机器学习——快餐类型识别
1 选题背景
随着信息网络的运用,部分餐厅已经实现点餐结账无人化,解放了收款人员。一些互联网公司与更大的连锁餐饮企业联手“智慧餐厅”,打造出更加极致的“无人概念餐厅”,如北京海底捞无人餐厅,店里全采用机器人服务,这种运营服务也让体力老店铺那个得到解脱,相比以往的服务这种服务更加高效。对于实现“无人餐厅”,计算机视觉技术是机器人服务员辨别对应的菜品的重要手段。
本项目将利用kaggle平台的快餐图像数据构建神经网络模型,训练出一个能够有效辨别快餐类型的模型。
2. 数据来源
Kaggle,网址:https://www.kaggle.com/datasets/utkarshsaxenadn/fast-food-classification-dataset
3 机器学习的实现步骤
3.1 环境准备
导入pandas,numpy,matplotlib,os,pathlib,sklearn库,导入keras,tensorflow框架。
import pandas as pd import numpy as np import tensorflow as tf from sklearn.model_selection import train_test_split import os from keras.models import Sequential, load_model from keras.layers import Activation,Dense, Dropout, Flatten, Conv2D, MaxPool2D from keras.applications.resnet import preprocess_input from keras.preprocessing.image import ImageDataGenerator from keras.preprocessing import image from keras import optimizers from pathlib import Path import matplotlib.pyplot as plt
3.2 图像数据读取
读取Baked Potato,Burger,Fries快餐的JPEG格式文件名,存储至列表filepaths。
# 读取Baked Potato,Burger,Fries,Pizza,Sandwich,Taquito快餐的JPEG格式文件名 dir_BakedPotato = Path('数据集/Baked Potato') filepaths_BakedPotato = list(dir_BakedPotato.glob('**/*.JPEG')) dir_Burger = Path('数据集/Burger') filepaths_Burger = list(dir_Burger.glob('**/*.JPEG')) dir_Fries = Path('数据集/Fries') filepaths_Fries = list(dir_Fries.glob('**/*.JPEG'))
3.3 图像数据处理
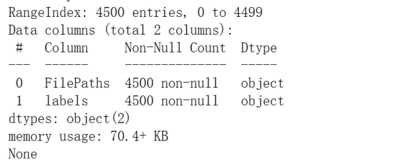
# 构建列表,存储图片路径 filepaths = [filepaths_BakedPotato,filepaths_Burger,filepaths_Fries,] # 把二维列表降一维 filepaths = sum(filepaths, []) # 构建列表,存储图片对应类型 list_BakedPotato = list(map(lambda x:'BakedPotato', [i for i in range(len(filepaths_BakedPotato))])) list_Burger = list(map(lambda x:'Burger', [i for i in range(len(filepaths_Burger))])) list_Fries = list(map(lambda x:'Fries', [i for i in range(len(filepaths_Fries))])) label = [list_BakedPotato,list_Burger,list_Fries,] print(len(label)) # 把二维列表降一维 label = sum(label, []) print(len(label)) # 合并两个列表为数据框 filepaths_S = pd.Series(filepaths,name='FilePaths') label_S = pd.Series(label,name='labels') data = pd.merge(filepaths_S,label_S,right_index=True,left_index=True) print(data.head()) print(data.info())
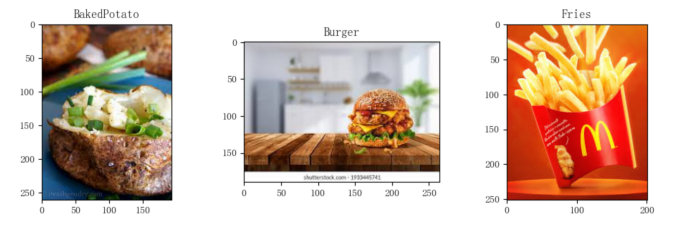
3.3.2 使用数据框中图片路径查看图片。
# 查看图像 pic = plt.figure(figsize=(12,7)) l1 = [3,1502,3002] for i in range(1,4,1): ax = pic.add_subplot(2, 3, i) plt.imshow(plt.imread(data['FilePaths'][l1[i-1]])) plt.title(data['labels'][l1[i-1]]) plt.savefig('图像.jpg') plt.show()
3.4 划分图像数据集
利用sklearn中train_test_split函数划分数据集,划分后,查看训练集,测试集,验证集的形状以及各类型图片的张数。
# 划分数据集,85:15划分x_train,x_test data['FilePaths'] = data['FilePaths'].astype(str) X_train, X_test = train_test_split(data, test_size=0.15,stratify=data['labels']) print('训练集形状', X_train.shape) print('测试集形状', X_test.shape) # 划分数据集,4:1划分x_train,x_val X_train, X_val = train_test_split(X_train, test_size=0.2,stratify=X_train['labels']) print('训练集形状', X_train.shape) print('验证集形状', X_val.shape) # 查看各类型的图片张数 print(X_train['labels'].value_counts()) print(X_train['FilePaths'].shape)


3.5 图像预处理
