语境学习(in-context-learning)
(高级机器学习的作业,反正写了干脆搬过来)
4.1 引言
请考虑这样一句话“该公司预计其营业利润会有所改善。”
可以发现,这句话的情感是积极向上的。我们期待如果把这句话输入给大语言模型,它能够返回“积极(Positive)”这样的词汇。
然而,如果我们直接把这句话输入给大模型,可以预见的是,模型很难理解我们给出这句话的意图。它也许会表示赞同,也许会进行续写,也许会做出其他意料之外的回答。
那么我们如何让模型理解我们的意图,或者说任务需求呢?
一个直观的思路或许是预训练或者微调。我们只要在训练数据中加入足够多的对话情感识别数据,模型就有希望在遇见“该公司预计其营业利润会有所改善。”这句话时返回“积极(Positive)”。
不过,训练的开销可能是无法承受的。训练需要获取足够多的数据,消耗一定的计算资源和时间。此外,如果换成另外一个任务——例如预测这句话所描述事实的类别——那么就需要重新训练了,这些开销都是难以接受的。
所以,单纯依赖预先的训练或者微调,无法涵盖所有的情形。对于这样需求频繁变化的、和语境(context)紧密相关的任务,模型是很难出色完成的。
既然某些问题需要依赖特定的语境,那么是否可以有这样一种方式,让模型通过上下文或语境判断此时应当做出的回复?这便是本章要介绍的语境学习(in-context Learning)
语境学习(in-context Learning)能让模型在推理过程中学习。通过简单的任务说明或少量的标签数据即可以灵活地处理不同的任务。
比如,当我们期待模型完成情感识别任务时,可以额外增添几个例子。能够让模型通过类比的方式把握任务内容。当我们期待模型完成语句分类任务时,同样可以使用其他的例子,让模型意识到需要输出语句对应的类别,而不是做出其他回复。
整个流程可以用下图表示

