C++基础之对象模型
前言
网上关于C++对象模型的资料有很多,找到了两篇较为详实细致,理论与实践结合得较好,图文并茂的文章,在此做个总结转载,用以巩固与温故。(之所以是两篇,是因为这两篇内容大体一致,但出处却是两位作者,不知是谁原创,索性做个汇总。。。原文中存在多处错误或语义表述不清,已做修正补充)
图文和代码源自两处,略有不同。
附原文链接:
图说C++对象模型:对象内存布局详解(代码参考)
C++对象模型(图文参考)
正文
引用《深度探索C++对象模型》这本书中的话:
有两个概念可以解释C++对象模型:
- 语言中直接支持面向对象程序设计的部分。
- 对于各种支持的底层实现机制。
语言中直接支持面向对象程序设计的部分,如构造函数、析构函数、虚函数、继承(单继承、多继承、虚继承)、多态等等。第一部分这里我简单过一下,重点在底层实现机制。
在C语言中,“数据”和“处理数据的操作(函数)”是分开来声明的,也就是说,语言本身并没有支持“数据和函数”之间的关联性。在C++中,通过抽象数据类型(abstract data type,ADT),在类中定义数据和函数,来实现数据和函数直接的绑定。
概括来说,在C++类中有两种成员数据:static、nonstatic;三种成员函数:static、nonstatic、virtual。

如下面的Base类定义:
class Base { public: Base(int i) :baseI(i){}; //non-static function int getI(){ return baseI; } //non-static function static void countI(){}; //static function virtual ~Base(){} //virtual function virtual void print(void){ cout << "Base::print()"; } //virtual function private: int baseI; //non-static variable static int baseS; //static variable };
Base类在机器中我们如何构建出各种成员数据和成员函数呢?
基本C++对象模型
在介绍C++使用的对象模型之前,介绍2种对象模型:简单对象模型(a simple object model)、表格驱动对象模型(a table-driven object model)。
slot(槽)
每个slot(槽)中存放的是虚函数的地址,而并非真正的函数(二级制指令),请注意区分!
简单对象模型(a simple object model)

所有的成员占用相同的空间(跟成员类型无关),对象只是维护了一个包含成员指针的一个表。表中放的是成员的地址,无论上成员变量还是函数,都是这样处理。对象并没有直接保存成员而是保存了成员的指针。
表格对象模型(a table-driven object model)
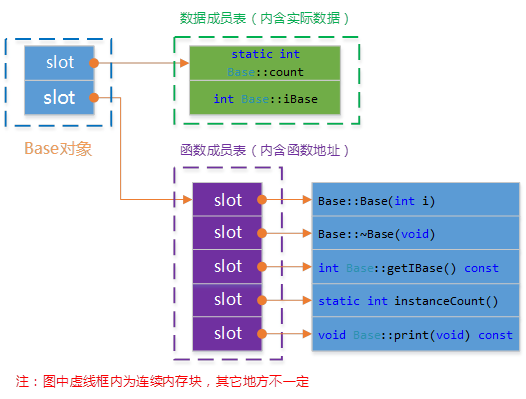
这个模型在简单对象的基础上又添加了一个间接层。将成员分成函数和数据,并且用两个表格保存,然后对象只保存了两个指向表格的指针。这个模型可以保证所有的对象具有相同的大小,比如简单对象模型还与成员的个数相关。其中数据成员表中包含实际数据;函数成员表中包含的实际函数的地址(与数据成员相比,多一次寻址)。
C++对象模型
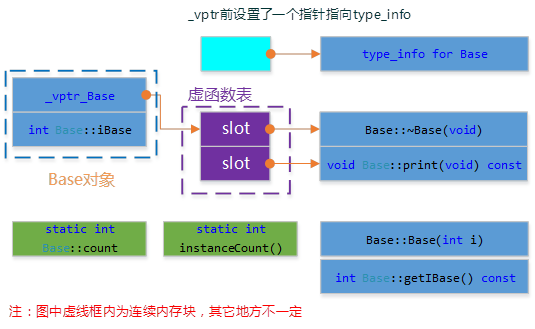
这个模型从结合上面两种模型的特点,并对内存存取和空间进行了优化。在此模型中,nonstatic数据成员被放置到对象内部,static数据成员, static and nonstatic函数成员均被放到对象之外。对于虚函数的支持则分两步完成:
- 每一个class产生一堆指向虚函数的指针,放在表格之中。这个表格称之为虚函数表(virtual table,vtbl)。
- 每一个对象被添加了一个指针,指向相关的虚函数表vtbl。通常这个指针被称为vptr。vptr的设定(setting)和重置(resetting)都由每一个class的构造函数,析构函数和拷贝赋值运算符自动完成。
另外,虚函数表地址的前面设置了一个指向type_info的指针,RTTI(Run Time Type Identification)运行时类型识别是由编译器在编译期生成的特殊类型信息,包括对象继承关系,对象本身的描述,RTTI是为多态而生成的信息,所以只有具有虚函数的对象才会生成。
优缺点
这个模型的优点在于它的空间和存取时间的效率;
缺点如下:如果应用程序本身未改变,但当所使用的类的non static数据成员添加删除或修改时,需要重新编译。
模型验证测试
void testBase(Base &p) { cout << "对象的内存起始地址:" << &p << endl; cout << "type_info信息:" << endl; RTTICompleteObjectLocator str = *((RTTICompleteObjectLocator*)*((int*)*(int*)(&p) - 1)); string classname(str.pTypeDescriptor->name); classname = classname.substr(4, classname.find("@@") - 4); cout << "根据type_info信息输出类名:"<< classname << endl; cout << "虚函数表指针地址:" << (int *)(&p) << endl; //修正 //验证虚表 cout << "虚函数表地址,即第一个虚函数指针(slot)地址:" << (int *)*((int*)(&p)) << endl; //修正 cout << "析构函数的地址:" << (int* )*(int *)*((int*)(&p)) << endl; cout << "虚函数表中,第二个虚函数即print()的指针(slot)地址:" << ((int*)*(int*)(&p) + 1) << endl; //修正 //通过地址调用虚函数print() typedef void(*Fun)(void); Fun IsPrint=(Fun)* ((int*)*(int*)(&p) + 1); cout << endl; cout<<"调用了第二个虚函数";//补充 IsPrint(); //若地址正确,则调用了Base类的虚函数print() cout << endl; //输入static函数的地址 p.countI();//先调用函数以产生一个实例 cout << "static函数countI()的地址:" << p.countI << endl; //验证nonstatic数据成员 cout << "推测nonstatic数据成员baseI的地址:" << (int *)(&p) + 1 << endl; cout << "根据推测出的地址,输出该地址的值:" << *((int *)(&p) + 1) << endl; cout << "Base::getI():" << p.getI() << endl; } //Base b(1000); //testBase(b);