使用tensorflow框架里面的ImageDataGenerator函数对图像预处理,批量数据的尺寸batch_size=32,随机种子seed=30。
# 图像预处理 img_preprocessing = ImageDataGenerator(rescale=1./255) x_train = img_preprocessing.flow_from_dataframe(dataframe=X_train, x_col='FilePaths', y_col='labels', target_size=(112, 112), color_mode='rgb', class_mode='categorical', batch_size=32, seed=30) x_test = img_preprocessing.flow_from_dataframe(dataframe=X_test, x_col='FilePaths', y_col='labels', target_size=(112, 112), color_mode='rgb', class_mode='categorical', batch_size=32, seed=30) x_val = img_preprocessing.flow_from_dataframe(dataframe=X_val, x_col='FilePaths', y_col='labels', target_size=(112, 112), color_mode='rgb', class_mode='categorical', batch_size=32, seed=30)
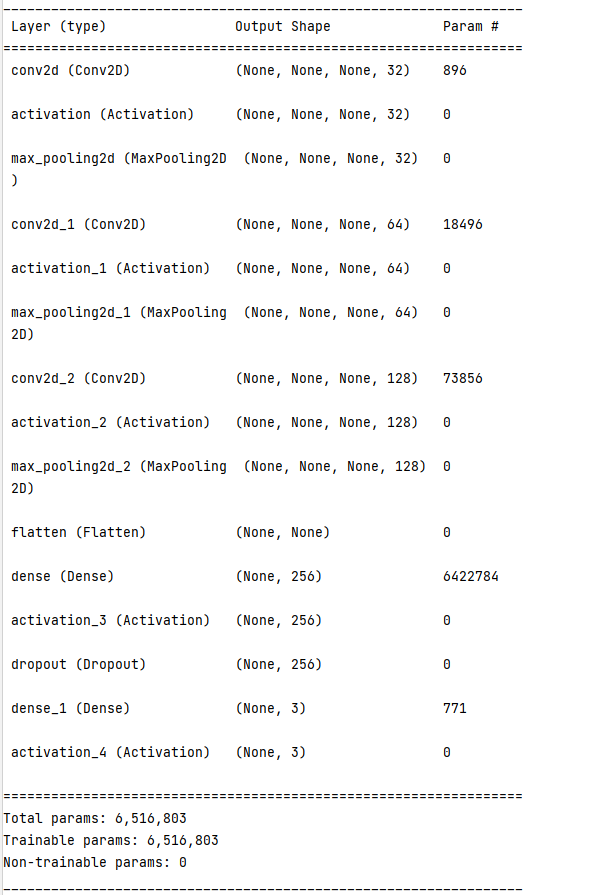
3.6 构建神经网络模型
# 构建神经网络模型并训练 model = Sequential() # Conv2D层,32个滤波器 model.add(Conv2D(filters=32, kernel_size=(3,3), padding='same')) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) # Conv2D层,64个滤波器 model.add(Conv2D(filters=64, kernel_size=(3,3), padding='same')) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) # Conv2D层,128个滤波器 model.add(Conv2D(filters=128, kernel_size=(3,3), padding='same')) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) # 展平数据,降维 model.add(Flatten()) # 全连接层 model.add(Dense(256)) model.add(Activation('relu')) # 减少过拟合 model.add(Dropout(0.5)) # 全连接层 model.add(Dense(3)) # 识别6种类 model.add(Activation('softmax')) # #使用softmax进行分类 # 模型编译 model.compile(optimizer=optimizers.RMSprop(learning_rate=1e-4), loss="categorical_crossentropy", metrics=["accuracy"]) # metrics指定衡量模型的指标
3.7 模型训练
3.7.1 设置参数epichs训练80轮,并打印验证集的最终的损失与准确率
# h1模型训练 print('training-----') h1 = model.fit(x_train,validation_data=x_val,epochs=80) model.summary()
print('\validating-----') loss,accuracy=model.evaluate(x_val) print('\nvalidation loss: ',loss) print('\nvalidation accuracy: ',accuracy) # 保存模型 model.save('h21')


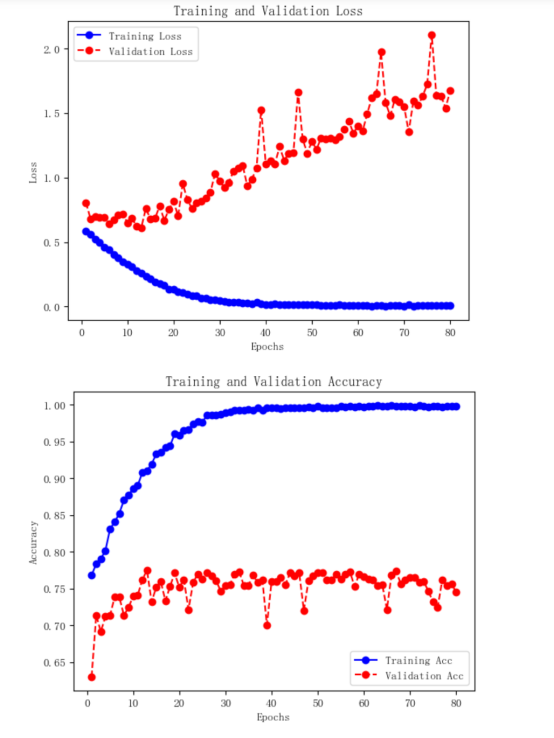
3.7.2 绘制h1模型的损失变化曲线与准确率变化曲线,观察它们的变化
# 绘制h1模型损失变化曲线 loss = h1.history["loss"] epochs = range(1, len(loss)+1) val_loss = h1.history["val_loss"] plt.plot(epochs, loss, "bo-", label="Training Loss") plt.plot(epochs, val_loss, "ro--", label="Validation Loss") plt.title("Training and Validation Loss") plt.xlabel("Epochs") plt.ylabel("Loss") plt.legend() plt.savefig('h1模型损失变化曲线图.jpg') plt.show() # 绘制h1模型准确率变化曲线 acc = h1.history["accuracy"] epochs = range(1, len(acc)+1) val_acc = h1.history["val_accuracy"] plt.plot(epochs, acc, "bo-", label="Training Acc") plt.plot(epochs, val_acc, "ro--", label="Validation Acc") plt.title("Training and Validation Accuracy") plt.xlabel("Epochs") plt.ylabel("Accuracy") plt.legend() plt.savefig('h1模型准确率变化曲线图.jpg') plt.show()
3.8 模型优化