可以发现,对于同样的内容,通过不同的语境信息进行引导,模型便有可能通过语境内容进行学习,得出用户所期待的回复。
而这些例子只要和最后的“该公司预计其营业利润会有所改善”一并输入即可,无需额外的训练开销,对于频繁更改需求的场景,这显然是有巨大价值的。
除了语境学习之外,本章也会探讨大模型的预训练方法,并通过GLM-130B模型作为案例逐一解读大模型预训练的各个步骤。
4.2 语境学习的概念
实际上,引言中的例子里,我们已经把语境学习的相关过程已经涉及一二。
语境学习,实质上是一种通过类比进行学习的手段。使用时,只需要提供构造好的语境,模型便可以根据提供的语境学习得到任务目标以及任务意图。换言之,语境学习通过构造语境来辅助定义任务,以举例的方式让模型更好地完成特定的任务。
值得指出的是,语境学习的“学习”,与通常机器学习算法中的“学习”有些不同。通常意义下,机器学习中的“学习”需要经过数据训练,以反向传播等方式更新有关模型参数。而语境学习中的“学习”,并非要修改模型的参数,而是把“训练”要用的数据和待推理的问题合并作为输入,全部送入大模型中。
所以,语境学习是在推理过程中的学习,并不需要额外的训练阶段,从宏观模型使用上来看,与直接做推理并无二至。语境学习与传统意义上需要训练参数的学习相同之处在于,均需要构建一定的数据。只是前者无需训练过程。
提及数据,还应当说明的是,在传统机器学习中,往往需要构建足够多的数据集(这甚至可能需要百万条),才能获得优秀的效果;而语境学习中,仅需要很少量数据(往往个位数),甚至无需数据,便可以较好的达到所期待的目标。
使用少量数据进行语境学习的方法称为“few-shot”,而无需数据直接推理的方法称为“zero-shot”. 关于语境学习中,few-shot与zero-shot为什么有效的话题,我们放在后面的章节进行讨论。
4.3 语境构建
4.3.1 输入模板
构建语境时,可以包含如下内容:
①任务描述(可选)
②举例(作为样例)
③提示词(问题描述)
一个可行的例子如下图:

4.3.2 样例选取
样例选取应当兼顾正确性,多样性,同时应当考虑输入-输出映射的影响,以及语境示例的偏置。
事实上,在这些因素中,保证样例-提示词数据分布的一致性是非常重要的。因为这能够把模型指引到正确的标签空间中。而更多的样例数据总体上能够带来收益,但这也并不绝对,更多的样例数据也可能带来负面作用(参考4.3.1中的实验分析),而且更多的样例也对模型的上下文提取能力做出了更高的要求。在这两点的基础上,如果样例能够提供正确的标签,那么这将给模型能力带来进一步提升。
除了上述技巧外,如何通过提示词的设计,让模型的语境学习推理能力获得更好的提升呢?思维链(Chain of thought)或许是一种可行的方法。
4.3.3 样例设计与思维链
1. 思维链
朴素的few-shot方法在需要强大推理能力的任务上表现不尽如人意。比如对于如下的场景:

提示词中是一道需要计算的数学题目,而在样例中,仅简单地提供了另外一道数学题的答案。可以想到的是,这种样例对模型语境学习的能力提升是十分有限的,模型难以从样例中获取较多的灵感来对提示词中的问题进行准确的回复。
而思维链的语境设计方式,则是通过自然语言的形式,对样例中的答案获得过程做出解释,或者说阐述了为什么该问题应当对应该答案。
以上述数学题为例,在样例的答案环节增加计算过程,向模型解释为什么能够计算得到11这个答案。从实验结果来看,在语境中增加了思维链后的模型给出了正确的回复以及理由。
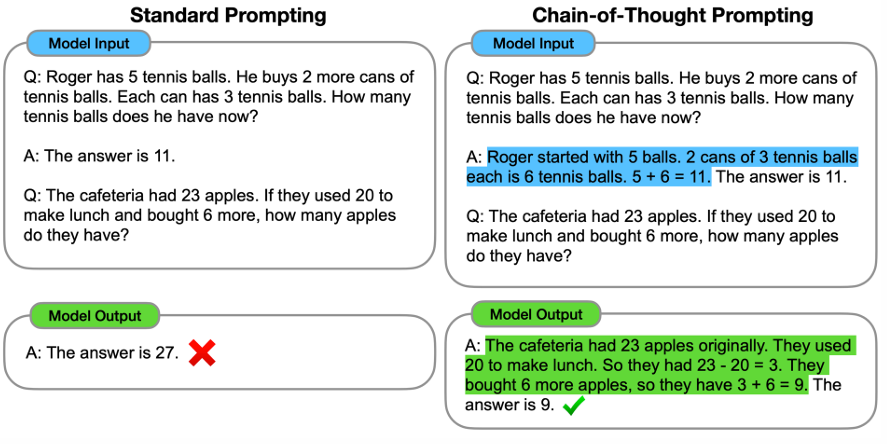
总而言之,思维链通过用“元数据”(即推理过程)做引导的方式,提升了语言模型处理更复杂问题的能力。
2. 思维链下的语境学习
在Few-shot方式下,使用思维链的语境构建示例和输入输出流程由下图所示:
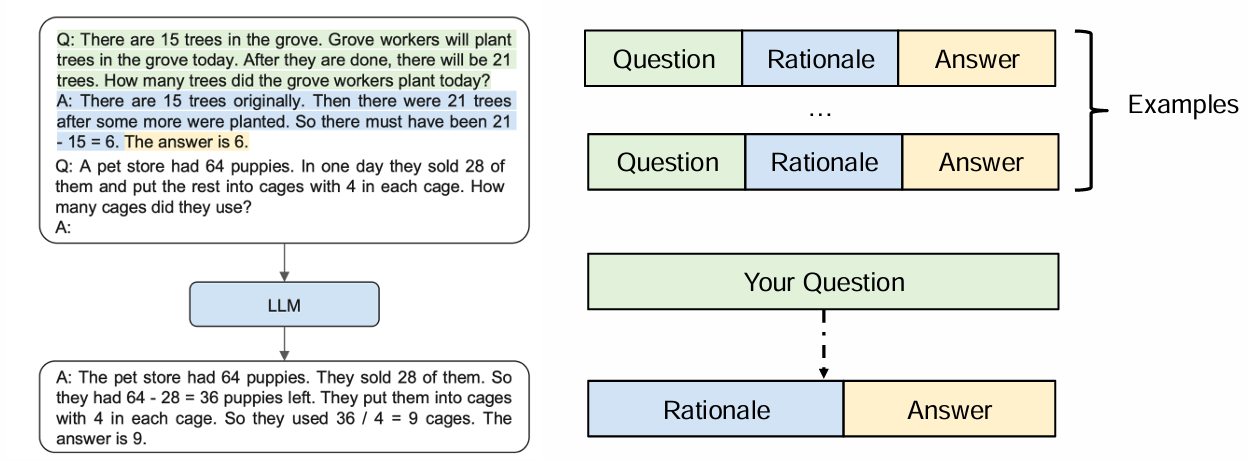
即先输入若干条样例,其中的每一条包含问题、理由(推理过程)、答案三个部分。最后输入向咨询的问题。期待情况下,模型会给出推理过程,以及相应的答案。
在Zero-shot方式下,可以通过在咨询的问题后添加“请一步一步地想”作为引导,以激活模型的推理能力。使用思维链的语境构建示例和输入输出流程可由下图所示:

实验验证表明了思维链方法的确可以激活模型地推理能力,并很大程度上提升了模型在多步骤推理任务上的表现。
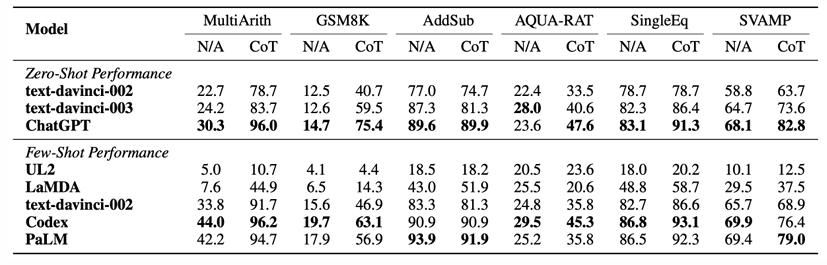
4.4 语境学习的理解
探究语境学习的效果受哪些因素影响。可能的因素包括:样例标签准确性,样例数据和训练数据的分布是否一致,样例数据的数量,输入语境格式等。
4.4.1.实验测试
Meta发表的文章Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 对语境学习有效的原因做出了探讨,并通过大量的实验进行了探究。
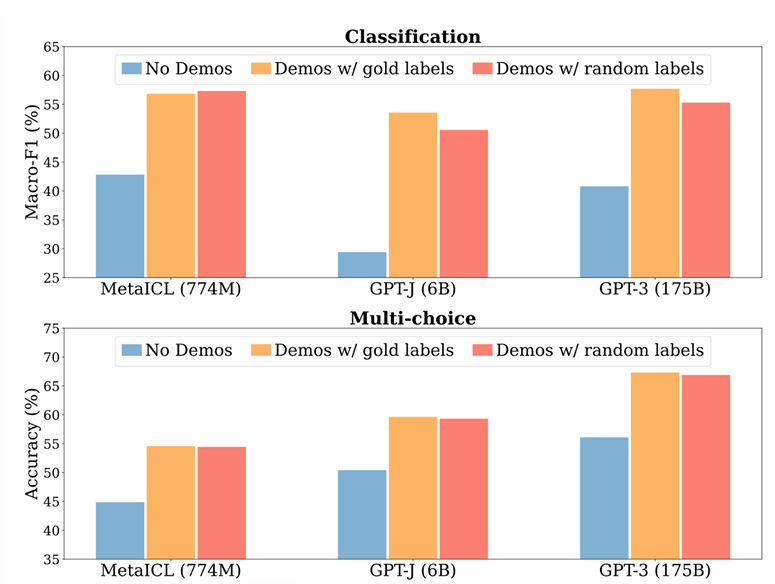
实验发现,即使样例的标签是随机生成的,大模型仍然能有一定概率分类正确。相比于提供正确的标签,精度上仅有细微的下降。而不提供标签的情况下,模型回答精度则下降较为明显。这种现象在不同大小的模型上均有所体现。
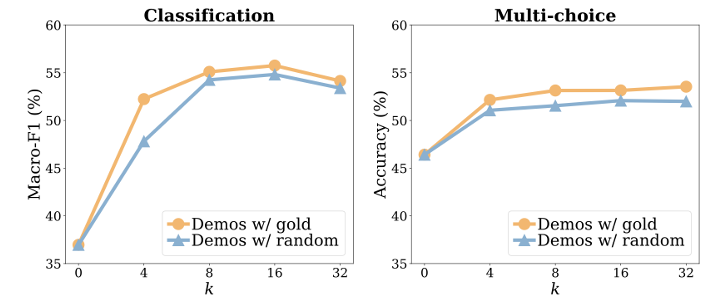
此外,样例的数目也会影响模型回答的准确程度。可以看到,无论是分类任务还是多选任务,即使仅仅使用4各样例,仍然能够大幅度提升模型的回答准确度。此外,当k大于等于8时,样例数目增长带来的提升就不那么明显了。同时,通过比较标签是随机的还是完全正确的这两条折线,依然可以发现样例标签的准确性似乎对模型能力的影响不是很大。
