C# 数据与集合相关
内容主要来自:B站:IT萌叔Jack ,《C# 7.0核心技术指南》,《CLR via C# 第4版》
——↓ 引自《C# 7.0核心技术指南》——————————————————
.NET Framework提供了一系列标准的存储和管理对象集合的类型。其中包括可变大小的列表、链表、排序或非排序字典以及数组。在这些类型中,只有数组是C#语言的一部分,而其余的集合只是一些类,我们可以和其他类一样将其实例化。
Framework中的集合类型可以分为以下类别:
· 定义标准集合协议的接口
· 开箱即用的集合类(列表、字典等)
· 编写应用程序特有集合的基类

7.1 枚举
计算中会涉及很多不同类型的集合,有简单数据结构如数组或链表,也有复杂的红黑树和散列表。虽然这些数据结构的内部实现和外部特征差异很大,但几乎都需要实现遍历集合内容这一功能。Framework通过一系列接口(IEnumerable、IEnumerator及其泛型接口)来支持该需求,允许不同的数据结构使用一组通用的遍历API。图7-1展示了部分集合接口:

7.1.1 IEnumerable和IEnumerator
IEnumerator接口定义了以前向方式遍历或枚举集合元素的基本底层协议。其声明如下:
public interface IEnumerator
{
bool MoveNext();
object Current { get; }
void Reset();
}
MoveNext将当前元素或“游标”向前移动到下一个位置,如果集合没有更多的元素,那么它会返回false。
Current返回当前位置的元素(通常需要从object转换为更具体的类型)。在取得第一个元素之前必须先调用MoveNext,即使是空集合也支持这个操作。如果实现了Reset方法,那么它的作用就是将当前位置移回起点,并允许再一次枚举集合。
Reset方法存在的目的主要是COM互操作;而其他情况应当尽量避免直接调用该方法因为它并未得到广泛支持(另外,调用用该方法并没有太大必要,因为完全可以重新实例化一个枚举器来达到相同效果)。 PS:(COM(Component Object Model)互操作是指在不同的应用程序或系统之间交换数据和功能的能力。在.NET中,COM互操作通常指运行时调用实现了COM接口的本地代码或使用本地COM组件来完成某些任务。
Reset方法是IEnumerator接口定义的一种方法,它的主要作用是将枚举器对象重置为其初始状态,以便再次遍历枚举器对象的元素集合。在许多情况下,这种方法可能不被经常使用。但是,在与COM组件交互时,由于COM组件支持枚举器模式,因此Reset方法在这种情况下非常重要,因为它能够确保枚举器对象始终处于正确的状态。同时,由于COM具有相对较低的性能,因此Reset方法还可以通过减少内存和资源消耗来提高性能。)
通常,集合本身并不实现枚举器,而是通过IEnumerable接口提供枚举器:
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
通过定义一个返回枚举器的方法,IEnumerable灵活地将迭代逻辑转移到了另一个类上。此外,多个消费者可以同时遍历同一个集合而不互相影响。IEnumerable可以看作是“IEnumerator的提供者”,它是所有集合类型需要实现的最基础接口。
以下的例子演示了IEnumerable和IEnumerator的最基本用法:
string s = "Hello";
// 由于C#中的字符串类型实现了IEnumerable接口,所以我们可以在对字符串进行操作时调用GetEnumerator()方法。
IEnumerator rator = s.GetEnumerator();
while (rator.MoveNext())
{
char c = (char) rator.Current;
Console.Write (c + ".");
}
// Output: H.e.l.l.o.
