Python之路(四十):RabbitMQ消息队列
RabbitMQ
RabbitMQ 是信息传输的中间者。本质上,从生产者(producers)接收消息,转发这些消息给消费者(consumers)。换句话说,能够根据指定的规则进行消息转发,缓冲,和持久化
在Python中使用RabiitMQ需要安装一个pika模块
直接pip install pika
我这里使用自己的虚拟机安装RabiitMQ作为服务端
首先需要这样写
import pika
credentials = pika.PlainCredentials('miracle', 'admin123')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='替换为自己的ip', credentials=credentials))
channel = connection.channel()
先导入pika模块
因为我这里是连接的远程服务器,所以需要免不了身份验证
pika.PlainCredentials('用户名',‘密码’) # 注意,这里连接成功的条件是需要在服务器设置允许远程访问的
然后创建连接对象,pika.BlockingConnetion(pika.ConnectionParameters(host=ip地址,credentials=身份验证的对象))
最后需要创建频道,用connect对象创建
channel = connection.channel()
之后的操作都是基于channel,可以把它理解为与RabbitMQ通信的一个渠道
然后需要声明队列名称,相当于创建一个新的队列,因为RabbitMQ可以同时有很多队列,但是每个队列的名字都必须唯一
channel.queue_declare(queue='test_queue')
然后就是发送消息了
channel.basic_publish(exchange=' ', routing_key='test_queue', body='hello rabbit' ) channel.close()
解释一下参数:exchange后面做解释,routing_key代表需要发送消息的队列的名称,Body代表消息的内容
完整版代码:
__author__ = 'Miracle'
__date__ = '2018/11/22 10:55'
import pika
credentials = pika.PlainCredentials('miracle', 'admin123')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='119.23.46.9', credentials=credentials))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='test_queue')
# exchange 代表交换机, routing_key代表队列名称, body为发送的消息内容
channel.basic_publish(
exchange='',
routing_key='test_queue',
body='hello rabbitmq'
)
print('send success')
channel.close()
说完了发送端,来看看接收端
开头都是一样的 需要连接到远程的RabbitMQ
__author__ = 'Miracle'
__date__ = '2018/11/22 11:12'
import pika
cre = pika.PlainCredentials('miracle', 'admin123')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='自己的ip', credentials=cre))
channel = connection.channel()
# 声明队列
channel.queue_declare('test_queue')
然后需要写一个回调函数
def call_back_func(ch, method, properties, body):
print('recv msg success')
print(body)
channel.basic_consume(call_back_func, queue='test_queue', no_ack=True)
# 死循环 一直接收数据
channel.start_consuming()
这样子我们就能基本使用RabbitMQ来做消息收发了
B,acknowledgment 消息反馈机制 确认(消息不丢失)
no-ack = False,如果消费者由于某些情况宕了,那 RabbitMQ 会重新将该任务放入队列中。
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑…..
__author__ = 'Miracle'
__date__ = '2018/11/22 11:12'
import pika
import time
cre = pika.PlainCredentials('miracle', 'admin123')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='自己的ip', credentials=cre))
channel = connection.channel()
# 声明队列
channel.queue_declare('test_queue')
def call_back_func(ch, method, properties, body):
print('recv msg success')
print(body)
time.sleep(20)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(call_back_func, queue='test_queue')
# 死循环 一直接受数据
channel.start_consuming()
当把no_ack去掉或者该为False的时候,是收到消息后需要确认的
需要添加ch.basic_ack(delivery_tag = method.delivery_tag)作为回应,否则消息将一直存在队列中,下一个连接将会收到上一条没做出回应的消息
C,durable 消息持久化存储(队列,消息不丢失)
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储:
将队列(Queue)与消息(Message)都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果需要对这种小概率事件也要管理起来,那么要用到事务。由于这里仅为RabbitMQ的简单介绍,所以不讲解RabbitMQ相关的事务。
