

redis连环炮问题
剖析
redis是一个NIO的单线程异步的工作模型,Memcache在之前的个别互联网公司会使用,现在使用的很少了。redis的key和String类型的Value的大小都可以是512MB.
一:redis和Memcache的区别是什么?
①redis拥有更多的数据结构
相对比Memcache呢redis有更多的数据结构,在Memcache中需要拿到客户端进行类似的修改然后set进去,增加了io的次数和体积。redis呢就类似getter 和 setter一样高效,所以redis使用的较多。
②redis内存利用率对比
简单k-v存储的话,Memcache的效率较高,但是redis使用的是Hash结构存储,由于其组合式的压缩,其内存利用率高于Memcache.
③性能对比
redis是单核在存储小数据上还可以,大数据上【100k以上的数据】还是不如Memcache,虽然最近有所提升还是不够。
④集群模式
Memecache没有原生的集群模式,需要依赖客户端实现往集群中分片写入数据;而redis是原生支持cluster模式。
二:redis都有哪些数据类型以及其使用的场景
①String
最基本的类型,做简单的key value操作,和set get操作类似。
②Hash
主要将对象放进缓存,后面操作的时候可以直接仅仅操作某个对象的字段值。
③List
●有序列表:可以通过list存储一些列表型的数据结构,如 学生列表,文章列表等。
●可以通过lrange命令,从某个元素开始读取多少个元素,基础list实现分页查询,redis简单高性能分页,可以做类似微博那种不断下拉的分页。 性能高
●可以做简单的消息队列,从list头部插入尾巴取出。
④Set
●无序列表,自动去重;
●可以做差集,交集等可以看共同好友
⑤Sorted Set
●去重可以排序
●排行榜:将每个用户和对应的什么分数写进去,zadd bord score username 接着 zrevaange bord 0 99,可以获取排名前一把的人
zrank bord username 可以看到用户在排行榜里的排名
⑥BitMaps
本身不是一种数据类型,是一中字符串,可以对字符串的 位 进行操作。可以想象成一个以 位 为单位的数组。
⑦HypeLogLogs
如果实现统计网站的PV[页面访问量],可以使用redis的 incr incrby可以轻松实现,但是如果想实现UV[独立访客],独立IP数等去重和计数 问题的时候,就可以用HypeLogLogs
⑧geo
地理信息的缩写,是元素的二维坐标。在地图上就是经纬度。
实际中,可以查附近的人,两个人实际距离。
三:Redis持久化对生产环境的意义
1.redis持久化对于故障的恢复也属于一个高可用的环节。
如:当存在内存中的数据,会因为redis的挂掉而数据丢失。
如果只将数据存在redis中 如果出现意外情况是很费劲才可恢复数据的,一般都是会将redis中的数据持久化到磁盘中,然后定期同步到云 盘上
国内的可以是 阿里云的ODPS ,国外的可是 亚马逊的s3
2.Redis中RDB和AOF两种持久化机制
①当出现redis宕机时需要做的是重启redis,尽快对外恢复服务。缓冲中全部无法命中会出现缓冲血崩的问题
②所有请求会到mysql数据库中,严重会导致系统宕机。
RDB持久化机制:
简单说:就是每隔一段时间就将redis中的数据进行持久化操作。每隔一会会生成一份数据快照
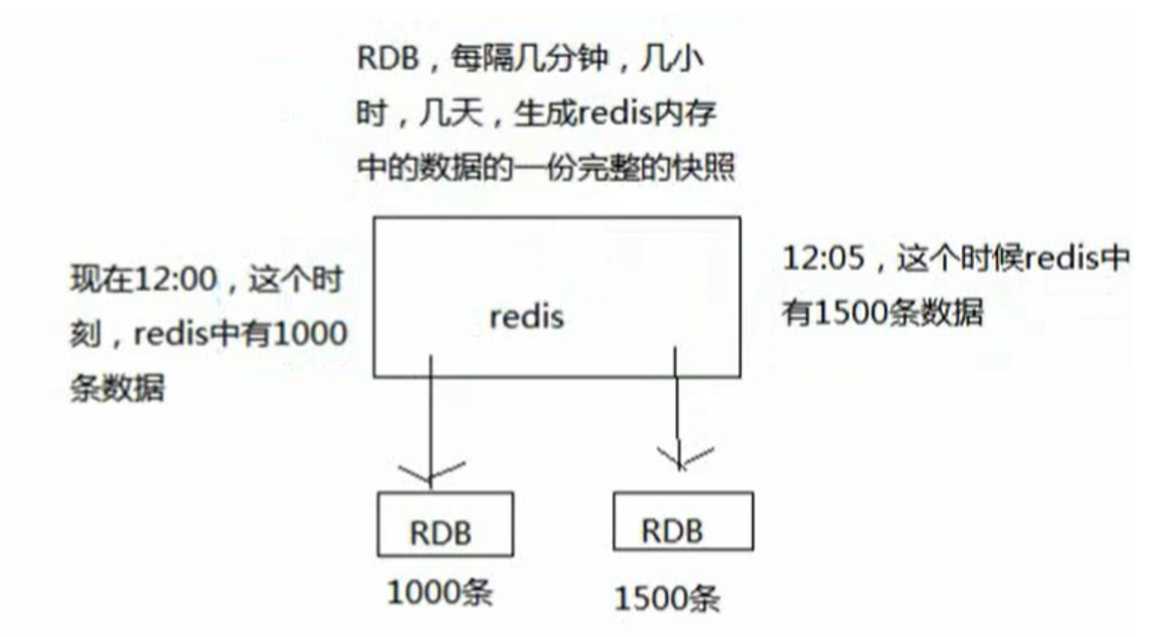
优点:
每隔一段时间就会自动生成一个文件,适合去做冷备份,可以将完整的数据发送的云上。RDB做冷备份,优势在于可以由redis去控制固定时长 生成快照文件的事情。
RDB对redis对外提供的服务影响小性能高。。redis主进程只需要fork一个子进程,让子进程对IO操作来进行持久化操作即可。
缺点:
因为是每隔一段时间才会持久化一次,万一宕机了 就很容易丢掉一定的数据。
AOF持久化机制:
是将内r存中数据存到一个AOF文件中,随着时间推移和数据的增多,文件会越来越大。是以append-only的模式进行写入日志的方式。
当数据大到一定程度的时候会进行淘汰算法【LRU】自动清除一部分数据。写入数据的时候到一定程度也是会对文件进行重写的
优点:
更好的保护数据不丢失。
AOF日志文件以 append-only方式写入,没有磁盘寻址开销,性能高文件也不容易损坏。
AOF文件的命令通过非常可读的方式进行,适合做灾难行的误删除文件恢复。如:误使用了flushall 情况了redis中数据,只要后台还没发生 rewrite 就可以立即拷贝 aof文件删除最后一个flushall命令 然后再将aof文件放回去即可。
缺点:
同于同一份文件而言aof文件比rdb文件更大。
做数据恢复比较慢,做冷备份比较麻烦,需要手写脚本。
RDB和AOF的选择:
两个配合使用,使用AOF来保证数据不丢失,恢复数据的第一选择,使用RDB来做不同程度的冷备份


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY