdateTime: "2021-05-18T07:54:44Z"
message: ReplicaSet "nginx-prod-665d4d645c" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 3
replicas: 3
updatedReplicas: 3五、深度理解pod对象
1、pod基本概念
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享网络命名空间
- Pod是短暂的2、pod存在的意义
Pod为亲密性应用而存在。
亲密性应用场景:
- 两个应用之间发生文件交互
- 两个应用需要通过127.0.0.1或者socket通信
- 两个应用需要发生频繁的调用3、pod实现机制与设计模式
Pod本身是一个逻辑概念,没有具体存在,那究竟是怎么实现的呢?
众所周知,容器之间是通过Namespace隔离的,Pod要想解决上述应用场景,那么就要让Pod里的容器之间高效共享。
具体分为两个部分:网络和存储
- **共享网络**
kubernetes的解法是这样的:会在每个Pod里先启动一个`infra container`小容器,然后让其他的容器连接进来这个网络命名空间,然后其他容器看到的网络试图就完全一样了,即网络设备、IP地址、Mac地址等,这就是解决网络共享问题。在Pod的IP地址就是infra container的IP地址。
- **共享存储**
比如有两个容器,一个是nginx,另一个是普通的容器,普通容器要想访问nginx里的文件,就需要nginx容器将共享目录通过volume挂载出来,然后让普通容器挂载的这个volume,最后大家看到这个共享目录的内容一样。例如:
[root@k8s-master1 ~]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: write
image: centos
command: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]
volumeMounts:
- name: data
mountPath: /data
- name: read
image: centos
command: ["bash","-c","tail -f /data/hello"]
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}#上述示例中有两个容器,write容器负责提供数据,read消费数据,通过数据卷将写入数据的目录和读取数据的目录都放到了该卷中,这样每个容器都能看到该目录。
验证:
[root@k8s-master1 ~]# kubectl apply -f pod.yaml
pod/my-pod created
[root@k8s-master1 ~]# kubectl logs my-pod -c read -f
8
9
10
11
12
13
14
15
16
17
18
19**在Pod中容器分为以下几个类型:**
- **Infrastructure Container**
基础容器,维护整个Pod网络空间,对用户不可见
- **InitContainers**
初始化容器,先于业务容器开始执行,一般用于业务容器的初始化工作
- **Containers**
业务容器,具体跑应用程序的镜像
4、镜像拉取策略(ImagePullPolicy)
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: lizhenliang/java-demo
imagePullPolicy: IfNotPresent # 镜像拉取策略有三种,Always,IfNotPresent,Never
#镜像拉取策略有三种,Always,IfNotPresent,Never
- IfNotPresent:默认值,镜像在宿主机上不存在时才拉取
- Always:每次创建 Pod 都会重新拉取一次镜像
- Never: Pod 永远不会主动拉取这个镜像#如果拉取公开的镜像,直接按照上述示例即可,但要拉取私有的镜像,是必须认证镜像仓库才可以,即docker login,而在K8S集群中会有多个Node,显然这种方式是很不放方便的!为了解决这个问题,K8s 实现了自动拉取镜像的功能。 以secret方式保存到K8S中,然后传给kubelet。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
imagePullSecrets:
- name: myregistrykey
containers:
- name: java
image: lizhenliang/java-demo
imagePullPolicy: IfNotPresent
#上述中名为 myregistrykey 的secret是由kubectl create secret docker-registry命令创建:
kubectl create secret docker-registry myregistrykey --docker-username=admin --docker-password=Harbor12345 --docker-email=admin@harbor.com --docker-server=192.168.100.54
