


python2.7 爬取简书30日热门专题文章之简单分析_20170207
昨天在简书上写了用Scrapy抓取简书30日热门文章,对scrapy是刚接触,跨页面抓取以及在pipelines里调用settings,连接mysql等还不是很熟悉,今天依旧以单独的py文件区去抓取数据。同时简书上排版不是很熟悉,markdown今天刚下载还没来得及调试,以后会同步更新
简书文章:http://www.jianshu.com/p/eadfdb4b5a9d
一、下面是将爬取到的数据写到Mysql数据库代码:
插入数据库titletime字段需要将字符型转化为datetime型 用time模块显得冗长 下一步用datetime改进
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
from lxml import etree
import MySQLdb
import time
import datetime
def insertinto_MySQL():
try:
conn=MySQLdb.connect(host='localhost',user='root',passwd='你的密码',db='local_db',port=3306,charset='utf8')
with conn:
cursor=conn.cursor()
for i in range(0, 6):
url = 'http://www.jianshu.com/trending/monthly?page=%s' % str(i)
html = requests.get(url).content
selector = etree.HTML(html)
infos = selector.xpath("//ul[@class='note-list']/li")
for info in infos:
author = info.xpath('div/div[1]/div/a/text()')[0]
title = info.xpath('div/a/text()')[0]
titleurl = 'http://www.jianshu.com' + str(info.xpath('div/a/@href')[0])
strtime = info.xpath('div/div[1]/div/span/@data-shared-at')[0].replace('+08:00', '').replace('T'," ")
timea = time.strptime(strtime, "%Y-%m-%d %H:%M:%S")
timeb = time.mktime(timea)
timec = time.localtime(timeb)
titletime = time.strftime('%Y-%m-%d %H:%M:%S', timec)
reader = int(str(info.xpath('div/div[2]/a[1]/text()')[1]).strip())
comment_num = int(str(info.xpath('div/div[2]/a[2]/text()')[1]).strip())
likes = int(info.xpath('div/div[2]/span/text()')[0])
rewards = int(str(info.xpath('div/div[2]/span[2]/text()')[0])) if len(info.xpath('div/div[2]/span[2]/text()')) != 0 else 0
cursor.execute("INSERT INTO monthly values(%s,%s,%s,%s,%s,%s,%s,%s)",(author,title,titleurl,titletime,reader,comment_num,likes,rewards))
conn.commit()
except MySQLdb.Error:
print u"连接失败!"
if __name__ == '__main__':
insertinto_MySQL()
二、写python代码前预先在本地mysql数据库建表
CREATE TABLE monthly( author VARCHAR(255), title VARCHAR(255), titleurl VARCHAR(255), titletime DATETIME, reader INT(19), comment_num INT(19), likes INT(19), rewards INT(19) )ENGINE=INNODB DEFAULT CHARSET=utf8;
三、查看数据库,爬取了30日热门 通过查看异步加载请求的url一共加载了6页 119篇文章
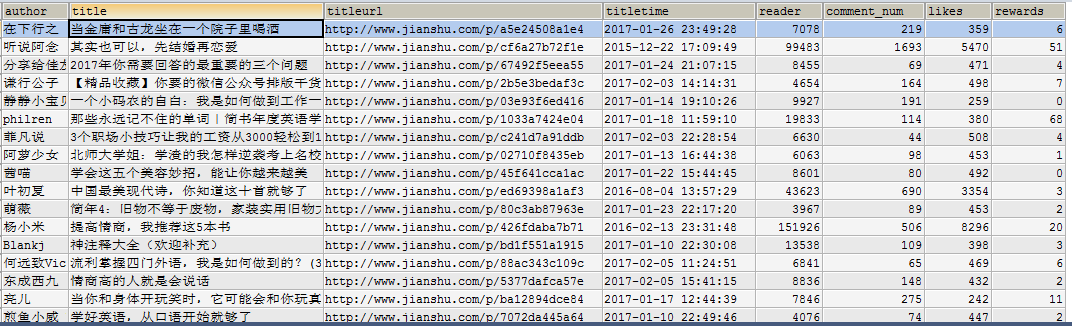
四、时间关系简单分析,先看下汇总情况,按照时间以今天所在日期30天前和30天后为两部分,因此sql采用了纵向连接union all,和热门30天似乎能响应,最早的一票是简叔的,2015年的,浏览量超过了60万,
通过观察数据表数据结构,写sql看下总体情况
( SELECT a.收录专题,a.时间区间,c.天数,b.作者数,a.文章数,a.累计PV浏览量,a.累计评论数,a.累计喜欢数,a.累计打赏数 FROM ( SELECT '30日热门' AS 收录专题,'30天前' AS 时间区间,COUNT(*) AS 文章数,SUM(reader) AS 累计PV浏览量,SUM(comment_num) AS 累计评论数,SUM(likes) AS 累计喜欢数,SUM(rewards) AS 累计打赏数 FROM monthly WHERE titletime<DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS a LEFT JOIN ( SELECT 时间区间,COUNT(作者) AS 作者数 FROM ( SELECT 时间区间,author AS 作者 FROM ( SELECT *,'30天前' AS 时间区间 FROM monthly WHERE titletime<DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS b0 GROUP BY author ) AS b1 ) AS b ON a.时间区间=b.时间区间 LEFT JOIN ( SELECT 时间区间,COUNT(发表日期) AS 天数 FROM ( SELECT 时间区间,发表日期 FROM ( SELECT *,'30天前' AS 时间区间,DATE(titletime) AS 发表日期 FROM monthly WHERE titletime<DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS b0 GROUP BY 发表日期 ) AS b1 ) AS c ON a.时间区间=b.时间区间 ) UNION ALL ( SELECT a.收录专题,a.时间区间,c.天数,b.作者数,a.文章数,a.累计PV浏览量,a.累计评论数,a.累计喜欢数,a.累计打赏数 FROM ( SELECT '30日热门' AS 收录专题,'近30天' AS 时间区间,COUNT(*) AS 文章数,SUM(reader) AS 累计PV浏览量,SUM(comment_num) AS 累计评论数,SUM(likes) AS 累计喜欢数,SUM(rewards) AS 累计打赏数 FROM monthly WHERE titletime>=DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS a LEFT JOIN ( SELECT 时间区间,COUNT(作者) AS 作者数 FROM ( SELECT 时间区间,author AS 作者 FROM ( SELECT *,'近30天' AS 时间区间 FROM monthly WHERE titletime>=DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS b0 GROUP BY author ) AS b1 ) AS b ON a.时间区间=b.时间区间 LEFT JOIN ( SELECT 时间区间,COUNT(发表日期) AS 天数 FROM ( SELECT 时间区间,发表日期 FROM ( SELECT *,'近30天' AS 时间区间,DATE(titletime) AS 发表日期 FROM monthly WHERE titletime>=DATE_ADD(CURRENT_DATE,INTERVAL -30 DAY) ) AS b0 GROUP BY 发表日期 ) AS b1 ) AS c ON a.时间区间=b.时间区间 )