然而,我们很少采用这种直接调用枚举器方法的方式。因为C#提供了更快捷的语法:foreach语句。以下使用foreach语句重写了上述示例:
string s = "Hello"; // The String class implements IEnumerable
foreach (char c in s)
Console.Write (c + ".");
7.1.2 IEnumerable<T>和IEnumerator<T>
IEnumerator和IEnumerable总是和它们的扩展泛型版本同时实现:
public interface IEnumerator<T> : IEnumerator, IDisposable
{
T Current { get; }
}
public interface IEnumerable<T> : IEnumerable
{
IEnumerator<T> GetEnumerator();
}
这些接口通过定义一个类型化的Current和GetEnumerator强化了静态类型安全性,避免了值类型元素装箱的额外开销,而且对于消费者来说更加方便。数组已经自动实现了IEnumerable<T> (其中,T指的是数组成员的类型)。
这段内容在原书中还有其他部分,请参阅原书以获取完整信息。在此处,我只是引用了其中的一些段落,如果您需要更全面的了解,请查阅原书。
7.2 ICollection和IList接口
虽然枚举接口提供了一种向前迭代集合的协议,但是它们并没有提供确定集合大小、根据索引访问成员、搜索以及修改集合的机制。为了实现这些功能,.NET Framework定义了ICollection、IList和IDictionary接口。这些接口都支持泛型和非泛型版本。然而,非泛型版本的存在只是为了兼容遗留代码。
这些接口的继承层次如图7-1所示。可以简单总结为:
· IEnumerable<T> (和IEnumerable):提供了最少的功能支持(仅支持元素枚举)
· ICollection<T> (和ICollection):提供一般的功能(例如Count属性)
· IList<T>/IDictionary<K, V> 及其非泛型版本:支持最多的功能(包括根据索引/键进行“随机”访问)
🐧大多数情况下我们不需要实现这些接口。当需要编写一个集合类时,往往会从Collection<T>(请参见7.6节)派生。LINQ还提供了另一种适合于多个场景的方法。上述接口的泛型和非泛型版本的差异很大,特别是ICollection。这其中很多是由历史原因造成的:泛型出现在后,由于借鉴了之前经验,导致在成员的选择上和之前出现了差异(比之前更好了)。因此,ICollection<T>并没有实现ICollection;而IList<T>也没有实现IList;相应的IDictionary<TKey, TValue>也没有实现IDictionary。当然,在有利的情况下,集合类通常同时实现了两种版本的接口。
🐧 若IList<T>实现IList,则当类型转换为IList<T>接口时,会得到一个同时含有Add(T)和Add(object)成员的接口。而这显著破坏了静态类型安全性,因为我们可以将任意类型作为Add方法的参数。本节将介绍ICollection<T>、IList<T>及其非泛型版本;字典相关的接口将在7.5节介绍。
.NET FrameWork并未统一“集合”(collection)和“列表”(list)这两个词汇的使用方式。例如IList<T>接口比ICollection<T>接口的功能更多,因此很容易认为List<T>类比Collection<T>类的功能更强。但事实并非如此。因此,一般认为“集合”和“列表”这两个术语大体上含义是相同的,只在涉及具体类型时例外。
7.2.1 ICollection<T>和ICollection
ICollection<T>标准集合接口可以对其中的对象进行计数。
它可以确定集合大小(Count),
确定集合中是否存在某个元素(Contains),
将集合复制到一个数组(ToArray)以及确定集合是否为只读(IsReadOnly)。
对于可写集合,还可以对集合元素进行添加(Add)、删除(Remove)以及清空(Clear)操作。
由于它实现了IEnumerable<T>,因此也可以通过foreach语句进行遍历。
public interface ICollection<T> : IEnumerable<T> , IEnumerable