--docker-server: 指定docke仓库地址
--docker-username: 指定docker仓库账号
--docker-password: 指定docker仓库密码
--docker-email: 指定邮件地址(选填)
5、资源限制
Pod资源配额有两种:
- 申请配额:调度时使用,参考是否有节点满足该配置
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
- 限制配额:容器能使用的最大配置
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
示例:
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: java
image: lizhenliang/java-demo
resources: # 资源配额限制
requests: # 请求资源-下限,如果资源不够,无法启动容器
memory: "64Mi" # 内存限制
cpu: "250m" # CPU限制
limits: # 资源-上限,如果超过容器将停止并重启
memory: "128Mi" # 内存限制
cpu: "500m" # CPU限制
requests 容器请求的资源,k8s会根据这个调度到能容纳的Node
limits 容器最大使用资源
注意:
pod内存超出limits,会被k8s给kill6、重启策略(restartPolicy)
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: lizhenliang/java-demo
restartPolicy: Always
restartPolicy字段有三个可选值:
- Always:当容器终止退出后,总是重启容器,默认策略。
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。适于job
- Never:当容器终止退出,从不重启容器。适于job
------------------------------------------------------------------------------------
always:持久性运行应用,例如nginx、mysql (容器挂了,健康检查失败)
onfaiure、never:短期运行的应用7、健康检查(Probe)
默认情况下,kubelet 根据容器状态作为健康依据,但不能容器中应用程序状态,例如程序假死。这就会导致无法提供服务,丢失流量。因此引入健康检查机制确保容器健康存活。
**健康检查有两种类型:**
- livenessProbe
如果检查失败,将杀死容器,根据Pod的restartPolicy来操作。
- readinessProbe
如果检查失败,Kubernetes会把Pod从service endpoints中剔除。
这两种类型支持三种检查方法:
- httpGet
发送HTTP请求,返回200-400范围状态码为成功。
- exec
执行Shell命令返回状态码是0为成功。
- tcpSocket
发起TCP Socket建立成功。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5上述示例:启动容器第一件事创建文件,停止30s,删除该文件,再停止60s,确保容器还在运行中。
验证现象:容器启动正常,30s后异常,会restartPolicy策略自动重建,容器继续正常,反复现象。
8、调度策略
Pod中影响调度的主要属性
# *****pod的调度****
# 自动调度
# 定向调度 NodeName NodeSlector
# 亲和性调度 NodeAffinity PodAffinity PodAntiAffinity-反亲和力
# 污点(容忍)调度 Taints-污点 Toleration-容忍自动调度
# 不指定调度条件,即为自动调度
# autoselect.yaml
apiVersion: v1
kind: Pod
metadata:
name: autoselcetnode
namespace: dev
spec:
containers:
- name: nginx-auto
image: nginx:1.20.0
imagePullPolicy: IfNotPresent
restartPolicy: Always
# 没有指定任何调度条件,就会自动调度到任一节点根据nodeName定向调度
# 定向调度 nodeName
# 示例9 podtest11.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: devlop
spec:
containers:
- name: nginx36
image: nginx:1.8
nodeName: k8s-node1 # 指定调度到node1根据nodeSelector定向调度
# 定向调度 nodeSelector 需要给node打标签
[root@k8s-master1 yml]# kubectl label node k8s-node2 "web=nginx" # 给节点打标签
node/k8s-node2 labeled
# 示例10 podtest12.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: devlop
spec:
containers:
- name: nginx37
image: nginx:1.8
nodeSelector:
web: nginx # 指定调度到具有web=nginx标签的节点上根据亲和性调度
# 亲和性调度 nodeAffinity【node亲和】 podAffinity【pod亲和】 podAntiAffinity[pod反亲和]
# pod 亲和性[硬限制-软限制-反亲和]
# 亲和性--频繁交互的pod越近越好;反亲和性--分布式多副本部署,高可用性
# 三种亲和性的用法参数基本相同,这里以nodeAffinity为例演示说明
[1] nodeAffinity
[root@k8s-master1 yml]# kubectl explain pod.spec.affinity.nodeAffinity
(1)preferredDuringSchedulingIgnoredDuringExecution <[]Object> # 优先调度到满足指定的规则的node,相当于软限制(倾向)
- weight 倾向权重 ,在范围1-100
preference # 一个节点选择器项,与相应的权重相关联 preference <Object>
matchFields # 按节点字段列出节点选择器要求的列表
matchExpressions # 按标签列出的节点选择器要求的列表--推荐
- key 键
values 值
operator 关系符 支持Exits DoesNoExist In NotIn Gt-大于 Lt-小于
(2)requiredDuringSchedulingIgnoredDuringExecution <Object> # ndoe节点必须满足指定的所有规则才可以,相当于硬限制
nodeSelectorTerms # 节点选择列表 nodeSelectorTerms <[]Object>
matchFields # 按节点字段列出节点选择器要求的列表
matchExpressions # 按标签列出的节点选择器要求的列表--推荐
- key 键
values 值
operator 关系符 支持Exits DoesNoExist In NotIn Gt-大于 Lt-小于
# 示例11 podtest13.yml [01]requiredDuringSchedulingIgnoredDuringExecution【硬限制】
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity
namespace: devlop
spec:
containers:
- name: nginx38
image: nginx:1.8
affinity: # 亲和性设置
nodeAffinity: #设置node亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制,匹配不到则无法调度
nodeSelectorTerms:
- matchExpressions: # 匹配web属性在["xxxx","yyyy"]中的标签
- key: web
operator: In
values: ["nginx","12112"]
# ---------------------------------------------------------------------
# 示例12 podtest14.yml [02]preferredDuringSchedulingIgnoredDuringExecution 【软限制】
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity
namespace: devlop
spec:
containers:
- name: nginx39
image: nginx:1.8
affinity: # 亲和性设置
nodeAffinity: #设置node亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软限制,匹配到则优先调度,没有也可以调度
- weight: 1
preference:
matchExpressions: # 匹配web属性在["xxxx","yyyy"]中的标签-当前环境没有
- key: web
operator: In
values: ["pppp","12112"]污点和容忍
# 污点和容忍
# 污点格式 key=value:effect key和value是污点的标签
# effect支持三个选项
# [1] PreferNoSchedule kubernetes将尽量避免把pod调度到具有该污点的node上,除非没有其他节点可以调度
# [2] NoSchedule kubernetes将不会把pod调度到具有该污点的node上,但不影响已经存在于该节点的pod
# [3] NoExecute-不执行 kubernetes将不会把pod调度到具有该污点的node上,同时会把node节点上已经存在的pod驱离
# 设置污点
# 命令格式 kubectl taint nodes node1 key=value:effect
# 去除污点
# 命令格式 kubectl taint nodes node1 key:effect-
# 去除所有污点
# 命令格式 kubectl taint nodes node1 key-
# 示例13 podtest15.yml
[root@k8s-master1 yml]# kubectl taint nodes k8s-node1 test=pro:PreferNoSchedule # 给节点设置污点
