
【译】.NET 7 中的性能改进(十一)
原文 | Stephen Toub
翻译 | 郑子铭
同样,为了不做不必要的工作,有一个相当常见的模式出现在string.Substring和span.Slice等方法中。
span = span.Slice(offset, str.Length - offset);
这里需要注意的是,这些方法都有重载,只取起始偏移量。由于指定的长度是指定偏移量后的剩余部分,所以调用可以简化为。
span = span.Slice(offset);
这不仅可读性和可维护性更强,而且还有一些小的效率优势,例如,在64位上,Slice(int, int)构造函数比Slice(int)有一个额外的加法,而对于32位,Slice(int, int)构造函数会产生一个额外的比较和分支。因此,简化这些调用对代码维护和性能都是有益的,dotnet/runtime#68937对所有发现的该模式的出现都进行了简化。dotnet/runtime#73882使其更具影响力,它简化了string.Substring,以消除不必要的开销,例如,它将四个参数验证检查浓缩为一个快速路径比较(在64位进程中)。
好了,关于弦的问题就到此为止。那跨度呢?C# 11中最酷的功能之一是对Ref字段的新支持。什么是引用字段?你对C#中的引用很熟悉,我们已经讨论过它们本质上是可管理的指针,也就是说,由于它引用的对象在堆上被移动,运行时可以随时更新的指针。这些引用可以指向对象的开头,也可以指向对象内部的某个地方,在这种情况下,它们被称为 "内部指针"。Ref从1.0开始就存在于C#中,但那时它主要是通过引用传递给方法调用,例如
class Data
{
public int Value;
}
...
void Add(ref int i)
{
i++;
}
...
var d = new Data { Value = 42 };
Add(ref d.Value);
Debug.Assert(d.Value == 43);
后来的C#版本增加了拥有本地参考文献的能力,例如。
void Add(ref int i)
{
ref j = ref i;
j++;
}
甚至是要有 ref 的返回,例如
ref int Add(ref int i)
{
ref j = ref i;
j++;
return ref j;
}
这些设施更为先进,但它们在整个更高性能的代码库中被广泛使用,近年来.NET中的许多优化在很大程度上是由于这些与ref相关的能力而实现的。
Span
private T[] _items;
...
public T this[int i]
{
get => _items[i];
set => _items[i] = value;
}
但不是 span。Span
public ref T this[int index]
{
get
{
if ((uint)index >= (uint)_length)
ThrowHelper.ThrowIndexOutOfRangeException();
return ref Unsafe.Add(ref _reference, index);
}
}
注意这里只有一个getter,没有setter;这是因为它返回一个指向实际存储位置的ref T。它是一个可写的引用,所以你可以对它进行赋值,例如,你可以写。
span[i] = value;
但这并不等同于调用一些设置器。
span.set_Item(i, value);
它实际上等同于使用getter来检索引用,然后通过该引用写入一个值,比如说
ref T item = ref span.get_Item(i);
item = value;
这一切都很好,但是getter定义中的_reference是什么?好吧,Span
public readonly ref struct Span<T>
{
internal readonly ref T _reference;
private readonly int _length;
...
