


爬虫介绍
爬虫简介:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。
爬虫处理图效果
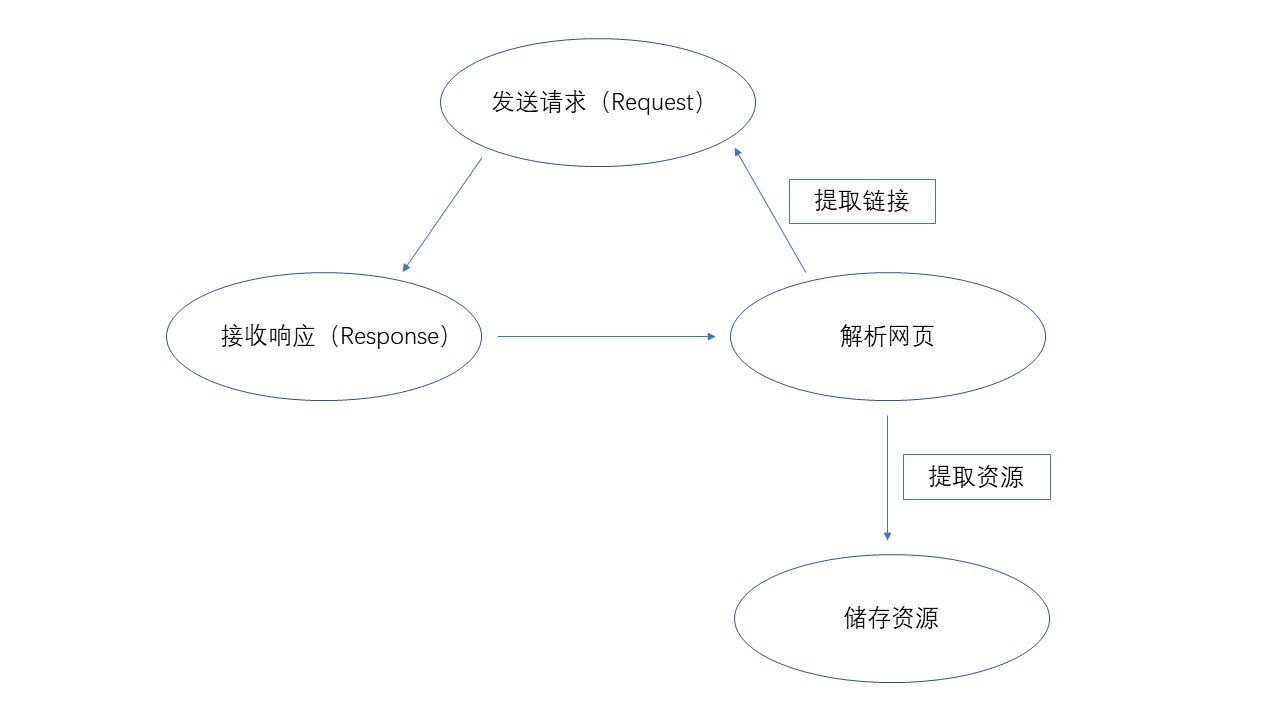
1.获取网页
通过上图知道 使用request发送get请求,获取网页的源代码。
import requests respones = requests.get('https://www.cnblogs.com/Moodsfeelings/') print(r.text)
这里还要安装request库
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
2.用BeautifulSoup解析数据
from bs4 import BeautifulSoup#导入BeautifulSoup soup = BeautifulSoup(r,'lxml')#解析网页数据 pattern = soup.find_all('a','postTitle2')#寻找数据 for item in pattern:#用for循环打印 print(item.string)
这里还要用两个库
pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
3.用txt文档保存数据
with open('file.txt','a',encoding = 'utf-8')as f: for item in pattern: f.write(item.string)
那么我们的基本爬虫差不多就完成了,下次再见!
