python之字符编码(四)
一、字符编码的使用:
1、文本编辑器
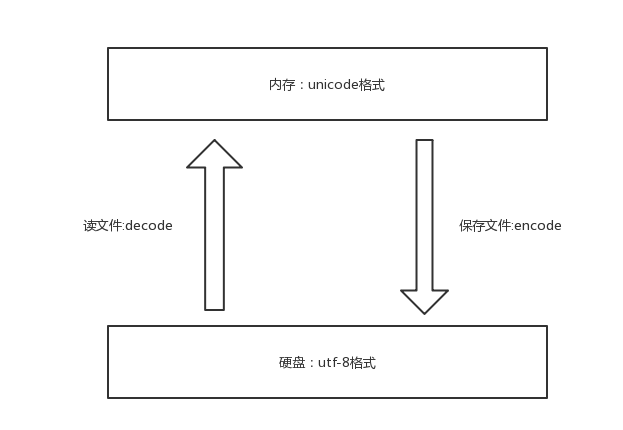
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
补充:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
2、文本编辑器nodpad++:
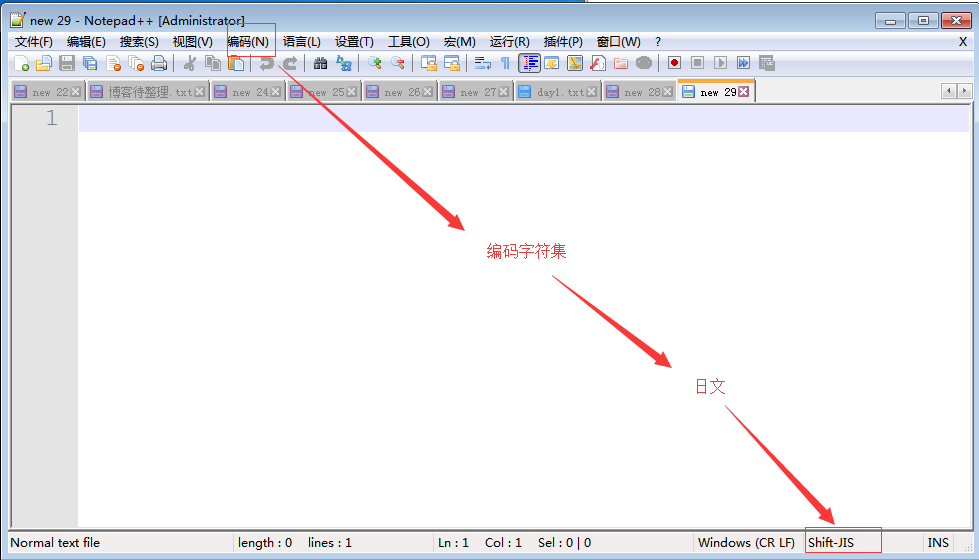
分析过程?什么是乱码
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
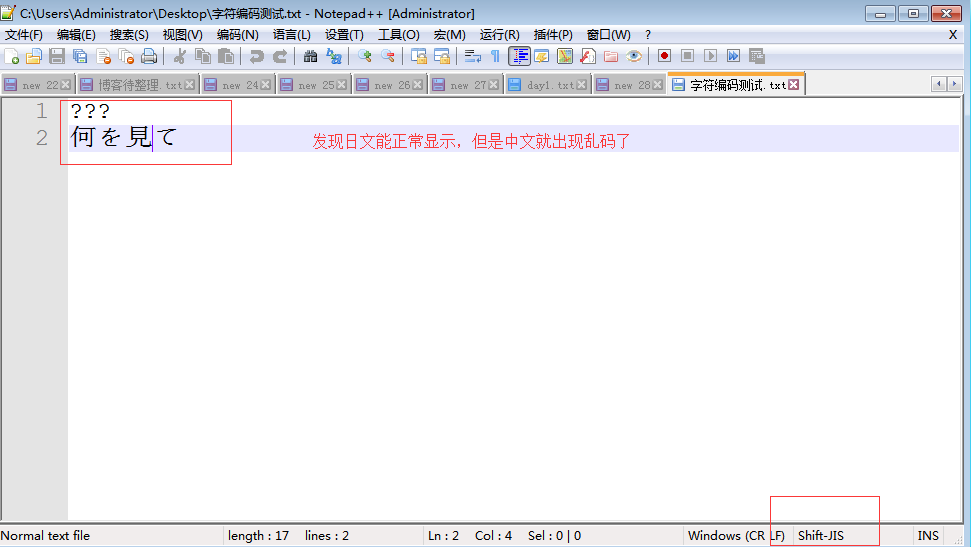
乱码一:存文件时就已经乱码
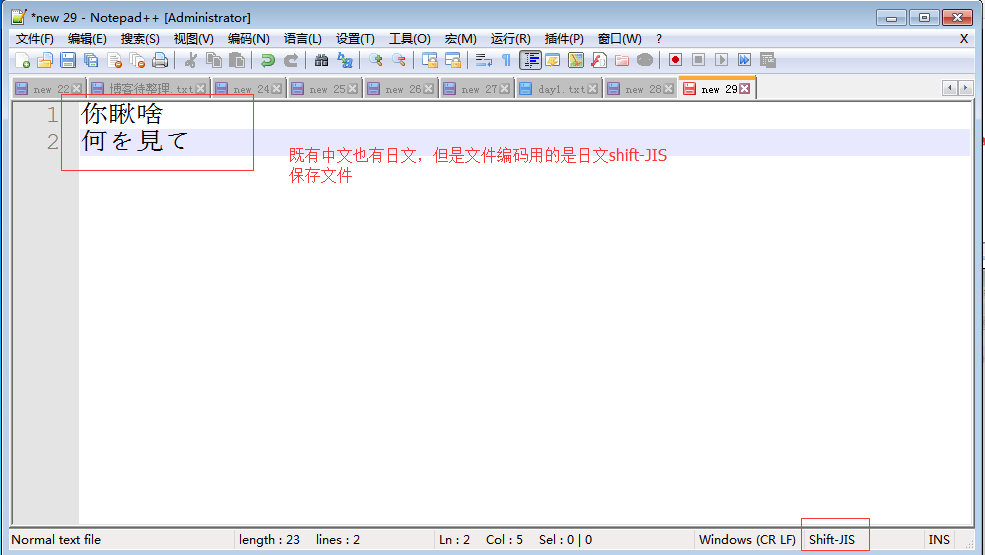
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败(可以用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis')
f.write('你瞅啥\n何を見て\n') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て\n'可以成功)
但当我们硬要存的时候,编辑并不会报错,毫无疑问的是乱码了,即存文件阶段就已经发生乱码
而当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
f=open('a.txt','wb')
f.write('何を見て\n'.encode('shift_jis'))
f.write('你愁啥\n'.encode('gbk'))
f.write('你愁啥\n'.encode('utf-8'))
f.close()
