201971010231-毛玉贤 实验三 结对项目—《{0-1}KP 实例数据集算法实验平台》项目报告
实验三 {0-1}KP 实例数据集算法实验平台
一、实验目的与要求
| 项目 | |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs |
| 本次作业要求链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs/homework/12560 |
| 我的课程学习目标 | (1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。 (2)掌握Github协作开发软件的操作方法。 |
| 本次作业在哪些方面 帮助我实现学习目标 |
(1)老师的帮助以及作业要求文档中清晰的指导步骤让人一目了然。 (2)PSP流程的使用,使我更加合理的分配时间,执行任务计划。 (3)实验清晰的功能需求,让我更加合理的结构化的设计了本次项目的界面以及函数的封装等等。 |
| 结对方学号-姓名 | |
| 结对方本次博客作业链接 | https://www.cnblogs.com/20010201jmm/p/16080075.html |
| 本项目Github的仓库链接地址 | https://github.com/Mao-cpu/Algrithm_platform |
二、实验内容与步骤
1、任务一:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念
(1)代码风格规范
- 代码风格规范的原则是:简单、易读、无二义性
| 风格 | |
|---|---|
| 缩进 | 4个空格,距离从可读性来说,正好 |
| 行宽 | 以前规定的80字符太小,现在可以限定为字符 |
| 括号 | 用括号清楚的表示逻辑优先级 |
| 断行与空白的{}行 | 每个“{”,“}”都独占一行,结构更清晰 |
| 分行 | 不要把多条语句、多个变量定义放在一行 |
| 命名 | (1)在变量名中不要提到类型或其他语法方面的描述 (2)避免过多的描述 (3)如果信息可从上下文中得到,则此类信息不必写入变量名中 (4)避免可要可不要的修饰词 |
| 下划线 | 分隔变量名字中的作用域标注和变量的语义 |
| 大小写 | 多个单词组成变量名,大小写适配得到,清晰易读 |
| 注释 | 解释程序做什么,为什么这样做 |
(2)代码设计规范
- 代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计,模块之间的关系,设计模式等方面,这里主要讨论通用的原则
| 风格 | |
|---|---|
| 函数 | 只做一件事,并且要做好 |
| goto | 函数最好有单一出口,为达目的,可使用goto |
| 错误处理(参数处理) | 在Debug版本中,所有参数都要验证其正确性 |
| 错误处理(断言) | 检验正确性时,可以使用断言 |
| 类 | (1)使用类来封装面向对象的概念和多态 (2)避免传递类型实体的值,应该用指针 (3)对于有显式的构造和析构函数的类,不要创建全局的实体 (4)仅在必要时,使用“类” |
| class vs. struct | 如果只是数据的封装,用struct即可 |
| 公共/保护/私有成员 | 按照此顺序来说明类中的成员 |
| 数据成员 | (1)数据类型的成员用m_name说明 (2)不要使用公共的数据成员,要用inline访问函数,这样才可兼顾封装和效率 |
| 虚函数 | (1)实现多态 (2)仅在很有必要时,使用虚函数 (3)若一类型实现多态,在基类中的析构函数应该是虚函数 |
| 构造函数 | (1)不做复杂操作 (2)不应返回错误 |
| new 和 delete | (1)尽量实现自己的new/delete (2)检查new的返回值 (3)释放指针时不用检查NULL |
| 运算符 | (1)无需自定义操作符 (2)不要做标准语义之外的动作 (3)运算符的实现必须非常有效率 (4)当打不定主意时,用成员函数 |
| 异常 | (1)不要将异常作为处理程序主要流程 (2)了解异常及处理异常的花销 (3)使用时,注意在什么地方清理数据 (4)异常不能跨过DLL或进程的边界来传递信息 |
| 类型继承 | (1)仅在必要时使用 (2)用const标注只读的参数 (3)用const标注不改变数据的函数 |
(3)代码复审
-
正确定义:看代码是否在代码规范的框架正确地解决了问题。
-
复审形式:

-
基本手段:同伴复审
-
复审目的:
- ①找出代码错误
- ②发现逻辑错误,程序可以编译通过,但逻辑是错的
- ③发现算法错误,如使用的算法不够优化
- ④发现潜在错误和回归性错误
- ⑤发现可能需要改进的地方
- ⑥互相教育开发人员,传授经验
(4)结对编程概念
