大数据学习总结14
1、MapReduce 排序和序列化
-
序列化 (Serialization) 是指把结构化对象转化为字节流
-
反序列化 (Deserialization) 是序列化的逆过程. 把字节流转为结构化对象. 当要在进程间传递对象或持久化对象的时候, 就需要序列化对象成字节流, 反之当要将接收到或从磁盘读取的字节流转换为对象, 就要进行反序列化
-
Java 的序列化 (Serializable) 是一个重量级序列化框架, 一个对象被序列化后, 会附带很多额外的信息 (各种校验信息, header, 继承体系等), 不便于在网络中高效传输. 所以, Hadoop 自己开发了一套序列化机制(Writable), 精简高效. 不用像 Java 对象类一样传输多层的父子关系, 需要哪个属性就传输哪个属性值, 大大的减少网络传输的开销
-
Writable 是 Hadoop 的序列化格式, Hadoop 定义了这样一个 Writable 接口. 一个类要支持可序列化只需实现这个接口即可
-
另外 Writable 有一个子接口是 WritableComparable, WritableComparable 是既可实现序列化, 也可以对key进行比较, 我们这里可以通过自定义 Key 实现 WritableComparable 来实现我们的排序功能
案例:
数据格式如下
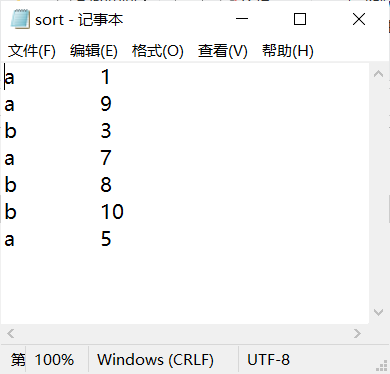
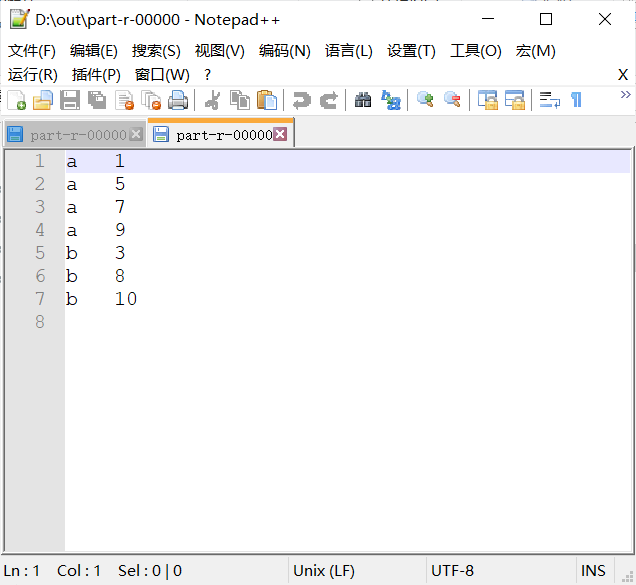
要求:
-
第一列按照字典顺序进行排列
-
第一列相同的时候, 第二列按照升序进行排列
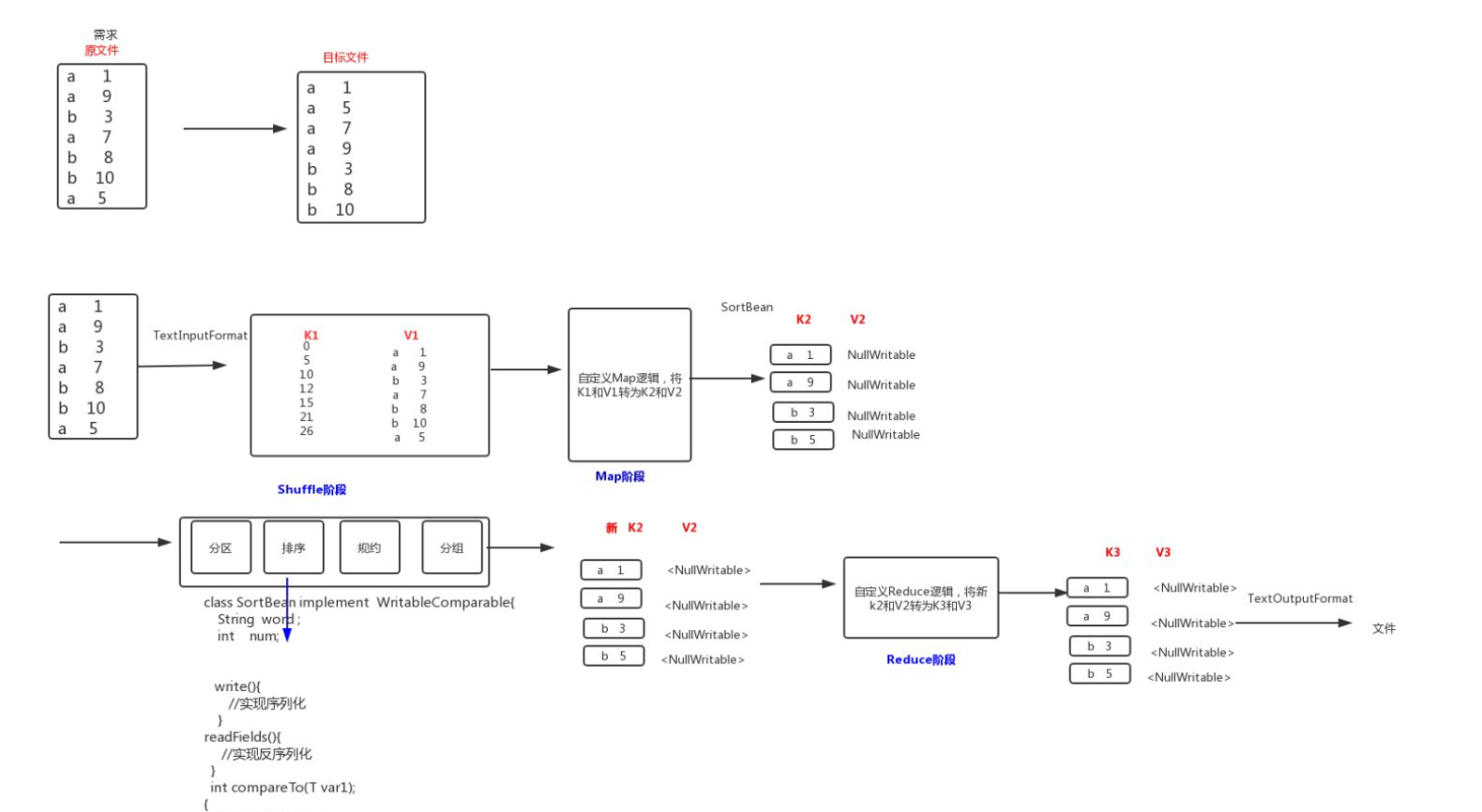
解决思路:
-
将 Map 端输出的
<key,value>中的 key 和 value 组合成一个新的 key (newKey), value值不变 -
这里就变成
<(key,value),value>, 在针对 newKey 排序的时候, 如果 key 相同, 就再对value进行排序
Step 1. 自定义类型和比较器


package sort; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @author MoooJL * @data 2020/8/27-22:50 */ public class SortBean implements WritableComparable<SortBean> { private String word; private int num; public String getWord() { return word; } public void setWord(String word) { this.word = word; } public int getNum() { return num; } public void setNum(int num) { this.num = num; } //实现比较器,指定排序规则 /* 第一列(word)按照字典顺序进行排列 第一列相同的时候, 第二列(num)按照升序进行排列 */ @Override public String toString() { return word + "\t" + num ; } @Override public int compareTo(SortBean sortBean) { //第一列排序 int result = this.word.compareTo(sortBean.getWord()); //如果第一列相同,则排序第二列 if (result==0){ return this.num-sortBean.getNum(); } return result; } //实现序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(word); out.writeInt(num); } //实现反序列化 @Override public void readFields(DataInput in) throws IOException { this.word=in.readUTF(); this.num=in.readInt(); } }