所以可以初步得出如下的结论:语境学习主要获益于对标签空间的监控,或者说激活了预训练/微调时标签空间相关的参数。而至于其他方面,比如标签的正确性等,则较容易从训练时习得的数据中还原出来。
进一步地,为了探究样例数据分布和提示词中的问题分布是否一致对模型预测准确度的影响,该论文使用分布上不同的数据作为样例进行了测试。实验结果如下(这里ppt上的图错了,我从原文找了图)
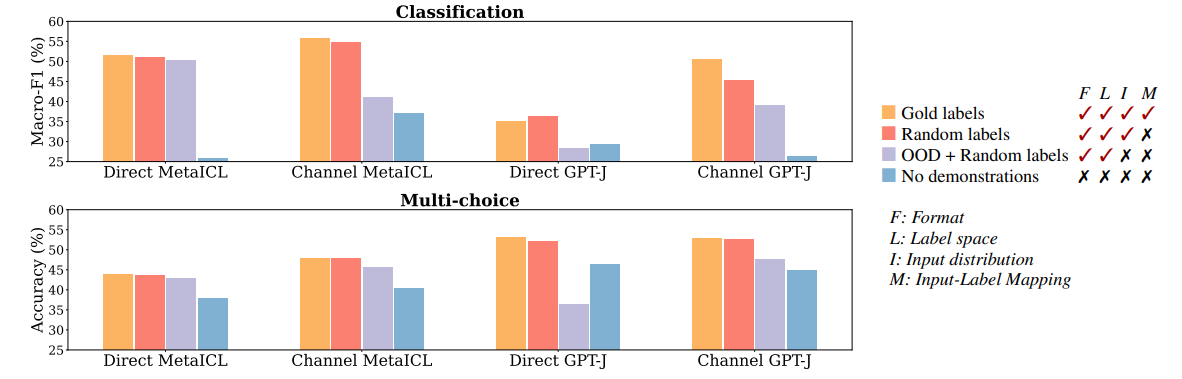
比较图中红色与浅紫色的柱形可以发现,在同样使用随机标签的情况下,使用和提示词数据分布不同(Out-of-Distribution,OOD)的数据作为样例,会导致于精度的显著下降(除了MetaICL)。
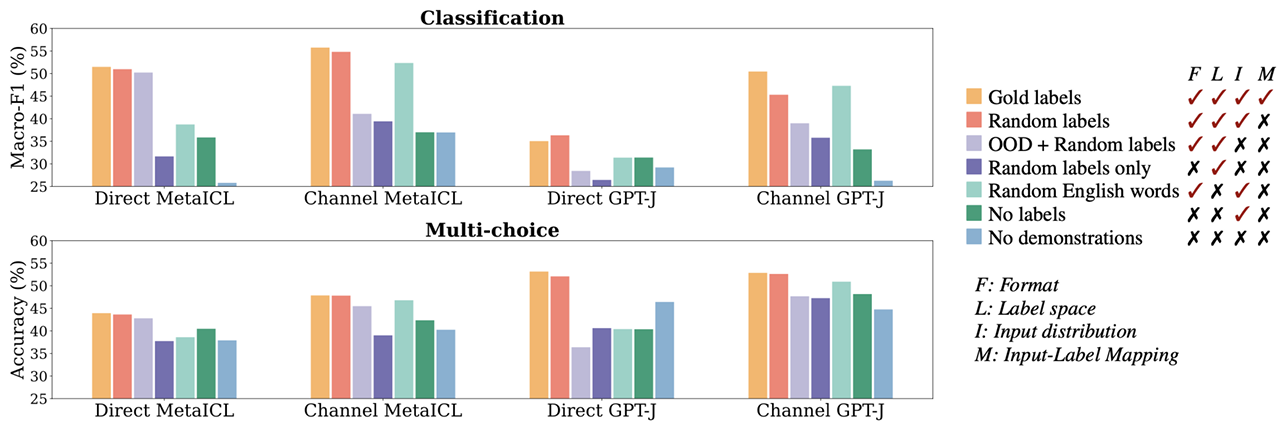
随后,该文章探究了语境输入格式对回复精度的影响,从下图中可以看到,如果不保持规范的输入格式,整体上模型的表现会更差。
4.4.2 理论推导
在进行理论推导前,首先让我们回顾语境学习和微调方式的关联性。
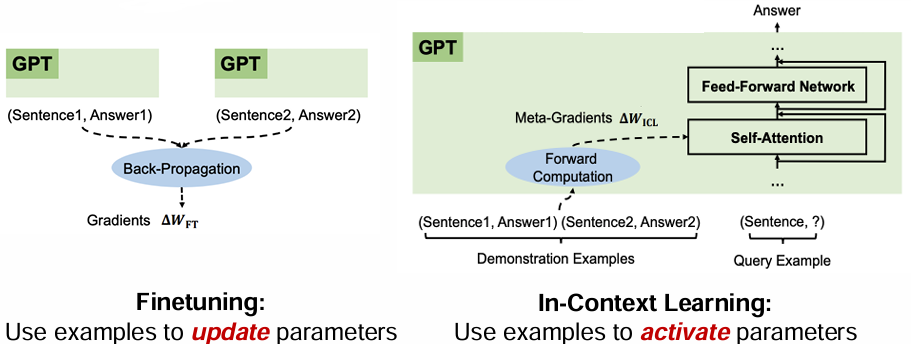
通过对比可以发现,微调实际上是用样例更新模型参数,而语境学习是用样例去激活模型参数。而微调之所以能成功,是因为反向传播时的梯度下降方法恰当地更新了模型的参数。而实际上,语境学习过程也可以类比梯度下降。
文章《Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers》对此进行了阐述。
语境学习中的注意力模块计算公式如下:
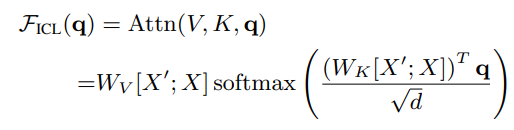
其中,X'为语境学习中输入的样例,X则为提示词中出现的问题。而q可以认为是当前阶段查询的token.