- 代码复审可以发现很多问题,有很好的效果,如果我们每时每刻都处于在代码复审的状态,可能会更好。极限编程正是这一思想的体现——将一些卓有成效的开发方法用到极致。
- 结对编程的诸多好处:
- ①在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作解决问题的能力更强。
- ②对于开发人员自身来说,结对工作,信心大增,高质量的产出带来高满足感。
- ③在企业管理层次上,结对能更有效的交流,相互学习传递经验,分享知识,应对人员流动。
2、任务二:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
| 博客链接 | |
|---|---|
| 201971010115-蒋敏敏 | ①博文结构:本篇博客层次清晰、色彩明丽、让人眼前一亮,整体排版干净整洁,一点也不拖泥带水,博主在细节的把控上则显得游刃有余,用颜色亮条来突出重点,与博客背景浑然一体,给人以视觉上的舒适感受。在博主的配色方面,采用少女粉紫搭配,尽显青春活力,但在此处依旧提出一点小的建议,供博主采纳,紫色深度浅些,粉色加重或许会更加好看!(仅个人意见!) ②博文内容:本篇博客整体内容较为充实,在内容的分配上也是详略得当,张弛有度。尤其在总结概述《构建之法》第一二章当中,博主按章节总结的内容,更让我感受到了博主的用心以及积极学习的态度,人无完人,本篇博客美中不足的地方在于,没有介绍实现三种算法的思想、没有事后的经验分享环节以及将文件代码上传至github的过程分享等,期待博主更新,分享经验! ③博文结构与PSP中“任务内容”列的关系:可以看出博文整体结构基本对应了PSP中的“任务内容”,在进行计划分析后,也得出了需求分析,生产设计文档,有自己的编码规范风格,有具体的设计,以及编码、测试、修改代码(完善功能)、提交代码、提交博文、事后总结等过程。 ④PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究:博主计划共完成需要的时间为10min,而实际完成需要的时间为8分钟,我猜想是由于实验二的实验要求老师已经详尽给出,所以在需求设计,功能分析、语言的选择等等计划方面、能够快速做出决定,因此节约了很多时间,来完成后期任务!不知道博主是否赞同我的猜想呢? |
(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
-
2.2.1 克隆项目:
-
结对方Github项目仓库链接:https://github.com/1813964315/src1
- 导入pycharm运行

-
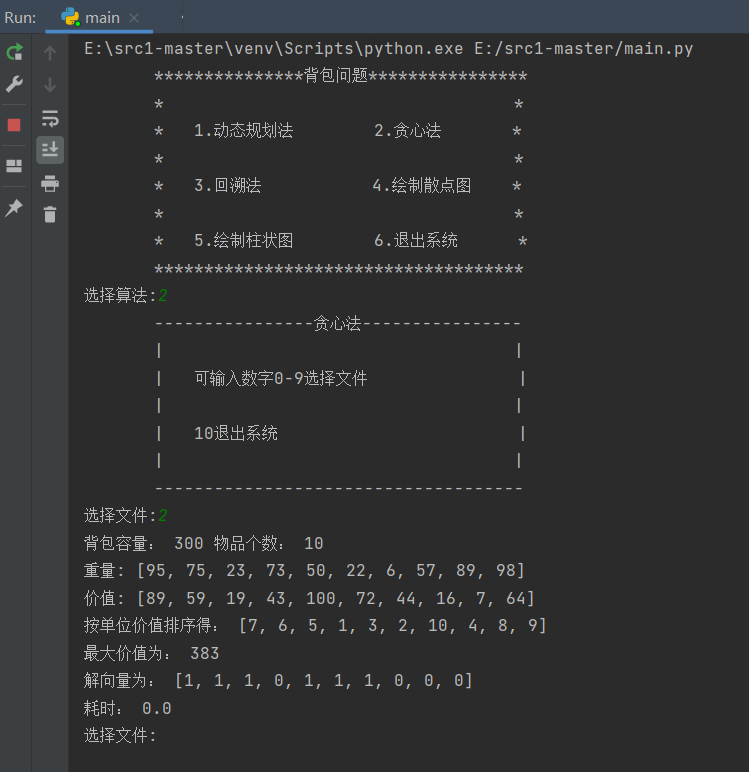
2.2.2 运行测试:
-
测试贪心算法,数据2求解情况(其他算法与数据也均测试,在此处不多做展示):
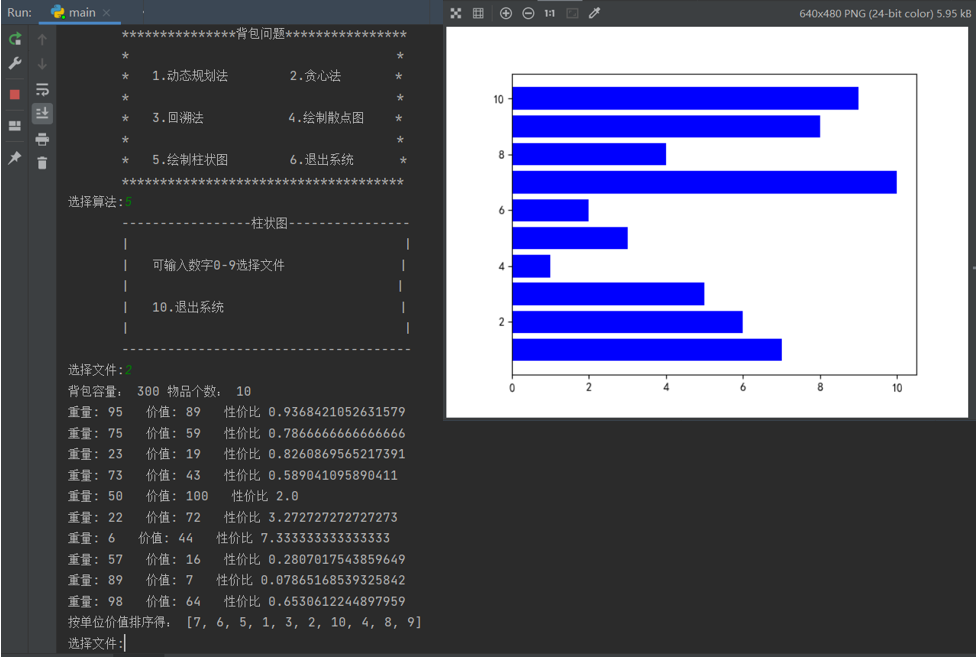
- 退回上级列表,选择绘制数据2散点图:

- 退回上级列表,选择绘制数据2柱形图:
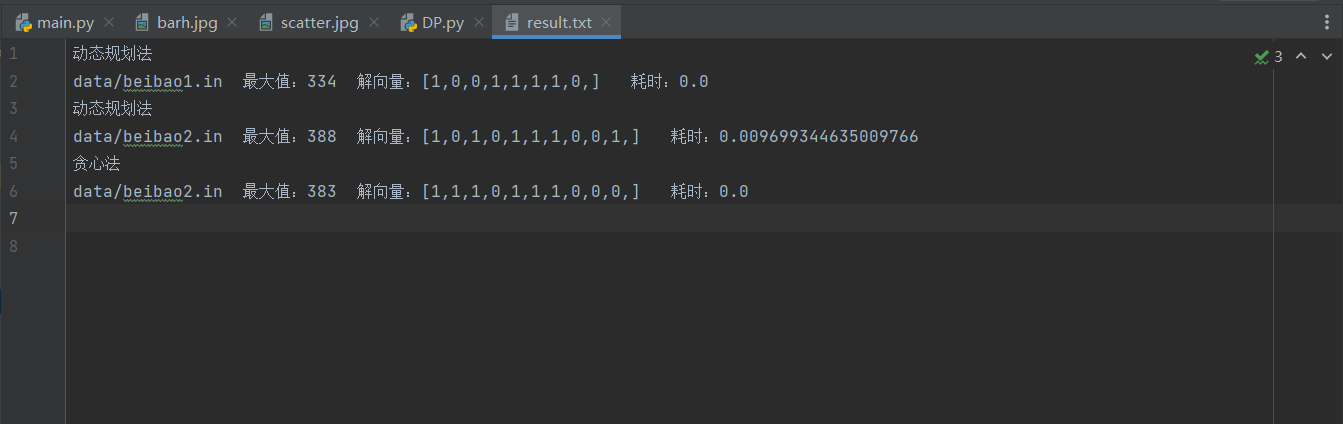
- 保存贪心法求解数据2的运算结果:
- 保存得到的散点图、柱形图:
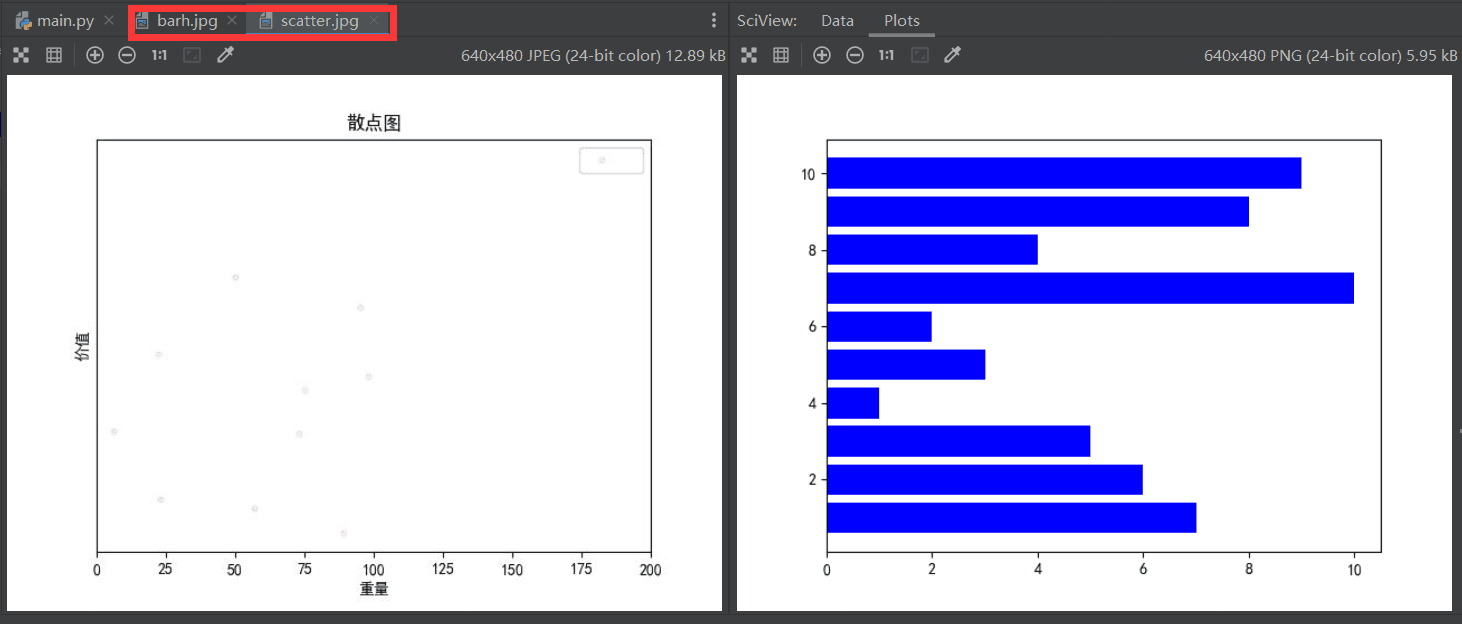
- 2.2.3 测试总结:
克隆项目,经过一段时间的测试,以及以上部分测试截图可知:在代码规范方面也完全符合他所要求的代码规范说明;在功能测试上,蒋敏敏同学不仅完成了实验二的基本要求,例如读入文件,数据排序,数据选择,算法求解,散点图绘制等基本功能外,还实现了柱状图的绘制,并且实时保存最新的柱状图与散点图于src文件中,可以说是百分百完成了老师编程上的要求并附加了额外功能;在代码结构上:结构快划分非常清晰,代码复用性强,注释详略得当,单元测试十分方便。
- 2.2.4 代码复审核查表
| 内容 | |
|---|---|
| 概要部分 | |
| 代码符合需求和规格说明么? | 符合 |
| 代码设计是否考虑周全? | 是 |
| 代码可读性如何? | 结构化清晰,可读性好 |
| 代码容易维护么? | 容易复用与维护 |
| 代码的每一行都执行并检查过了吗? | 是 |
| 设计规范部分 | |
| 设计是否遵从已知的设计模式或项目中常用的模式? | 是 |
| 有没有硬编码或字符串/数字等存在? | 没有 |
| 代码有没有依赖于某一平台,是否会影响将来的移植? | 没有,不影响移植 |
| 在本项目中是否存在类似的功能可以通过调用而不用全部重新实现? | 没有 |
| 有没有无用的代码可以清除? | 没有 |
| 代码规范部分 | |
| 修改的部分符合代码标准和风格么? | 符合 |
| 具体代码部分 | |
| 对于调用的外部函数,是否检查了返回值或处理了异常? | 已检查并处理 |
| 参数传递有无错误,字符串的长度是字节的长度还是字符的长度,是从0开始计数还是从1开始计数 | 没有 |
