
数据预处理
- 数据写入:
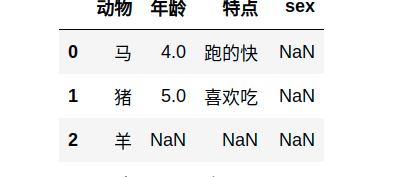
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file1= os.path.join('..', 'data', 'animals.csv')
with open(data_file1,'w',encoding='utf8') as f: #open文件名参数不要打引号
f.write('动物,年龄,特点,sex\n')
f.write('马,4,跑的快,NA\n')
f.write('猪,5,喜欢吃,NA\n')
data1= pd.read_csv(data_file1)
data1
- 列(特征)标签获取:
aa=data1.columns
aa[1],aa
('年龄', Index(['动物', '年龄', '特点', 'sex'], dtype='object'))
- 缺失值分析:
- 各变量基本非缺失样本统计:
data1.info() - 具体每一个变量非缺失样本统计:
data1['动物'].isna().sum() - 查看各个变量具体缺失:
data1.isna().sum()
- 删除列变量:
data2=data1.drop(label,axis=1) #axis=1,按列删除
- 删除多个变量举例:
data2=data1.drop(data1[['sex','特点']],axis=1) - 删除一个变量举例:
data3=data1.drop('特点',axis=1)
- dataframe转化为tensor:
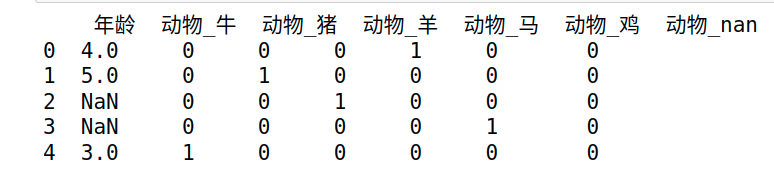
- 分类变量编码:
data3 = pd.get_dummies(data3, dummy_na=True)
print(data3)
#整体一个data3一起进行,而不需要把分类变量编码出来再进行编码
![]()
- 转化为张量:
y = torch.tensor(data3.values)
y
``
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号