当忽略softmax函数以及标准化处理后,可以规约为下面的式子:
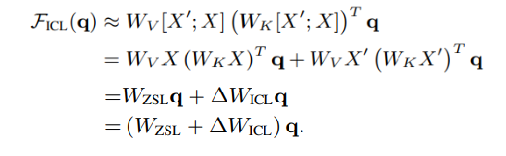
Wzsl表示Zero-shot涉及的权重,ΔWICL则表示通过增添样例带来的权重变化。
而微调后使用Zero-shot的计算方式可以写作下式:
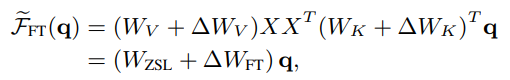
其中Wzsl仍然表示Zero-shot涉及的权重,ΔWFT则表示在初始模型基础上经过微调带来的权重变化。
通过类比观察可知,微调与语境学习在参数激活角度上是殊途同归的。所以,已知使用梯度下降的微调更新参数的方式能够带来性能上的提升,那么通过语境学习中的样例激活相关的参数便也同样能获得性能上的改善。
4.5 模型涌现能力
4.5.1 规模增长带来的收益

可以看到GPT-3和LaMDA等模型表明,随着模型和计算规模扩大,性能持续提高,在多个任务上展现出更强能力。此外,仍然可以发现,在某些任务上,模型在达到一定规模前性能随机,之后显著提升,且一个基础模型有潜力处理多种任务。
大模型(约100B参数或1023FLOPs)的这种能力被称作涌现能力,即在较小模型中不存在但在大模型中出现的能力。
对于数学能力,指令遵循,多步推理,程序执行等更困难的任务,模型数据量的增长依然可以带来性能上的提升,而且一定范围内,能力可以呈指数级上涨。这仍然是涌现能力的体现。
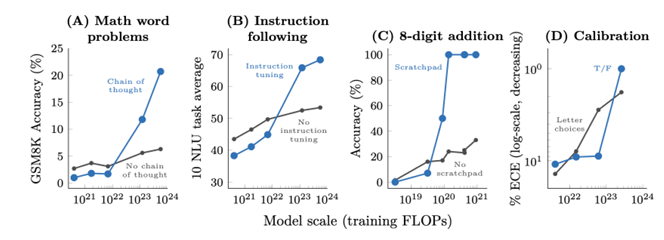
4.5.2 涌现能力的来源
可以看到,当模型参数规模上涨到一定程度时,在某些任务上的预测精度陡然提升,模型瞬间获得了解决这种问题的能力。此外,这种能力的获得也是不可预测的,发生精度陡然提升时所需要的模型参数随着任务的不同而不同。
这种涌现能力是从何而来呢?