}
ref字段在整个dotnet/runtime中的推广是在dotnet/runtime#71498中完成的,此前C#语言主要是在dotnet/roslyn#62155中获得了这种支持,这本身就是许多PR的高潮,首先是一个特性分支。Ref字段本身不会自动提高性能,但它确实大大简化了代码,它允许使用ref字段的新自定义代码,以及利用它们的新API,这两者都可以帮助提高性能(特别是在不牺牲潜在安全的情况下的性能)。新API的一个例子是ReadOnlySpan
public Span(ref T reference);
public ReadOnlySpan(in T reference);
在dotnet/runtime#67447中添加的(然后在dotnet/runtime#71589中公开并更广泛地使用)。这可能会引出一个问题:考虑到跨度已经能够存储一个引用,为什么对引用字段的支持能够使两个新的构造函数接受引用?毕竟,MemoryMarshal.CreateSpan(ref T reference, int length)和相应的CreateReadOnlySpan方法已经存在了很长时间,而这些新的构造函数相当于调用那些长度为1的方法。 答案是:安全。
想象一下,如果你可以随意地调用这个构造函数。你就可以写出这样的代码了。
public Span<int> RuhRoh()
{
int i = 42;
return new Span<int>(ref i);
}
在这一点上,这个方法的调用者得到了一个指向垃圾的跨度;这在本应是安全的代码中是很糟糕的。你已经可以通过使用指针来完成同样的事情。
public Span<int> RuhRoh()
{
unsafe
{
int i = 42;
return new Span<int>(&i, 1);
}
}
但在这一点上,你已经承担了使用不安全代码和指针的风险,任何由此产生的问题都在你身上。在C# 11中,如果你现在试图使用基于Ref的构造函数来编写上述代码,你会遇到这样的错误。
error CS8347: Cannot use a result of 'Span<int>.Span(ref int)' in this context because it may expose variables referenced by parameter 'reference' outside of their declaration scope
换句话说,编译器现在理解Span
通常情况下,解决了一个问题,就会把罐子踢到路上,并暴露出另一个问题。编译器现在认为,传递给 ref 结构上的方法的 ref 可以使该 ref 结构实例存储该 ref(注意,传递给 ref 结构上的方法的 ref 结构已经是这种情况),但是如果我们不希望这样呢?如果我们想说 "这个 ref 是不可存储的,并且不应该逃出调用范围 "呢?从调用者的角度来看,我们希望编译器能够允许传入这样的 ref,而不抱怨潜在的寿命延长;从调用者的角度来看,我们希望编译器能够阻止方法做它不应该做的事情。进入作用域。这个新的C#关键字所做的正是我们所希望的:把它放在一个Ref或Ref结构参数上,编译器将保证(不使用不安全的代码)该方法不能把参数藏起来,然后使调用者能够编写依赖该保证的代码。例如,考虑这个程序。
var writer = new SpanWriter(stackalloc char[128]);
Append(ref writer, 123);
writer.Write(".");
Append(ref writer, 45);
Console.WriteLine(writer.AsSpan().ToString());
static void Append(ref SpanWriter builder, byte value)
{
Span<char> tmp = stackalloc char[3];
value.TryFormat(tmp, out int charsWritten);
builder.Write(tmp.Slice(0, charsWritten));
}
ref struct SpanWriter
{
private readonly Span<char> _chars;
private int _length;
public SpanWriter(Span<char> destination) => _chars = destination;
public Span<char> AsSpan() => _chars.Slice(0, _length);
public void Write(ReadOnlySpan<char> value)
{
if (_length > _chars.Length - value.Length)
{
throw new InvalidOperationException("Not enough remaining space");
}
value.CopyTo(_chars.Slice(_length));
_length += value.Length;
}
}
我们有一个Ref结构SpanWriter,它的构造函数接受一个Span
error CS8350: This combination of arguments to 'SpanWriter.Write(ReadOnlySpan<char>)' is disallowed because it may expose variables referenced by parameter 'value' outside of their declaration scope
我们该怎么做呢?Write方法实际上并没有存储参数值,而且也不需要,所以我们可以改变方法的签名,将其注释为范围。
public void Write(scoped ReadOnlySpan<char> value)
如果Write试图存储值,编译器会拒绝。
error CS8352: Cannot use variable 'ReadOnlySpan<char>' in this context because it may expose referenced variables outside of their declaration scope