Step 2. Mapper
package sort; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @author MoooJL * @data 2020/8/27-23:14 */ public class SortMapper extends Mapper<LongWritable, Text,SortBean, NullWritable> { /* map方法将K1和V1转为K2和V2: K1 V1 0 a 3 5 b 7 ---------------------- K2 V2 SortBean(a 3) NullWritable SortBean(b 7) NullWritable */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1:将行文本数据(V1)拆分,并将数据封装到SortBean对象,就可以得到K2 String[] split = value.toString().split("\t"); SortBean sortBean=new SortBean(); sortBean.setWord(split[0]); sortBean.setNum(Integer.parseInt(split[1])); //2:将K2和V2写入上下文中 context.write(sortBean, NullWritable.get()); } }
Step 3. Reducer
package sort; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @author MoooJL * @data 2020/8/27-23:21 */ public class SortReducer extends Reducer<SortBean, NullWritable,SortBean,NullWritable> { //reduce方法将新的K2和V2转为K3和V3 @Override protected void reduce(SortBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
Step 4. Main 入口
package sort; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @author MoooJL * @data 2020/8/27-23:23 */ public class JobMain extends Configured implements Tool { @Override public int run(String[] args) throws Exception { //1:创建job对象 Job job = Job.getInstance(super.getConf(), "mapreduce_sort"); //2:配置job任务(八个步骤) //第一步:设置输入类和输入的路径 job.setInputFormatClass(TextInputFormat.class); ///TextInputFormat.addInputPath(job, new Path("hdfs://node01:8020/input/sort_input")); TextInputFormat.addInputPath(job, new Path("file:///D:\\input\\sort_input")); //第二步: 