
API 工程化分享
 本文是学习B站毛剑老师的《API 工程化分享》的学习笔记,分享了 gRPC 中的 Proto 管理方式,Proto 分仓源码方式,Proto 独立同步方式,Proto git submodules 方式,Proto 项目布局,Proto Errors,服务端和客户端的 Proto Errors,Proto 文档等等
本文是学习B站毛剑老师的《API 工程化分享》的学习笔记,分享了 gRPC 中的 Proto 管理方式,Proto 分仓源码方式,Proto 独立同步方式,Proto git submodules 方式,Proto 项目布局,Proto Errors,服务端和客户端的 Proto Errors,Proto 文档等等
概要
本文是学习B站毛剑老师的《API 工程化分享》的学习笔记,分享了 gRPC 中的 Proto 管理方式,Proto 分仓源码方式,Proto 独立同步方式,Proto git submodules 方式,Proto 项目布局,Proto Errors,服务端和客户端的 Proto Errors,Proto 文档等等
目录
- Proto IDL Management
- IDL Project Layout
- IDL Errors
- IDL Docs
Proto IDL Management
- Proto IDL
- Proto 管理方式
- Proto 分仓源码方式
- Proto 独立同步方式
- Proto git submodules 方式
Proto IDL
gRPC 从协议缓冲区使用接口定义语言 (IDL)。协议缓冲区 IDL 是一种与平台无关的自定义语言,具有开放规范。 开发人员会创作 .proto 文件,用于描述服务及其输入和输出。 然后,这些 .proto 文件可用于为客户端和服务器生成特定于语言或平台的存根,使多个不同的平台可进行通信。 通过共享 .proto 文件,团队可生成代码来使用彼此的服务,而无需采用代码依赖项。
Proto 管理方式
煎鱼的一篇文章:真是头疼,Proto 代码到底放哪里?
文章中经过多轮讨论对 Proto 的存储方式和对应带来的优缺点,一共有如下几种方案:
- 代码仓库
- 独立仓库
- 集中仓库
- 镜像仓库
镜像仓库
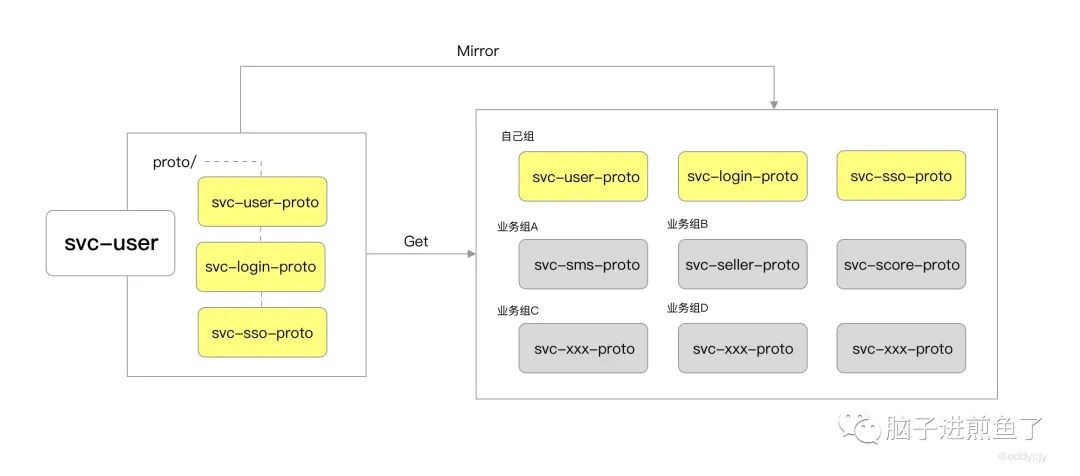
在我自己的微服务仓库里面,有一个 Proto 目录,就是放我自己的 Proto,然后在我提交我的微服务代码到主干或者某个分支的时候,它可能触发一个 mirror 叫做自动同步,会镜像到这个集中的仓库,它会帮你复制过去,相当于说我不需要把我的源码的 Proto 开放给你,同时还会自动复制一份到集中的仓库
在煎鱼的文章里面的集中仓库还是分了仓库的,B站大仓是一个统一的仓库。为什么呢?因为比方像谷歌云它整个对外的 API 会在一个仓库,不然你让用户怎么找?到底要去哪个 GitHub 下去找?有这么多 project 怎么找?根本找不到,应该建统一的一个仓库,一个项目就搞定了
我们最早衍生这个想法是因为无意中看到了 Google APIs 这个仓库。大仓可以解决很多问题,包括高度代码共享,其实对于 API 文件也是一样的,集中在一个 Repo 里面,很方便去检索,去查阅,甚至看文档,都很方便
我们不像其他公司喜欢弄一个 UI 的后台,我们喜欢 Git,它很方便做扩展,包括 CICD 的流程,包括 coding style 的 check,包括兼容性的检测,包括 code review 等等,你都可以基于 git 的扩展,gitlab 的扩展,GitHub 的一些 actions,做很多很多的工作
