结对第二次—文献摘要热词统计及进阶需求
结对第二次—文献摘要热词统计及进阶需求
作业描述###
作业所属课程:软件工程1619|W(福州大学)
作业要求:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600111|221600138
作业目的:学习团队协作,提高合作编程的能力,培养良好的代码风格
结对同学及此次作业相关信息
结对同学:221600138
本次作业:第二次结对作业
(一开始不知道github的用法,自己建了一个项目,以下贴出的记录是旧项目的)
Github旧项目地址:221600111&221600138
Github提交作业的项目地址:221600111&221600138
Github代码签入记录图:

由于开发过程中Github网站经常上不去,所以必要时我们会用QQ互传文件,所以Github上的代码记录仅作参考
分工:221600111(队友1)负责文件部分、统计热词,221600138(队友2)负责统计行数字符树及单元测试;功能的实现我们有线上线下互相讲解及合作实现部分功能。
PSP表格###
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 300 | 450 |
| Development | 开发 | 150 | 300 |
| • Analysis | • 需求分析 (包括学习新技术) | 20 | 35 |
| • Design Spec | • 生成设计文档 | ||
| • Design Review | • 设计复审 | ||
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 35 | 20 |
| • Design | • 具体设计 | 30 | 50 |
| • Coding | • 具体编码 | 100 | 300 |
| • Code Review | • 代码复审 | 20 | 105 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 20 | 55 |
| Reporting | 报告 | 100 | 120 |
| • Test Report | • 测试报告 | ||
| • Size Measurement | • 计算工作量 | ||
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | ||
| 合计 | 795 | 1465 |
解题思路###
刚开始拿到题目时,我们在进行讨论时并没有对这次作业有更深入的理解,仅仅是觉得可以用java来完成这次作业,于是在做题之前有专门去看了一些有关java的一些方法,但是在真正的进行编码时,才发现并不是这样,这其中的很多功能并不是用单个函数或类就可以实现的,而且在对有效行、单词频数以及单词在字典中的先后顺序进行输出时,我们出现了不少的错误,在改正的时候,中间发现了不少有关有效行的判断的错误,比如:在仅对“\r\n”进行判断的时候很容易将多个只含换行符或含有多个空白字符的无效行计入有效行中,从而使得有效行的数目判断错误,中间有在网络上面进行相应错误、方法的查找。单词频率统计最开始用数组解决,经思考讨论后最终用字符树解决。
设计实现过程###
在设计实现过程,开始我们将文件的处理代码先写在主函数中,再从中逐字符调用处理函数,在实现所有处理功能后再改变整个代码的结构,即功能拆分成如题目要求的API。其中对于所得的单词的处理上,在队友2的想法中是直接用数组将所有的被判断为是单词的字符串全部存储在一个字符串数组中同时用另一个整型数组对每个单词的词频进行记录,并且在后面添加一些排序的函数以及调用字符串在字典中先后顺序的方法对整型数组以及相对应的字符串数组中的所有的单词进行排序。这其中又有几个相应的函数;部分关键函数是需要画出流程图的;