但由于它没有尝试这样做,现在一切都编译成功了。你可以在前面提到的dotnet/runtime#71589中看到关于如何利用这个的例子。
还有另一个方向:有些东西是隐式范围的,比如结构上的this引用。考虑一下这段代码。
public struct SingleItemList
{
private int _value;
public ref int this[int i]
{
get
{
if (i != 0) throw new IndexOutOfRangeException();
return ref _value;
}
}
}
这将产生一个编译器错误。
error CS8170: Struct members cannot return 'this' or other instance members by reference
有效地,这是因为这是隐含的范围(尽管这个关键词以前并不存在)。如果我们想让这样的项目能够被返回呢?输入[UnscopedRef]。这在需求中是很罕见的,以至于它没有得到自己的C#语言关键字,但C#编译器确实识别了新的[UnscopedRef]属性。它可以被放到相关的参数上,也可以放到方法和属性上,在这种情况下,它适用于该成员的这个引用。因此,我们可以将之前的代码例子修改为:。
[UnscopedRef]
public ref int this[int i]
而现在代码将被成功编译。当然,这也对这个方法的调用者提出了要求。对于一个调用站点来说,编译器看到了被调用成员上的[UnscopedRef],然后知道返回的ref可能会引用该结构中的一些东西,因此给返回的ref分配了与该结构相同的生命周期。因此,如果该结构是一个生活在堆栈上的局部,那么该引用也将被限制在同一方法上。
另一个有影响的跨度相关的变化来自于dotnet/runtime#70095,来自@teo-tsirpanis。System.HashCode的目标是为产生高质量的哈希码提供一个快速、易于使用的实现。在其目前的版本中,它包含了一个随机的全进程种子,并且是xxHash32非加密哈希算法的实现。在之前的版本中,HashCode增加了一个AddBytes方法,该方法接受一个ReadOnlySpan
private byte[] _data = Enumerable.Range(0, 256).Select(i => (byte)i).ToArray();
[Benchmark]
public int AddBytes()
{
HashCode hc = default;
hc.AddBytes(_data);
return hc.ToHashCode();
}
| 方法 | 运行时 | 平均值 | 比率 |
|---|---|---|---|
| AddBytes | .NET 6.0 | 159.11 ns | 1.00 |
| AddBytes | .NET 7.0 | 42.11 ns | 0.26 |
另一个与跨度有关的变化,dotnet/runtime#72727重构了一堆代码路径,以消除一些缓存的数组。为什么要避免缓存数组?毕竟,缓存一次数组并反复使用它不是可取的吗?是的,如果那是最好的选择,但有时有更好的选择。例如,其中一个变化采取了这样的代码。
private static readonly char[] s_pathDelims = { ':', '\\', '/', '?', '#' };
...
int index = value.IndexOfAny(s_pathDelims);
并将其替换为以下代码。
int index = value.AsSpan().IndexOfAny(@":\/?#");
这有很多好处。在可用性方面的好处是使被搜索的令牌靠近使用地点,在可用性方面的好处是列表是不可改变的,这样某些地方的代码就不会意外地替换数组中的一个值。但也有性能方面的好处。我们不需要一个额外的字段来存储数组。我们不需要作为这个类型的静态构造函数的一部分来分配数组。而且,加载/使用字符串的速度也稍微快一些。
private static readonly char[] s_pathDelims = { ':', '\\', '/', '?', '#' };
private static readonly string s_value = "abcdefghijklmnopqrstuvwxyz";
[Benchmark]
public int WithArray() => s_value.IndexOfAny(s_pathDelims);
[Benchmark]
public int WithString() => s_value.AsSpan().IndexOfAny(@":\/?#");
| 方法 | 平均值 | 比率 |
|---|---|---|
| WithArray | 8.601 ns | 1.00 |
| WithString | 6.949 ns | 0.81 |
另一个例子来自该PR,其代码大致如下。
private static readonly char[] s_whitespaces = new char[] { ' ', '\t', '\n', '\r' };
...
switch (attr.Value.Trim(s_whitespaces))
{
case "preserve": return Preserve;
case "default": return Default;
}
并将其替换为以下代码。
switch (attr.Value.AsSpan().Trim(" \t\n\r"))
{
case "preserve": return Preserve;
case "default": return Default;
}
在这种情况下,我们不仅避免了char[],而且如果文本确实需要修剪空白处,新版本(修剪一个跨度而不是原始字符串)将为修剪后的字符串保存一个分配。这是在利用C#11的新特性,即支持在ReadOnlySpan
当然,在某些情况下,数组是完全不必要的。在那份PR中,有几个这样的案例。
private static readonly char[] WhiteSpaceChecks = new char[] { ' ', '\u00A0' };
...