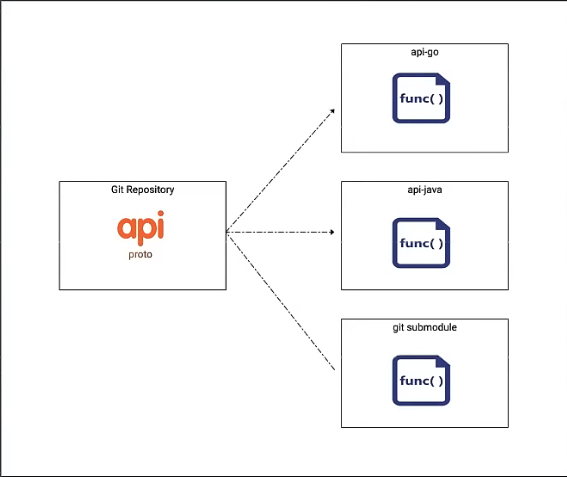
Proto 分仓源码方式
过去为了统一检索和规范 API,我们内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。它只是一个申明文件。
- API 仓库,方便跨部门协作;
- 版本管理,基于 git 控制;
- 规范化检查,API lint;
- API design review,变更 diff;
- 权限管理,目录 OWNERS;
集中式仓库最大的风险是什么呢?是谁都可以更改
大仓的核心是放弃了读权限的管理,针对写操作是有微观管理的,就是你可以看到我的 API 声明,但是你实际上调用不了,但是对于迁入 check in,提到主干,你可以在不同层级加上 owner 文件,它里面会描述谁可以合并代码,或者谁负责 review,两个角色,那就可以方便利用 gitlab 的 hook 功能,然后用 owner 文件做一些细粒度的权限管理,针对目录级别的权限管理
最终你的同事不能随便迁入,就是说把文件的写权限,merge 权限关闭掉,只允许通过 merge request 的评论区去回复一些指令,比方说 lgtm(looks good to me),表示 review 通过,然后你可以回复一个 approve,表示这个代码可以被成功 check in,这样来做一些细粒度的权限检验
怎么迁入呢?我们的想法是在某一个微服务的 Proto 目录下,把自己的 Proto 文件管理起来,然后自动同步进去,就相当于要写一个插件,可以自动复制到 API 仓库里面去。做完这件事情之后,我们又分了 api.go,api.java,git submodule,就是把这些代码使用 Google protobuf,protoc 这个编译工具生成客户端的调用代码,然后推到另一个仓库,也就是把所有客户端调用代码推到一个源码仓库里面去
Proto 独立同步方式
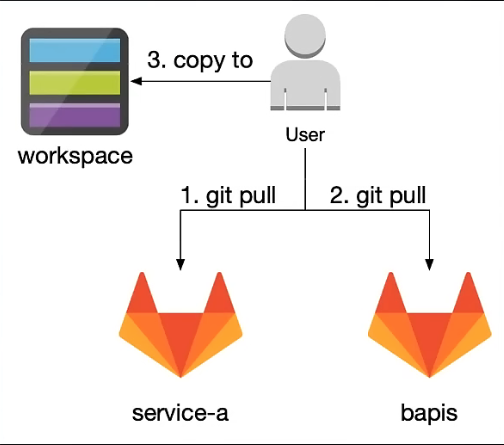
移动端采用自定义工具方式,在同步代码阶段,自动更新最新的 proto 仓库到 worksapce 中,之后依赖 bazel 进行构建整个仓库
- 业务代码中不依赖 target 产物,比如 objective-c 的 .h/.a 文件,或者 Go 的 .go 文件(钻石依赖、proto 未更新问题)
源码依赖会引入很多问题
- 依赖信息丢失
- proto 未更新
- 钻石依赖
依赖信息丢失
在你的工程里面依赖了其他服务,依赖信息变成了源码依赖,你根本不知道依赖了哪个服务,以前是 protobuf 的依赖关系,现在变成了源码依赖,服务依赖信息丢失了。未来我要去做一些全局层面的代码盘点,比方说我要看这个服务被谁依赖了,你已经搞不清楚了,因为它变成了源码依赖
proto 未更新
如果我的 proto 文件更新了,你如何保证这个人重新生成了 .h/.a 文件,因为对它来说这个依赖信息已经丢失,为什么每次都要去做这个动作呢?它不会去生成 .h/.a 文件
钻石依赖
当我的 A 服务依赖 B 服务的时候,通过源码依赖,但是我的 A 服务还依赖 C 服务,C 服务是通过集中仓库 bapis 去依赖的,同时 B 和 C 之间又有一个依赖关系,那么这个时候就可能出现对于 C 代码来说可能会注册两次,protobuf 有一个约束就是说重名文件加上包名是不允许重复的,否则启动的时候就会 panic,有可能会出现钻石依赖
- A 依赖 B
- A 依赖 C