从这里看出热门30天专题收录的时间大致接近最近50多天的数据,简叔的那个数据应该算是异常值,时间关系我没来得及改where条件,这两个时间段前后收录的文章数差距很大,作者数也差距很大,30天前的pv浏览量如果去掉简书的60多万PV 差距也会很大,但从评论数和喜欢数上来看,30天前的文章文笔比近30天的文笔要好一些,吸引了吃瓜群众的吐槽,在文章数差距比较大的情况下,这两个数据变化不是很大,甚至30天前的喜欢数远超近30天。
五、看下专题收录文章前10名作者的情况
#30日热门收录文章数前10名的作者 SELECT a.*,b.首次被专题收录时间,c.最近被专题收录时间,DATEDIFF(c.最近被专题收录时间,b.首次被专题收录时间) AS 间隔天数,d.发表天数 FROM ( SELECT '30日热门' AS 收录专题,author AS 作者,COUNT(titleurl) AS 被收录几次,COUNT(titleurl) AS 文章数,SUM(reader) AS 累计PV浏览量,SUM(comment_num) AS 累计评论数,SUM(likes) AS 累计喜欢数,SUM(rewards) AS 累计打赏数 FROM monthly GROUP BY author ORDER BY COUNT(titleurl) DESC LIMIT 10 ) AS a LEFT JOIN ( SELECT author AS 作者,首次被专题收录时间 FROM ( SELECT author,DATE(titletime) AS 首次被专题收录时间 FROM monthly GROUP BY author,DATE(titletime) ORDER BY author,titletime ) AS b0 GROUP BY author ) AS b ON a.作者=b.作者 LEFT JOIN ( SELECT author AS 作者,最近被专题收录时间 FROM ( SELECT author,DATE(titletime) AS 最近被专题收录时间 FROM monthly GROUP BY author,DATE(titletime) ORDER BY author,titletime DESC ) AS c0 GROUP BY author ) AS c ON a.作者=c.作者 LEFT JOIN ( SELECT author AS 作者,COUNT(发表日期) AS 发表天数 FROM ( SELECT author,DATE(titletime) AS 发表日期 FROM monthly GROUP BY author,DATE(titletime) ) AS d0 GROUP BY author ) AS d ON a.作者=d.作者

专题作者,后面字段还可以更完善,可以加上这个作者评论最多的文章,打赏最多的文章等等,以及下一步爬取专题作者页面获得作者注册时间,粉丝数,累计发表文章数,累计写了多少文字等等
时间关系,抽时间再完善一下分析的角度,收录专题中发表文章集中的时间段,打赏,浏览py的文章有什么特性等以及图表制作