node/k8s-node1 tainted
[root@k8s-master1 yml]# kubectl run taint-nginx35 --image=nginx:1.8 -n devlop
pod/taint-nginx35 created # 容器不会在node1创建,除非没有其他节点可以调度
[root@k8s-master1 yml]# kubectl taint nodes k8s-node1 test=pro:PreferNoSchedule- # 取消污点
node/k8s-node1 untainted # 取消PreferNoSchedule污点
[root@k8s-master1 yml]# kubectl taint nodes k8s-node1 test=pro:NoSchedule
node/k8s-node1 tainted # 设置污点NoSchedule
[root@k8s-master1 yml]# kubectl run taint-nginx38 --image=nginx:1.8 -n devlop
pod/taint-nginx38 created # 不会调度pod到node1上,同时也不会影响node1上已运行的pod
[root@k8s-master1 yml]# kubectl taint nodes k8s-node1 test- # 取消所有污点
node/k8s-node1 untainted # 去掉node1上所有污点
[root@k8s-master1 yml]# kubectl get pods -n devlop -o wide # 查看node3上有运行的pod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx2023-8566f5fd46-x9x4t 1/1 Running 0 26h 10.10.3.5 k8s-node3 <none> <none>
pod-affinity 1/1 Running 0 44m 10.10.1.31 k8s-node1 <none> <none>
taint-nginx35 1/1 Running 0 11m 10.10.3.12 k8s-node3 <none> <none>
taint-nginx38 1/1 Running 0 6m5s 10.10.3.13 k8s-node3 <none> <none>
[root@k8s-master1 yml]# kubectl taint nodes k8s-node3 test=pre:NoExecute # node3增加污点NoExecute
node/k8s-node3 tainted
[root@k8s-master1 yml]# kubectl get pods -n devlop -o wide # node3上的pod被驱离
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx2023-8566f5fd46-tcspl 1/1 Running 0 10s 10.10.2.21 k8s-node2 <none> <none>
pod-affinity 1/1 Running 0 45m 10.10.1.31 k8s-node1 <none> <none>
taint-nginx38 0/1 Terminating 0 7m19s 10.10.3.13 k8s-node3 <none> <none>
[root@k8s-master1 yml]# kubectl run nginx333 --image=nginx:1.8 -n devlop # 新的pod不能被调度到node3
pod/nginx333 created
[root@k8s-master1 yml]# kubectl get pods -n devlop -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx2023-8566f5fd46-tcspl 1/1 Running 0 2m27s 10.10.2.21 k8s-node2 <none> <none>
nginx333 1/1 Running 0 3s 10.10.2.22 k8s-node2 <none> <none>
pod-affinity 1/1 Running 0 48m 10.10.1.31 k8s-node1 <none> <none>
# 容忍 toleration 查询语法 kubectl explain pod.spec.tolerations
# 示例13 podtest15.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: devlop
spec:
containers:
- name: nginx39
image: nginx:1.8
tolerations: # 添加容忍
- key: "test" # 要容忍的污点的key
operator: "Equal" # 操作符
value: "pre" # 要容忍的污点的value
effect: "NoExecute" # 添加要容忍的规则,这里必须和标记的污点规则相同
nodeName: k8s-node3 # 指定调度到ndoe3
---------------------------------------------------------
[root@k8s-master1 yml]# kubectl apply -f podtest15.yml
pod/pod-toleration created
[root@k8s-master1 yml]# kubectl get pods -n devlop -o wide # 设置容忍后可以调度pod到node3上
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx2023-8566f5fd46-tcspl 1/1 Running 0 23m 10.10.2.21 k8s-node2 <none> <none>
nginx333 1/1 Running 0 20m 10.10.2.22 k8s-node2 <none> <none>
pod-affinity 1/1 Running 0 68m 10.10.1.31 k8s-node1 <none> <none>
pod-toleration 1/1 Running 0 3s 10.10.3.14 k8s-node3 <none> <none>六、深入理解常用控制器
1、在Kubernetes部署应用程序流程
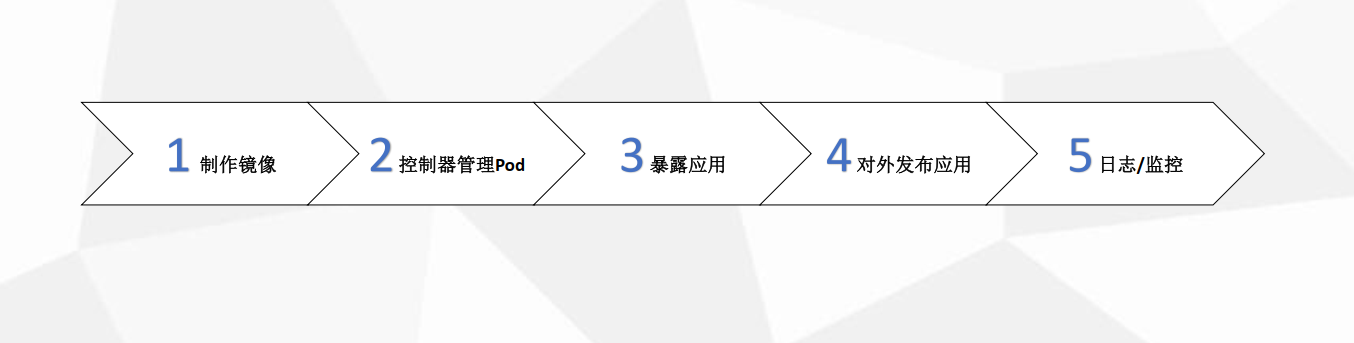
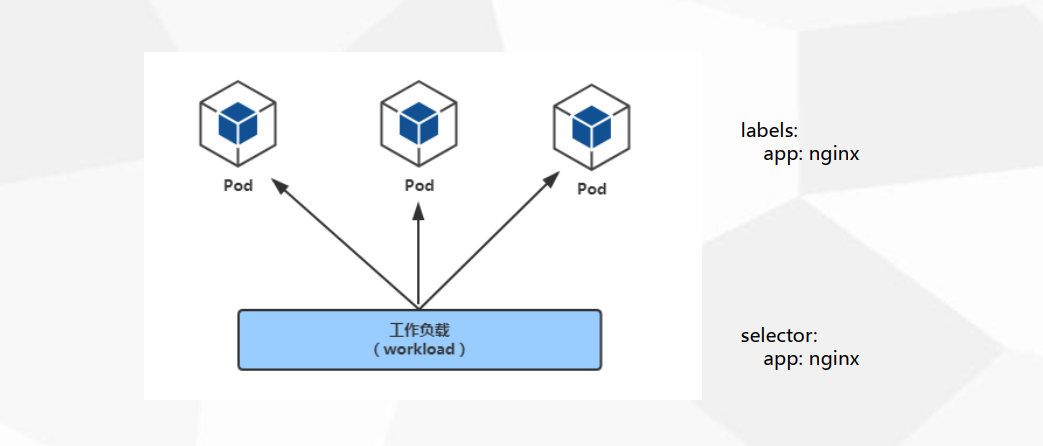
2、Pod与controllers的关系
- controllers:在集群上管理和运行容器的对象。有时也称为工作负载(workload)
- 通过label-selector相关联,如下图所示。
- Pod通过控制器实现应用的运维,如伸缩,滚动升级等
3、Deployment
Deployment功能:
- 部署无状态应用(无状态应用简单来讲,就是Pod可以漂移任意节点,而不用考虑数据和IP变化)
- 管理Pod和ReplicaSet(副本数量管理控制器)
- 具有上线部署、副本设定、滚动升级、回滚等功能
- 提供声明式更新,例如只更新一个新的Image
应用场景:Web服务,微服务
使用YAML部署一个java应用:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3 # 设置3个副本
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: lizhenliang/java-demo
name: java将这个java应用暴露到集群外部访问:
apiVersion: v1
kind: Service
metadata:
labels:
app: web
name: web
spec:
ports:
- port: 80 # 集群内容访问应用端口
protocol: TCP
targetPort: 8080 # 容器镜像端口
nodePort: 30008 # 对外暴露的端口
selector:
app: web
type: NodePort查看资源:
kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/web-7f9c858899-dcqwb 1/1 Running 0 18s
pod/web-7f9c858899-q26bj 1/1 Running 0 18s
pod/web-7f9c858899-wg287 1/1 Running 0 48s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 5m55s
service/web NodePort 10.1.157.27 <none> 80:30008/TCP 48s浏览器输入:http://NodeIP:30008 即可访问到该应用。
升级项目,即更新最新镜像版本,这里换一个nginx镜像为例:
kubectl set image deployment/web nginx=nginx:1.15
kubectl rollout status deployment/web # 查看升级状态
如果该版本发布失败想回滚到上一个版本可以执行:
kubectl rollout undo deployment/web # 回滚最新版本
也可以回滚到指定发布记录:
kubectl rollout history deployment/web # 查看发布记录
kubectl rollout undo deployment/web --revision=2 # 回滚指定版本
扩容/缩容:
kubectl scale deployment nginx-deployment --replicas=5
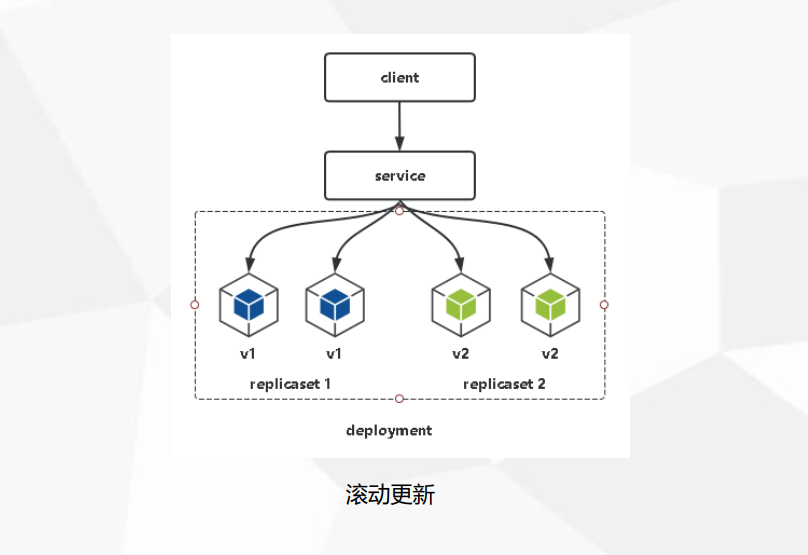
--replicas设置比现在值大就是扩容,反之就是缩容。kubectl set image 会**触发滚动更新**,即分批升级Pod。