- A 和 B 是源码依赖
- A 和 C 是 proto 依赖
- B 和 C 之间又有依赖
那么它的版本有可能是对不齐的,就是有风险的,这就是为什么 google basic 构建工具把 proto 依赖的名字管理起来,它并没有生成 .go 文件再 checkin 到仓库里面,它不是源码依赖,它每一次都要编译,每次都要生成 .go 文件的原因,就是为了版本对齐
Proto git submodules 方式
经过多次讨论,有几个核心认知:
- proto one source of truth,不使用镜像方式同步,使用 git submodules 方式以仓库中目录形式来承载;
- 本地构建工具 protoc 依赖 go module 下的相对路径即可;
- 基于分支创建新的 proto,submodules 切换分支生成 stub 代码,同理 client 使用联调切换同一个分支;
- 维护 Makefile,使用 protoc + go build 统一处理;
- 声明式依赖方式,指定 protoc 版本和 proto 文件依赖(基于 BAZEL.BUILD 或者 Yaml 文件)
proto one source of truth
如果只在一个仓库里面,如果只有一个副本,那么这个副本就是唯一的真相并且是高度可信任的,那如果你是把这个 proto 文件拷来拷去,最终就会变得源头更新,拷贝的文件没办法保证一定会更新
镜像方式同步
实际上维护了本地微服务的目录里面有一个 protobuf 的定义,镜像同步到集中的仓库里面,实际上是有两个副本的
使用 git submodules 方式以仓库中目录形式来承载
子模块允许您将 Git 存储库保留为另一个 Git 存储库的子目录。这使您可以将另一个存储库克隆到您的项目中并保持您的提交分开。
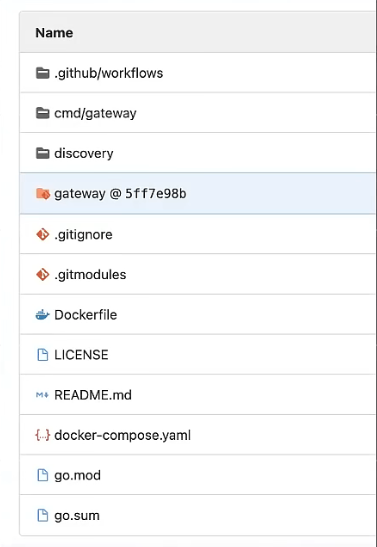
图中 gateway 这个目录就是以本地目录的形式,但是它是通过 git submodules 方式给承载进来的
如果公司内代码都在一起,api 的定义都在一起,那么大仓绝对是最优解,其次才是 git submodules,这也是 Google 的建议
我们倾向于最终 proto 的管理是集中在一个仓库里面,并且只有一份,不会做任何的 copy,通过 submodules 引入到自己的微服务里面,也就是说你的微服务里面都会通过 submodules 把集中 API 的 git 拷贝到本地项目里面,但是它是通过 submodeles 的方式来承载的,然后你再通过一系列 shell 的工具让你的整个编译过程变得更简单
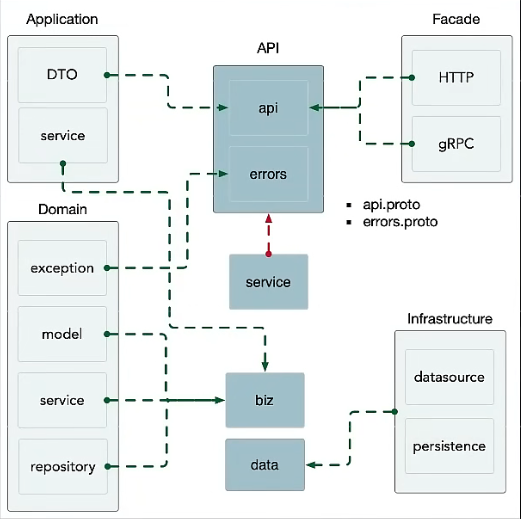
IDL Project Layout
Proto Project Layout
在统一仓库中管理 proto,以仓库为名
根目录:
- 目录结构和 package 对齐;
- 复杂业务的功能目录区分;
- 公共业务功能:api、rpc、type;

目录结构和 package 对齐
我们看一下 googleapis 大量的 api 是如何管理的?
第一个就是在 googleapis 这个项目的 github 里面,它的第一级目录叫 google,就是公司名称,第二个目录是它的业务域,业务的名称
目录结构和 protobuf 的包名是完全对齐的,方便检索
复杂业务的功能目录区分
v9 目录下分为公共、枚举、错误、资源、服务等等
公共业务功能:api、rpc、type
在 googleapis 的根目录下还有类似 api、rpc、type 等公共业务功能
