大数据HelloWorld----WordCount
俗话说一个程序员开始学习书法的时候拿起笔就是写 HelloWorld.没错我们学习一个新的语言或者新的知识的时候都是从基本的HelloWorld开始。大数据的HelloWorld我们可以参考
/hadoop-3.1.3/share/hadoop/mapreduce 目录下的 hadoop-mapreduce-examples-3.1.3.jar 文件 可以在linux中使用sz + 文件名的方式下载到windows中 解压使用反编译工具进行反编译。然后根据源码我们参考编写自己的WordCount
源码如下:

编码实操
需求:
输入数据 ,期望输出 【统计单词次数】
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
步骤:
一;环境准备
①加入依赖
②加入日志文件
二:编码
Map阶段:
1. map()方法中把传入的数据转为String类型
2. 根据空格切分出单词
3. 输出<单词,1>
Reduce阶段:
1. 汇总各个key(单词)的个数,遍历value数据进行累加
2. 输出key的总数
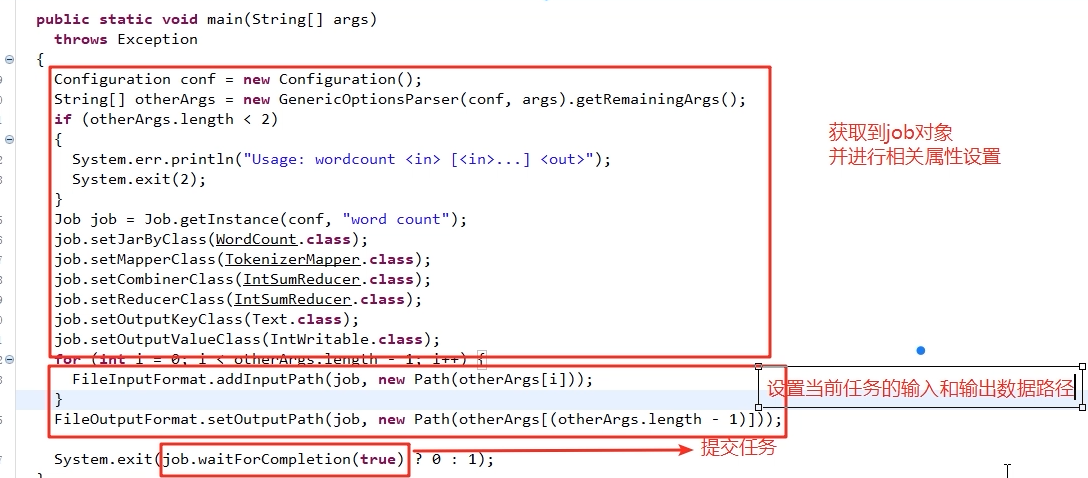
Driver
1. 获取配置文件对象,获取job对象实例
2. 指定程序jar的本地路径
3. 指定Mapper/Reducer类
4. 指定Mapper输出的kv数据类型
5. 指定最终输出的kv数据类型
6. 指定job处理的原始数据路径
7. 指定job输出结果路径
依赖
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
log4.j
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
Mapper类
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.获取一行
String line=value.toString();
//2.切割
String[] word = line.split(" ");
//3.输出
for (String s : word) {
k.set(s);
context.write(k,v);
}
}
Reduce类
public class WordContReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1.累加求和
sum=0;
for (IntWritable count : values) {
sum+=count.get();
}
//2.输出
v.set(sum);
context.write(key,v);
}
}
Driver类
public static void main(String[] args) throws Exception {
//1.获取配置信息获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
//3.关联mapper和reduce的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordContReduce.class);
//4.设置mapper 输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终的输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6设置输入和输出的路径
FileInputFormat.setInputPaths(job,new Path("E:\\bigData\\guigu\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\bigData\\guigu\\output2"));
//7.提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
成功时候可以在输出的路径中看到对应的文件
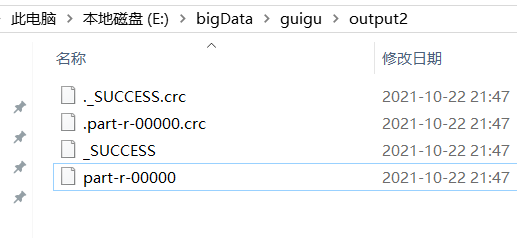
打开文件即可看到我们想看到的结果。