滚动更新原理其实很简单,利用新旧两个replicaset,例如副本是3个,首先Scale Up增加新RS副本数量为1,准备就绪后,Scale Down减少旧RS副本数量为2,以此类推,逐渐替代,最终旧RS副本数量为0,新RS副本数量为3,完成本次更新。这个过程可通过kubectl describe deployment web看到。
4、DaemonSet
DaemonSet功能:
- 在每一个Node上运行一个Pod
- 新加入的Node也同样会自动运行一个Pod
应用场景:Agent,例如监控采集工具,日志采集工具
# DaemonSet(DS) # 每个节点都创建pod
示例daemonset.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: pc-daemon
namespace: devlop
spec:
selector:
matchLabels:
app: nginx-daemon
template:
metadata:
labels:
app: nginx-daemon
spec:
containers:
- name: nginx2042
image: nginx:1.8
[root@k8s-master1]# kubectl apply -f daemonset.yml
daemonset.apps/pc-daemon created
[root@k8s-master1]# kubectl get ds pc-daemon -n devlop #获取ds信息
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
pc-daemon 3 3 3 3 3 <none> 24s
[root@k8s-master1]# kubectl get pods -n devlop -o wide # 获取详情,每个节点都有一个daemonpod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pc-daemon-6mjvs 1/1 Running 0 65s 10.10.1.106 k8s-node1 <none> <none>
pc-daemon-8dx65 1/1 Running 0 65s 10.10.2.82 k8s-node2 <none> <none>
pc-daemon-gctdd 1/1 Running 0 65s 10.10.3.77 k8s-node3 <none> <none>
[root@k8s-master1]# kubectl delete -f daemonset.yml # 删除DaemonSet
daemonset.apps "pc-daemon" deleted5、Job
**Job:一次性执行**
应用场景:离线数据处理,视频解码等业务
# Job # 完成单次要处理的任务
# 示例 jobtest.yml
apiVersion: batch/v1
kind: Job
metadata:
name: pc-job
namespace: devlop
spec:
manualSelector: true
completions: 9 # 指定job需要成功运行pods 的次数,默认值为1
parallelism: 3 # 指定job在任一时刻应该并发运行pods的数量,默认值为1
selector:
matchLabels:
app: job-pod
template:
metadata:
labels:
app: job-pod
spec:
restartPolicy: Never
containers:
- name: job-test2022
image: centos:7.9.2009
command: # ["/bin/sh","-c","for i in 10 9 8 7 6 5 4 3 2 1; do echo ${i}; sleep 2; done"]
- "/bin/sh"
- "-c"
- "for i in $(seq 1 10); do echo ${i}; sleep 0.5; done"
[root@k8s-master1 ]# kubectl apply -f jobtest.yml
job.batch/pc-job created
[root@k8s-master1 ]# kubectl get job -n devlop # 执行中
NAME COMPLETIONS DURATION AGE
pc-job 0/1 11s 11s
[root@k8s-master1 ]# kubectl get job -n devlop # 执行完成
NAME COMPLETIONS DURATION AGE
pc-job 1/1 34s 72s
[root@k8s-master1 ]# kubectl get job -n devlop -o wide
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
pc-job 1/1 32s 59s job-test2022 busybox app=job-pod
[root@k8s-master1 ]# kubectl get job -n devlop -o wide -w