{
int Count { get; }
bool Contains (T item);
void CopyTo (T[] array, int arrayIndex);
bool IsReadOnly { get; }
void Add(T item);
bool Remove (T item);
void Clear();
}
7.2.2 IList<T>和IList
IList<T>是按照位置对集合进行索引的标准接口。
除了从ICollection<T>和IEnumerable<T>继承的功能之外。
它还可以按位置(通过索引器)读写元素,并在特定位置插入/删除元素。
public interface IList<T> : ICollection<T> , IEnumerable<T> , IEnumerable
{
T this [int index] { get; set; }
int IndexOf (T item);
void Insert (int index, T item);
void RemoveAt (int index);
}
IndexOf方法可以对列表执行线性搜索,如果未找到指定的元素则返回-1。
IList的非泛型版本具有更多的成员,因为(相比泛型版本)它从ICollection继承过来的成员比较少:
public interface IList : ICollection, IEnumerable
{
object this [int index] { get; set }
bool IsFixedSize { get; }
bool IsReadOnly { get; }
int Add (object value);
void Clear();
bool Contains (object value);
int IndexOf (object value);
void Insert (int index, object value);
void Remove (object value);
void RemoveAt (int index);
}
非泛型的IList的Add方法会返回一个整数代表最新添加元素的索引。相反,ICollection
通用的List<T>类实现了IList<T>和IList两种接口。C#的数组同样实现了泛型和非泛型版本的IList接口(需要注意,添加和删除元素的方法使用显式接口实现对外隐藏。如果调用这些方法则会抛出NotSupportedException)。
这段内容在原书中还有其他部分,请参阅原书以获取完整信息。在此处,我只是引用了其中的一些段落,如果您需要更全面的了解,请查阅原书。
——↑ 引自《C# 7.0核心技术指南》——————————————————
数组
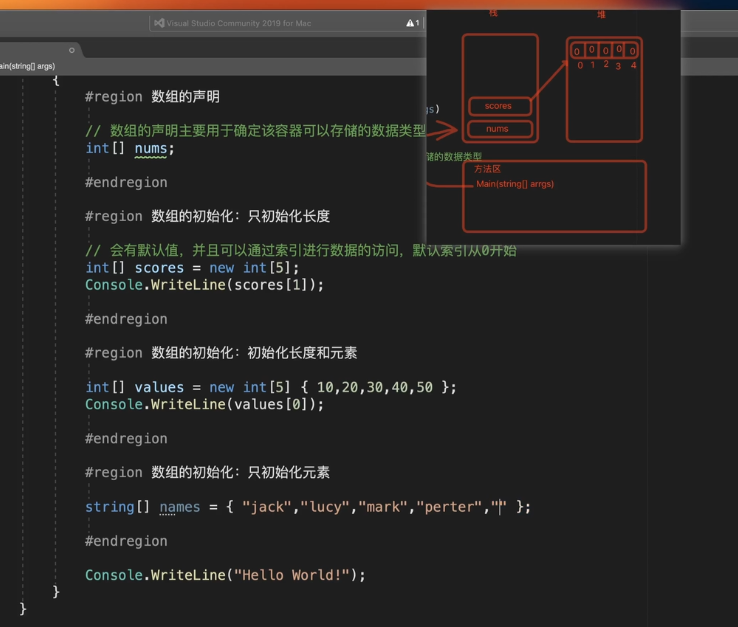
数组的添加操作
public static void Main(string[] args)
{
int[] targetArr = { 3, 5, 7, 9, 11 };
int addIndex = 3;
int addValue = 55;
int[] addArray = new int[targetArr.Length + 1];
for (int i = 0, j = 0; i < targetArr.Length; i++, j++)
{
if (i == addIndex)
{
addArray[j] = addValue;
j++;
}
addArray[j] = targetArr[i];
}
for (int i = 0; i < addArray.Length; i++)
{
Console.Write($"{addArray[i]}、");
}
Console.WriteLine();
}
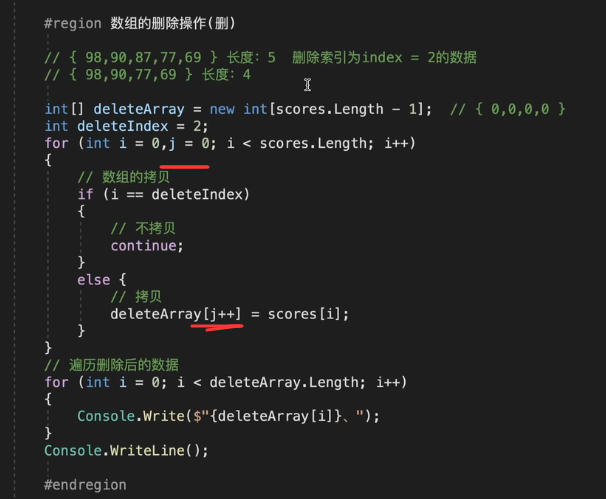
数组的删除操作
通过 j 来进行 deleteArray数组的维护
多维数组
多维数组只需要更多的逗号,例如:
[,,,]
double [,,,] nums;
二维数组的初试化
public static void Main(string[] args)
{
int [,] nums;
int [,] value=new int [3,3]{{1,2,3},{4,5,6},{7,8,9}};
