python之协程函数、递归、二分法
一、协程函数:
协程函数的语法:
def eater(name):
print('%s说:我开动啦' %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print('%s 吃了 %s' %(name,food))
e=eater('egon')
e.send(None) #next(e) #初始化装饰器,
e.close() #关闭
解决方法:第一步:初始化函数Next(),第二部:给yield传值
二、面向过程:
面向过程:核心是过程二字,过程就是解决问题的步骤,基于面向过程去设计程序就像是在设计,一条工业流水线,是一种机械式的思维方式 #优点:程序结构清晰,可以把复杂的问题简单化,流程化
#缺点:可扩展性差,一条流线只是用来解决一个问题
#应用场景:linux内核,git,httpd,shell脚本
三、递归:
递归调用:在调用一个函数的过程中,直接或间接地调用了函数本身
递归效率低,需要在进入下一次递归时保留当前的状态
解决方法是尾递归,即在函数的最后一步(而非最后一行)调用自己
但是python又没有尾递归,且对递归层级做了限制
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回, 栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
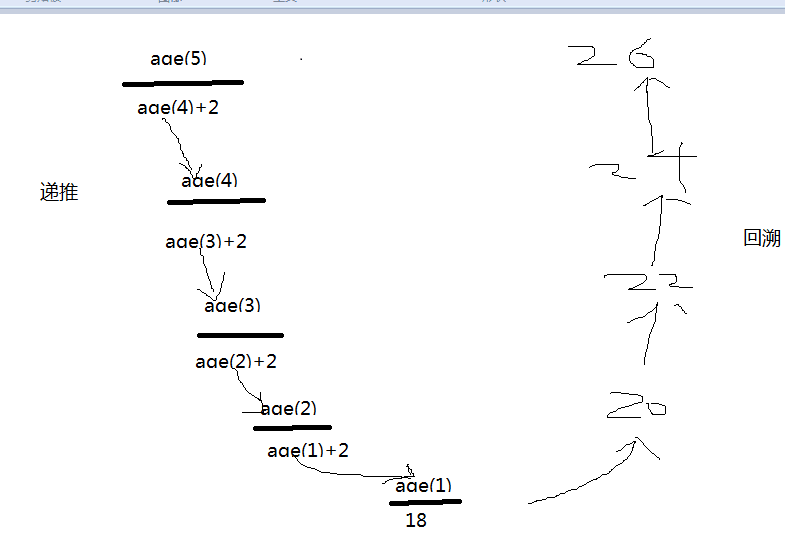
递归的执行分为两个阶段:
1 递推
2 回溯
def age(n):
if n == 1:
return 18
return age(n-1)+2
print(age(5))
四、二分法:
l=[1,2,10,2,30,40,33,22,99,31]
def search(num,l):
print(l)
if len(l) > 1:
mid=len(l)//2
if num > l[mid]:
#in the right
l=l[mid:]
search(num,l)
elif num < l[mid]:
#in the left
l=l[:mid]
search(num,l)
else:
print('find it')
else:
if num == l[0]:
print('find it')
else:
print('not exists')
search(100,l)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号