音视频基础概念
DTS与PTS
DTS:DecodeTimeStamp,用于标识读入内存的比特流什么时候送入解码器编码
PTS:PresentationTimeStamp,用于标识解码后的视频帧什么时候显示出来
GOP(Group Of Pictures)是图像组的概念,它指的是视频编码序列中两个 I 帧之间的距离。 通常意义上的 GOP 由 I 帧开始,到下一个 I 帧之前的帧结束。严格意义上讲,这个 I 帧是一个 IDR 帧。
视频帧、音频帧
视频帧常见的有IPB帧
I。关键帧,这一帧的画面完整保留。解码时根据本帧数据即可完成
P。差别帧。这一帧和上一个关键帧活P帧的差别。解码时需要根据之前缓存的画面叠加上本帧定义的差别生成最终画面
B。双向差别帧。这一帧记录的是本帧与前后帧的差别。换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,最后根据前后画面和本帧数据叠加得到最终画面。压缩率高。CPU吃力
音频帧
PCM(未经编码的音频数据)来说,他根本就不需要帧的概念,根据采样率和采样精度就可以播放。
AMR,规定每20ms是一帧,每一帧独立,可能采用不同的编码算法。
MP3帧包含更多数据,比如采样率,比特率。每一帧分为帧头和实体数据。长度不固定。
量化精度
量化精度越高,音乐的声压振幅越接近原音乐。CD标准的量化精度是16bit、DVD为24bit。可以理解为一个采样点多少bit表示
采样率
每秒音频采样点个数。用hz表示
采样与量化
图像的数字化和声音的数字化类似,最终都是要把模拟信号转换成数字信号,这种转换包括两个过程:采样量化
为了产生数字图像,必须把连续感知数据转换为数字形式,比如图像的坐标,会有无穷多个取值。连续的数据无法交由计算机处理,也无法在数字系统中传输与存储。所以必须将坐标值和颜色值数字化处理,转换为离散的数字信号。对坐标值的数字化称为采样,对颜色值的数字化称为量化。
量化2:表示把连续的颜色数据变成2种,只针对颜色。
采样1:16:表示在每16个坐标单位中取一个坐标,只针对坐标