int wsIndex = target.IndexOfAny(WhiteSpaceChecks, targetPosition);
if (wsIndex < 0)
{
return false;
}
通过改用跨度,我们也可以这样写。
int wsIndex = target.AsSpan(targetPosition).IndexOfAny(' ', '\u00A0');
if (wsIndex < 0)
{
return false;
}
wsIndex += targetPosition;
MemoryExtensions.IndexOfAny对两个和三个参数有专门的重载,这时我们根本不需要数组(这些重载也恰好更快;当传递一个两个字符的数组时,实现会从数组中提取两个字符并传递给同一个双参数的实现)。dotnet/runtime#60409删除了一个单字符数组,该数组被缓存以传递给string.Split,取而代之的是使用直接接受单字符的Split重载。
最后,来自@NewellClark的 dotnet/runtime#59670 摆脱了更多的数组。我们在前面看到了C#编译器是如何对用恒定长度和恒定元素构造的byte[]进行特殊处理的,并立即将其转换为ReadOnlySpan
正则 (Regex)
早在5月份,我就分享了一篇关于.NET 7中正则表达式改进的详细文章。回顾一下,在.NET 5之前,Regex的实现已经有相当长的时间没有被触动过了。在.NET 5中,我们从性能的角度出发,将其恢复到与其他多个行业的实现相一致或更好。.NET 7在此基础上进行了一些重大的飞跃。如果你还没有读过这篇文章,请你现在就去读,我等着你......
欢迎回来。有了这个背景,我将避免在这里重复内容,而是专注于这些改进到底是如何产生的,以及这样做的PR。
RegexOptions.NonBacktracking
让我们从Regex中较大的新功能之一开始,即新的RegexOptions.NonBacktracking实现。正如在上一篇文章中所讨论的,RegexOptions.NonBacktracking将Regex的处理转为使用基于有限自动机的新引擎。它有两种主要的执行模式,一种是依靠DFA (deterministic finite automata)(确定的有限自动机),一种是依靠NFA (non-deterministic finite automata)(非确定的有限自动机)。这两种实现方式都提供了一个非常有价值的保证:处理时间与输入的长度成线性关系。而反追踪引擎 (backtracking engine)(如果没有指定NonBacktracking,Regex就会使用这种引擎)可能会遇到被称为 "灾难性反追踪 (catastrophic backtracking)"的情况,即有问题的表达式与有问题的输入相结合会导致输入长度的指数级处理,NonBacktracking保证它只会对输入中的每个字符做一个摊薄的恒定量。在DFA的情况下,这个常数是非常小的。对于NFA,这个常数可以大得多,基于模式的复杂性,但对于任何给定的模式,工作仍然是与输入的长度成线性关系。