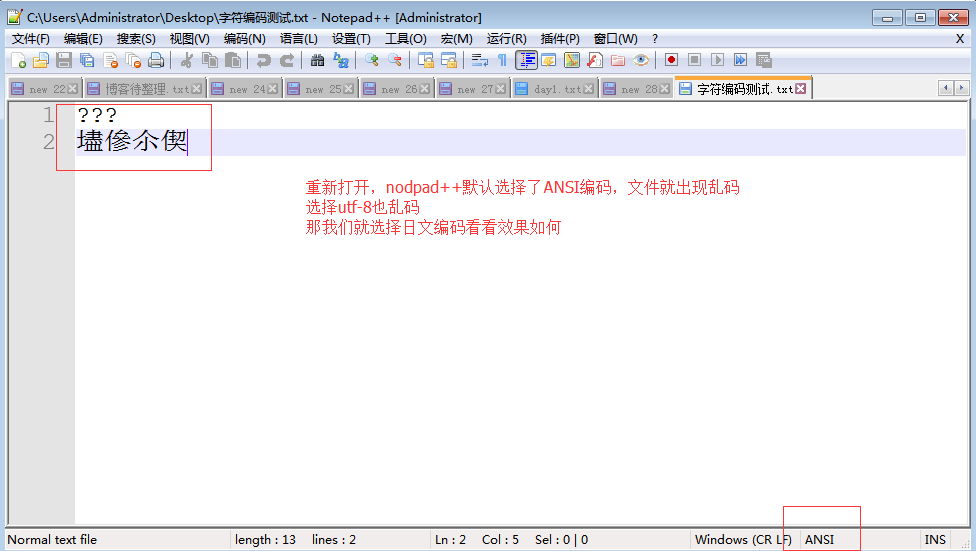
#以任何编码打开文件a.txt都会出现其余两个无法正常显示的问题
其他类似的测试
乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,
而存文件时不顾编码错误而去硬存,不报错则肯定是数据损坏了。
3、文本编辑器pycharm
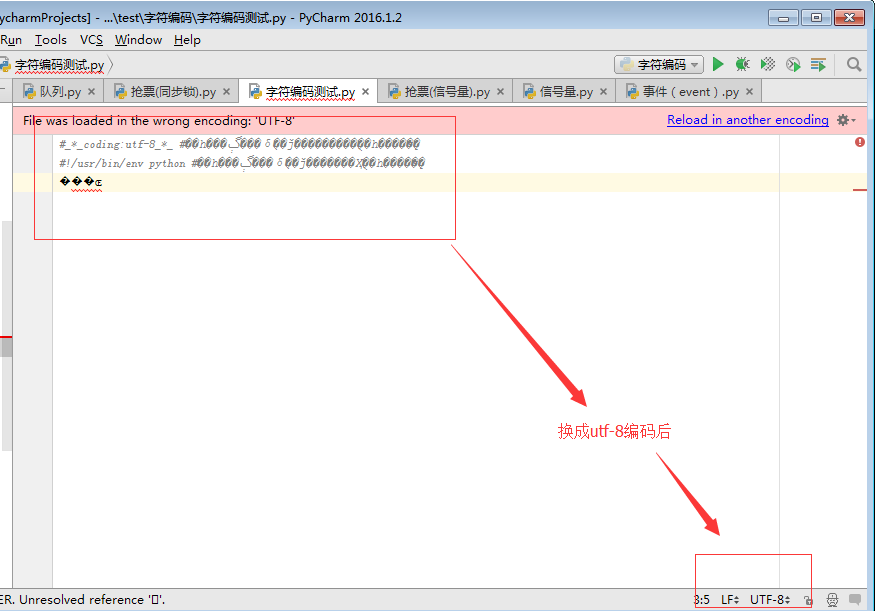
以gbk格式保存

以utf-8格式打开(reload)
reload与convert的区别:
pycharm非常强大,提供了自动帮我们convert转换的功能,即将字符按照正确的格式转换
要自己探究字符编码的本质,还是不要用这个
我们选择reload,即按照某种编码重新加载文件
分析过程?
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
4、文本编辑器之python解释器
文件test.py以gbk格式保存,内容为:
x='林'
无论是
python2 test.py
还是
python3 test.py
都会报错(因为python2默认ascii,python3默认utf-8)
除非在文件开头指定#coding:gbk
5、程序的执行
python test.py (我再强调一遍,执行test.py的第一步,一定是先将文件内容读入到内存中)
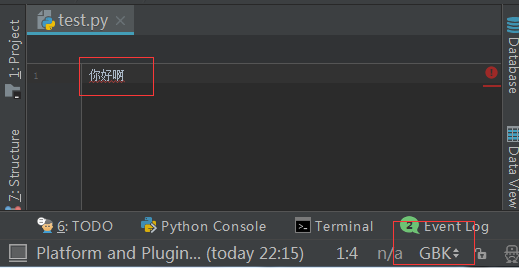
test.py文件内容以gbk格式保存的,内容为:
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码,
可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8

改正:在test.py指定文件头,字符编码一定要为gbk,
#coding:gbk 你好啊