队列持久化呢就是在声明队列的时候加上一个参数
channel.basic_declare(queue='test_queue', durable=True)
但是光队列持久化没用,因为即使队列还在但是队列里面的数据不在了也是没用的
所以我们还需要要消息也变成持久化
# delivery_mode = 2就是说明此消息持久化存储
property=pika.BasicProperties(delivery_mode=2)
在发消息的时候加上上面这句
D,Fair dispatch(公平调度)
上面实例中,虽然每个工作者是依次分配到任务,但是每个任务不一定一样。可能有的任务比较重,执行时间比较久;有的任务比较轻,执行时间比较短。如果能公平调度就最好了,使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,即只有工作者完成任务之后,才会再次接收到任务。
channel.basic_qos(prefetch_count=1) # 只有当前任务完成后,才会再次接受到任务
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, properties, body):
print("received msg...start processing....",body)
time.sleep(20)
print(" [x] msg process done....", body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
callback,
queue='task_queue',
no_ack=False # 默认为False
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
E,发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
如果需要将消息广播出去,让每个接收端都能收到,那么就要使用交换机。
交换机的工作原理:消息发送端先将消息发送给交换机,交换机再将消息发送到绑定的消息队列,而后每个接收端都能从各自的消息队列里接收到信息。
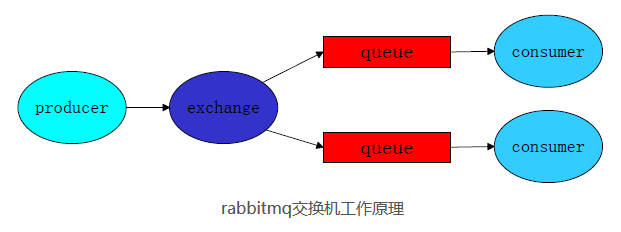
- exchange如果为空,表示是使用匿名的交换机。
- routing_key在使用匿名交换机的时候才需要指定,表示发送到哪个队列的意思。
转发器可分为三种类型,如下
I,fanout
白话来讲,类似于收听广播,具有实时性。
较于之前的,作了俩个改动
- 定义交换机 # exchange
- 不是将消息发送到hello队列,而是发送到交换机
-
__author__ = 'Miracle' __date__ = '2018/11/22 10:55' import pika credentials = pika.PlainCredentials('miracle', 'admin123') connection = pika.BlockingConnection(pika.ConnectionParameters(host='119.23.46.9', credentials=credentials)) channel = connection.channel() # 声明交换机 channel.exchange_declare(exchange='msg', type='fanout') channel.queue_declare(queue='test_queue', durable=True) # exchange 代表交换机, routing_key代表队列名称, body为发送的消息内容 channel.basic_publish( exchange='msg', routing_key='', body='hello rabbitmq', # delivery_mode = 2就是说明此消息持久化存储 property=pika.BasicProperties(delivery_mode=2) ) print('send success') channel.close()主要改动就是声明了交换机。 channel.exchange_declare(exchange='msg', type='fanout')
- 另外在发送消息那里,参数有变化,因为使用了广播,所以不再指定某一个频道了。所以routing_key设置为空,而exchange填上上面声明的exchange
较于之前的接收端,也主要作了俩处改动
- 定义交换机
- 不使用hello队列了,随机生成一个临时队列,并绑定到交换机上
__author__ = 'Miracle' __date__ = '2018/11/22 11:12' import pika import time cre = pika.PlainCredentials('miracle', 'admin123') connection = pika.BlockingConnection(pika.ConnectionParameters(host='119.23.46.9', credentials=cre)) channel = connection.channel() # 定义交换机 channel.exchange_declare(exchange='msg', exchange_type='fanout') result = channel.queue_declare(exclusive=True) name = result.method.queue channel.queue_bind(exchange='msg', queue=name) def call_back_func(ch, method, properties, body): print('recv msg success') print(body) time.sleep(20) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(call_back_func, queue=name) # 死循环 一直接受数据 channel.start_consuming()
接收端的改动主要是也声明了交换机,因为多个接收端需要同时接受消息,所以不能公用一个队列
声明队列的时候如果不指定队列名字,就会自动生成一个临时的队列,而如果加上exclusive=True的话,表示退出后自动销毁创建的临时队列
可以用一个变量来接受创建的临时队列,然后通过method.queue能取到队列的名字
最后,通过channel的queue_bind()方法来将创建的临时队列与交换机绑定在一起就能实现广播了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号