3.8.1 从h1模型的损失变化曲线与准确率变化曲线,可以得出training loss不断降低,但validation loss不断上升,说明模型过拟合,因此我们需要降低过拟合,下面通过数据增强来降低过拟合。
# 数据增强 train_data_gen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest') val_data_gen = ImageDataGenerator(rescale=1./255) x_train1 = train_data_gen.flow_from_dataframe(dataframe=X_train, x_col='FilePaths', y_col='labels', target_size=(112, 112), color_mode='rgb', class_mode='categorical', batch_size=32, seed=30) x_val1 = val_data_gen.flow_from_dataframe(dataframe=X_val, x_col='FilePaths', y_col='labels', target_size=(112, 112), color_mode='rgb', class_mode='categorical', batch_size=32, seed=30)
3.8.2 激活特征图和打印特征图
img_path = "训练/Burger/Burger-Train (1470).jpeg" img = image_utils.load_img(img_path, target_size=(150,150)) img_tensor = image_utils.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor /= 255. print(img_tensor.shape) #显示样本 import matplotlib.pyplot as plt plt.imshow(img_tensor[0]) plt.show() layer_outputs = [layer.output for layer in model.layers[:8]] activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs) #获得改样本的特征图 activations = activation_model.predict(img_tensor) #第一层激活输出特的第一个滤波器的特征图 first_layer_activation = activations[0] # 存储层的名称 layer_names = [] for layer in model.layers[:4]: layer_names.append(layer.name) # 每行显示16个特征图 images_pre_row = 16 # 每行显示的特征图数 # 循环8次显示8层的全部特征图 for layer_name, layer_activation in zip(layer_names, activations): n_features = layer_activation.shape[-1] # 保存当前层的特征图个数 size = layer_activation.shape[1] # 保存当前层特征图的宽高 n_col = n_features // images_pre_row # 计算当前层显示多少行 # 生成显示图像的矩阵 display_grid = np.zeros((size * n_col, images_pre_row * size)) # 遍历将每个特张图的数据写入到显示图像的矩阵中 for col in range(n_col): for row in range(images_pre_row): # 保存该张特征图的矩阵(size,size,1) channel_image = layer_activation[0, :, :, col * images_pre_row + row] # 为使图像显示更鲜明,作一些特征处理 channel_image -= channel_image.mean() channel_image /= channel_image.std() channel_image *= 64 channel_image += 128 # 把该特征图矩阵中不在0-255的元素值修改至0-255 channel_image = np.clip(channel_image, 0, 255).astype("uint8") # 该特征图矩阵填充至显示图像的矩阵中 display_grid[col * size:(col + 1) * size, row * size:(row + 1) * size] = channel_image scale = 1. / size # 设置该层显示图像的宽高 plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) plt.title(layer_name) plt.grid(False) # 显示图像 plt.imshow(display_grid, aspect="auto", cmap="viridis") plt.show()

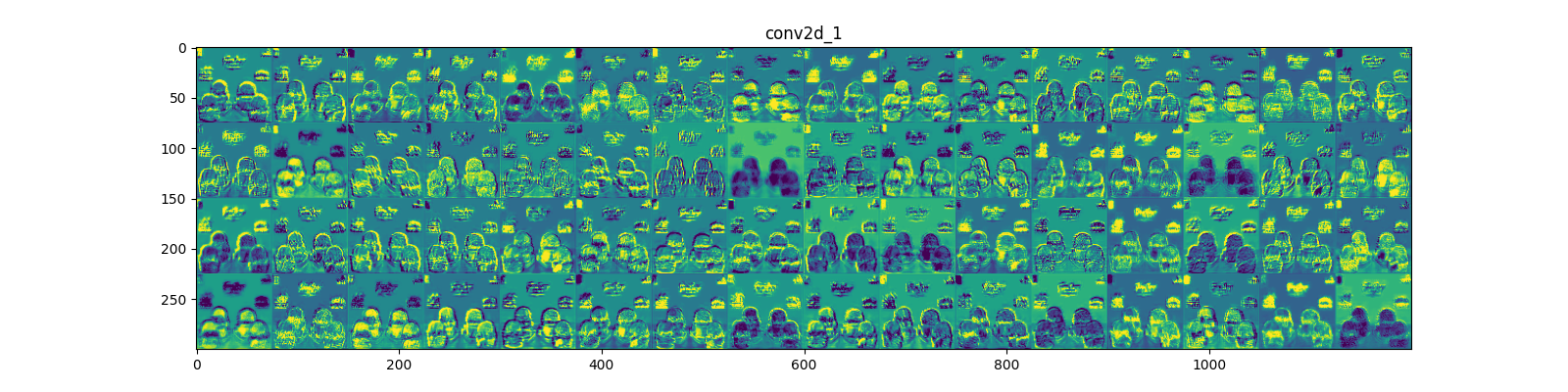

3.8.3 再次训练模型,并打印验证集的最终的损失与准确率
# h2模型训练 print('training-----') h2 = model.fit(x_train1,validation_data=x_val1,epochs=50) print('\validating-----') loss,accuracy=model.evaluate(x_val1) print('\nvalidation loss: ',loss) print('\nvalidation accuracy: ',accuracy) # 保存模型 model.save('h22')


3.8.3 绘制h2模型损失变化曲线与准确率变化曲线