阶段三:读取已经加载到内存的代码(unicode编码格式),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
内存的编码使用unicode,不代表内存中全都是unicode,
在程序执行之前,内存中确实都是unicode,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode的格式存放于内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间)用来存放python的数据类型的值,而python的字符串类型又涉及到了字符的概念
比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放字符串类型的值,至于该字符串类型的值被识别成何种编码存放,这就与python解释器的有关了,而python2与python3的字符串类型又有所不同。
二、python2与python3字符窜类型的区别
1、在python2中有两种字符窜类型str和unicode
str类型
当python解释器执行到产生字符串的代码时(例如x='上'),会申请新的内存地址,然后将'上'编码成文件开头指定的编码格式
要想看x在内存中的真实格式,可以将其放入列表中再打印,而不要直接打印,因为直接print()会自动转换编码,这一点我们稍后再说。
#coding:gbk x='上' y='下' print([x,y]) #['\xc9\xcf', '\xcf\xc2'] #\x代表16进制,此处是c9cf总共4位16进制数,一个16进制四4个比特位,4个16进制数则是16个比特位,即2个Bytes,这就证明了按照gbk编码中文用2Bytes
print(type(x),type(y)) #(<type 'str'>, <type 'str'>)
理解字符编码的关键!!!!!!!!!!!!!!!!!!!!!!!!!