| 边界条件是如何处理的?switch语句和default分支是如何处理的?循环有没有可能出现死循环? | 没有使用switch语句,不会出现死循环 |
| 对资源的利用,有无可能存在资源泄露?有没有优化的空间? | 没有资源泄露,存在优化空间 |
| 效能 | |
| 代码的效能如何?最坏的情况是怎么样的? | 效能较好,最坏情况:有时算法求解时间微长 |
| 代码中,特别是循环中是否有明显可优化的部分? | 无 |
| 对于系统和网络的调用是否会超时?如何处理? | 没有对网络进行调用,没有超时 |
| 可读性 | |
| 代码可读性如何?有没有足够的注释? | 注释足够,可读性强 |
| 可测试性 | |
| 代码是否需要更新或创建新的单元测试? | 不需要,代码结构性强,可以直接单元测试 |
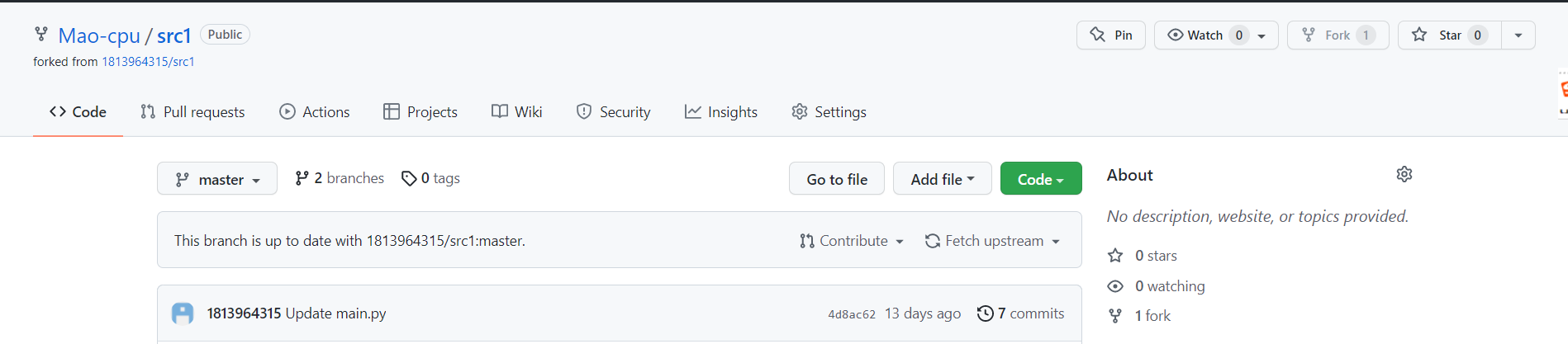
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
- 2.3.1 fork结对方的项目到自己的github
-
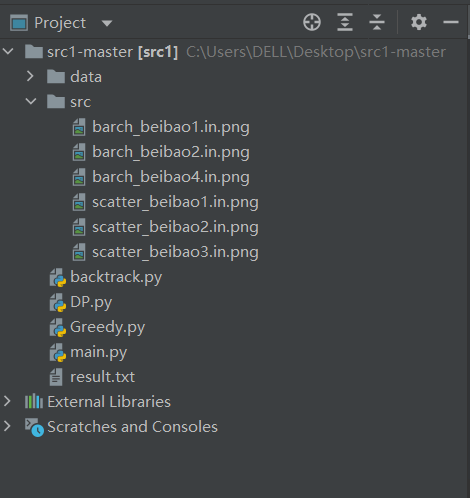
2.3.2 修改结对方代码
-
优化功能:将程序产生的所有柱形图、散点图均保存到一个文件夹里(原来功能:只保存实时的即最新获取到的散点图、柱形图),修改完后,可将所有产生的图片放入src文件夹中
-
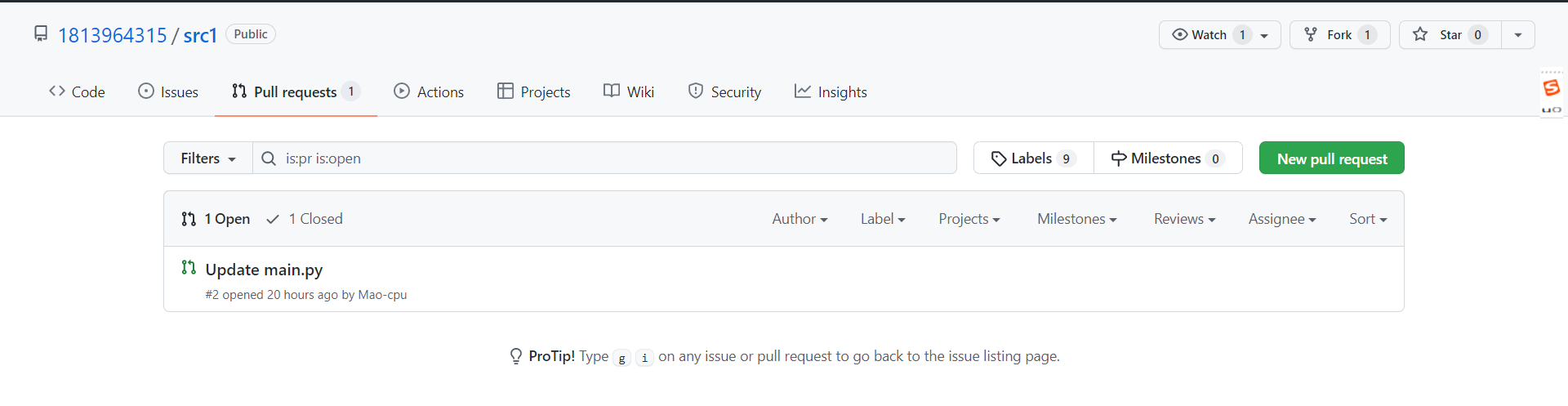
2.3.3 修改完成,请求合并
-
修改完成后,发起pull request给原仓库,原仓库review这个修改

- 如果是正确的话,就会merge到他自己的项目中
3、任务三:采用两人结对编程方式,设计开发一款{0-1}KP 实例数据集算法实验平台
(1)问题定义
- 采用两人结对编程方式,设计开发一款{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
- (1)平台基础功能:实验二 任务3;
- (2){0-1}KP 实例数据集需存储在数据库;
- (3)平台可动态嵌入任何一个有效的{0-1}KP 实例求解算法,并保存算法实验日志数据;
- (4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
- (5)查阅资料,设计遗传算法求解{0-1}KP,并利用此算法测试要求(3);
- (6)附加功能:除(1)-(5)外的任意有效平台功能实现。
(2)可行性分析
- 经济可行性分析:完成该项目,软硬件成本几乎为0,只是耗费了人力,并非盈利性平台所以不记收益;
- 技术可行性:该项目的界面搭建可使用python GUI中tkinter库等,有丰富的组件可供使用,数据库可使用pyhcarm中的SQLite3,用户使用门槛低,产品环境依赖性低,技术要求完全可实现;
- 操作可行性:平台界面简洁大气,让人一目了然,易操作、易上手、用户体验较好。
(3)需求分析陈述
- Who 为谁设计,用户是谁?
- 设计开发一款{0-1}KP 实例数据集算法实验平台 ,提供给使用不同方法求解0-1背包,且处理多组数据的用户;
- What 需要解决如下问题?
- GUI界面
- 人机交互界面要求为GUI界面(python GUI实现),以便用户使用;
- 存储数据库
- 将实验二的数据文件0-9保存到数据库中;
- 导入数据
- 平台可动态嵌入任何一个有效的{0-1}KP 实例求解算法,即动态选择任意有效的数据;
- 将保存到数据库datafile.db中,并显示到平台界面上;
- 算法求解
- 选择任意数据文件(数据库中保存的),任意算法求出最大价值、解向量、以及运行时间,结果保存到result.txt文件中;
- 算法有:动态规划、贪心、回溯、遗传,实现求解数据集,并在平台界面显示结果;
- 绘制图形
- 绘制所选数据文件的散点图、柱形图;
- 将所绘制的图片保存到picture文件夹中;
- 在平台界面显示所绘制的图片;
- 排序
- 将背包按单位重量价值比排序,同时显示结果到平台界面;
- 排序方式:递增、递减;
- 日志记录
- 进入平台界面后,每次执行的操作都会被记录下来,并保存到数据库中;
- GUI界面
- Why 为什么解决这些问题?
- 根据题目要求,实现完成项目,不仅可以锻炼自己解决问题的能力,还可以主动学习新知识;结对编程,让我们平等的、互补的、高效的,进行软件项目的开发。
(4)软件设计说明
- 总体设计
- 点本次项目软件界面包含的功能有导入数据(任意有效数据文件均从本地导入),算法求解,绘图、排序、日志记录,这五大块功能。每个大模块下,又包含了自己的细分模块,例如:算法求解又分为动态规划、贪心算法、回溯算法、遗传算法,排序模块又分为递增、递减排序。
- 点击图片放大查看更清楚哦!