IDL Errors
- Proto Errors
- Proto Errors:Server
- Proto Errors:Client
Proto Errors
- 使用一小组标准错误配合大量资源
- 错误传播
用简单的协议无关错误模型,这使我们能够在不同的 API,API 协议(如 gRPC 或 HTTP)以及错误上下文(例如,异步,批处理或工作流错误)中获得一致的体验。
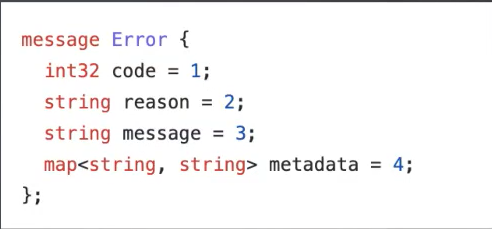

使用一小组标准错误配合大量资源
服务器没有定义不同类型的“找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息。
我们以前自己的业务代码关于404,关于某种资源找不到的错误码,定义了上百上千个,请问为什么大家在设计 HTTP restful 或者 grpc 接口的时候不用人家标准的状态码呢?人家有标准的404,或者 not found 的状态码,用状态码去映射一下通用的错误信息不好吗?你不可能调用一个接口,返回几十种具体的错误码,你根本对于调用者来说是无法使用的。当我的接口返回超过3个自定义的错误码,你就是面向错误编程了,你不断根据错误码做不同的处理,非常难搞,而且你每一个接口都要去定义
这里的核心思路就是使用标准的 HTTP 状态码,比方说500是内部错误,503是网关错误,504是超时,404是找不到,401是参数错误,这些都是通用的,非常标准的一些状态码,或者叫错误码,先用它们,因为不是所有的错误都需要我们叫业务上 hint,进一步处理,也就是说我调你的服务报错了,我大概率是啥都不做的,因为我无法纠正服务端产生的一个错误,除非它是带一些业务逻辑需要我做一些跳转或者做一些特殊的逻辑,这种不应该特别多,我觉得两个三个已经非常多了
所以说你会发现大部分去调用别人接口的时候,你只需要用一个通用的标准的状态码去映射,它会大大降低客户端的逻辑复杂性,同时也不限制说你包含一些可操作的 hint 的一些信息,也就是说你可以包含一些指示你接下来要去怎么做的一些信息,就是它不冲突
错误传播
如果您的 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到您的客户端。
举个例子,你现在要跟移动端说我有一个接口,那么这个接口会返回哪些错误码,你始终讲不清楚,你为什么讲不清楚呢?因为我们整个微服务的调用链是 A 调 B,B 调 C,C 调 D,D 的错误码会一层层透传到 A,那么 A 的错误码可能会是 ABCD 错误码的并集,你觉得你能描述出来它返回了哪些错误码吗?根本描述不出来
所以对于一个服务之间的依赖关系不应该盲目地将下游服务产生的这些错误码无脑透传到客户端,并且曾经跟海外很多公司,像 Uber,Twitter,Netflix,跟他们很多的华人的朋友交流,他们都不建议大家用这种全局的错误码,比方 A 部门用 01 开头,B 部门用 02 开头,类似这样的方式去搞所谓的君子契约,或者叫松散的没有约束的脆弱的这种约定
在翻译错误时,我们建议执行以下操作:
- 隐藏实现详细信息和机密信息
- 调整负责该错误的一方。例如,从另一个服务接收 INVALID_ARGUMENT 错误的服务器应该将 INTERNAL 传播给它自己的调用者。
比如你返回的错误码是4,代表商品已下架,我对这个错误很感兴趣,但是错误码4 在我的项目里面已经被用了,我就把它翻译为我还没使用的错误码6,这样每次翻译的时候就可以对上一层你的调用者,你就可以交代清楚你会返回错误码,因为都是你定义的,而且是你翻译的,你感兴趣的才翻译,你不感兴趣的通通返回 500 错误,就是内部错误,或者说 unknown,就是未知错误,这样你每个 API 都能讲清楚自己会返回哪些错误码