内存中的数据通常用16进制表示,2位16进制数据代表一个字节,如\xc9,代表两位16进制,一个字节
gbk存中文需要2个bytes,而存英文则需要1个bytes,它是如何做到的???!!!
gbk会在每个bytes,即8位bit的第一个位作为标志位,标志位为1则表示是中文字符,如果标志位为0则表示为英文字符
x=‘你a好’ 转成gbk格式二进制位 8bit+8bit+8bit+8bit+8bit=(1+7bit)+(1+7bit)+(0+7bit)+(1+7bit)+(1+7bit)
这样计算机按照从左往右的顺序读:
#连续读到前两个括号内的首位标志位均为1,则构成一个中午字符:你 #读到第三个括号的首位标志为0,则该8bit代表一个英文字符:a #连续读到后两个括号内的首位标志位均为1,则构成一个中午字符:好
也就是说,每个Bytes留给我们用来存真正值的有效位数只有7位,而在unicode表中存放的只是这有效的7位,至于首位的标志位与具体的编码有关,即在unicode中表示gbk的方式为:
(7bit)+(7bit)+(7bit)+(7bit)+(7bit)
按照上图翻译的结果,我们可以去unicode关于汉字的对应关系中去查:链接:https://pan.baidu.com/s/1dEV3RYp 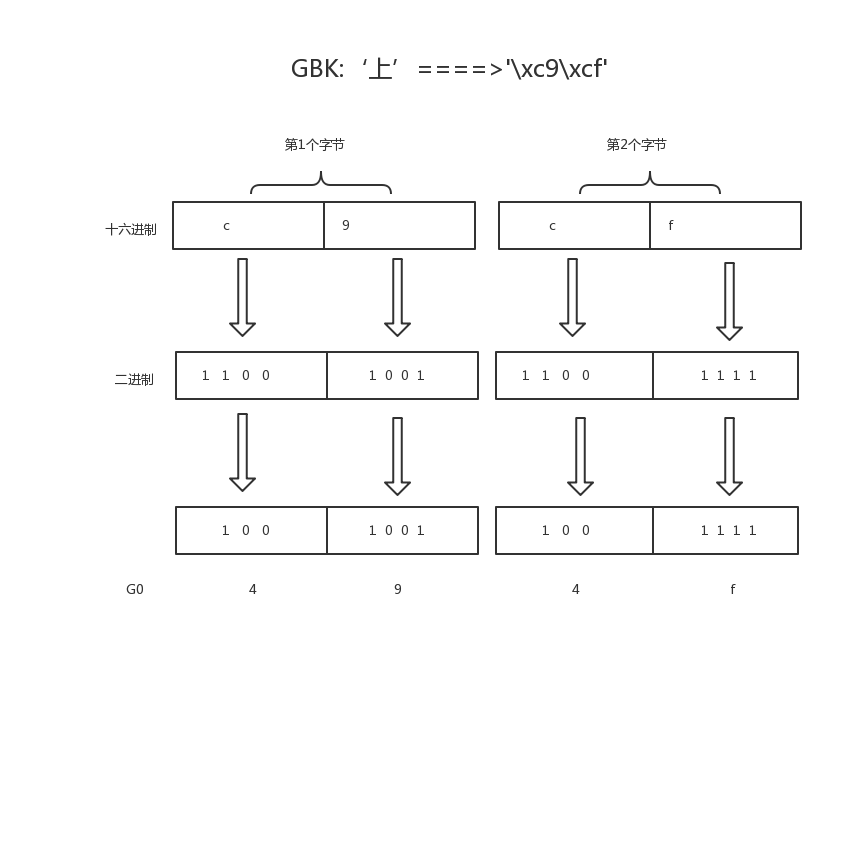
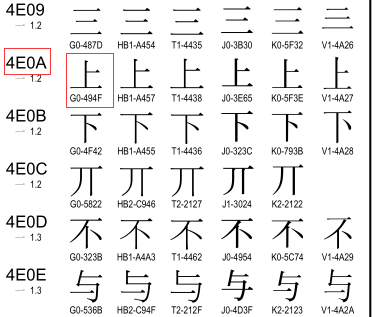
可以看到“”上“”对应的gbk(G0代表的是gbk)编码就为494F,即我们得出的结果,而上对应的unicode编码为4E0A,我们可以将gbk-->decode-->unicode
#coding:gbk
x='上'.decode('gbk')
y='下'.decode('gbk')
print([x,y]) #[u'\u4e0a', u'\u4e0b']
unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
#coding:gbk
x=u'上' #等同于 x='上'.decode('gbk')
y=u'下' #等同于 y='下'.decode('gbk')
print([x,y]) #[u'\u4e0a', u'\u4e0b']
print(type(x),type(y)) #(<type 'unicode'>, <type 'unicode'>)