-
详细设计
-
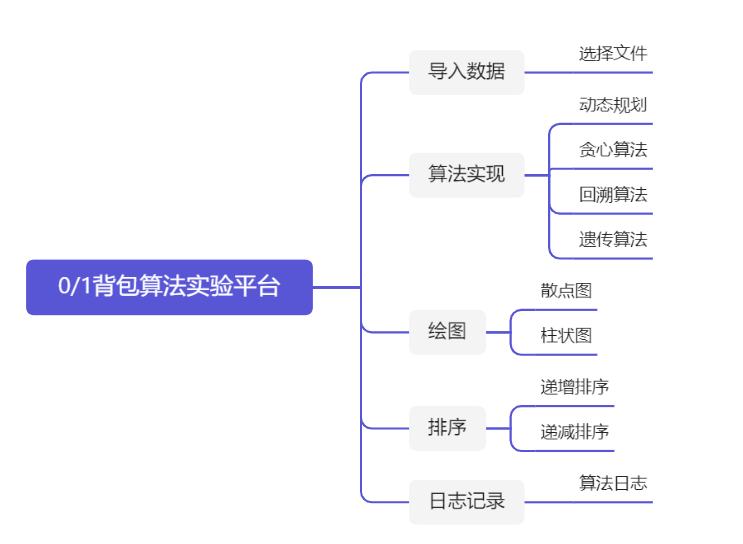
导入数据:
-
算法求解:

-
绘图:

-
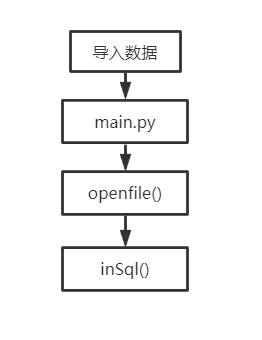
排序:
-
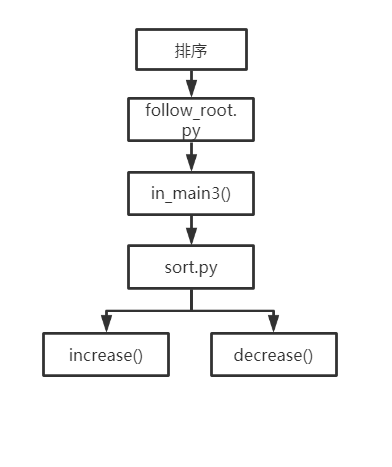
日志记录:
-
(5)软件实现及核心功能代码展示
-
3.5.1 软件实现
-
软件设计工程结构
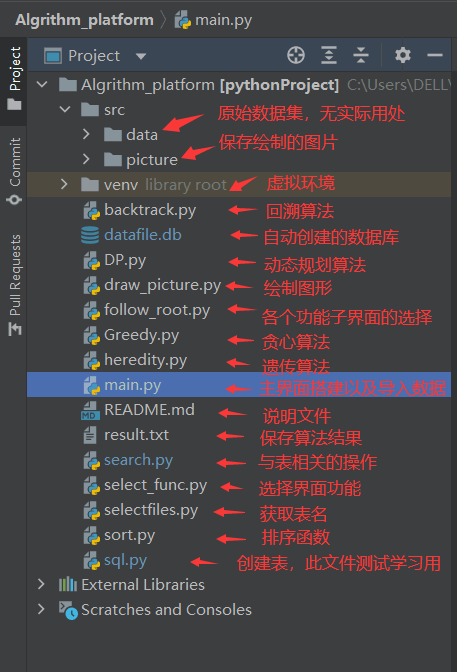
-
系统流程图
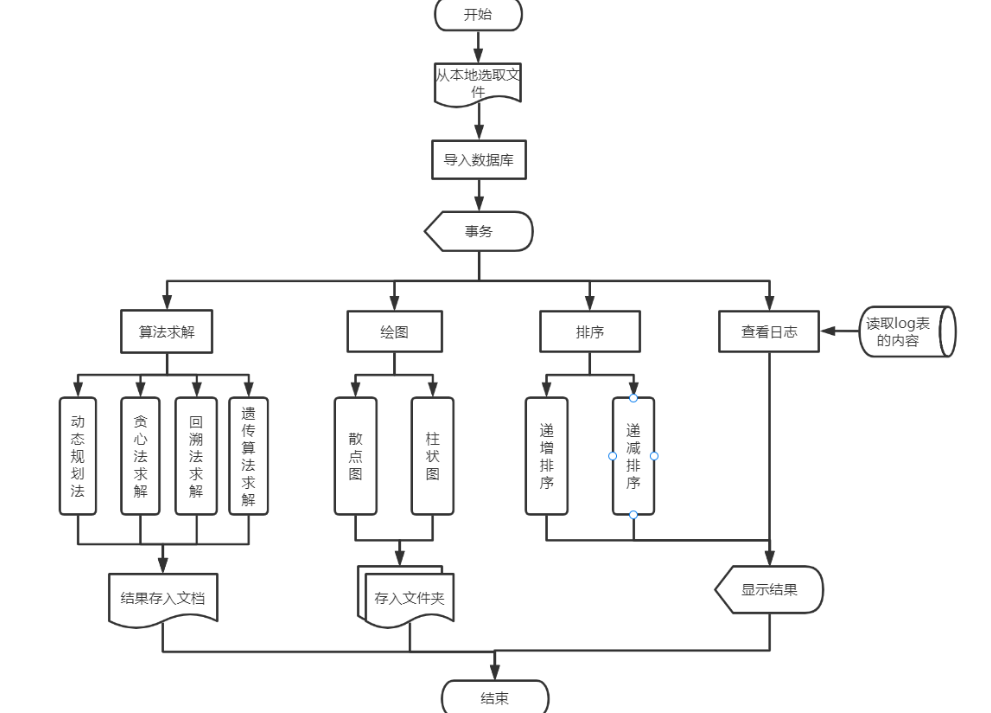
-
主要函数调用关系图
- 本次实验平台界面采用的是python GUI实现,tkinter库中提供了丰富的组件可以使用,数据库使用的是SQLite;
- 在该项目的实现过程中,没有使用类,而是使用了大量的函数,这些函数在不同的.py文件中有逻辑的调用,从而实行项目的整体运行;
- 主要函数功能:
- openfile() :打开所选择的本地文件,显示其内容到平台界面上;
- inSql() :将打开的文件内容保存到数据库中;
- inmain() :用来判断选择、执行四大算法,并将最终结果显示到平台上;
- inmain2() :选择、执行绘图功能,并将所绘制的图像显示到界面上;
- inmain3() :选择、执行排序功能,并将所绘制的图像显示到平台上;
- inmain4() :获取数据库日志表当中的数据,显示日志记录;
- Dp()、Greedy()、Bt()、heredity() :分别实现动规、贪心、回溯、遗传算法,并将结果保存在本地txt文件中(在inmain()中被调用);
- scatter()、barch():实现绘制散点图、柱状图功能,并保存结果到本地src文件夹下面的picture文件夹下(在inmain2()中被调用);
- increase()、decrease() :分别实现数据按单位重量价值递增、递减排序(在inmain3()中被调用);
- log():从数据库log表当中取出数据(在inmain4()中被调用)
- in_log() :将得到的日志记录数据存入数据库log表当中(在各个具体实现功能的函数中被调用);
- 点击图片放大查看更清楚哦!

-
导入数据,连接数据库核心思想
- 当要导入数据时,选择本地文件导入,此时系统会判断数据库中是否存在以该文件命名的表,若不存在,则创建表,并将文件中的数据插入新建的表当中,如果已存在,则将文件数据直接插入到数据库已知表当中。
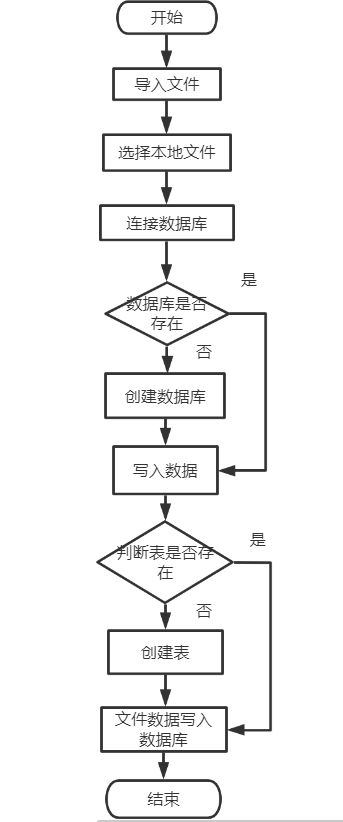
-
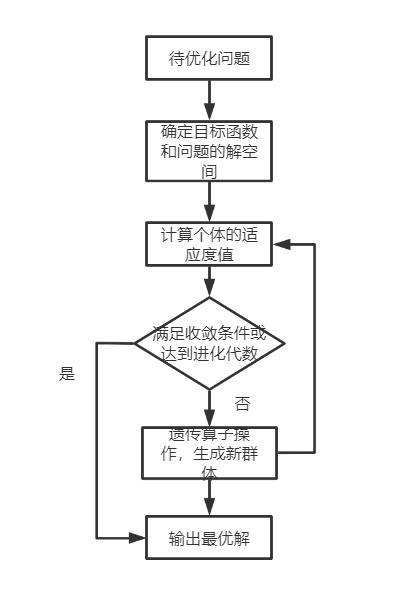
遗传算法设计思想
-
遗传算法是一种基于自然选择和群体遗传机理的搜索算法,它模拟了自然选择和自然遗传过程中的繁殖、杂交和突变现象.再利用遗传算法求解问题时,问题的每一个可能解都被编码成一个“染色体”,即个体,若干个个体构成了群体(所有可能解).在遗传算法开始时,总是随机的产生一些个体(即初始解),根据预定的目标函数对每一个个体进行评估,给出一个适应度值,基于此适应度值,选择一些个体用来产生下一代,选择操作体现了“适者生存”的原理,“好”的个体被用来产生下一代,“坏”的个体则被淘汰,然后选择出来的个体,经过交叉和变异算子进行再组合生成新的一代,这一代的个体由于继承了上一代的一些优良性状,因而在性能上要优于上一代,这样逐步朝着最优解的方向进化.因此,遗传算法可以看成是一个由可行解组成的群体初步进化的过程。
-
利用遗传算法求解问题时,首先要确定问题的目标函数和变量,然后对变量进行编码,这样做主要是因为在遗传算法中,问题的解是用数字串来表示的,而且遗传算子也是直接对串进行操作的.编码方式可以分为二进制编码和实数编码.若用二进制编码表示个体,则二进制数转化为十进制数的解码公式可以为:
-
\[f(b_{i1}, b_{i2}..., b_{il}) = R_i + \frac{T_i -R_i }{2^l - 1}\sum_{j = 1} ^lb_{ij}2^{j-1} \]
-
其中(bi1,bi2,...bil),为某个个体的第i段,每段段长都为l,每个bik都是0或者1,Ti和Ri是第段分量Xi的定义域的两个端点。
-
遗传操作是模拟生物基因的操作,他的任务就是根据个体适应度对其施加一定的操作,从而实现优胜劣汰的进化过程。从优化搜索的角度来看,遗传操作可以使问题的解逐代优化,逼近最优解,遗传操作包括以下三个基本遗传算子:选择、交叉、变异.选择和交叉基本上完成了遗传算法的大部分搜索功能,变异增加了遗传算法找到最优解的能力。