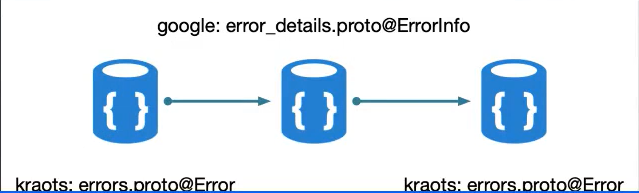
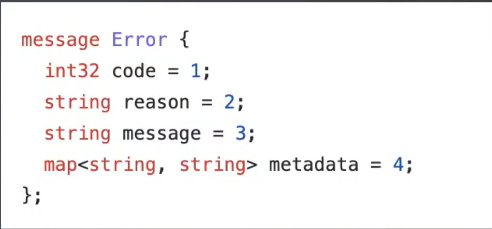
在 grpc 传输过程中,它会要求你要实现一个 grpc states 的一个接口的方法,所以在 Kraots 的 v2 这个工程里面,我们先用前面定义的 message Error 这个错误模型,在传输到 grpc 的过程中会转换成 grpc 的 error_details.proto 文件里面的 ErrorInfo,那么在传输到 client 的时候,就是调用者请求服务,service 再返回给 client 的时候再把它转换回来
也就是说两个服务使用一个框架就能够对齐,因为你是基于 message Error 这样的错误模型,这样在跨语言的时候同理,经过 ErrorInfo 使用同样的模型,这样就解决了跨语言的问题,通过模型的一致性

Proto Errors:Server
errors.proto 定义了 Business Domain Error 原型,使用最基础的 Protobuf Enum,将生成的源码放在 biz 大目录下,例如 biz/errors
- biz 目录中核心维护 Domain,可以直接依赖 errors enum 类型定义;
- data 依赖并实现了 biz 的 Reporisty/ACL,也可以直接使用 errors enum 类型定义;
- TODO:Kratos errors 需要支持 cause 保存,支持 Unwrap();
在某一个微服务工程里面,errors.proto 文件实际上是放在 API 的目录定义,之前讲的 API 目录定义实际上是你的服务里面的 API 目录,刚刚讲了一个 submodules,现在你可以理解为这个 API 目录是另外一个仓库的 submodules,最终你是把这些信息提交到那个 submodules,然后通过 reference 这个 submodules 获取到最新的版本,其实你可以把它打成一个本地目录,就是说我的定义声明是在这个地方
这个 errors.proto 文件其实就列举了各种错误码,或者叫错误的字符串,我们其实更建议大家用字符串,更灵活,因为一个数字没有写文档前你根本不知道它是干啥的,如果我用字符串的话,我可以 user_not_found 告诉你是用户找不到,但是我告诉你它是3548,你根本不知道它是什么含义,如果我没写文档的话
所以我们建议使用 Protobuf Enum 来定义错误的内容信息,定义是在这个地方,但是生成的代码,按照 DDD 的战术设计,属于 Domain,因为业务设计是属于领域的一个东西,Domain 里面 exception 它最终的源码会在哪?会在 biz 的大目录下,biz 是 business 的缩写,就是在业务的目录下,举个例子,你可以放在 biz 的 errors 目录下
有了这个认知之后我们会做三个事情
首先你的 biz 目录维护的是领域逻辑,你的领域逻辑可以直接依赖 biz.errors 这个目录,因为你会抛一些业务错误出去
第二,我们的 data 有点像 DDD 的 infrastructure,就是所谓的基础设施,它依赖并实现了 biz 的 repository 和 acl,repository 就是我们所谓的仓库,acl 是防腐层