# 绘制h2模型损失变化曲线 loss = h2.history["loss"] epochs = range(1, len(loss)+1) val_loss = h2.history["val_loss"] plt.plot(epochs, loss, "bo-", label="Training Loss") plt.plot(epochs, val_loss, "ro--", label="Validation Loss") plt.title("Training and Validation Loss") plt.xlabel("Epochs") plt.ylabel("Loss") plt.legend() plt.savefig('h2模型损失变化曲线图.jpg') plt.show() # 绘制h2模型准确率变化曲线 acc = h2.history["accuracy"] epochs = range(1, len(acc)+1) val_acc = h2.history["val_accuracy"] plt.plot(epochs, acc, "bo-", label="Training Acc") plt.plot(epochs, val_acc, "ro--", label="Validation Acc") plt.title("Training and Validation Accuracy") plt.xlabel("Epochs") plt.ylabel("Accuracy") plt.legend() plt.savefig('h2模型准确率变化曲线图.jpg') plt.show()
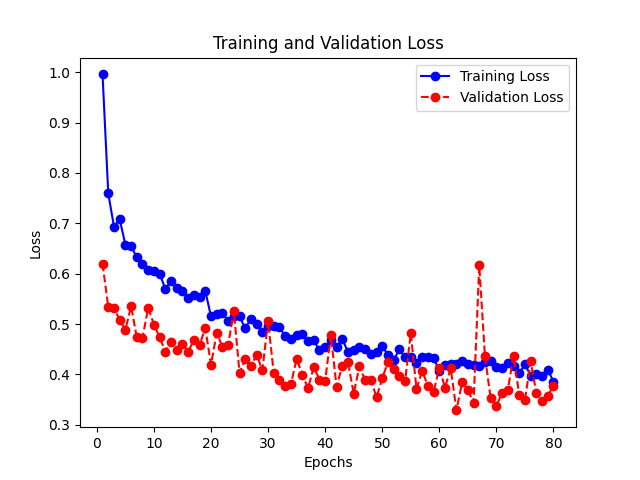
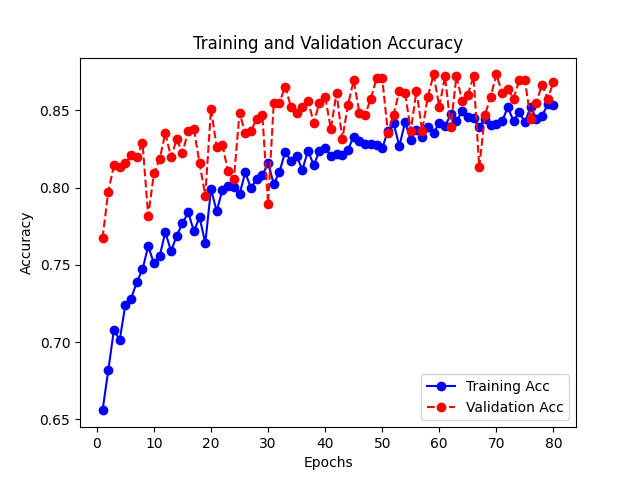
准确率基本是问题提高,说明模型拟合程度不错。
3.9 模型预测
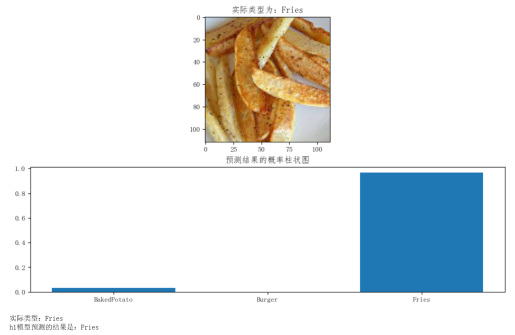
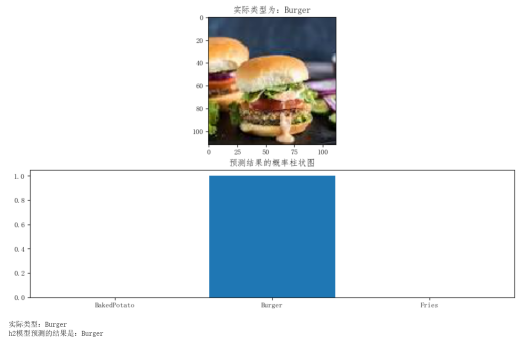
# h1模型预测 # 3类型 l1 = ['BakedPotato','Burger','Fries',] # 原图 i = 10 p1 = plt.figure(figsize=(12,7)) img1,label1 = x_test.next() plt.rcParams["font.sans-serif"]=["FangSong"] # 解决中文显示异常 ax1 = p1.add_subplot(2, 1, 1) plt.imshow((img1[i]*255).astype('uint8')) plt.title('实际类型为:' + l1[np.argmax(label1[i])]) # 将图片转换成 4D 张量 x_test_img1 = img1[i].reshape(1, 112, 112, 3).astype("float32") # 预测结果的概率柱状图 pr1 = h1.predict(x_test_img1) ax2 = p1.add_subplot(2, 1, 2) plt.title("预测结果的概率柱状图") plt.bar(np.arange(3), pr1.reshape(3), align="center") plt.xticks(np.arange(3),l1) plt.show() # 实际类型与h1模型预测结果对比 print('实际类型:' + l1[np.argmax(label1[i])]) print('h1模型预测的结果是:' + l1[np.argmax(pr1)]) # 加载h2模型 h2 = load_model('h22') # h2模型预测 # 3类型 l2 = ['BakedPotato','Burger','Fries'] # 原图 i = 10 p2 = plt.figure(figsize=(12,7)) img2,label2 = x_test.next() plt.rcParams["font.sans-serif"]=["FangSong"] # 解决中文显示异常 ax3 = p2.add_subplot(2, 1, 1) plt.imshow((img2[i]*255).astype('uint8')) plt.title('实际类型为:' + l2[np.argmax(label2[i])]) # 将图片转换成 4D 张量 x_test_img2 = img2[i].reshape(1, 112, 112, 3).astype("float32") # 预测结果的概率柱状图 pr2 = h2.predict(x_test_img2) ax4 = p2.add_subplot(2, 1, 2) plt.title("预测结果的概率柱状图") plt.bar(np.arange(3), pr2.reshape(3), align="center") plt.xticks(np.arange(3),l2) plt.show() # 实际类型与h2模型预测结果对比 print('实际类型:' + l2[np.argmax(label2[i])]) print('h2模型预测的结果是:' + l2[np.argmax(pr2)])
最终我选择绘制概率柱状图来显示数据,方便查看和识别。
4 总结
结论:从最终效果可以得出,我们最开始出现过拟合的情况得到了比较有效的解决,快餐食品的识别也是可以正常的运行,从我们的损失变化曲线和准确率变化曲线可以看出,Training loss跟Validation loss都在下降,Training acc和Validation acc在不断的上升。并且我们的validation acc几乎始终比training acc高,我们的模型的拟合程度好,最终通过长时间训练,准确度得到了良好的提升。
个人收获:本次机器学习我查阅了大量资料,在最开始选题的时候就出现了问题,有很多的想法但是不切实际,代码实力不对等,最终选择类别识别的项目来做参考文件比较多,在开发过程中也遇到了大量的问题,查阅资料,询问一些相关行业朋友,通过大量的时间最终开发完成,开发中遇到了过拟合问题,根据课上的讲解,我先尝试Dropout,尝试了数据增强,最终大概解决了问题,然后记录下来,是一段宝贵的经历。学习了不少的代码经验,虽然没有系统化学习,但是我对此展开了较大的兴趣,希望在未来空闲时间去进行系统化的学习,自我的研究。