-
选择是指从群体中选择优良个体并淘汰劣质个体的操作。它建立在适应度评估的基础上。适应度越大的个体,被选中上的可能性就越大,他的“子孙”在下一代中的个数就越多,选择出来的个体就被放入配对库中。目前常用的选择方法有轮赌盘方法、最佳个体保留法、期望值法、排序选择法、竞争法、线性标准化法。
-
交叉就是指把两个父代个体的部分结构加以替换重组而生成新的个体的操作,交叉的目的是为了在下一代产生新的个体,通过交叉操作,遗传算法的搜索能力得到了飞跃性的提高。交叉是遗传算法获取优良个体的重要手段。交叉操作是按照一定的交叉概率在匹配库中随机的选取两个个体进行的,交叉位置也是随机的,交叉概率一般取得很大,为0.6~0.9。
-
变异就是以很小的变异概率Pm随机地改变种群中个体的某些基因的值,变异操作的基本过程是:产生一个[0,1]之间的随机数rand,如果rand<Pm,则进行变异操作。变异操作本身是一种局部随机搜索,与选择、交叉算子结合在一起,能够避免由于选择和交叉算子而引起的某些信息永久性丢失,保证了遗传算法的有效性,使遗传算法具有了局部随机搜索能力,同时使得遗传算法能够保持群体的多样性,以防出现未成熟收敛。在变异操作中,变异概率不宜取得过大,如果Pm>0.5,遗传算法就退化为了随机搜索。
-
-
日志记录设计思想
- 此处是在每一个具体执行的算法函数中,使用了time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),获取当前的系统时间,以及原来函数中已知的操作名称 a_name、文件名 s,调用in_log()函数,传入参数,将这些数据都保存在数据库log表中。当用户点击日志记录按钮时,系统会执行inmain4()函数,该函数调用log()(取出数据库log表当中的数据)后,将数据记录显示在界面上。
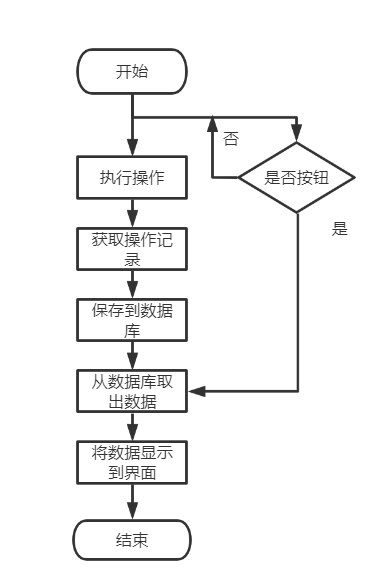
- 3.5.2 项目代码规范说明
| 缩进 | (1)程序块要采用缩进风格编写,缩进的空格数为4个; (2)缩进或者对齐只能使用空格键,不可使用TAB键,使用TAB键需要设置TAB键的空格数目是4格 ; |
| 变量命名 | (1)命名尽量使用英文单词,力求简单清楚; (2)命名规范必须与所使用的系统风格保持一致,并在同一项目中统一; (3)全小写或全大写(可加下划线); |
| 每行最多字符数 | (1)较长的语句(>100 字符)要分成多行书写 )要分成多行书写; |
| 函数最大行数 | (1)函数的规模尽量限制在100 行以内; |
| 函数、类命名 | (1)模块尽量使用小写命名,首字母保持小写,尽量不要用下划线; (2)类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头; (3)函数名一律小写,如有多个单词,用下划线隔开; |
| 常量 | (1)常量使用以下划线分隔的大写命名; |
| 空行规则 | (1)模块级函数和类定义之间空两行; (2)类成员函数之间空一行; |
| 空格规则 | (1)关键字之后要留空格。 const、virtual、inline、case 等关键字之后至少要留一个空格; (2)if、for、while 等关键字之后应留一个空格再跟左括号‘( ’, 以突出关键字; (3)变量名后紧跟逗号,逗号后空格; |
| 注释规则 | (1)“#”号后空一格,段落间用空行分开(同样需要“#”号); (2)不要在文档注释复制函数定义原型, 而是具体描述其具体内容, 解释具体参数和返回值等; |
| 操作符前后空格 | (1)在二元运算符两边各空一格 =, -, +=, ==, >, <, >=, <= 等等。 |
-
3.5.3 核心功能代码
-
选择文件显示数据
def openfile():
filePath = askopenfilename() # 全路径
fileName = os.path.basename(filePath) # 文件名
tab = Frame(master=tabBar)
tabBar.add(tab, text=fileName)
textContainer = Labelframe(tab)
textContainer.pack(expand=YES, fill=BOTH)
tabBar.pack(expand=YES, fill=BOTH)