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
pc-job 3/9 45s 45s job-test2022 busybox app=job-pod
pc-job 4/9 64s 64s job-test2022 busybox app=job-pod
pc-job 5/9 65s 65s job-test2022 busybox app=job-pod
pc-job 6/9 65s 65s job-test2022 busybox app=job-pod
pc-job 7/9 97s 97s job-test2022 busybox app=job-pod
pc-job 8/9 98s 98s job-test2022 busybox app=job-pod
pc-job 9/9 98s 98s job-test2022 busybox app=job-pod
[root@k8s-master1 ~]# kubectl get pod -n devlop
NAME READY STATUS RESTARTS AGE
nginx-dep-5b98dc9f6-46ggk 1/1 Running 0 117m
nginx-dep-5b98dc9f6-fxjz2 1/1 Running 0 117m
nginx-dep-5b98dc9f6-xzhjb 1/1 Running 0 117m
pc-job-5pn4w 0/1 Completed 0 105s
pc-job-c97wk 0/1 Completed 0 105s
pc-job-ffkj5 0/1 Completed 0 72s
pc-job-rm9dk 0/1 Completed 0 41s
pc-job-snwks 0/1 Completed 0 73s
pc-job-vvwfq 0/1 Completed 0 72s
pc-job-wkgk5 0/1 Completed 0 105s
pc-job-wxnzk 0/1 Completed 0 40s
pc-job-zg75v 0/1 Completed 0 40s
[root@k8s-master1 ]# kubectl delete -f jobtest.yml
job.batch "pc-job" deleted6、CronJob
**CronJob:定时任务,像Linux的Crontab一样。**
应用场景:通知,备份
# CronJob(CJ)
# 示例 cronjob.yml
apiVersion: batch/v1
kind: CronJob
metadata:
name: pc-cronjob
namespace: devlop
labels:
controller: cronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
metadata:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: cronjob2043
image: centos:7.9.2009
command: # ["/bin/sh","-c","for i in 5 4 3 2 1;do echo ${i};sleep 3;done"]
- "/bin/sh"
- "-c"
- "for i in `seq 1 10`;do echo ${i};sleep 1;done"
[root@k8s-master1 ]# kubectl apply -f cronjob.yml
cronjob.batch/pc-cronjob created
[root@k8s-master1 ]# kubectl get pods -n devlop -w
NAME READY STATUS RESTARTS AGE
nginx-dep-5b98dc9f6-46ggk 1/1 Running 0 135m
nginx-dep-5b98dc9f6-fxjz2 1/1 Running 0 135m
nginx-dep-5b98dc9f6-xzhjb 1/1 Running 0 135m
pc-cronjob-1611310680-jzkjp 0/1 Completed 0 75s
pc-cronjob-1611310740-6p6xk 1/1 Running 0 14s
pc-cronjob-1611310740-6p6xk 0/1 Completed 0 17s
[root@k8s-master1 ~]# kubectl get job -n devlop -w # 每分钟执行一次任务
NAME COMPLETIONS DURATION AGE
pc-cronjob-1611310680 0/1 0s
pc-cronjob-1611310680 0/1 0s 0s
pc-cronjob-1611310680 1/1 19s 19s
pc-cronjob-1611310740 0/1 0s
pc-cronjob-1611310740 0/1 0s 0s
pc-cronjob-1611310740 1/1 17s 17s
[root@k8s-master1 ]# kubectl delete -f cronjob.yml
cronjob.batch "pc-cronjob" deleted

 浙公网安备 33010602011771号
浙公网安备 33010602011771号