
pandas函数之pivot、pivot_table和crosstab
1、pivot方法
pandas.pivot(data, index=None, columns=None, values=None)
(1)参数
data:DataFrame
index:str or object or a list of str, optional。用于创建新DataFrame索引名称。 如果没有,则使用现有的索引。
columns:str or object or a list of str。用于创建新DataFrame列名称。
values:str, object or a list of the previous, optional。
(2)举例
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two','two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
pivot_df = pd.pivot(df,columns='bar')
foo baz zoo
bar A B C A B C A B C
0 one NaN NaN 1.0 NaN NaN x NaN NaN
1 NaN one NaN NaN 2.0 NaN NaN y NaN
2 NaN NaN one NaN NaN 3.0 NaN NaN z
3 two NaN NaN 4.0 NaN NaN q NaN NaN
4 NaN two NaN NaN 5.0 NaN NaN w NaN
5 NaN NaN two NaN NaN 6.0 NaN NaN t
df.pivot(index='foo', columns='bar', values='baz') bar A B C foo one 1 2 3 two 4 5
df.pivot(index='foo', columns='bar')['baz']
bar A B C
foo
one 1 2 3
two 4 5 6
df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])
baz zoo
bar A B C A B C
foo
one 1 2 3 x y z
two 4 5 6 q w t
索引和列都是列表形式
df = pd.DataFrame({"lev1": [1, 1, 1, 2, 2, 2],
"lev2": [1, 1, 2, 1, 1, 2],
"lev3": [1, 2, 1, 2, 1, 2],
"lev4": [1, 2, 3, 4, 5, 6],
"values": [0, 1, 2, 3, 4, 5]})
lev1 lev2 lev3 lev4 values
0 1 1 1 1 0
1 1 1 2 2 1
2 1 2 1 3 2
3 2 1 2 4 3
4 2 1 1 5 4
5 2 2 2 6 5
df.pivot(index="lev1", columns=["lev2", "lev3"],values="values")
lev2 1 2
lev3 1 2 1 2
lev1
1 0.0 1.0 2.0 NaN
2 4.0 3.0 NaN 5.0
df.pivot(index=["lev1", "lev2"], columns=["lev3"],values="values")
lev3 1 2
lev1 lev2
1 1 0.0 1.0
2 2.0 NaN
2 1 4.0 3.0
2 NaN 5.0
![]()
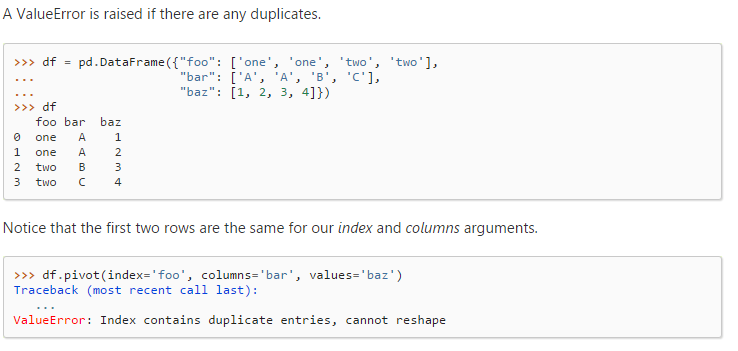
2、pivot_table方法(透视表)
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',fill_value=None, margins=False,
dropna=True, margins_name='All', observed=False,sort=True)
(1)参数
data:DataFrame
values:列聚合值。
index:column, Grouper, array, or list of the previous。
columns:column, Grouper, array, or list of the previous。
aggfunc:function, list of functions, dict, default numpy.mean。聚合方式
fill_value:scalar, default None。Value to replace missing values with (in the resulting pivot table, after aggregation).(缺失值填充)
margins:bool, default False。Add all row / columns
dropna:bool, default True。Do not include columns whose entries are all NaN.
margins_name:str, default ‘All’。Name of the row / column that will contain the totals when margins is True.
observed:bool, default False
(2)举例
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"