5 本文全部代码
1 import pandas as pd 2 import numpy as np 3 import tensorflow as tf 4 from keras.utils import image_utils 5 from sklearn.model_selection import train_test_split 6 import os 7 from keras.models import Sequential, load_model 8 from keras.layers import Activation,Dense, Dropout, Flatten, Conv2D, MaxPool2D 9 from keras.applications.resnet import preprocess_input 10 from keras.preprocessing.image import ImageDataGenerator 11 from keras.preprocessing import image 12 from keras import optimizers, activations 13 from pathlib import Path 14 import matplotlib.pyplot as plt 15 16 # 读取Baked Potato,Burger,Fries,Pizza,Sandwich,Taquito快餐的JPEG格式文件名 17 dir_BakedPotato = Path('数据集/Baked Potato') 18 filepaths_BakedPotato = list(dir_BakedPotato.glob('**/*.JPEG')) 19 20 dir_Burger = Path('数据集/Burger') 21 filepaths_Burger = list(dir_Burger.glob('**/*.JPEG')) 22 23 dir_Fries = Path('数据集/Fries') 24 filepaths_Fries = list(dir_Fries.glob('**/*.JPEG')) 25 26 # 构建列表,存储图片路径 27 filepaths = [filepaths_BakedPotato,filepaths_Burger,filepaths_Fries,] 28 # 把二维列表降一维 29 filepaths = sum(filepaths, []) 30 31 # 构建列表,存储图片对应类型 32 list_BakedPotato = list(map(lambda x:'BakedPotato', [i for i in range(len(filepaths_BakedPotato))])) 33 list_Burger = list(map(lambda x:'Burger', [i for i in range(len(filepaths_Burger))])) 34 list_Fries = list(map(lambda x:'Fries', [i for i in range(len(filepaths_Fries))])) 35 label = [list_BakedPotato,list_Burger,list_Fries,] 36 print(len(label)) 37 38 # 把二维列表降一维 39 label = sum(label, []) 40 print(len(label)) 41 # 合并两个列表为数据框 42 filepaths_S = pd.Series(filepaths,name='FilePaths') 43 label_S = pd.Series(label,name='labels') 44 data = pd.merge(filepaths_S,label_S,right_index=True,left_index=True) 45 print(data.head()) 46 print(data.info()) 47 48 # 查看图像 49 pic = plt.figure(figsize=(12,7)) 50 l1 = [3,1502,3002] 51 for i in range(1,4,1): 52 ax = pic.add_subplot(2, 3, i) 53 plt.imshow(plt.imread(data['FilePaths'][l1[i-1]])) 54 plt.title(data['labels'][l1[i-1]]) 55 plt.savefig('图像.jpg') 56 plt.show() 57 58 # 划分数据集,85:15划分x_train,x_test 59 data['FilePaths'] = data['FilePaths'].astype(str) 60 X_train, X_test = train_test_split(data, test_size=0.15,stratify=data['labels']) 61 print('训练集形状', X_train.shape) 62 print('测试集形状', X_test.shape) 63 64 # 划分数据集,4:1划分x_train,x_val 65 X_train, X_val = train_test_split(X_train, test_size=0.2,stratify=X_train['labels']) 66 print('训练集形状', X_train.shape) 67 print('验证集形状', X_val.shape) 68 69 # 查看各类型的图片张数 70 print(X_train['labels'].value_counts()) 71 print(X_train['FilePaths'].shape) 72 73 # 图像预处理 74 img_preprocessing = ImageDataGenerator(rescale=1./255) 75 x_train = img_preprocessing.flow_from_dataframe(dataframe=X_train, 76 