
pandas函数之cut和qcut
1、cut方法
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)
(1)参数
X:被切分的类数组(array-like)数据,必须是1维的。不能是DataFrame。
bins:被切割后的区间,有3中形式:int, sequence of scalars, or IntervalIndex。
int:代表将X平分成bins份,x的范围在每侧扩展0.1%,以包括X的最大值和最小值。
sequence of scalars(标量序列):被分割后每一个bin的区间边缘,此时x没有扩展。
IntervalIndex:定义要使用的精确区间。
right:bool型,默认为True。是否包括最右边的边缘,比如right=True,bins=[1,2,3,4],则区间为(1,2]、(2,3]、(3,4];right=False,则区间为(1,2)、(2,3)、(3,4)。
labels:给分割后的bins打标签。必须与箱子长度相同,比如bins=[1,2,3],划分后有两个区间(1,2]、(2,3],则labels长度必须为2。如果labels=False,则返回X中的数据在第几个 bin中(从0开始)。
retbins:bool型,默认为False。是否将分割后的bins返回,当bins为一个int型的标量比较有用,这样可以得到划分后的区间。
precision:保留区间小数点的位数,默认为3.
include_lowest:bool型,默认为False。第一个间隔是否应包含在内。
duplicates:是否允许重复区间。raise:不允许,drop:允许。
ordered:bool型,默认为True。True对结果进行排序,False不排序。
(2)返回值
out:Categorical, Series, or ndarray。分区后x中的每个值在那个bin中,如果指定了labels则返回对应的label。
bins:分割后的区间,当指定retbins为True时返回。
(3)举例
df = pd.DataFrame([x for x in range(20)],columns=['number',])

df = pd.DataFrame([x**2 for x in range(11)],columns=['number',])
df['cut_group'] = pd.cut(df['number'],4)(按照数据值由小到大的顺序将数据分成4份,并且使每组值的范围大致相等。)
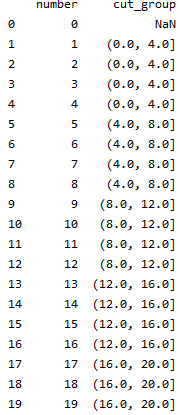
df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20])(bins参数:按照指定的边界值对变量进行分割)
![]()
df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20],right=False)(right参数:设定分组的开闭区间)
![]()

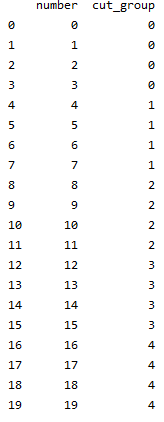
df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20],right=False,labels=False)(labels为False,返回值在第几个bin中)
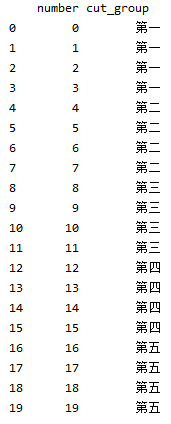
df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20],right=False,labels=['第一','第二','第三','第四','第五',])(返回自定义标签名)
![]()
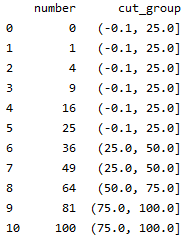
df['cut_group'],bins = pd.cut(df['number'],4,retbins=True)(retbins参数:获取边界值的列表)
![]()

df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20],right=True,include_lowest=False)(第一)
df['cut_group'] = pd.cut(df['number'],bins=[0,4,8,12,16,20],right=True,include_lowest=True)(第二)
![]()
![]()


2、qcut方法
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
(1)参数
x:一维 ndarray 或系列
q:整数或浮点数的list-like,分位数。 10 表示十分位数,4 表示四分位数等。交替排列的分位数,例如[0, .25, .5, .75, 1.] 四分位数。
labels:数组或假,默认无。用作结果箱的标签。必须与生成的 bin 长度相同。如果为 False,则仅返回 bin 的整数指示符。如果为 True,则引发错误。
retbins:布尔型,可选。是否返回(箱,标签)。如果 bins 作为标量给出,则可能很有用。
precision:整数,可选。存储和显示 bin 标签的精度。
duplicates:{默认 ‘raise’, ‘drop’},可选。
(2)举例
df = pd.DataFrame([x**2 for x in range(11)],columns=['number',])
df['cut_group'] = pd.qcut(df['number'],4)(按变量的数量来对变量进行分割,把变量由小到大分成四组,并且让每组变量的数量相同)
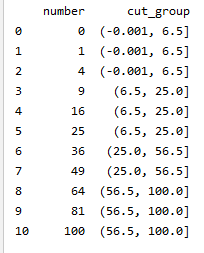
跟cut()一样, 我们可以通过在qcut()设置retbins参数, 获取每个分组的边界值列表。
df['cut_group'] = pd.qcut(df['number'],4,retbins=True)
总结
cut()和qcut()的主要作用都是对变量进行分箱操作。但不同的是,cut()是按变量的值进行划分,而qcut()是按照变量的个数进行划分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号