设置Mapper类和数据类型 job.setMapperClass(SortMapper.class); job.setMapOutputKeyClass(SortBean.class); job.setMapOutputValueClass(NullWritable.class); //第三,四,五,六 //第七步:设置Reducer类和类型 job.setReducerClass(SortReducer.class); job.setOutputKeyClass(SortBean.class); job.setOutputValueClass(NullWritable.class); //第八步: 设置输出类和输出的路径 job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\sort_out")); //3:等待任务结束 boolean bl = job.waitForCompletion(true); return bl?0:1; } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); //启动job任务 int run = ToolRunner.run(configuration, new JobMain(), args); System.exit(run); } }
2、规约Combiner
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能,是 MapReduce 的一种优化手段之一
- combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是 Reducer
- combiner 和 reducer 的区别在于运行的位置
- Combiner 是在每一个 maptask 所在的节点运行
- Reducer 是接收全局所有 Mapper 的输出结果
- combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
实现步骤
·自定义一个 combiner 继承 Reducer,重写 reduce 方法
·在 job 中设置 job.setCombinerClass(CustomCombiner.class)
combiner 能够应用的前提是不能影响最终的业务逻辑,而且,combiner 的输出 kv 应该跟 reducer 的输入 kv 类型要对应起来
案例:基于统计单词的出现次数案例
Step 1. 自定义MyCombiner
package combiner; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @author MoooJL * @data 2020/8/28-18:57 */ public class MyCombiner extends Reducer<Text, LongWritable,Text,LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { //1、遍历集合,将集合的数字相加得到v3 long count =0; LongWritable longWritable=new LongWritable(); for (LongWritable value : values) { count+=value.get(); } //2、将k3 v3写入上下文 longWritable.set(count); context.write(key,longWritable); } }
Step 2.在 job 中设置 job.setCombinerClass(MyCombiner.class)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号