声道
声卡多用立体声道
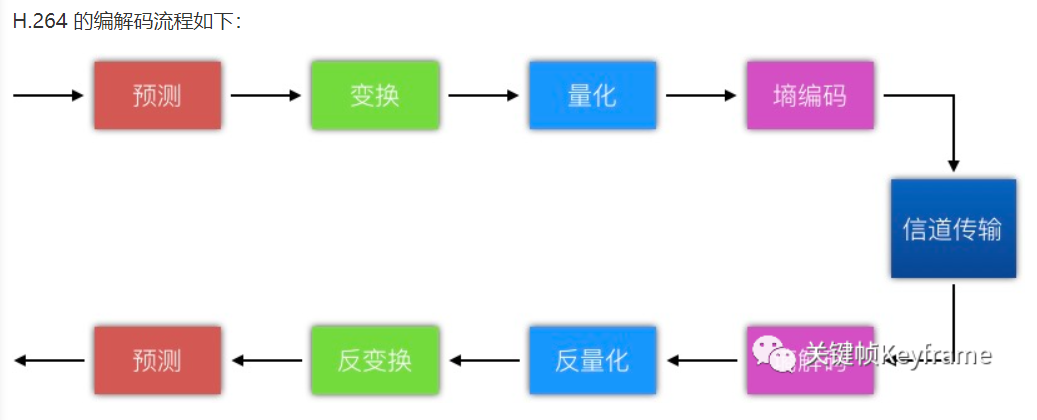
H.264编码
H.264 的主要目标是为了有高的视频压缩比和良好的网络亲和性,为了达成这两个目标, H.264 的解决方案是将系统框架分为两个层面
VCL(Video Coding Layer)视频编码层:负责高效的视频内容表示。VCL数据即编码处理的输出。表示被压缩编码后的饰品数据序列
NAL(Network Abstraction Layer)网络提取层:负责以网络锁要求的恰当方式来对数据进行打包和传送。
编码原理
H.264/AVC没有明确表示一个编解码器如何实现。而是规定了一个编码的视频比特流的句法和改比特流的解码方法。

H264采用变换和预测混合编码方式。看不懂
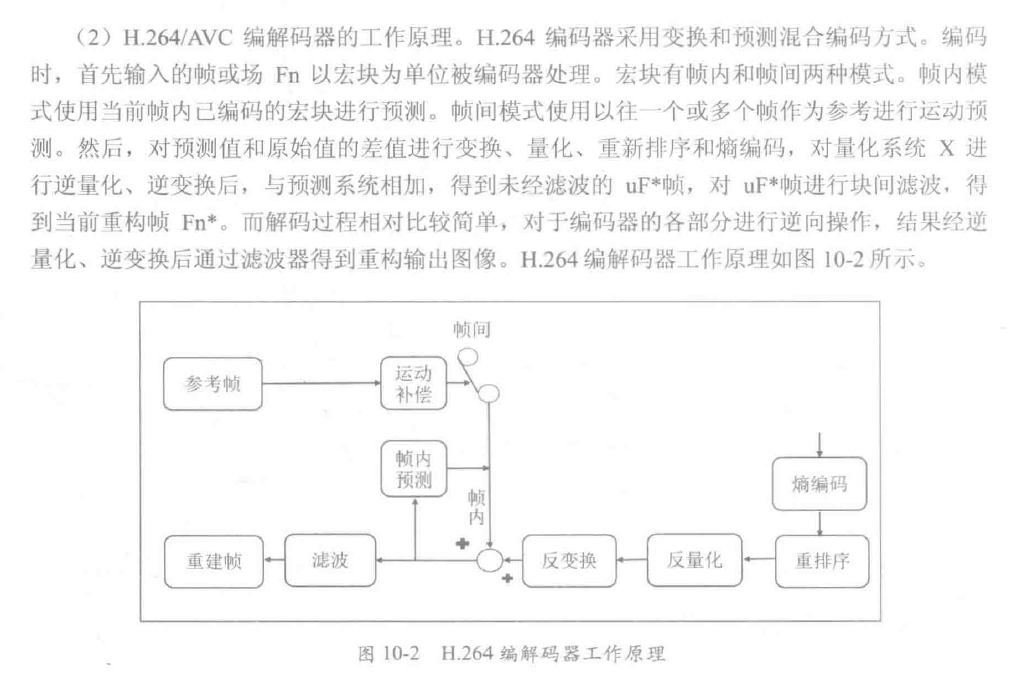
编码格式
VCL数据传输或存储之前,这些编码的VCL数据先被映射或封装进NAL单元中。
每个NAL单元包括一个RBSP(RAW BYTE SEQUENCE PAYLOAD)和一组对应于视频编码的NAL头信息。

NAL Header
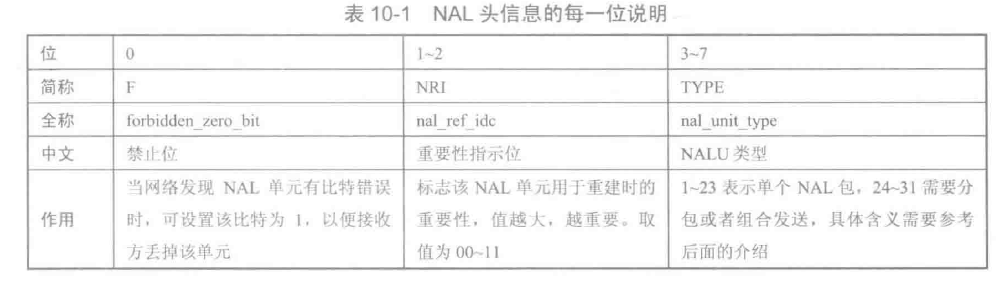
RBSP格式
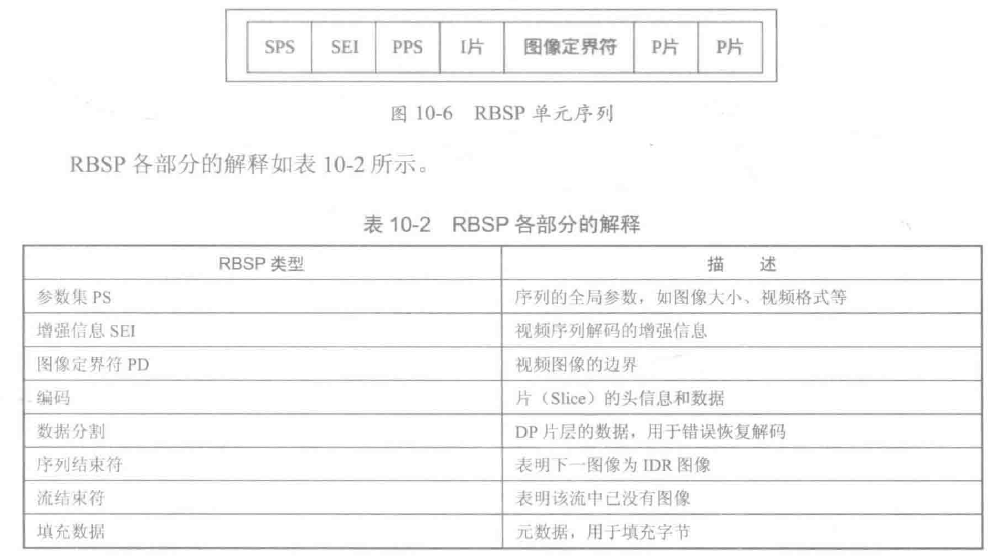
H264码流结构
NALU即NAL单元,用于传输或者存储。VCL是压缩编码后的视频数据系列。
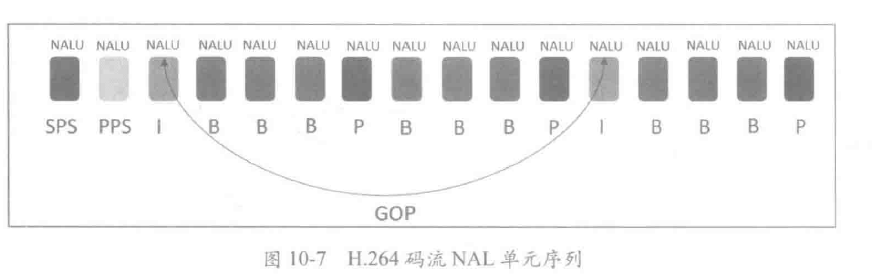
NALU类型如下:
SPS:序列参数集,作用于一系列连续的编码图像
PSS:图像参数集,作用于编码视频序列中一个或多个独立图像
参数集是一个独立的数据单位,不依赖于参数集以外的其他句法元素。一个参数据不对应某一个特定的图像或序列。一个参数集可以被一个或者多个图像引用。只有编码器认为需要更新参数及内容时,才会发出新的参数集
编码算法