因为我们之前讲过它的整个依赖倒置的玩法,就是让我们的 data 去依赖 biz,最终让我们的 biz 零依赖,它不依赖任何人,也不依赖基础设施,它把 repository 和 acl 的接口定义放在 biz 自己目录下,然后让 data 依赖并实现它
也就是说最终我这个 data 目录也可以依赖 biz 的 errors,我可能通过查 mysql,结果这个东西查不到,会返回一个 sql no rows,但肯定不会返回这个错误,那我就可以用依赖 biz 的这个 errors number,比如说 user_not_found,我把它包一个 error 抛出去,所以它可以依赖 biz 的 errors
目前 Kratos 还不支持根因保存,根因保存是什么呢?刚刚说了你可能是 mysql 报了一个内部的错误,这个内部错误你实际上在最上层的传输框架,就是 HTTP 和 grpc 的 middleware 里面,你可能会把日志打出来,就要把堆栈信息打出来,那么根因保存就是告诉你最底层发生的错误是什么
不支持 Unwrap 就是不支持递归找根因,如果支持根因以后呢,就可以让 Kratos errors 这个 package 可以把根因传进去,这样子既能搞定我们 go 的 wrap errors,同时又支持我们的状态码和 reason,大类错误和小类错误,大类错误就是状态码,小类错误就是我刚刚说的用 enum 定义的具体信息,比方说这个商品被下架,这种就不太好去映射一个具体的错误码,你可能是返回一个500,再带上一个 reason,可能是这样的一个做法
Proto Errors:Client
从 Client 消费端只能看到 api.proto 和 error.proto 文件,相应的生成的代码,就是调用测的 api 以及 errors enum 定义
- 使用 Kratos errors.As() 拿到具体类型,然后通过 Reason 字段进行判定;
- 使用 Kratos errors.Reason() helper 方法(内部依赖 errors.As)快速判定;
拿到这两个文件之后你可以生成相应代码,然后调用 api
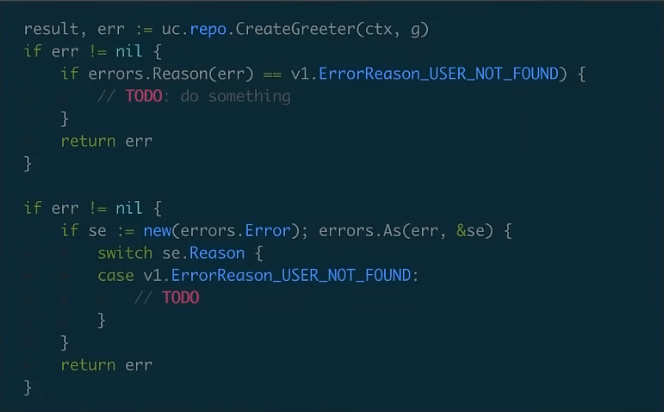
举个例子,图中的代码是调用服务端 grpc 的某一个方法,那么我可能返回一个错误,我们可以用 Kratos 提供的一个 Reason 的 short car,一个快捷的方法,然后把 error 传进去,实际上在内部他会调用标准库的 error.As,把它强制转换成 Kratos 的 errors 类型,然后拿到里面的 Reason 的字段,然后再跟这个枚举值判定,这样你就可以判定它是不是具体的一个业务错误
第二种写法你可以拿到原始的我们 Kratos 的 Error 模型,就是以下这个模型
new 出来之后用标准库的 errors.As 转换出来,转换出来之后再用 switch 获取它里面的 reason 字段,然后可以写一些业务逻辑
这样你的 client 代码跨语言,跨传输,跨协议,无论是 grpc,http,同样是用一样的方式去解决
IDL Docs
- Proto Docs
Proto Docs
基于 openapi 插件 + IDL Protobuf 注释(IDL 即定义,IDL 即代码,IDL 即文档),最终可以在 Makefile 中使用 make api 生成 openapi.yaml,可以在 gitlab/vscode 插件直接查看
- API Metadata 元信息用于微服务治理、调试、测试等;
因为我们可以在 IDL 文件上面写上大量的注释,那么当讲到这个地方,你就明白了 IDL 有什么样的好处?