NonBacktracking的实现经历了大量的开发工作,它最初是在dotnet/runtime#60607中被加入到dotnet/runtime中。然而,它的原始研究和实现实际上来自微软研究院(MSR),并以MSR发布的Symbolic Regex Matcher (SRM)库的形式作为一个实验包提供。在现在的.NET 7的代码中,你仍然可以看到它的痕迹,但它已经有了很大的发展,在.NET团队的开发人员和MSR的研究人员之间进行了紧密的合作(在被集成到dotnet/runtime之前,它在dotnet/runtimelab孵化了一年多,原始的SRM代码是通过dotnet/runtimelab#588从@veanes那里拿来的)。
这个实现是基于正则表达式导数的概念,这个概念已经存在了几十年(这个术语最初是由Janusz Brzozowski在20世纪60年代的一篇论文中提出的),并且在这个实现中得到了很大的改进。Regex衍生物构成了用于处理输入的自动机(考虑 "图")的基础。其核心思想是相当简单的:取一个词组并处理一个字符......你得到的描述处理这一个字符后剩下的新词组是什么?这就是导数。例如,给定一个匹配三个字的词组 w{3},如果你把这个词组应用于下一个输入字符'a',那么,这将剥去第一个 w,留给我们的是衍生词 `w{2}。很简单,对吗?那么更复杂的东西呢,比如表达式.(the|he)。如果下一个字符是t会怎样?那么,t有可能被模式开头的.所吞噬,在这种情况下,剩下的重组词将与开头的重组词(.(the|he))完全相同,因为在匹配t之后,我们仍然可以匹配与没有t时完全相同的输入。但是,t也可能是匹配the的一部分,并且应用于the,我们将剥离t并留下he,所以现在我们的导数是.(the|he)|he。那么原始交替中的 "他 "呢?t不匹配h,所以导数将是空的,我们在这里表示为一个空的字符类,得到.(the|he)|he|[]。当然,作为交替的一部分,最后的 "无 "是一个nop,所以我们可以将整个派生简化为.(the|he)|he...完成。这只是针对下一个t的原始模式的应用,如果是针对h呢?按照与t相同的逻辑,这次我们的结果是.(the|he)|e。以此类推。如果我们从h的导数开始,下一个字符是e呢?在交替的左边,它可以被.消耗掉(但不匹配t或h),所以我们最后得到的是同样的子表达式。但是在交替关系的右侧,e与e匹配,剩下的就是空字符串()。.*(the|he)|()。在一个模式是 "nullable"(它可以匹配空字符串)的地方,可以认为是一个匹配。我们可以把这整个事情看成是一个图,每个输入字符都有一个过渡到应用它所产生的衍生物的过程。
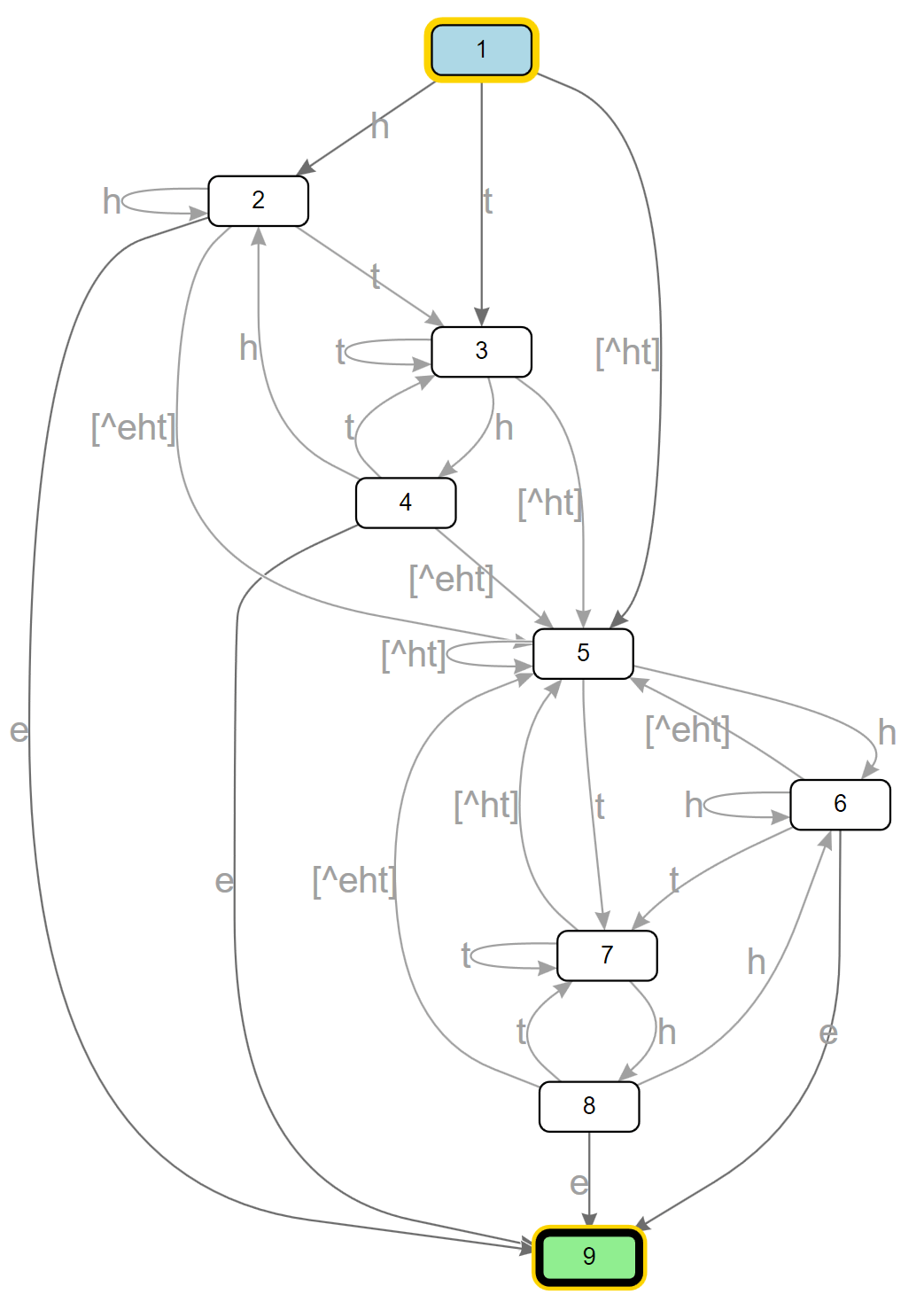
看起来非常像DFA,不是吗?它应该是这样的。而这正是NonBacktracking处理输入的DFA的构造方式。对于每一个楔形结构(连接、交替、循环等),引擎都知道如何根据正在评估的字符来推导出下一个楔形。这个应用是懒惰地完成的,所以我们有一个初始的起始状态(原始模式),然后当我们评估输入中的下一个字符时,它寻找是否已经有一个可用于该过渡的衍生工具:如果有,它就跟随它,如果没有,它就动态/懒惰地导出图中的下一个节点。在其核心,这就是它的工作方式。