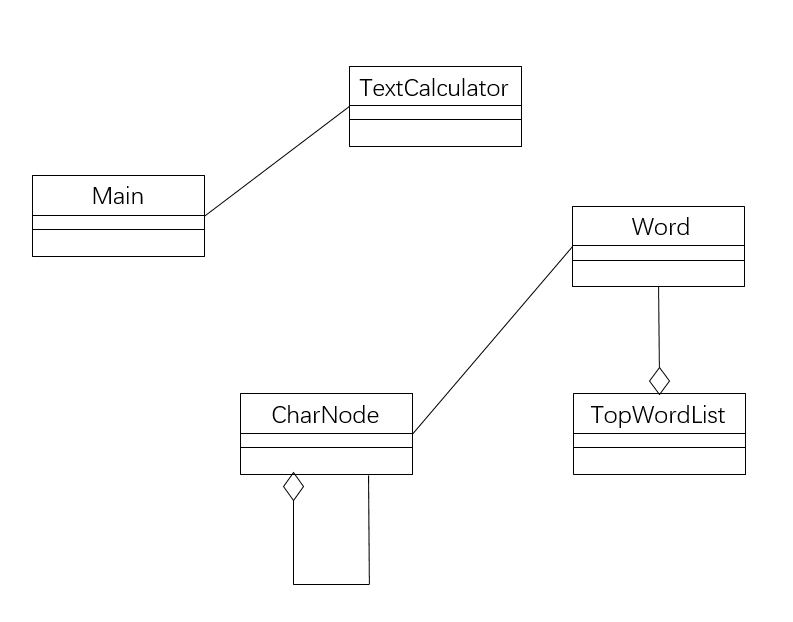
这是类关系图:
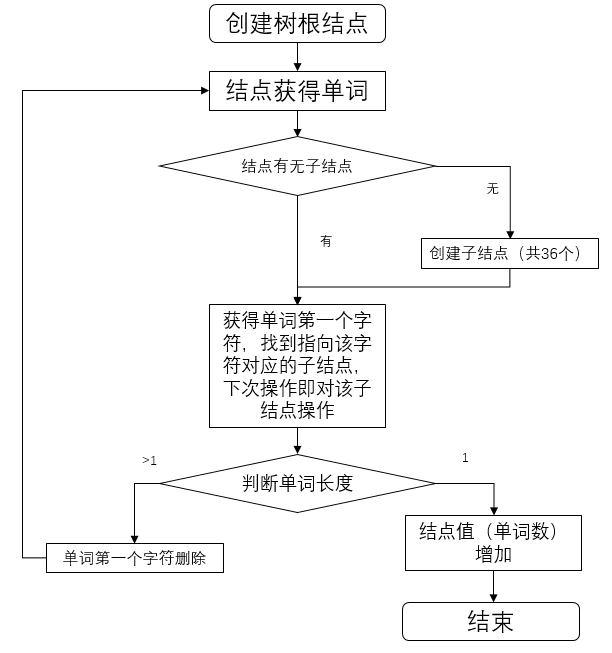
这是计算单词树、计算行数的流程图,它们的说明在上下文有提及这里不过多解释
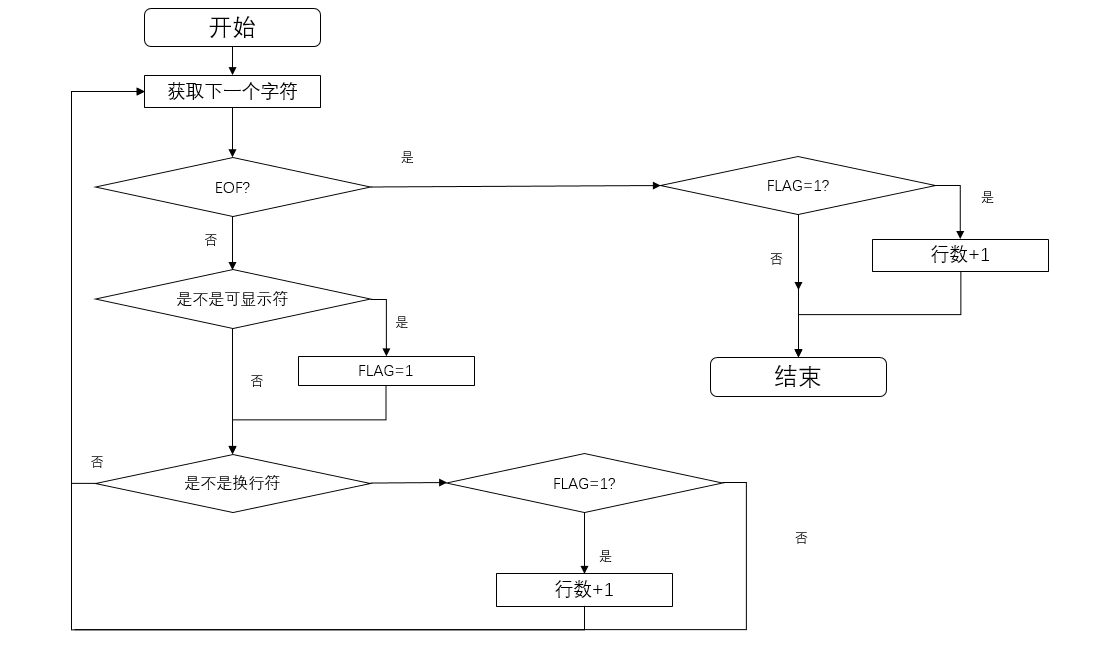
改进思路###
在改进程序的性能上我们大约花了将近一天的时间,我们先是通过将主体架构的文件输入输出代码编写后,再对其他的方法和函数进行编写。在所有功能都实现了之后,我们首先在原来思想的基础上,回顾了上面已经编写的代码,发现上面已经编写的代码有很多的冗余的部分,而且用字符串数组以及整型数组分别存储单词以及单词出现的频率,这中间的代码量并不友好,所以最后根据队友1的想法,他创建了一个树,在每读入一个单词的时候就将这棵树增加一个分支,同时将上面所有的代码的冗余部分删除。
我们在进行编程的时候,一开始并未对这一部分有太多的想法,只是说如果在读取文件中的字符是出现了“\r\n”这几个字符的时候对记录有效行的静态变量(下面统一为rowCount)进行+1运算,但后来发现,这样做会将无效行也统计在内,于是我们有改变思路:在其中加入一个判断,只要“\r\n”的前一个字符或者是后一个字符(主要看怎么进行“\r\n”的判断)是非空白字符就将rowCount增加1,但这样的代码却导致了如果在文件中的某一行的最后一个字符(“\r\n”前一个字符)或某一行的前面的字符(“\r\n”后一个字符)出现了空白字符,那么即使这一行是有效行,程序也不会将这一行视作有效行;最后我们用了一个布尔类型的静态变量(后面记作rowFlag),将其初始化为false,在每次的读取字符时只要出现了非空字符,就将rowFlag设置为true,并在对有效行进行判断时将这个条件加入--即只要rowFlag为true且出现了字符“\r\n”则将rowCount加1,同时将rowFlag设置为false,这样就解决了我们在统计有效行时出现的一系列问题。
当然在最后的接口封装阶段,我们为了符合作业的要求,将所有的实现的函数以及类都独立出来,但因为多次读入了文件内容,这中间整个程序的运行时间却是大大增加了,也就是说我们的改进虽然更加的符合了作业要求,但同时也极大的消耗了原本应该节省的时间。
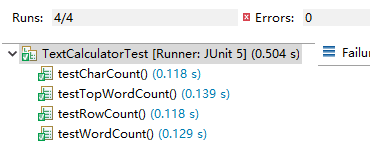
我们找了很久没有发现合适的性能测试工具,JAVA课程也没有学过所以性能测试部分使用Junit的结果代替一下
这是Junit分析一只测试数据的截图,可以看到计算字符和计算行的时间相同,毕竟计算行就是多了两句代码,性能自然损耗不大,但将两个功能拆分成单独API导致时间损耗了一倍;单词统计因为建树时间更长,热词统计因为建完树还要遍历导致时间最长,在预料之中;时间主要是因为读取文件损耗的。
关键代码###
private static class charNode{
private char value;
private charNode[] nextChar;
private int count=0;
public void nextCharInit()
{
nextChar=new charNode[36];
for(int i=0;i<26;i++) {
nextChar[i+10]=new charNode('a'+i);
}
for(int i=0;i<10;i++) {
nextChar[i]=new charNode('0'+i);
}
}
public void generateTree(String word) {
if(nextChar==null) {
nextCharInit();
}
if(word.length()==1) {
nextChar[getNextCharIndex(word.charAt(0))].plus();
}
else {