x_col='FilePaths', 77 y_col='labels', 78 target_size=(112, 112), 79 color_mode='rgb', 80 class_mode='categorical', 81 batch_size=32, 82 seed=30) 83 84 x_test = img_preprocessing.flow_from_dataframe(dataframe=X_test, 85 x_col='FilePaths', 86 y_col='labels', 87 target_size=(112, 112), 88 color_mode='rgb', 89 class_mode='categorical', 90 batch_size=32, 91 seed=30) 92 93 x_val = img_preprocessing.flow_from_dataframe(dataframe=X_val, 94 x_col='FilePaths', 95 y_col='labels', 96 target_size=(112, 112), 97 color_mode='rgb', 98 class_mode='categorical', 99 batch_size=32, 100 seed=30) 101 102 # 构建神经网络模型并训练 103 model = Sequential() 104 105 # Conv2D层,32个滤波器 106 model.add(Conv2D(filters=32, kernel_size=(3,3), padding='same')) 107 model.add(Activation('relu')) 108 model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) 109 110 # Conv2D层,64个滤波器 111 model.add(Conv2D(filters=64, kernel_size=(3,3), padding='same')) 112 model.add(Activation('relu')) 113 model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) 114 115 # Conv2D层,128个滤波器 116 model.add(Conv2D(filters=128, kernel_size=(3,3), padding='same')) 117 model.add(Activation('relu')) 118 model.add(MaxPool2D(pool_size=(2,2), strides=2, padding='valid')) 119 120 # 展平数据,降维 121 model.add(Flatten()) 122 123 # 全连接层 124 model.add(Dense(256)) 125 model.add(Activation('relu')) 126 127 # 减少过拟合 128 model.add(Dropout(0.5)) 129 130 # 全连接层 131 model.add(Dense(3)) # 识别6种类 132 model.add(Activation('softmax')) # #使用softmax进行分类 133 134 135 # 模型编译 136 model.compile(optimizer=optimizers.RMSprop(learning_rate=1e-4), loss="categorical_crossentropy", 137 metrics=["accuracy"]) # metrics指定衡量模型的指标 138 139 # h1模型训练 140 print('training-----') 141 h1 = model.fit(x_train,validation_data=x_val,epochs=80) 142 model.summary() 143 144 print('\validating-----') 145 loss,accuracy=model.evaluate(x_val) 146 147 print('\nvalidation loss: ',loss) 148 print('\nvalidation accuracy: ',accuracy) 149 150 # 保存模型 151 model.save('h21') 152 153 # 绘制h1模型损失变化曲线 154 loss = h1.history["loss"] 155 epochs = range(1, len(loss)+1) 156 val_loss = h1.history["val_loss"] 157 plt.plot(epochs, loss, "bo-", label="Training Loss") 158 plt.plot(epochs, val_loss, "ro--", label="Validation Loss") 159 plt.title("Training and Validation Loss") 160 plt.xlabel("Epochs") 161 plt.ylabel("Loss") 162 plt.legend() 163 plt.savefig('h1模型损失变化曲线图.jpg') 164 plt.show() 165 166 # 绘制h1模型准确率变化曲线 167 acc = h1.history["accuracy"] 168 epochs = range(1, len(acc)+1) 169 val_acc = h1.history["val_accuracy"] 170 plt.plot(epochs, acc, "bo-", label="Training Acc") 171 plt.plot(epochs, val_acc, "ro--", label="Validation Acc") 172 plt.title("Training and Validation Accuracy") 173 plt.xlabel("Epochs") 174 plt.ylabel("Accuracy") 175 plt.legend() 176 plt.savefig('h1模型准确率变化曲线图.jpg') 