文章《Understanding Emergent Abilities of Language Models from the Loss Perspective》对此进行了讨论。
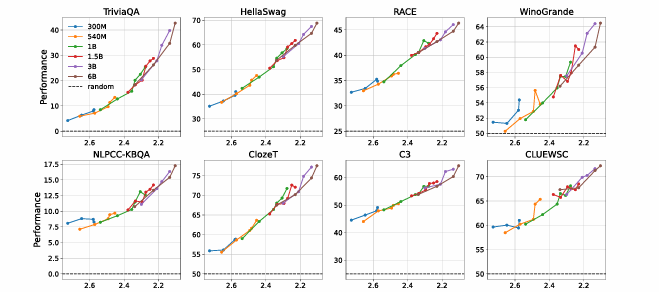
文章中,作者训练一系列具有不同大小和训练标记的语言模型,发现不同大小的数据点和训练token在很大程度上落在相同的趋势曲线上。换句话说,无论token计数和模型大小如何,具有相同预训练损失的语言模型在不同的语言、任务和提示格式上表现出相同的性能。
而参数量更大的模型能够将训练损失进一步降低,从而获得性能上的提升。

如上图所示,再进一步分析模型效果与训练损失,可以发现,训练前损失减小到2.2左右之前,三种不同规模的模型性能都在随机水平上。而当损失降到2.2及以下时,模型能力陡然攀升。受参数规模影响,蓝色点所代表的小模型无法进一步降低损失,停留在了随机预测的水平;而绿色、橙色代表的更大的模型则通过不断训练降低了损失,从而获得了涌现能力。
这同样说明在损失函数相同的情形下,不同规模的模型预测能力相近。而更大的模型能更好地学习训练数据,降低了损失,从而提升了性能。对涌现能力的认识,大大指导了模型训练的过程。
4.5.2 语境学习能力与规模
本节介绍了不同数据规模/参数规模情况下语境学习的能力,以及相关因素给预测精度带来的影响。
1 标签翻转与参数量规模
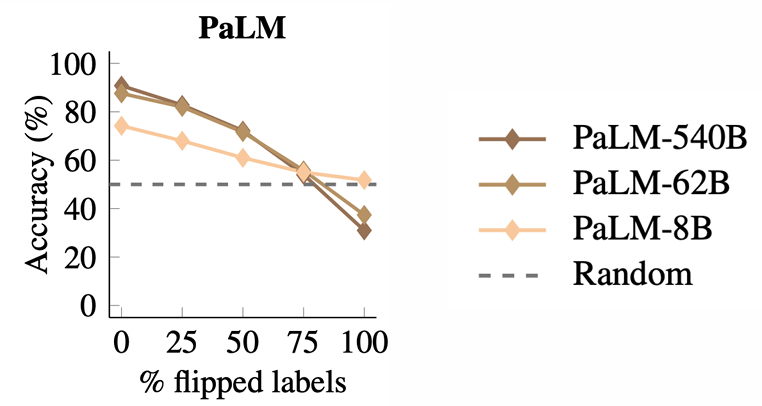
当语境中的样例标签发生翻转时(即二分类任务,标签取反),参数规模越大的模型的预测精度受影响越大。且当所有的标签全部翻转后,62B和540B的PaLM模型甚至预测精度低于50%的随机猜测准确度,而8B的小模型则仍然能够保持大于50%预测精度的水平。
这说明虽然模型具备一定的纠错能力,但参数量越大的模型越会优先考虑语境中提供的内容,故容易受到语境样例的错误标签影响。
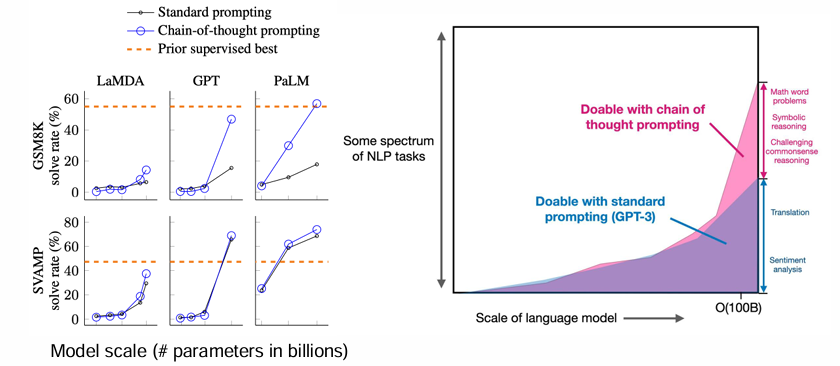
2 思维链与参数量规模
下图中的实验展示了随参数量规模增长,思维链方式带来的提升情况。可以看到,当参数量规模增长时,相比于普通的提示词设计方式(Standard prompt),思维链方式获得的提升更为显著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号