int [,] array={{1,2,3},{4,5,6},{7,8,9}};
Console.WriteLine("value[0,0]="+value[0,0]);
}
获取⼆维数组⾏列
int[,] nums = new int[2, 5];
//结果:⾏:2 列:5
Console.WriteLine($"⾏:{nums.GetLength(0)} 列:{nums.GetLength(1)}");
//遍历
int[,] values = { { 1, 2 }, { 4, 5 }, { 7, 8 } };
for (int i = 0; i < values.GetLength(0); i++)
{
for (int j = 0; j < values.GetLength(1);j++)
{
Console.Write(values[i,j] + " ");
}
Console.WriteLine();
}
GetLength(0) 是一个用于获取多维数组第一维长度的方法。在这个特定的例子中,它被用来获取 values 数组中的行数。 由于 values 是一个有着 3 行 2 列的二维数组,调用 GetLength(0) 方法将返回值 3。
交错数组
//交错数组 可以简单理解为数组中的数组 一个数组中存储了多个数组,即:交错数组
public static void Main(string[] args)
{ //定义并初始化交错数组
int [][] arr = new int[3][]; //定义了一个交错数组,数组中有3个元素,每个元素都是一个数组
arr[0] = new int[2] {1,2}; //第一个元素是一个数组,数组中有2个元素
arr[1] = new int[3] {3,4,5}; //第二个元素是一个数组,数组中有3个元素
arr[2] = new int[4] {6,7,8,9}; //第三个元素是一个数组,数组中有4个元素
//遍历交错数组
for (int i = 0; i < arr.Length; i++)
{
for (int j = 0; j < arr[i].Length; j++)
{
Console.Write(arr[i][j] + " ");
}
Console.WriteLine();
}
}
//也可以这样定义并初始化交错数组
int [][] arr2 = new int[3][]
{
new int[] {1,2},
new int[] {3,4,5},
new int[] {6,7,8,9}
};
Array类
7.3 Array类
Array类是所有一维和多维数组的隐式基类,它是实现标准集合接口的最基本类型之一。
Array类提供了类型统一性,所以所有的数组对象都能够访问它的一套公共的方法,而与它们的声明或实际的元素类型无关。正是由于数组是如此的基础,因此C#提供了显式的数组声明和初始化语法(请参见第2章、第3章)。
当使用C#语法声明数组时,CLR会在内部将其转换为Array类型的子类,合成一个对应该数组维度和元素类型的伪类型。这个伪类型实现了类型化的泛型集合接口,例如IList<string> 。CLR也会特别处理数组类型的创建,它将数组类型分配到一块连续内存空间中。这样数据的索引就非常高效了,同时不允许在创建后修改数组的大小。
Array实现了泛型接口IList<T>及其非泛型版本。但是IList<T>是显式实现的,以保证Array的公开接口中不包含其中的一些方法,如Add和Remove。这些方法会在固定长度的集合(如数组)上抛出异常。Array类实例也提供了一个静态的Resize方法。但是它实际上是创建一个新数组,并将每一个元素复制到新数组中。Resize方法是很低效的,而且程序中其他地方的数组引用仍然指向原始版本的数组。对于可调整大小的集合,一个更好的方式是使用List<T>类(将在下一节介绍)。
数组可以包含值类型或引用类型的元素。值类型元素存储在数组中,所以一个有三个long整数(每一个8字节)的数组将会占用24个字节的连续内存空间。然而,引用类型在数组中只占用一个引用所需的空间(32位环境是4字节,而64位环境则为8字节)。图7-2说明了下面这个程序在内存中的作用效果:
StringBuilder[] builders = new StringBuilder [5];
builders [0] = new StringBuilder ("builder1");
