大数据学习总结12
一、HDFS 的 API 操作
导入maven依赖


<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1、使用url方式访问数据
@Test
public void urlHdfs() throws IOException {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
InputStream inputStream=new URL("hdfs://node01:8020/dir1/hello.txt").openStream();
FileOutputStream fileOutputStream = new FileOutputStream(new File("D:\\hello.txt"));
IOUtils.copy(inputStream,fileOutputStream);
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(fileOutputStream);
}
2、使用文件系统方式访问数据
①获取 FileSystem 的几种方式
/*
获取 FileSystem 的几种方式
*/
@Test
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
//指定我们使用的文件系统类型:
configuration.set("fs.defaultFS", "hdfs://node01:8020/");
//获取指定的文件系统
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem);
}
@Test
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
System.out.println("fileSystem:"+fileSystem);
}
@Test
public void getFileSystem3() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
@Test
public void getFileSystem4() throws Exception{
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://node01:8020") ,new Configuration());
System.out.println(fileSystem.toString());
}

② 遍历 HDFS 中所有文件
/*
hdfs文件的遍历
*/
@Test
public void listFiles() throws URISyntaxException, IOException {
//1、获取 FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
//2、调用listFiles方法 获取 / 目录下的所有文件信息
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"), true);
//3、遍历迭代器
while (iterator.hasNext()){
LocatedFileStatus fileStatus = iterator.next();
//获取文件的绝对路径 : hdfs://node01:8020/xxx
System.out.println(fileStatus.getPath()+"----"+fileStatus.getPath().getName());
//fileStatus.getPath();
//文件的block信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println("block数"+blockLocations.length);
}
}
③ HDFS 上创建文件夹
/*
hdfs上创建文件夹
*/
@Test
public void mkdirsTest() throws URISyntaxException, IOException {
//1、获取 FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),
new Configuration());
//2、创建文件夹
//boolean b = fileSystem.mkdirs(new Path("/dir3/test"));
// 创建文件 如果目录不存在,会自动创建目录
fileSystem.create(new Path("/dir3/test/hello.txt"));
//System.out.println(b);
//3、关闭fileSystem
fileSystem.close();
}

④下载文件
/*
文件的下载 方法1
*/
@Test
public void downloadFile() throws URISyntaxException, IOException {
//1、获取 FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),
new Configuration());
//2、获取hdfs的输入流
FSDataInputStream inputStream=fileSystem.open(new Path("/dir1/hello.txt"));
//3、获取本地路径的输出流
FileOutputStream outputStream=new FileOutputStream("D://hello1.txt");
//4、文件的拷贝
IOUtils.copy(inputStream,outputStream);
//5、关闭
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
fileSystem.close();
}
/*
文件的下载 方法2
*/
@Test
public void downloadFile2() throws URISyntaxException, IOException, InterruptedException {
//1、获取 FileSystem实例
//FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),new Configuration());
//如果读写权限不够,伪装成root
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),new Configuration(),"root");
//2、调用方法,实现下载
fileSystem.copyToLocalFile(new Path("/dir1/hello.txt"),new Path("D://hello2.txt"));
//3、关闭
fileSystem.close();
}
⑤HDFS文件上传
/*
文件的上传
*/
@Test
public void uploadFile() throws URISyntaxException, IOException {
//1、获取 FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),
new Configuration());
//2、调用方法实现上传
fileSystem.copyFromLocalFile(new Path("D://test.txt"),new Path("/dir1"));
//3、关闭
fileSystem.close();
}
⑥小文件合并
由于 Hadoop 擅长存储大文件,因为大文件的元数据信息比较少,如果 Hadoop 集群当中有大 量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的 内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理
cd /export/servers
hdfs dfs -getmerge /config/*.xml ./hello.xml #将很多的 hdfs 文件合并成一个大文件下载到本地
/*
小文件的合并 然后上传
*/
@Test
public void mergeFile() throws URISyntaxException, IOException, InterruptedException {
//1:获取FileSystem(分布式文件系统)
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),
new Configuration(),"root");
//2:获取hdfs大文件的输出流
FSDataOutputStream outputStream = fileSystem.create(new Path("/big_txt.txt"));
//3:获取一个本地文件系统
LocalFileSystem localFileSystem=FileSystem.getLocal(new Configuration());
//4:获取本地文件夹下所有文件详情
FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("D:\\input"));
//5::遍历每个文件,获取每个文件的输入流
for (FileStatus fileStatus:fileStatuses){
FSDataInputStream inputStream = localFileSystem.open(fileStatus.getPath());
//6:将小文件的数据复制到大文件
IOUtils.copy(inputStream,outputStream);
IOUtils.closeQuietly(inputStream);
}
//7:关闭流
IOUtils.closeQuietly(outputStream);
fileSystem.close();
localFileSystem.close();
}
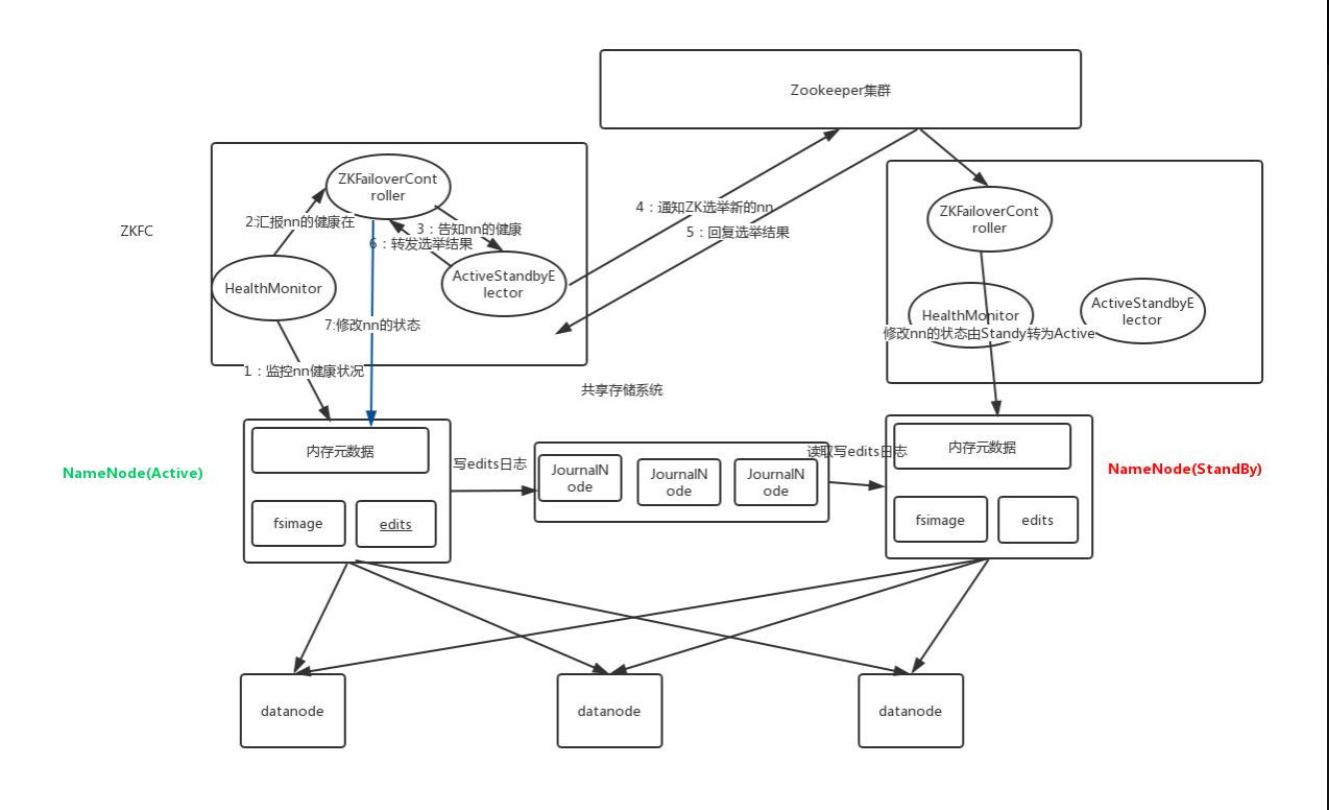
3、HDFS的高可用机制
在Hadoop 中,NameNode 所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由NameNode 来管理,NameNode的可用性直接决定了Hadoop 的可用性,一旦NameNode进程不能工作了,就会影响整个集群的正常使用。
在典型的HA集群中,两台独立的机器被配置为NameNode。在工作集群中,NameNode机器中的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端操作,而Standby充当从服务器。Standby机器保持足够的状态以提供快速故障切换(如果需要)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号