H.264 采用的核心算法是『帧内压缩』和『帧间压缩』,帧内压缩是生成 I 帧的算法,帧间压缩是生成 B 帧和 P 帧的算法。
帧内压缩也称为空间压缩。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩率,跟编码 JPEG 差不多。
帧间压缩也称为时间压缩,它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
编码压缩的步骤大致如下:
- 分组,也就是将一系列变换不大的图像归为一个组,也就是一个序列,也就是 GOP;
- 定义帧,将每组的图像帧归分为 I 帧、P 帧和 B 帧三种类型;
- 预测帧,以 I 帧做为基础帧,以 I 帧预测 P 帧,再由 I 帧和 P 帧预测 B 帧;
- 数据传输,最后将 I 帧数据与预测的差值信息进行存储和传输。
编码工具
预测信号:根据当前信号做预测信号,可以是时间上的帧间预测,可以是空间上的帧内预测。
残差信号:根据预测信号和当前信号相减得到残差信号,只对残差信号编码,就可以去除一部分时间和空间上的冗余信息
变换:实际上,编码器不会直接对残差信号进行编码,还需要通过离散余弦变换,再量化,去除空间上和感知上的冗余信息。
熵编码:再通过熵编码,去除统计上的冗余信息
帧内预测
假设现在我们要对一个像素 X 进行编码,在编码这个像素之前,我们找到它临近的像素作为参考像素 X’,根据 X’ 我们经过预测算法得到对像素 X 的预测值 Xp,然后我们再用 X 减去 Xp 得到二者的残差 D,并用这个残差 D 代替 X 进行编码,起到节省码率的作用。最后,我们还用预测值 Xp 和残差 D 相加得到 X’ 用于下一个像素的预测。这个就是我们用帧内预测进行编码压缩的大体思想。
在实际编码中,我们固然可以按像素为单位进行预测,但这样效率比较低,所以在 H.264 标准中提出按照块为单位进行计算。