builders [1] = new StringBuilder ("builder2");
builders [2] = new StringBuilder ("builder3");
long[] numbers = new long [3];
numbers [0] = 12345;
numbers [1] = 54321;
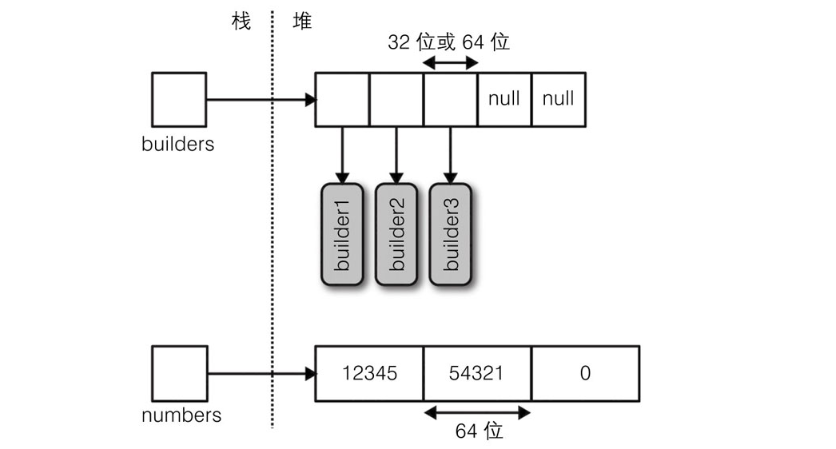
Array本身是一个类。因此无论数组中的元素是什么类型,数组(本身)总是引用类型。这意味着语句arrayB = arrayA的结果是两个变量引用同一数组。类似的,除非使用自定义相等比较器,否则两个不同的数组在相等比较中总是不相等的。
Framework 4.0提供了一种比较数组元素的比较器,可以通过StructuralComparisons类型访问它:
object[] a1 = { "string", 123, true };
object[] a2 = { "string", 123, true };
Console.WriteLine (a1 == a2); // False
Console.WriteLine (a1.Equals (a2)); // False
IStructuralEquatable se1 = a1;
Console.WriteLine (se1.Equals (a2,
StructuralComparisons.StructuralEqualityComparer)); // True
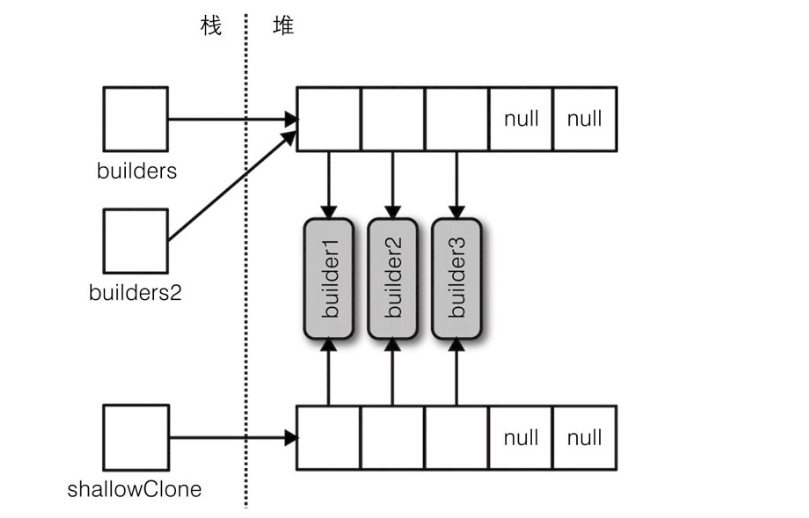
数组可以通过Clone方法进行复制,例如arrayB =arrayA.Clone()。
但是,其结果是一个浅表副本(shallow clone),即表示数组本身的内存会被复制。如果数组中包含的是值类型的对象,那么这些值也会被复制;但如果包含的是引用类型的对象,那么只有引用会被复制(结果就是两个数组的元素都引用了相同的对象)。
图7-3演示了以下代码的效果:
StringBuilder[] builders2 = builders;
StringBuilder[] shallowClone = (StringBuilder[]) builders.Clone();
如果要进行深度复制即复制引用类型子对象,必须遍历整个数组,然后手动克隆每一个元素。相同的规则也适用于其他.NET集合类型。虽然Array主要是针对32位索引器设计的,但是它也通过一些能够接受Int32和Int64参数的方法实现对64位索引器的部分支持(即令数组在理论上支持多至264个元素)。这些重载方法在实际中的作用是很小的,因为CLR不允许任何对象(包括数组)在大小上超过2GB(不论是32位还是64位运行环境都如此)。
可以通过调用Array.CreateInstance动态创建一个数组实例。该方法可以在运行时指定元素类型、维数,以及通过指定数组下界来实现非零开始的数组。非零开始的数组不符合CLS的规定(Common Language Specification,公共语言规范)。可以使用GetValue和SetValue方法访问动态创建的数组元素(它们也可以访问普通数组元素):
// Create a string array 2 elements in length:
Array a = Array.CreateInstance (typeof(string), 2);
a.SetValue ("hi", 0); // → a[0] = "hi";
a.SetValue ("there", 1); // → a[1] = "there";
string s = (string) a.GetValue (0); // → s = a[0];
// We can also cast to a C# array as follows:
string[] cSharpArray = (string[]) a;
string s2 = cSharpArray [0];
动态创建的从零开始索引的数组可以转换为匹配的或类型兼容(满足标准数组的可变性规则)的C#数组。例如,如果Apple是Fruit的子类,那么Apple[]可以转换为Fruit[]。
这就产生了一个问题,为什么不使用object[]作为统一的数组类型而使用Array类呢?