当然,魔鬼在细节中,有大量的复杂情况和工程智能用于使引擎高效。其中一个例子是内存消耗和吞吐量之间的权衡。考虑到能够有任何字符作为输入,你可以有效地从每个节点中获得65K的转换(例如,每个节点可能需要一个65K的元素表);这将大大增加内存消耗。然而,如果你真的有那么多的转换,很有可能其中大部分都会指向同一个目标节点。因此,NonBacktracking保持了自己对字符的分组,称之为 "minterms"。如果两个字符有完全相同的过渡,它们就属于同一个minterm。然后,过渡是以minterms为单位构建的,每个minterm从一个给定的节点中最多有一个过渡。当下一个输入字符被读取时,它将其映射到一个minterm ID上,然后为该ID找到合适的过渡;为了节省潜在的大量内存,增加了一层间接性。这种映射是通过一个数组位图来处理ASCII的,而一个高效的数据结构被称为二进制决策图(BDD),用于处理0x7F以上的一切。
如前所述,非反向追踪引擎在输入长度上是线性的。但这并不意味着它总是精确地查看每个输入字符一次。如果你调用Regex.IsMatch,它就会这样做;毕竟,IsMatch只需要确定是否存在匹配,而不需要计算任何额外的信息,比如匹配的实际开始或结束位置,任何关于捕获的信息等等。因此,引擎可以简单地使用它的自动机沿着输入行走,在图中从一个节点过渡到另一个节点,直到它达到最终状态或耗尽输入。然而,其他操作确实需要它收集更多的信息。Regex.Match需要计算一切,这实际上需要在输入上进行多次行走。在最初的实现中,Match的等价物总是需要三遍:向前匹配以找到匹配的终点,然后从终点位置反向匹配模式,以找到匹配的实际起始位置,然后再从已知的起始位置向前走一次,以找到实际的终点位置。然而,有了@olsaarik的dotnet/runtime#68199,除非需要捕获,否则现在只需两遍就能完成:一遍向前走以找到匹配的保证结束位置,然后一遍反向走以找到其开始位置。而来自@olsaarik的dotnet/runtime#65129增加了对捕获的支持,原来的实现也没有。这种捕获支持增加了第三道程序,一旦知道匹配的边界,引擎就会再运行一次正向程序,但这次是基于NFA的 "模拟",能够记录转换中的 "捕获效果"。所有这些都使得非反向追踪的实现具有与反向追踪引擎完全相同的语义,总是以相同的顺序和相同的捕获信息产生相同的匹配。这方面唯一的区别是,在逆向追踪引擎中,循环内的捕获组将存储在循环的每个迭代中捕获的所有值,而在非逆向追踪的实现中,只有最后一个迭代被存储。除此之外,还有一些非反追踪实现根本不支持的结构,因此在试图构建Regex时,尝试使用任何这些结构都会失败,例如反向引用和回看。
即使在它作为MSR的一个独立库取得进展之后,仍有100多个PR用于使RegexOptions.NonBacktracking成为现在的.NET 7,包括像@olsaarik的dotnet/runtime#70217这样的优化,它试图简化DFA核心的紧密内部匹配循环(如 读取下一个输入字符,找到适当的过渡,移动到下一个节点,并检查节点的信息,如它是否是最终状态),以及像@veanes的dotnet/runtime#65637这样的优化,它优化了NFA模式以避免多余的分配,缓存和重复使用列表和集合对象,使处理状态列表的过程中不需要分配。