在帧内预测模式中,预测块是基于已编码重建的块和当前块形成的。对亮度像素而言,预测块用于 4×4 子块或者 16×16 宏块的相关操作。4×4 亮度子块有 9 种可选预测模式,独立预测每一个 4×4 亮度子块,适用于带有大量细节的图像编码;16×16 亮度块有 4 种预测模式,预测整个 16×16 亮度块,适用于平坦区域图像编码;色度块也有 4 种预测模式,类似于 16×16 亮度块预测模式。编码器通常选择使预测块和编码块之间差异最小的预测模式。
帧间预测
帧间预测就是时域预测,旨在消除时域冗余信息,简单点说就是利用之前编码过的图像来预测要编码的图像。其中涉及到两个重要的概念:运动估计和运动补偿。
运动估计是寻找当前编码的块在已编码的图像(参考帧)中的最佳对应块,并且计算出对应块的偏移(运动矢量)。
运动补偿是根据运动矢量和帧间预测方法,求得当前帧的估计值过程。其实就是将运动矢量参数贴到参考帧上获取当前帧。另外运动补偿是一个过程。
H.264 帧间预测是利用已编码视频帧/场和基于块的运动补偿的预测模式。与以往标准帧间预测的区别在于块尺寸范围更广(从 16×16 到 4×4)、亚像素运动矢量的使用(亮度采用 1/4 像素精度 MV)及多参考帧的运用等等。
变换与量化?
空间域的图像变换到频域或所谓的变换域,会产生相关性很小的一些变换系数,并可对其进行压缩编码,即所谓的变换编码
量化过程根据图像的动态范围大小确定量化参数,既保留图像必要的细节,又减少码流
熵编码?
熵的大小与信源的概率模型有着密切的关系,各个符号出现的概率不同,信源的熵也不同。当信源中各事件是等概率分布时,熵具有极大值。信源的熵与其可能达到的最大值之间的差值反映了该信源所含有的冗余度。信源的冗余度越小,即每个符号所独立携带的信息量越大,那么传送相同的信息量所需要的序列长度越短,符号位越少。因此,数据压缩的一个基本的途径是去除信源的符号之间的相关性,尽可能地使序列成为无记忆的,即前一符号的出现不影响以后任何一个符号出现的概率。
利用信源的统计特性进行码率压缩的编码就称为熵编码,也叫统计编码。熵编码是无损压缩编码方法,它生成的码流可以经解码无失真地恢复出原数据。熵编码是建立在随机过程的统计特性基础上的。
视频编码常用的有两种:变长编码(哈夫曼编码)、算术编码。