IDL 文件它既定义,同时又是代码,也就是说你既做了声明,然后使用 protoc 可以去生成代码,并且是跨语言的代码,同时 IDL 本身既文档,也就是说它才真正满足了 one source of truth,就是唯一的事实标准
最终你可以在 Makefile 中定义一个 api 指令,然后生成一个 openapi.yaml,以前是 swagger json,现在叫 openapi,用 yaml 声明

生成 yaml 文件以后,现在 gitlab 直接支持 openapi.yaml 文件,所以你可以直接打开 gitlab 去点开它,就能看到这样炫酷的 UI,然后 VSCode 也有一个插件,你可以直接去查看
还有一个很关键的点,我们现在的 IDL 既是定义,又是代码,又是文档,其实 IDL 还有一个核心作用,这个定义表示它是一个元信息,是一个元数据,最终这个 API 的 mate data 元信息它可以用于大量的微服务治理
因为你要治理的时候你比方说对每个服务的某个接口进行路由,进行熔断进行限流,这些元信息是哪来的?我们知道以前 dubbo 2.x,3.x 之前都是把这些元信息注册到注册中心的,导致整个数据中心的存储爆炸,那么元信息在哪?
我们想一想为什么 protobuf 是定义一个文件,然后序列化之后它比 json 要小?因为它不是自描述的,它的定义和序列化是分开的,就是原始的 payload 是没有任何的定义信息的,所以它可以高度的compressed,可被压缩,或者说叫更紧凑
所以说同样的道理,IDL 的定义和它的元信息,和生成代码是分开的话,意味着你只要有 one source of truth 这份唯一的 pb 文件,基于这个 pb 文件,你就有办法把它做成一个 api 的 metadata 的服务,你就可以用于做微服务的治理
你可以选一个服务,然后看它有些什么接口,然后你可以通过一个管控面去做熔断、限流等功能,然后你还可以基于这个元信息去调试,你做个炫酷的 UI 可以让它有一些参数,甚至你可以写一些扩展,比方说这个字段叫 etc,建议它是什么样的值,那么你在渲染 UI 的时候可以把默认值填进去,那你就很方便做一些调试,甚至包含测试,你基于这个 api 去生成大量的 test case
参考
API 工程化分享
https://www.bilibili.com/video/BV17m4y1f7qc/
真是头疼,Proto 代码到底放哪里?
https://mp.weixin.qq.com/s/cBXZjg_R8MLFDJyFtpjVVQ
git submodules
https://git-scm.com/book/en/v2/Git-Tools-Submodules
kratos
https://github.com/go-kratos/kratos
error_details.proto
https://github.com/googleapis/googleapis/blob/master/google/rpc/error_details.proto#L112
pkg/errors
https://github.com/pkg/errors
Modifying gRPC Services over Time

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
如有任何疑问,请与我联系 (MingsonZheng@outlook.com) 。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步