nextChar[getNextCharIndex(word.charAt(0))].generateTree(word.substring(1));
}
}
思路:这段代码主要是用来创建树的,前面也有说过,我们的思路是通过创建一棵树,再将已经判断是单词的那些字符串全部添加至树的分支中去并且将每个单词的频数也通过树中的结点进行存储,此外再在这棵树外创建一个存储热词的一个数组,能够在遍历整棵树的时候将每个有意义的单词都放入热词的存储空间中并且在存入之前就调用相应的函数(插入排序)将其词频与下一个被从树中遍历的单词的频数进行对比,若其词频大,则不进行位置的交换,否则对其进行对换。树的儿子结点按ascii码从小到大排列,这样在前序遍历时不需要比较字典序,因为先遍历到的即是字典序排前的单词。
单元测试代码###
class TextCalculatorTest {
static final int expectedCharCount=102;
static final int expectedRowCount=2;
static final int expectedWordCount=2;
static final String expectedTopWordCount="<abcdefghijklmnopqrstuvwxyz>: 2";
@Test
void testCharCount() {
File inFile=new File("input.txt");
assertEquals(expectedCharCount, TextCalculator.charCount(inFile));
}
@Test
void testRowCount() {
File inFile=new File("input.txt");
assertEquals(expectedRowCount, TextCalculator.rowCount(inFile));
}
@Test
void testWordCount() {
File inFile=new File("input.txt");
assertEquals(expectedWordCount, TextCalculator.wordCount(inFile));
}
@Test
void testTopWordCount() {
File inFile=new File("input.txt");
String actualTopWordCount=TextCalculator.topWordCount(inFile);
assertEquals(expectedTopWordCount.length(),actualTopWordCount.length());
for(int i=0;i<expectedTopWordCount.length();i++)
assertEquals(expectedTopWordCount.charAt(i),actualTopWordCount.charAt(i));
}
}
说明:测试的函数有字符统计,行统计,单词统计,热词统计四个
构造测试数据思路:测试数据,一部分由我们参考例子自行制作,自己统计里面的单词等与结果比较,在基础的测试都完成后,一部分数据来自网络随手复制英文段落,在文本里多复制高频单词,使用word工具统计高频单词数,确保词频统计在大的数据处理需求下结果正确且性能达标。
评价###
结对困难:刚开始做题时并未与队友有过交流,只是各自先看题目然后做题,后来进行交流时才发现各自都有很多不同的想法;
解决方法:后面在做此次作业的时候并未各自单独做,而是通过qq一直在进行交流以及文件的互传
队友值得学习的地方:队友善于发现程序问题,针对我的程序(BUG)能够提出质疑和提供改进思路,省去了很多不必要的解决问题的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号