原因就是object[]既不兼容多维数组,也不兼容值类型数组以及不以零开始索引的数组。
int[]数组不能够转换为object[],因此,我们需要Array类实现彻底的类型统一。
查找数据 Array
#region Array类
//System.Array 该类主要提供一个静态的操作数组的方法
#endregion
public static void Main(string[] args)
{
#region 查找数据
int [] score=new int[]{1,2,3,4,5,6,7,8,9,10};
int index=Array.IndexOf(score,5); // public static int IndexOf<T>(T[] array, T value); 传入数组和值 返回索引下标 如果没找到该值,返回-1
Console.WriteLine(index);
int LastIndex = Array.LastIndexOf(scores,10);
//从后向前找 第一个值为10的下标 结果:10
Console.WriteLine(LastIndex);
#endregion
}
Array 拷贝数组

#region 拷贝数组
int[] score = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10 };
int[] score2 = new int[5];
Array.Copy(score, score2, 5);
foreach (var item in score2)
{
Console.Write($"{item}、");
}
#endregion
//输出结果为 1、2、3、4、5、
——↓ 引自《C# 7.0核心技术指南》——————————————————
7.3.7 复制数组
Array 提供了4个对数组进行浅表复制的方法:Clone、CopyTo、Copy和ConstrainedCopy。 Clone、CopyTo是实例方法;Copy和ConstrainedCopy为静态方法。Clone方法返回一个全新的(浅表复制的)数组,CopyTo和Copy方法复制数组中的若干连续元素。若复制多维数组则需要将多维数组的索引映射为线性索引。例如,一个3×3数组的中间矩阵(position[1, 1])的索引可以用4表示。其计算方法是1*3+1。这些方法允许源与目标范围重叠而不会造成任何问题。
ConstrainedCopy执行一个原子操作:如果所有请求的元素无法成功复制(例如类型错误)那么操作将会回滚。Array还提供了一个AsReadOnly方法来包装数组以防止其中的元素被重新赋值。
Array 排序数据

#region 排序数据
int[] scores = new int[] { 99, 20, 55, 20, 30, 94, 93, 92, 91, 90 };
Array.Sort(scores); //排序 默认升序
//输出
Console.WriteLine("Sort排序后:");
for (int i = 0; i < scores.Length; i++)
{
Console.Write($"{ scores[i] }、 ");
}
Console.WriteLine();
Array.Sort(scores, new Comparison<int>((i1, i2) => { return i2 - i1; })); //降序
Array.Reverse(scores); //反转
Array.Clear(scores, 0, scores.Length); //清空 ()
#endregion
//二分查找
Console.WriteLine("二分查找:");
int index = Array.BinarySearch(scores, 20);
Console.WriteLine($"index:{index}");
Array 清空数据
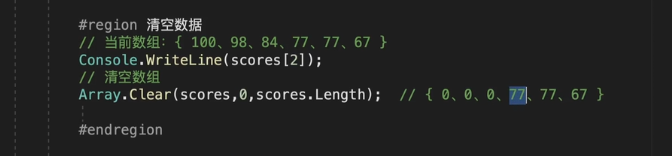
Array.Clear是一个用于清空数组元素的静态方法。使用它可以将一个数组中指定范围内的元素设置为默认值(数组元素类型的默认值)。
以下是Array.Clear方法的语法:
public static void Clear(Array array, int index, int length);
其中,array表示要清空的数组;index表示需要清空的起始位置;length表示需要清空的元素个数。
调用Array.Clear方法后,数组中从起始位置开始的一定数量的元素会被设置为数组元素类型的默认值,例如int数组中的元素会被设置为0,对象数组中的元素会被设置为null,bool数组中的元素会被设置为false等等。
以下是一个示例:
int[] arr = new int[5] { 1, 2, 3, 4, 5 };
Array.Clear(arr, 1, 3);
// 现在 arr 数组的元素为 {1, 0, 0, 0, 5}
在上述示例中,arr数组的第二个、第三个和第四个元素都被设置为默认值0。
集合
System.Collections 名称空间中的几个接口提供了基本的组合功能:
IEnumerable 可以迭代集合中的项。
ICollection(继承于 IEnumerable)可以获取集合中项的个数,并能把项复制到一个简单的数
组类型中。
IList(继承于 IEnumerable 和 ICollection)提供了集合的项列表,允许访问这些项,并提供其
他一些与项列表相关的基本功能。