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='上' #gbk下,字符串存放为\xc9\xcf
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,按理说应该是存的什么就打印什么,但打印\xc9\xcf,对一些不熟知python编码的程序员,立马就懵逼了,所以龟叔自作主张,在print(x)时,使用终端的编码格式,将内存中的\xc9\xcf转成字符显示,此时就需要终端编码必须为gbk,否则无法正常显示原内容:上


对于unicode格式的数据来说,无论怎么打印,都不会乱码

对于unicode格式的数据来说,无论怎么打印,都不会乱码
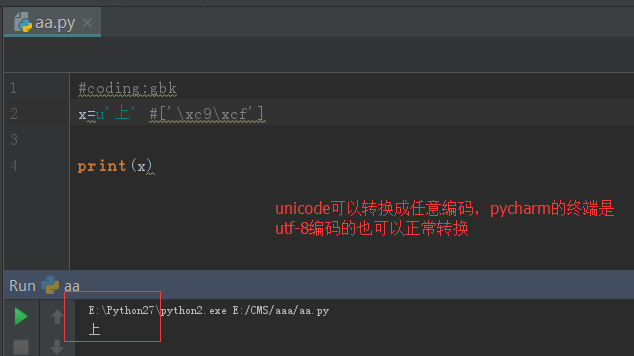

nicode这么好,不会乱码,那python2为何还那么别扭,搞一个str出来呢?python诞生之时,unicode并未像今天这样普及,很明显,好的东西你能看得见,龟叔早就看见了,龟叔在python3中将str直接存成unicode,我们定义一个str,无需加u前缀,就是一个unicode,屌不屌?
在python3 中也有两种字符串类型str和bytes
str是unicode
#coding:gbk
x='上' #当程序执行时,无需加u,'上'也会被以unicode形式保存新的内存空间中,
print(type(x)) #<class 'str'>
#x可以直接encode成任意编码格式
print(x.encode('gbk')) #b'\xc9\xcf'
print(type(x.encode('gbk'))) #<class 'bytes'>
很重要的一点是:看到python3中x.enco
很重要的一点是:看到python3中x.encode('gbk') 的结果\xc9\xcf正是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型
于是我有一个大胆的推测:python2中的str类型就是python3的bytes类型,于是我查看python2的str()源码,发现
de('gbk') 的结果\xc9\xcf正是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型


 浙公网安备 33010602011771号
浙公网安备 33010602011771号