textArea = Text(master=textContainer)
textArea.pack(side=LEFT, expand=YES, fill=BOTH)
inSql(filePath, fileName, textArea)
time1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 执行该操作的时间
in_log(time1, '导入数据', fileName)
# 右侧滑动条
scrollBar = Scrollbar(master=textContainer)
scrollBar.pack(side=RIGHT, fill=Y)
# 导航条获得文本位置
scrollBar.config(command=textArea.yview)
# 文本获得导航条位置
textArea.config(yscrollcommand=scrollBar.set)
- 文件数据导入数据库
def inSql(filePath, fileName, textArea):
cx = sqlite3.connect('./datafile.db') # 创建数据库,如果数据库已经存在,则链接数据库;如果数据库不存在,则先创建数据库,再链接该数据库。
cu = cx.cursor() # 定义一个游标,以便获得查询对象。
cu.execute('create table if not exists ' + "'" + fileName + "'" + ' (id integer primary key,w integer,v integer )') # 创建表,此处须修改表名
f = open(filePath, mode='r', encoding="utf-8")
list = []
i = 0
for line in f.readlines():
textArea.insert(INSERT, line)
list.append(line.strip().split(' '))
cu.execute('insert into ' + "'" + fileName + "'" + ' values(?,?,?)', (i, list[i][0], list[i][1]))
i += 1
f.close() # 关闭文件
cu.close() # 关闭游标
cx.commit() # 事务提交
cx.close() # 关闭数据库
- 动态规划算法
# 置零,表示初始状态
value = [[0 for j in range(c + 1)] for i in range(n + 1)]
for i in range(1, n+1):
for j in range(1, c+1):
value[i][j] = value[i - 1][j]
# 背包总容量够放当前物体,遍历前一个状态考虑是否置换
if j >= w[i - 1] and value[i][j] < value[i - 1][j - w[i - 1]] + v[i - 1]:
value[i][j] = value[i - 1][j - w[i - 1]] + v[i - 1]
- 贪心算法
for i in range(len(w)):
if w[y[i]-1] + weight < c:
value += v[y[i]-1]
weight += w[y[i]-1]
y1[y[i]-1] = 1
else:
y1[y[i]-1] = 0
- 回溯算法
# 回溯算法主要代码
def backtrack(i, w, v, n, c, x):
global bestV, curW, curV, bestX
if i >= n:
if bestV < curV:
bestV = curV
bestX = x[:]
else:
if curW+w[i] <= c:
x[i] = 1
curW += w[i]
curV += v[i]
backtrack(i+1, w, v, n, c, x)
curW -= w[i]
curV -= v[i]
x[i] = 0
backtrack(i+1, w, v, n, c, x)
- 遗传算法
def heredity(s):
last_time = time.time()
m = 8 # 规模
N = 800 # 迭代次数
Pc = 0.8 # 交配概率
Pm = 0.05 # 变异概率
w, n, W, V = table_data(s)
C = init(m, n)