IDictionary(继承于 IEnumerable 和 ICollection)类似于 IList,但提供了可通过键值(而不是索引)访问的项列表。
System.Array 类实现 IList、ICollection 和 IEnumerable,但不支持 IList 的一些更高级的功能,它表示大小固定的项列表。
视频学习:【079-ArrayList】 B站:IT萌叔Jack
ArrayList
// 创建容器对象
ArrayList arrayList = new ArrayList();
// 增
arrayList.Add("北京");
ArrayList list = new ArrayList();
list.Add("上海");
list.Add("⼴州");
arrayList.AddRange(list);
arrayList.Insert(1,"深圳");
Print(arrayList); // 结果:北京, 深圳, 上海, ⼴州,
// 查
Console.WriteLine($"容器容量:{arrayList.Capacity}"); // 结果:容器容量:4
Console.WriteLine($"数据⻓度:{arrayList.Count}"); // 结果:数据⻓度:4
Console.WriteLine(arrayList[0]); // 结果:北京
// 改
arrayList[0] = "⾹港";
Print(arrayList); // 结果:⾹港, 深圳, 上海, ⼴州,
// 删
arrayList.Remove("上海");
Print(arrayList); // 结果:⾹港, 深圳, ⼴州,
arrayList.RemoveAt(arrayList.Count - 1);
Print(arrayList); // 结果:⾹港, 深圳
// foreach遍历
foreach (string city in arrayList)
{
Console.Write(city + ", ");
}
Console.WriteLine();
// 迭代器遍历
IEnumerator enumerator = arrayList.GetEnumerator();
while (enumerator.MoveNext()) {
Console.Write(enumerator.Current + ", ");
}
Console.WriteLine();
}
// 定义⼀个遍历集合的⽅法
public static void Print(ArrayList list) {
for (int i = 0; i < list.Count; i!%)
{
Console.Write(list[i] + ", ");
}
Console.WriteLine();
}
视频学习:【082-Hashtable】 B站:IT萌叔Jack
Hashtable

可以通过Key遍历,也可以通过Value遍历,也可以键值对输出。
问题: 如果自定义类作为Hashtable的Key,如何判断是否是同一个key呢?
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 核心技术指南
{
class Key
{
public char key;
public Key(char key)
{
this.key = key;
}
// 重写⽅法
public override bool Equals(object obj)
{
return this.key == (obj as Key).key;
}
public override int GetHashCode()
{
return this.key.GetHashCode();
}
public static void Main(string[] args)
{
Hashtable table = new Hashtable();
table.Add(new Key('H'), "按键H");
//此时不会报错,因为hashtable不认为两个Key相同,重写Key类的Equals()和GetHashCode()⽅法就会报错
//重写之后,再次添加会报错
//table.Add(new Key('H'), "按键H");
Console.WriteLine(table[new Key('H')]);
}
}
}
——↓ 引自《C# 7.0核心技术指南》——————————————————
6.11.3.4重写GetHashCode
GetHashCode是Object类型中的一个虚方法。也许在System.Object这个只拥有很少预定义成员的类型中定义这个应用范围狭窄且用途特定的方法很怪异。因为它只服务于以下两种类型:
System.Collections.Hashtable
System.Collections.Generic.Dictionary<TKey, TValue>
这些类型都是散列表(hashtable),即一些使用键来存储和获取元素的集合。散列表支持一个基于键的高效分配元素的方法。 它要求每一个键都是Int32整数,或者称为散列码。 散列码对于每个键来说不需要唯一,但是为了实现最佳的散列表性能,它要尽可能保持差异性。 哈希表在系统中的地位是非常重要的,因此在System.Object中定义了GetHashCode方法,令每一种类型都能够生成散列码。
我们将在7.5节详细介绍散列表。引用类型和值类型都有默认的GetHashCode的实现。这意味只要不重写Equals,就不用重写GetHashCode(如果重写了GetHashCode那么几乎可以肯定Equals方法也会被重写)。下面是重写object.GetHashCode的其他规则:
· 它必须在Equals方法返回true的两个对象上返回相同的值。因此,GetHashCode和Equals通常成对地重写。
· 它不能抛出异常。
· 如果重复调用相同的对象,那么必须返回相同的值(除非对象改变)。
为了实现最佳的散列表性能,GetHashCode应当尽可能避免为两个不同的值返回相同的散列码。
这也是方才在结构体上重写GetHashCode和Equals的第三个原因,其目的就是为了实现更高效的散列算法。
结构体上的默认散列算法是在运行时生成的,它基于结构体中的每一个字段值来计算散列码。
相反,类的默认GetHashCode的实现是基于一个内部对象标识的。这个标识,基于目前的CLR实现,在所有实例中是唯一的。
如果一个对象作为键添加到字典后其散列码发生了变化,那么这个对象在字典中将不可访问。因此可以基于不可变的字段进行散列码的计算以避免这个问题。我们随后将用一个完整的例子展示重写GetHashCode的方法。
6.11.3.5 重写Equals
object.Equals的逻辑如下:
· 对象不可能是null(除非它是一个可空类型)
· 相等是自反性的(对象与其本身相等)
· 相等是可交换的(如果a.Equals(b)那么b.Equals(a))
· 相等是可传递的(如果a.Equals(b)且b.Equals(c)那么a.Equals(c))
· 相等比较操作是可以重复并且可靠的(它不会抛出异常)。
——↑ 引自《C# 7.0核心技术指南》——————————————————
泛型集合
* List<T>
* Stack<T>
* Queue<T>
* Dictionary<K,V>
* LinkedList<T>
* 自定义泛型
* 泛型约束
——↓ 引自《C# 7.0核心技术指南》——————————————————
7.4.1 List<T>和ArrayList
泛型List和非泛型ArrayList类都提供了一种可动态调整大小的对象数组实现。它们是集合类中使用最广泛的类型,ArrayList实现了IList而List<T>既实现了IList又实现了IList<T>。与数组不同,所有的接口都是公开实现的,而且其方法例如Add和Remove也都是公开可用的。
List<T>和ArrayList在内部都维护了一个对象数组,并在超出容量的时候替换为一个更大的数组。
在集合中追加元素的效率很高(因为数组末尾一般都有空闲的位置),而插入元素的速度会慢一些(因为插入位置之后的所有元素都必须向后移动才能留出插入空间)。与数组一样,对排序的列表执行BinarySearch是非常高效的。但其他情况下就需要检查每一个元素,因而效率就不是那么高了。
🦢如果T是一种值类型,那么List
List
public class List<T> : IList<T> , IReadOnlyList<T>
{
public List ();
public List (IEnumerable<T> collection);
public List (int capacity);
// Add+Insert
public void Add (T item);
public void AddRange (IEnumerable<T> collection);
public void Insert (int index, T item);
public void InsertRange (int index, IEnumerable<T> collection);
// Remove
public bool Remove (T item);
public void RemoveAt (int index);
public void RemoveRange (int index, int count);
public int RemoveAll (Predicate<T> match);
// Indexing
public T this [int index] { get; set; }
public List<T> GetRange (int index, int count);
public Enumerator<T> GetEnumerator();
// Exporting, copying and converting:
public T[] ToArray();
public void CopyTo (T[] array);
public void CopyTo (T[] array, int arrayIndex);
public void CopyTo (int index, T[] array, int arrayIndex, int count);
public ReadOnlyCollection<T> AsReadOnly();
public List<TOutput> ConvertAll<TOutput> (Converter <T, TOutput>
converter);
// Other:
public void Reverse(); // 反转列表中的所有元素。
public int Capacity { get; set; } // 强制扩展内部数组的大小。
public void TrimExcess(); // 将内部数组的大小调整为集合当前包含的元素数。
public void Clear(); // 删除所有元素,使 Count=0。
}
public delegate TOutput Converter <TInput, TOutput> (TInput input);
除了上述成员,List
🦢ArrayList从功能上和List

