Spark学习--SparkSQL02
数据读写
DataFrameReader
| 组件 | 解释 |
|---|---|
|
|
结构信息, 因为 |
|
|
连接外部数据源的参数, 例如 |
|
|
外部数据源的格式, 例如
|
读取文件的方式
def reader(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("reader") .getOrCreate() // 2. 第一种形式 spark.read .format("csv") .option("header", value = true) .option("inferSchema", value = true) .load("XXX.csv") .show(10) // 3. 第二种形式 spark.read .option("header", value = true) .option("inferSchema", value = true) .csv("XXX.csv") .show() }
DataFrameWriter
| 组件 | 解释 |
|---|---|
|
|
写入目标, 文件格式等, 通过 |
|
|
写入模式, 例如一张表已经存在, 如果通过 |
|
|
外部参数, 例如 |
|
|
类似 |
|
|
类似 |
|
|
用于排序的列, 通过 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
写入文件的方式
def writer(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("write") .getOrCreate() // 2. 读取数据集 val df = spark.read.option("header", value = true).csv("dataset/BeijingPM20100101_20151231.csv") // 3. 写入数据集 df.write.json("dataset/beijing_pm.json") df.write.format("json").save("dataset/beijing_pm2.json") }
读写 Parquet 格式文件
def parquetReadWritePartitions(): Unit = { //1. 读取数据 val df = spark.read .option("header", value = true) .csv("dataset/BeijingPM20100101_20151231.csv") //2. 写文件, 表分区 df.write .partitionBy("year", "month") .save("dataset/beijing_pm") //3. 读文件, 自动发现分区 // 写分区表的时候, 分区列不会包含在生成的文件中 // 直接通过文件来进行读取的话, 分区信息会丢失 //spark sql 会进行自动的分区发现 spark.read .parquet("dataset/beijing_pm4") .printSchema() }
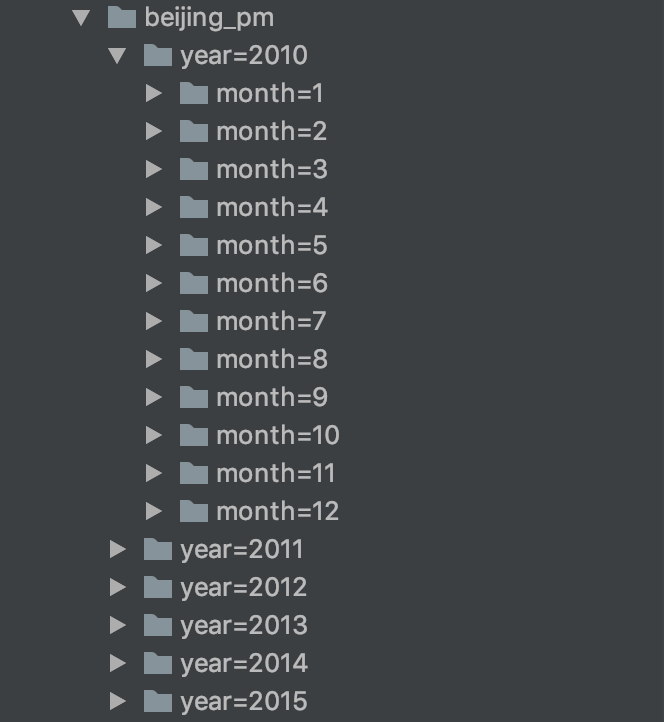
总结
- Spark 不指定 format 的时候默认就是按照 Parquet 的格式解析文件
- Spark 在读取 Parquet 文件的时候会自动的发现 Parquet 的分区和分区字段
- Spark 在写入 Parquet 文件的时候如果设置了分区字段, 会自动的按照分区存储
读写 JSON 格式文件
def json(): Unit = { val df = spark.read .option("header", value = true) .csv("xxx.csv") //直接转换 df.toJSON.show() df.write .json("xxx.json") spark.read .json("xxx.json") .show() }
Spark访问Hive
Hive的MetaStore
概念
Hive 的 MetaStore 是一个 Hive 的组件, 一个 Hive 提供的程序, 用以保存和访问表的元数据
配置hive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>username</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>password</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node01:9083</value> //当前服务器 </property>
启动
nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
Hive操作
shell操作
CREATE EXTERNAL TABLE student ( name STRING, age INT, ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' //行分隔符 LINES TERMINATED BY '\n' //列分隔符 STORED AS TEXTFILE LOCATION '/spark/hive'; LOAD DATA INPATH '/data/spark/studenttab10k' OVERWRITE INTO TABLE student; //文件存储位置
API操作
def main(args: Array[String]): Unit = { // 1. 创建 SparkSession // 1. 开启 Hive 支持 // 2. 指定 Metastore 的位置 // 3. 指定 Warehouse 的位置 val spark = SparkSession.builder() .appName("hive access") .enableHiveSupport() .config("hive.metastore.uris", "thrift://node01:9083") .config("spark.sql.warehouse.dir", "/spark/hive") .getOrCreate() import spark.implicits._ // 2. 读取数据 // 1. 上传 HDFS, 因为要在集群中执行, 没办法保证程序在哪个机器中执行 // 所以, 要把文件上传到所有的机器中, 才能读取本地文件 // 上传到 HDFS 中就可以解决这个问题, 所有的机器都可以读取 HDFS 中的文件 // 它是一个外部系统 // 2. 使用 DF 读取数据 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val dataframe = spark.read .option("delimiter", "\t") .schema(schema) .csv("hdfs:///saprk/data/studenttab10k") val resultDF = dataframe.where('age > 50) // 3. 写入数据, 使用写入表的 API, saveAsTable resultDF.write.mode(SaveMode.Overwrite).saveAsTable("spark03.student") }
Spark访问MySQL
def main(args: Array[String]): Unit = { // 1. 创建 SparkSession 对象 val spark = SparkSession.builder() .master("local[6]") .appName("mysql write") .getOrCreate() // 2. 读取数据创建 DataFrame // 1. 拷贝文件 // 2. 读取 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val df = spark.read .schema(schema) .option("delimiter", "\t") .csv("dataset/studenttab10k") // 3. 处理数据 val resultDF = df.where("age < 30") // 4. 落地数据 resultDF.write .format("jdbc") .option("url", "jdbc:mysql://node01:3306/spark02") .option("dbtable", "student") .option("user", "spark03") .option("password", "Spark03!") .mode(SaveMode.Overwrite) .save() }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号