S, F = fitness(C, m, n, W, V, w)
B, y = best_x(F, S, m)
Y = [y]
for i in range(N):
p = rate(F)
C = chose(p, C, m, n)
C = match(C, m, n, Pc)
C = vari(C, m, n, Pm)
S, F = fitness(C, m, n, W, V, w)
B1, y1 = best_x(F, S, m)
if y1 > y:
y = y1
Y.append(y)
print("最大值为:", y)
plt.plot(Y)
plt.show()
z = [0 for i in range(n)]
current_time = time.time()
for i in S[0]:
z[i] = 1
stime = str(current_time - last_time)
file_handle = open('result.txt', mode='a')
file_handle.write('遗传算法\n')
file_handle.write(s)
file_handle.write(' 最大值:')
file_handle.write(str(y))
file_handle.write(' 解向量:[')
for i in z:
file_handle.write(str(i))
file_handle.write(',')
file_handle.write('] 耗时:')
file_handle.write(str(current_time - last_time))
file_handle.write('\n')
file_handle.close()
return w, n, W, V, stime, z, y
- 显示绘图
def show():
if choice == 5:
scatter(s)
elif choice == 6:
barh(s)
time1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 执行算法的时间
search.in_log(time1, a_name, s)
global img_png # 定义全局变量 图像的
def Show_Img():
global img_png
if choice == 5:
Img = Image.open('./src/picture/scatter_' + s + '.png')
else:
Img = Image.open('./src/picture/barch_' + s + '.png')
img_png = ImageTk.PhotoImage(Img)
label_Img = tk.Label(win, image=img_png)
label_Img.pack(ipady=45)
- 显示排序
def go(*args): # 处理事件,*args表示可变参数
s = comboxlist.get()
time1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
search.in_log(time1, a_name, s)
if choice == 7:
c, n, w, v, x, y = decrease(s)
elif choice == 8:
c, n, w, v, x, y = increase(s)
- 日志记录
# 4. 显示日志记录
def in_main4(a_name):
# 构造窗体
win = tkinter.Tk()
win.geometry('920x250')
win.title(a_name)
list = search.log()
tree = ttk.Treeview(win) # #创建表格对象
tree["columns"] = ("重量", "价值", "解向量") # #定义列
tree.column("重量", width=220) # #设置列
tree.column("价值", width=220)
tree.column("解向量", width=220)
for num in range(len(list)):
i = len(list) - num - 1
tree.insert("", num, text=str(num), values=(str(list[i][0]), str(list[i][1]), str(list[i][2]))) # 给第0行添加数据,索引值可重复
