
综合练习:词频统计
1.英文词频统计:
下载一首英文的歌词或文章
song = ''' Passion is sweet Love makes weak You said you cherised freedom so You refused to let it go Follow your faith Love and hate never failed to seize the day Don't give yourself away Oh when the night falls And your all alone In your deepest sleep What are you dreeeming of My skin's still burning from your touch Oh I just can't get enough I said I wouldn't ask for much But your eyes are dangerous So the tought keeps spinning in my head Can we drop this masquerade I can't predict where it ends If you're the rock I'll crush against Trapped in a crowd Music's loud I said I loved my freedom too Now im not so sure i do All eyes on you Wings so true Better quit while your ahead Now im not so sure i am Oh when the night falls And your all alone In your deepest sleep What are you dreaming of My skin's still burning from your touch Oh I just can't get enough I said I wouldn't ask for much But your eyes are dangerous So the thought keeps spinning in my head Can we drop this masquerade I can't predict where it ends If you're the rock I'll crush against My soul, my heart If your near or if your far My life, my love You can have it all Oh when the night falls And your all alone In your deepest sleep What are you dreaming of My skin's still burning from your touch Oh I just can't get enough I said I wouldn't ask for much But your eyes are dangerous So the thought keeps spinning in my head Can we drop this masquerade I can't predict where it ends If you're the rock I'll crush against If you're the rock i'll crush against '''
将所有,.?!’:等分隔符全部替换为空格
sep = ''',.?';'"''' for i in sep: song.replace(i," ")
将所有大写转换为小写,生成单词列表
songList = song.lower().split()
生成词频统计
countdict = {} songset = set(songList) for i in songset: countdict[i] = songList.count(i) for i in countdict: print(i,countdict[i])
排序
dictList = list(countdict.items()) dictList.sort(key = lambda x:x[1],reverse = True)
排除语法型词汇,代词、冠词、连词
delList = {"the","a","an"}
songset = set(songList) - delList
输出词频最大TOP20
for i in range(20): print(dictList[i])
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
读取歌词:
f = open("F:/study/大三/大数据/song.txt","r") song = f.read(); f.close()
保存分析结果:
f = open("F:/study/大三/大数据/resulet.txt","a") for i in range(20): f.write('\n'+dictList[i][0]+" "+str(dictList[i][1])) f.close()
实验结果:

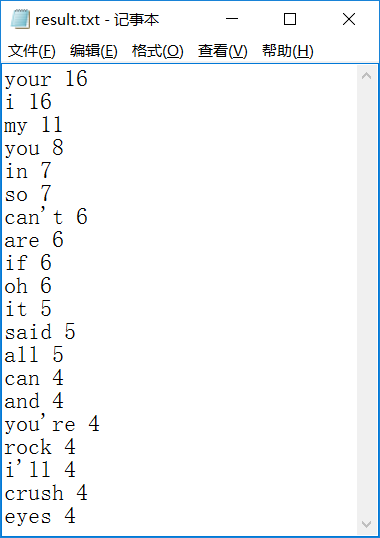
2.中文词频统计:
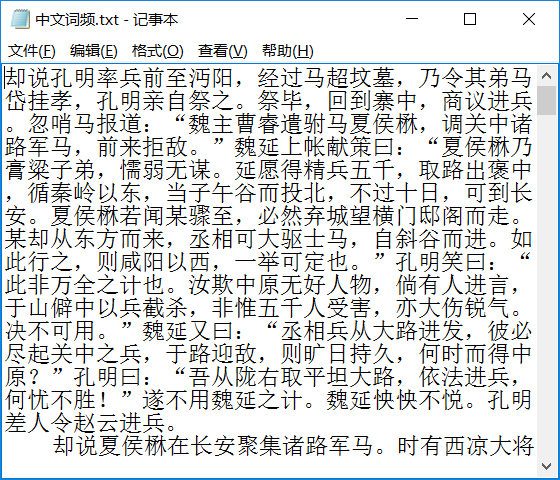
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20(或把结果存放到文件里)
import jieba f = open("F:\study\大三\大数据\中文词频.txt","r") str1 = f.read() stringList =list(jieba.cut(str1)) delset = {",","。",":","“","”","?"," ",";","!","、"} stringset = set(stringList) - delset countdict = {} for i in stringset: countdict[i] = stringList.count(i) dictList = list(countdict.items()) dictList.sort(key = lambda x:x[1],reverse = True) f = open("F:/study/大三/大数据/resulet.txt", "a") for i in range(20): f.write('\n' + dictList[i][0] + " " + str(dictList[i][1])) f.close()
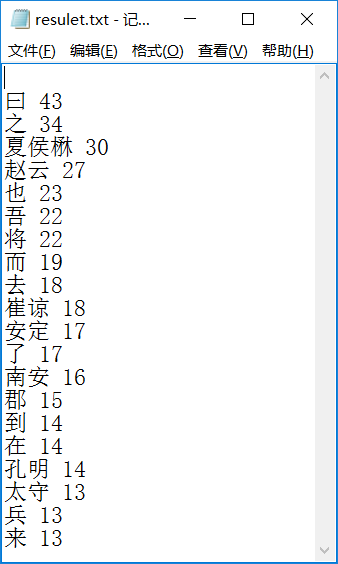

 浙公网安备 33010602011771号
浙公网安备 33010602011771号