Python爬取招聘网信息
1、数据来源:职友集
2、代码


import requests import openpyxl import time from bs4 import BeautifulSoup #用于解析和提取网页数据的 lst=[]#列表 def send_request(id,page): url = 'https://www.jobui.com/company/{0}/jobs/p{1}/'.format(id,page) headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'} # 创建头部信息 resp = requests.get(url, headers=headers) return resp.text #进行数据的提取 def parse_html(html): bs=BeautifulSoup(html,'html.parser') #得到Bea--的对象了 job_lst=bs.find_all('div',class_='c-job-list')#因为class是关键字,所以加一个下划线 #print(job_lst) for item in job_lst: #分别遍历每一个职位数据 name=item.find('h3').text#职位的名称 div_tag=item.find('div',class_='job-desc') #print(div_tag) span_tag=div_tag.find_all('span') #print(span_tag[0].text) url=item.find('a',class_='job-name')['href']#提取class样式为job-name的a标签,获取属性href的值 lst.append([name,span_tag[0].text,span_tag[1].text,'https://www.jobui.com'+url]) #存储excel def save(lst): wk = openpyxl.Workbook() sheet = wk.active for item in lst: sheet.append(item) wk.save('招聘信息.xlsx') #启动爬虫程序 def start(id,pages): for page in range(1,pages+1): resp_data=send_request(id,page) parse_html(resp_data) time.sleep(2) save(lst) if __name__=='__main__': id='10375749' pages=1 start(id,pages)
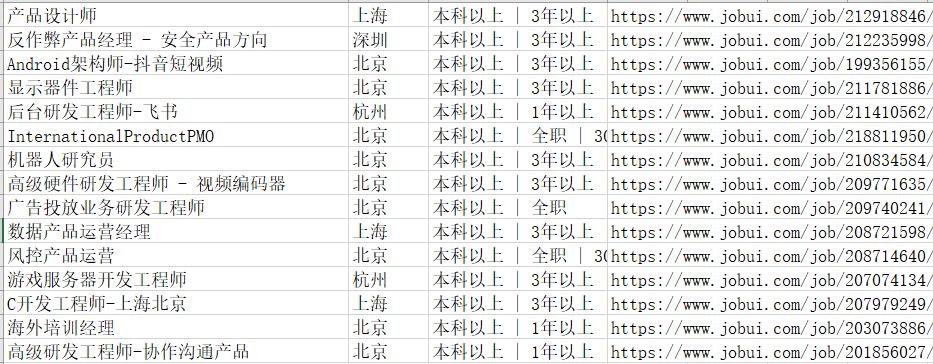
3、结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号