177 plt.show() 178 179 # 数据增强 180 train_data_gen = ImageDataGenerator(rescale=1./255, 181 rotation_range=40, 182 width_shift_range=0.2, 183 height_shift_range=0.2, 184 shear_range=0.2, 185 zoom_range=0.2, 186 horizontal_flip=True, 187 fill_mode='nearest') 188 189 val_data_gen = ImageDataGenerator(rescale=1./255) 190 191 x_train1 = train_data_gen.flow_from_dataframe(dataframe=X_train, 192 x_col='FilePaths', 193 y_col='labels', 194 target_size=(112, 112), 195 color_mode='rgb', 196 class_mode='categorical', 197 batch_size=32, 198 seed=30) 199 200 201 x_val1 = val_data_gen.flow_from_dataframe(dataframe=X_val, 202 x_col='FilePaths', 203 y_col='labels', 204 target_size=(112, 112), 205 color_mode='rgb', 206 class_mode='categorical', 207 batch_size=32, 208 seed=30) 209 210 img_path = "训练/Burger/Burger-Train (1470).jpeg" 211 img = image_utils.load_img(img_path, target_size=(150,150)) 212 img_tensor = image_utils.img_to_array(img) 213 img_tensor = np.expand_dims(img_tensor, axis=0) 214 img_tensor /= 255. 215 print(img_tensor.shape) 216 #显示样本 217 import matplotlib.pyplot as plt 218 plt.imshow(img_tensor[0]) 219 plt.show() 220 221 layer_outputs = [layer.output for layer in model.layers[:8]] 222 activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs) 223 #获得改样本的特征图 224 activations = activation_model.predict(img_tensor) 225 #第一层激活输出特的第一个滤波器的特征图 226 first_layer_activation = activations[0] 227 228 # 存储层的名称 229 layer_names = [] 230 for layer in model.layers[:4]: 231 layer_names.append(layer.name) 232 # 每行显示16个特征图 233 images_pre_row = 16 # 每行显示的特征图数 234 # 循环8次显示8层的全部特征图 235 for layer_name, layer_activation in zip(layer_names, activations): 236 n_features = layer_activation.shape[-1] # 保存当前层的特征图个数 237 size = layer_activation.shape[1] # 保存当前层特征图的宽高 238 n_col = n_features // images_pre_row # 计算当前层显示多少行 239 # 生成显示图像的矩阵 240 display_grid = np.zeros((size * n_col, images_pre_row * size)) 241 # 遍历将每个特张图的数据写入到显示图像的矩阵中 242 for col in range(n_col): 243 for row in range(images_pre_row): 244 # 保存该张特征图的矩阵(size,size,1) 245 channel_image = layer_activation[0, :, :, col * images_pre_row + row] 246 # 为使图像显示更鲜明,作一些特征处理 247 channel_image -= channel_image.mean() 248 channel_image /= channel_image.std() 249 channel_image *= 64 250 channel_image += 128 251 # 把该特征图矩阵中不在0-255的元素值修改至0-255 252 channel_image = np.clip(channel_image, 0, 255).astype("uint8") 253 # 该特征图矩阵填充至显示图像的矩阵中 254 display_grid[col * size:(col + 1) * size, row * size:(row + 1) * size] = channel_image 255 256 scale = 1. / size 257 # 设置该层显示图像的宽高 258 plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) 259 plt.title(layer_name) 260 plt.grid(False) 261 # 显示图像 262 plt.imshow(display_grid, aspect="auto", cmap="viridis") 263 plt.show() 264 265 # h2模型训练 266 print('training-----') 267 h2 = model.fit(x_train1,validation_data=x_val1,epochs=80) 268 269 print('\validating-----') 270 loss,accuracy=model.evaluate(x_val1) 271 272 print('\nvalidation loss: ',loss) 273 print('\nvalidation accuracy: ',accuracy) 274 275 # 保存模型 276 model.save('h22') 277 278 # 绘制h2模型损失变化曲线 279 loss = h2.history["loss"] 280 epochs = range(1, len(loss)+1) 281 val_loss = h2.history["val_loss"] 282 plt.plot(epochs, loss, "bo-", label="Training Loss") 283 plt.plot(epochs, val_loss, "ro--", label="Validation Loss") 284 plt.title("Training and Validation Loss") 285 plt.xlabel("Epochs") 286 plt.ylabel("Loss") 287 plt.legend() 288 plt.savefig('h2模型损失变化曲线图.jpg') 289 plt.show() 290 291 # 绘制h2模型准确率变化曲线 292 acc = h2.history["accuracy"] 293 epochs = range(1, len(acc)+1) 294 val_acc = h2.history["val_accuracy"] 295 plt.plot(epochs, acc, "bo-", label="Training Acc") 296 plt.plot(epochs, val_acc, "ro--", label="Validation Acc") 297 plt.title("Training and Validation Accuracy") 298 plt.xlabel("Epochs") 299 plt.ylabel("Accuracy") 300 plt.legend() 301 plt.savefig('h2模型准确率变化曲线图.jpg') 302 plt.show() 303 304 # 加载h1模型 305 h1 = load_model('h21') 306 307 # h1模型预测 308 # 3类型 309 l1 = ['BakedPotato','Burger','Fries',] 310 # 原图 311 i = 10 312 p1 = plt.figure(figsize=(12,7)) 313 img1,label1 = x_test.next() 314 plt.rcParams["font.sans-serif"]=["FangSong"] # 解决中文显示异常 315 ax1 = p1.add_subplot(2, 1, 1) 316 plt.imshow((img1[i]*255).astype('uint8')) 317 plt.title('实际类型为:' + l1[np.argmax(label1[i])]) 318 319 # 将图片转换成 4D 张量 320 x_test_img1 = img1[i].reshape(1, 112, 112, 3).astype("float32") 321 322 # 预测结果的概率柱状图 323 pr1 = h1.predict(x_test_img1) 324 ax2 = p1.add_subplot(2, 1, 2) 325 plt.title("预测结果的概率柱状图") 326 plt.bar(np.arange(3), pr1.reshape(3), align="center") 327 plt.xticks(np.arange(3),l1) 328 plt.show() 329 330 # 实际类型与h1模型预测结果对比 331 print('实际类型:' + l1[np.argmax(label1[i])]) 332 print('h1模型预测的结果是:' + l1[np.argmax(pr1)]) 333 334 # 加载h2模型 335 h2 = load_model('h22') 336 337 # h2模型预测 338 # 3类型 339 l2 = ['BakedPotato','Burger','Fries'] 340 # 原图 341 i = 10 342 p2 = plt.figure(figsize=(12,7)) 343 img2,label2 = x_test.next() 344 plt.rcParams["font.sans-serif"]=["FangSong"] # 解决中文显示异常 345 ax3 = p2.add_subplot(2, 1, 1) 346 plt.imshow((img2[i]*255).astype('uint8')) 347 plt.title('实际类型为:' + l2[np.argmax(label2[i])]) 348 349 # 将图片转换成 4D 张量 350 x_test_img2 = img2[i].reshape(1, 112, 112, 3).astype("float32") 351 352 # 预测结果的概率柱状图 353 pr2 = h2.predict(x_test_img2) 354 ax4 = p2.add_subplot(2, 1, 2) 355 plt.title("预测结果的概率柱状图") 356 plt.bar(np.arange(3), pr2.reshape(3), align="center") 357 plt.xticks(np.arange(3),l2) 358 plt.show() 359 360 # 实际类型与h2模型预测结果对比 361 print('实际类型:' + l2[np.argmax(label2[i])]) 362 print('h2模型预测的结果是:' + l2[np.argmax(pr2)])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号