tree.pack()
win.mainloop()
(6)程序运行
- 3.6.1 GUI总体界面
-
3.6.2 导入数据
-
选择文件
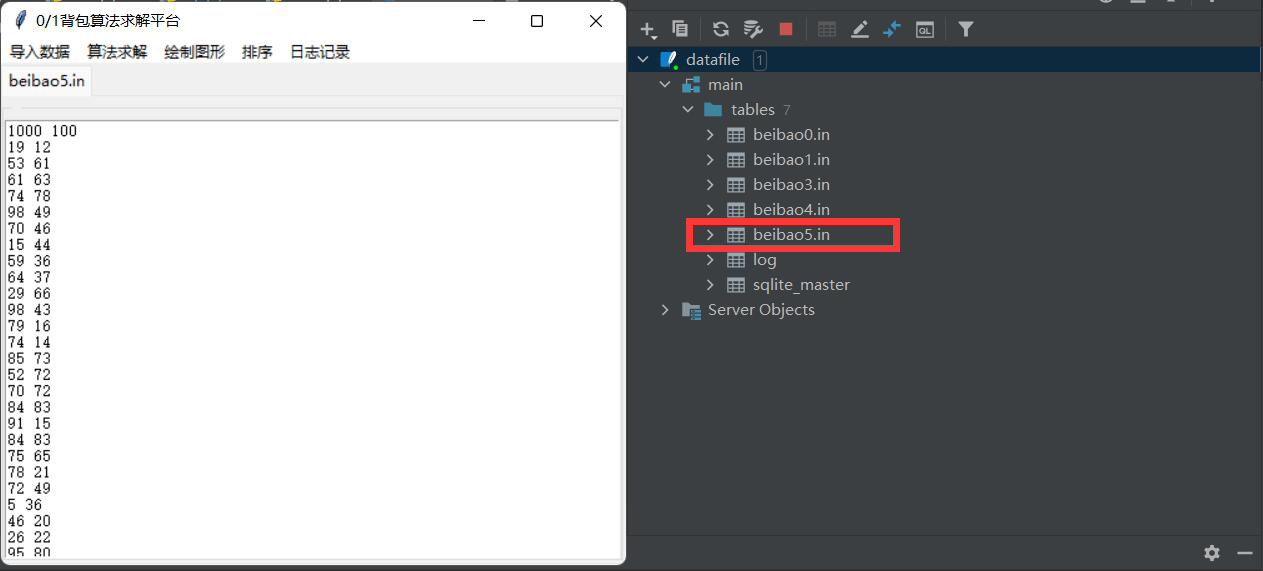
- 选择本地文件数据5
- 加入数据库,显示数据5
-
3.6.3 算法求解(以贪心、遗传为例)
-
选择算法求解
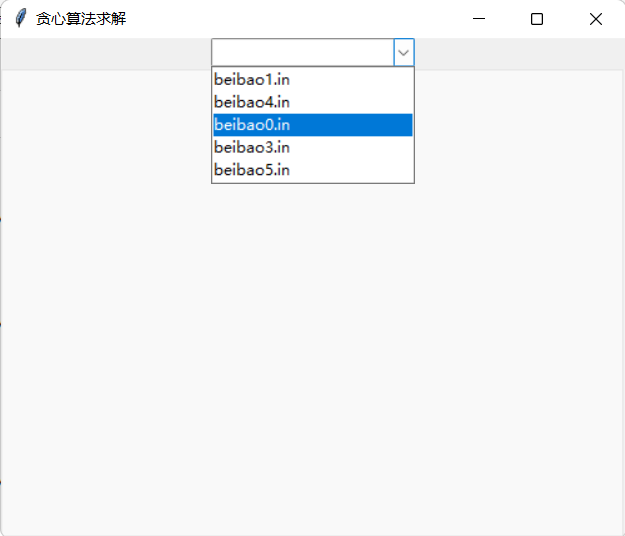
- 选择贪心算法,选择文件数据0
- 显示结果,同时结果页保存在了result.txt文件中(此处该截图不多做展示)

- 选择遗传算法,文件数据5

- 保存结果到txt文件

- 3.6.4 绘制图形
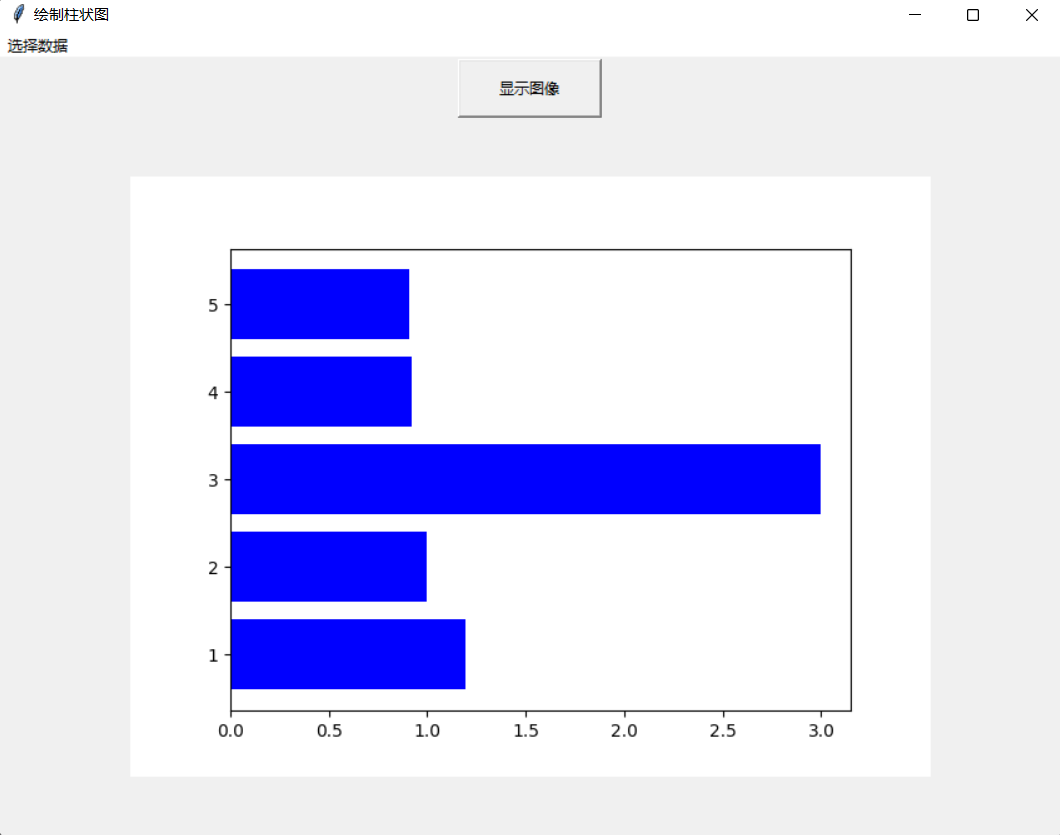
-选择绘制图形(柱形图为例)

- 绘制柱状图选择数据0
- 点击按钮——显示图像
-
3.6.5 排序
-
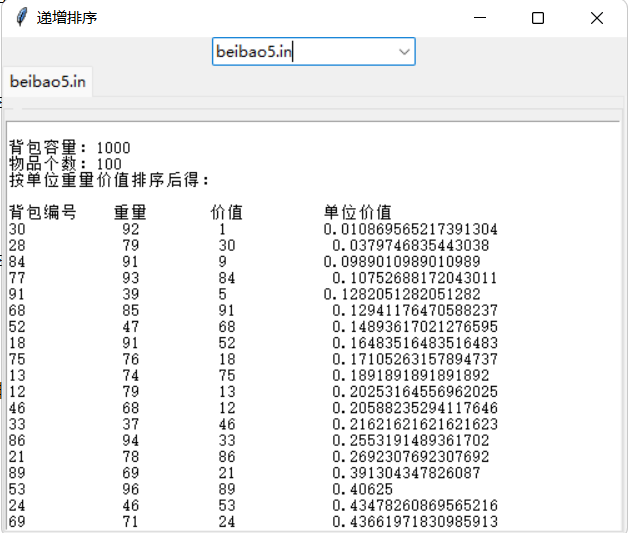
选择排序(以递增为例)
- 递增排序,选择数据5
-
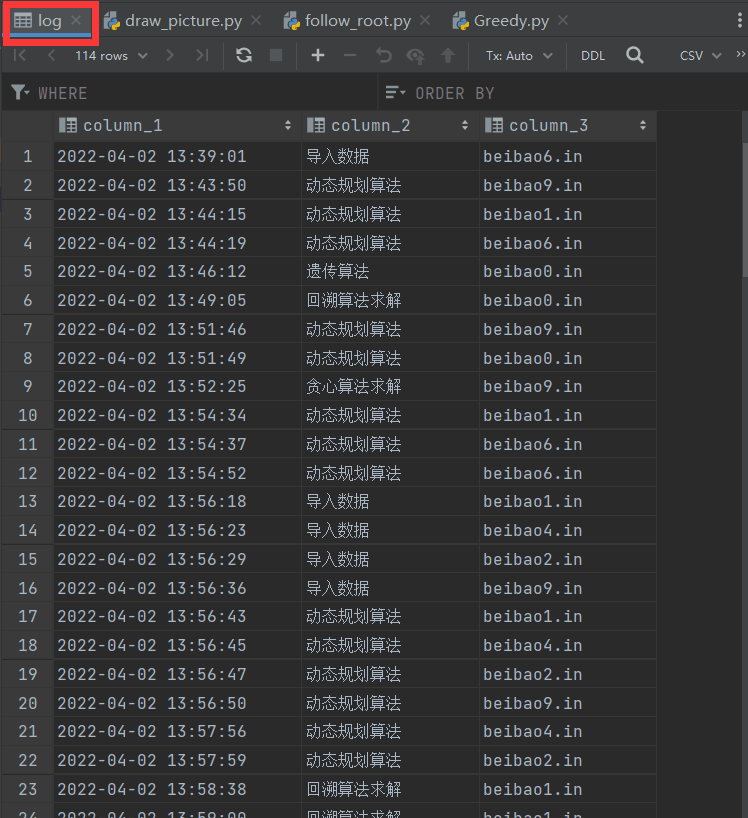
3.6.6 显示日志
-
显示部分操作记录

- 显示部分数据库日志数据
-
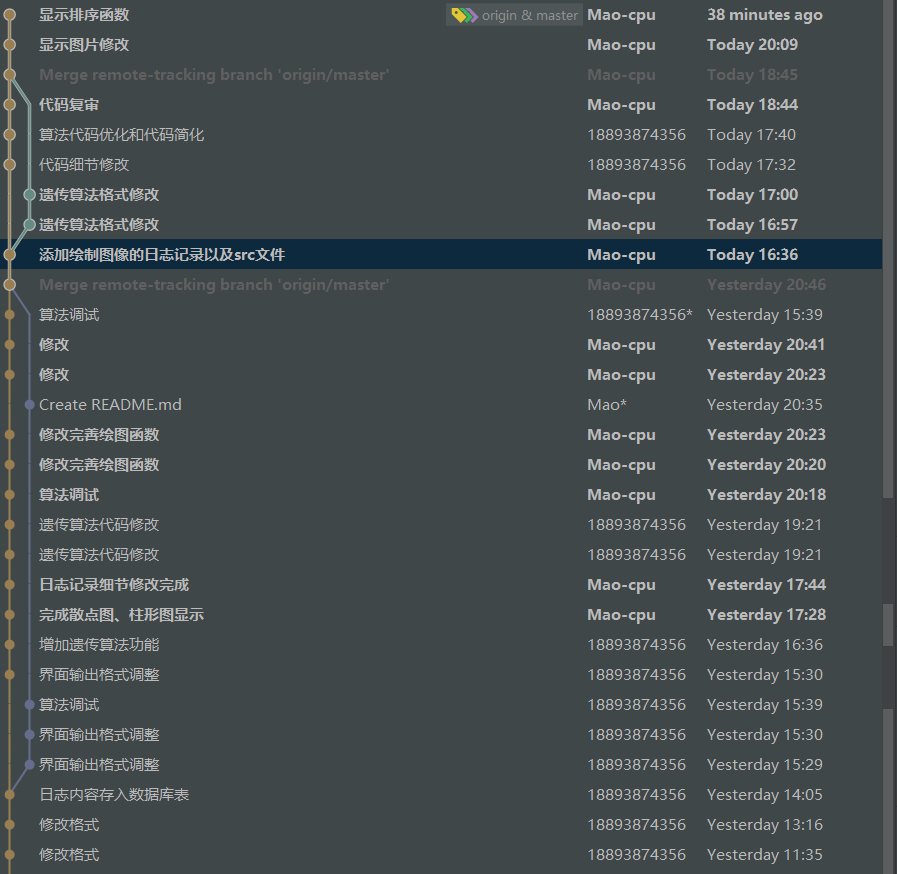
3.6.7 commit提交记录
-
共同commit记录

- 各自commit记录
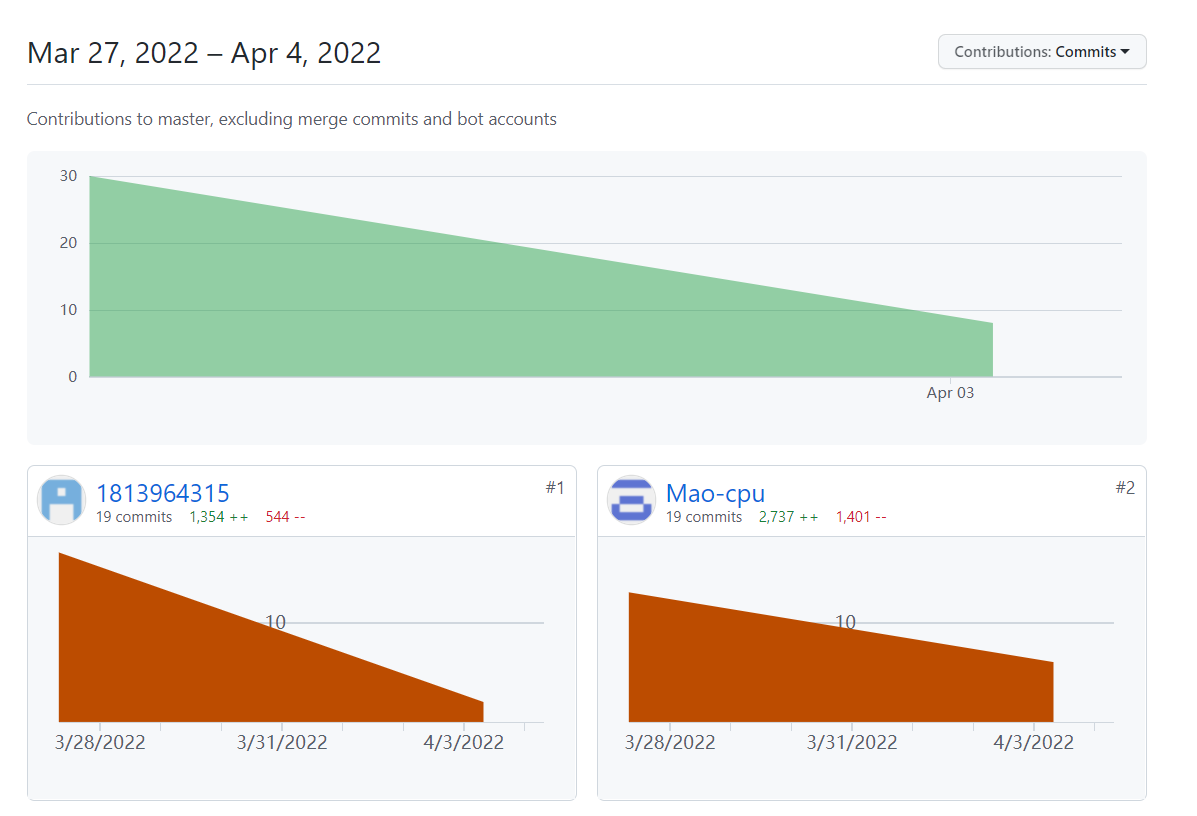
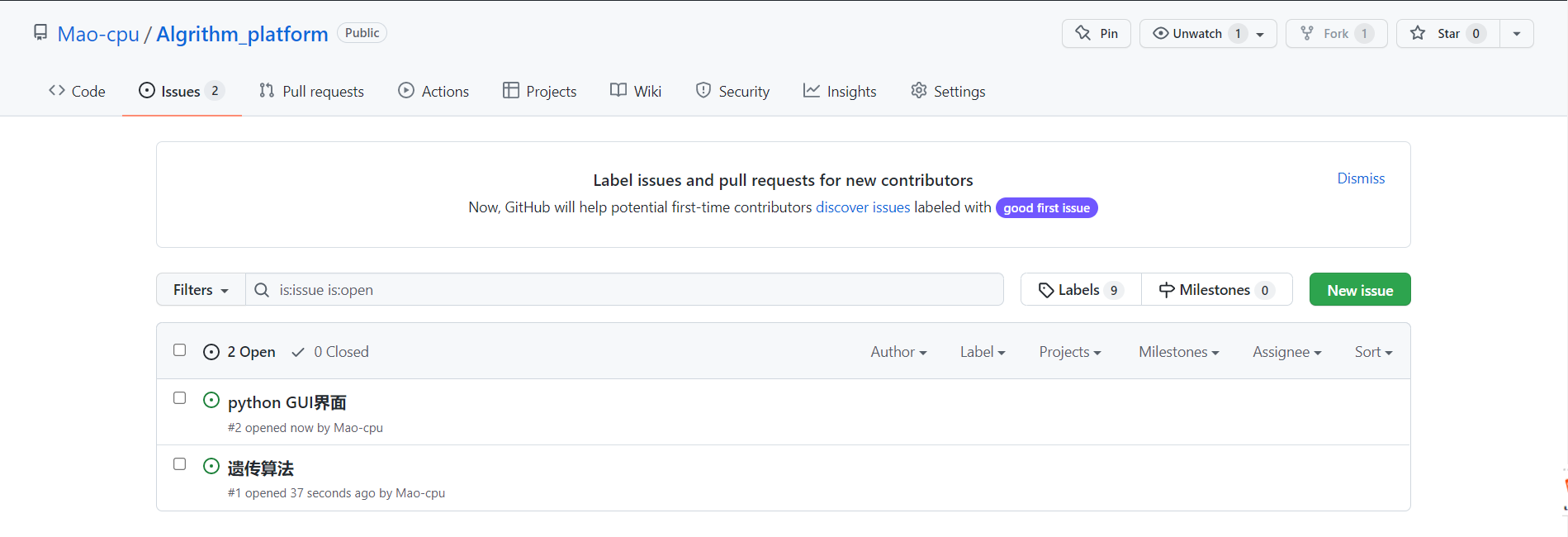
- issue 2次(GUI界面美化以及遗传算法讨论)
(7)描述结对的过程,提供两人在讨论、细化和编程时的结对照片(非摆拍)
- 结对过程中,使用企业微信交流,或直接当面讨论(互相交流,修改代码)
- 尝试采用汉堡包法实施项目结对中两个人的沟通
- 断言、桥梁、说服(部分截图)
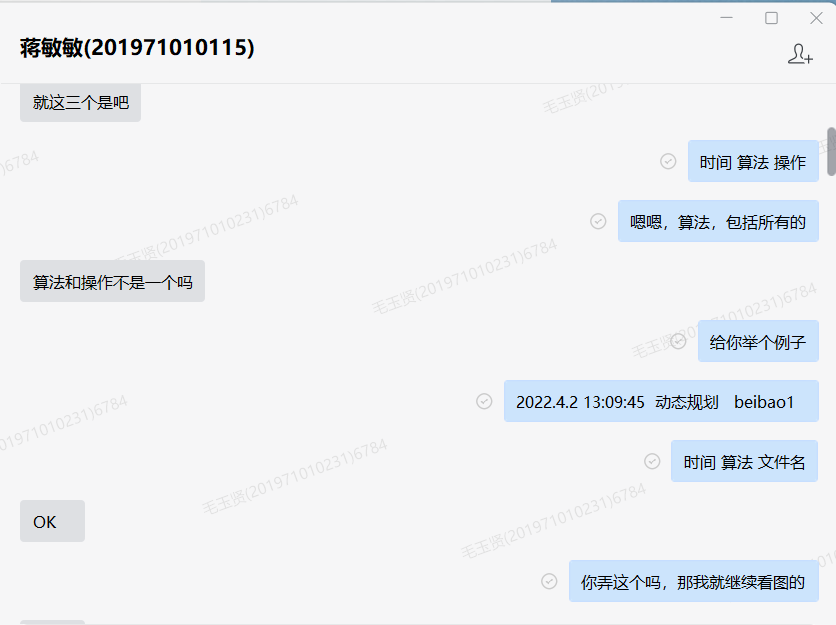
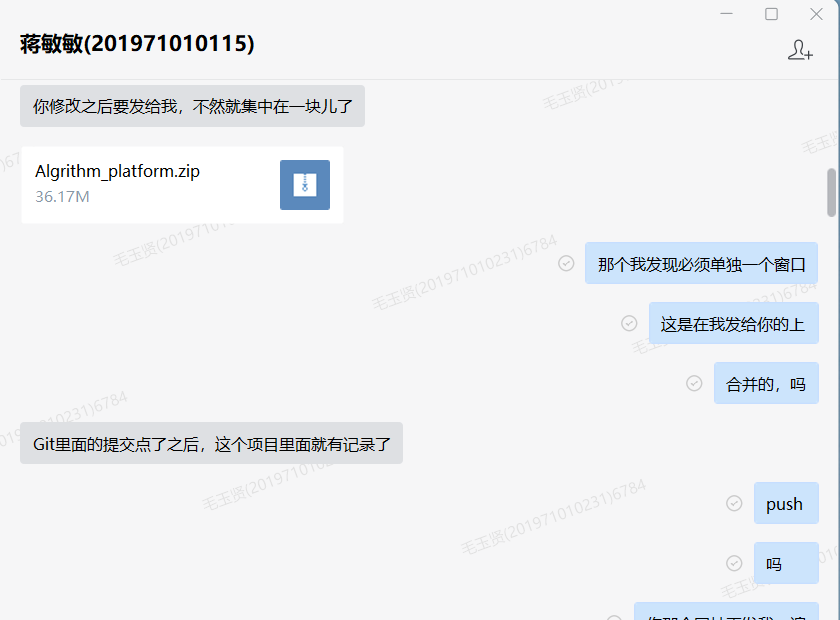
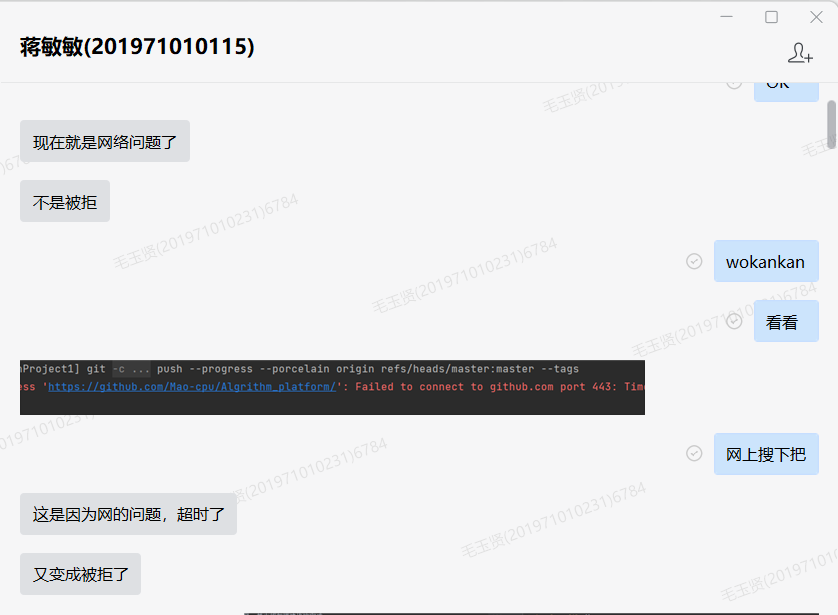
- 理解了领航员和驾驶员两种角色关系:两人都参与了编码工作,在结对编程中两个人轮流做对方的角色(角色交换过程部分截图)
(8)此次结对作业的PSP
| PSP2.1 | 任务内容 | 计划设计完成需要时间(min) | 实际需要时间 |
|---|---|---|---|
| Planning | 计划 | 25 | 30 |
| Estimate | 估计任务时间,规划工作步骤 | 19 | 21 |
| Development | 开发 | 1442 | 1481 |
| Analysis | 需求分析(包括学习新技术) | 120 | 152 |
| Design Spec | 生成设计文档 | 18 | 15 |
| Design Review | 设计复审(和同事审核设计文档) | 10 | 8 |
| Coding Standard | 代码规范 | 10 | 8 |
| Design | 具体设计 | 75 | 55 |
| Coding | 具体编码 | 1080 | 1102 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试、修改、提交) | 35 | 30 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 5 | 3 |
| Postmortem & Process Improvement Plan | 事后总结,提出过程改进计划 | 8 | 5 |
(9)小结感受:两人合作真的能够带来1+1>2的效果吗?通过这次结对合作,请谈谈你的感受和体会
- 我认为1+1可以带来大于2的效果,在以往的项目设计过程中,采用“单打独斗”的方式,但经常容易陷入自己的“思维定势中”,找不出问题所在。采用结对编程的方式,正好解决了这一问题,通过两个人交流讨论,彼此可以看出对方的问题所在,推进项目的进行,以及两个人互相交流知识的学习,但如果把握不好度的话,讨论时间过长,也会造成时间的浪费,降低效率,但相比较于其“利”来说,结对编程还是有利于两个人的互相成长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号