对于NonBacktracking来说,还有一组性能方面的PR。无论使用的是哪种多重引擎,Regex的实现都是将模式转化为可处理的东西,它本质上是一个编译器,和许多编译器一样,它自然会倾向于递归算法。在Regex的情况下,这些算法涉及到正则表达式结构树的行走。递归最终成为表达这些算法的一种非常方便的方式,但是递归也存在堆栈溢出的可能性;本质上,它是将堆栈空间作为抓取空间,如果最终使用了太多,事情就会变得很糟糕。处理这个问题的一个常见方法是把递归算法变成一个迭代算法,这通常涉及到使用显式的状态堆栈而不是隐式的。这样做的好处是,你可以存储的状态量只受限于你有多少内存,而不是受限于你线程的堆栈空间。然而,缺点是,以这种方式编写算法通常不那么自然,而且它通常需要为堆栈分配堆空间,如果你想避免这种分配,就会导致额外的复杂情况,例如各种池。dotnet/runtime#60385为Regex引入了一种不同的方法,然后被@olsaarik的dotnet/runtime#60786专门用于NonBacktracking的实现。它仍然使用递归,因此受益于递归算法的表现力,以及能够使用堆栈空间,从而在最常见的情况下避免额外的分配,但随后为了避免堆栈溢出,它发出明确的检查以确保我们在堆栈上没有太深(.NET早已为此目的提供了帮助器RuntimeHelpers.EnsureSufficientExecutionStack和RuntimeHelpers.TryEnsureSufficientExecutionStack)。如果它检测到它在堆栈上的位置太深,它就会分叉到另一个线程继续执行。触发这个条件是很昂贵的,但在实践中很少会被触发(例如,在我们庞大的功能测试中,只有在明确写成的测试中才会被触发),它使代码保持简单,并保持典型案例的快速。类似的方法也用于dotnet/runtime的其他领域,如System.Linq.Expressions。
正如我在上一篇关于正则表达式的博文中提到的,回溯实现和非回溯实现都有其存在的意义。非回溯实现的主要好处是可预测性:由于线性处理的保证,一旦你构建了regex,你就不需要担心恶意输入会在你的潜在易受影响的表达式的处理过程中造成最坏情况的行为。这并不意味着RegexOptions.NonBacktracking总是最快的;事实上,它经常不是。作为对降低最佳性能的交换,它提供了最佳的最坏情况下的性能,对于某些类型的应用,这是一个真正值得和有价值的权衡。
原文链接
Performance Improvements in .NET 7

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
如有任何疑问,请与我联系 (MingsonZheng@outlook.com)






【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 为DeepSeek添加本地知识库
· 精选4款基于.NET开源、功能强大的通讯调试工具
· DeepSeek智能编程
· 腾讯ima接入deepseek-r1,借用别人脑子用用成真了~
· [翻译] 为什么 Tracebit 用 C# 开发
2020-03-05 .NET Core开发实战(第17课:为选项数据添加验证:避免错误配置的应用接收用户流量)--学习笔记