结果分析
根据C++对象模型,实例化对象b的起始内存地址,即虚函数表地址。
- 虚函数表中第1个slot是虚析构函数的指针,指向真正的虚析构函数;
- 虚函数表的中第2个slot是虚函数print()的指针,通过函数指针可以调用,进行验证;
- 推测数据成员iBase的地址,为虚函数表指针的地址 + 1,即 ((int *)(&b) +1) ;
- 静态数据成员和静态函数所在内存地址,与对象数据成员和函数成员位段不一样;
【原文代码均为win32位系统环境下的测试,我在Linux Ubuntu18.04 64位系统上报错,遂将代码中的int替换为long类型】
【另外评论区有人补充,gcc下做实验调试测试的时候,发现了一个有意思的现象:在虚表中的析构函数,占两个slot(紧挨着)。查了下google,说第一个是基础对象析构函数,第二个是删除析构函数,由这两个函数共同完成析构,有兴趣可以一起探索下。】
C++对象模型中加入单继承
不管是单继承、多继承,还是虚继承,如果基于“简单对象模型”,每一个基类都可以被派生类中的一个slot指出,该slot内包含基类对象的地址。这个机制的主要缺点是,因为间接性而导致空间和存取时间上的额外负担;优点则是派生类对象的大小不会因其基类的改变而受影响。
如果基于“表格驱动模型”,派生类中有一个slot指向基类表,表格中的每一个slot含一个相关的基类地址(这个很像虚函数表,内含每一个虚函数的地址)。这样每个派生类对象增加一个基类表指针(bptr),它会被初始化,指向其基类表。这种策略的主要缺点是由于间接性而导致的空间和存取时间上的额外负担;优点则是在每一个派生类对象中对继承都有一致的表现方式,每一个派生类对象都应该在某个固定位置上放置一个基类表指针,与基类的大小或数量无关。第二个优点是,不需要改变派生类对象本身,就可以放大,缩小、或更改基类表。
不管上述哪一种机制,“间接性”的级数都将因为集成的深度而增加。
C++实际模型是,对于一般继承是扩充已有存在的虚函数表;对于虚继承,添加一个虚函数表指针。
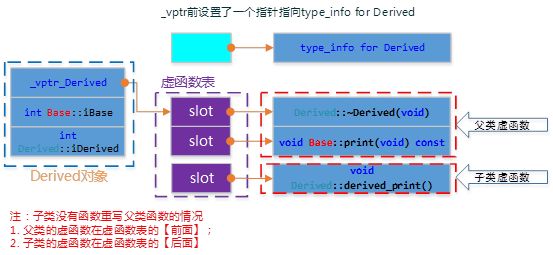
无重写的单继承
class Derive : public Base { public: Derive(int d) :Base(1000), DeriveI(d){}; // Derive声明的新的虚函数 virtual void Drive_print(){ cout << "Drive::Drive_print()" ; } virtual ~Derive(){} private: int DeriveI; };
Base的模型跟上面的一样,不受继承的影响。Derived不是虚继承,所以是扩充已存在的虚函数表,结构如下图所示:
有重写的单继承
class Derive : public Base { public: Derive(int d) :Base(1000), DeriveI(d){}; //overwrite父类虚函数print() virtual void print(void){ cout << "Drive::Drive_print()" ; } // Derive声明的新的虚函数 virtual void Drive_print(){ cout << "Drive::Drive_print()" ; } virtual ~Derive(){} private: int DeriveI; };
重写print()函数在虚函数表中表现如下:
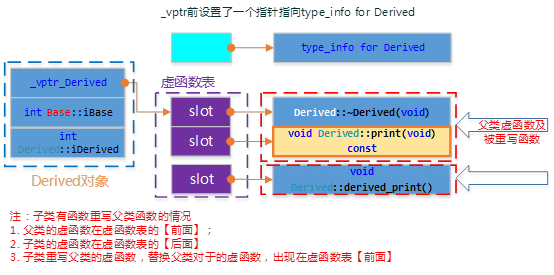
在C++对象模型中,对于一般继承(这个一般是相对于虚继承而言),若子类重写(overwrite)了父类的虚函数,则子类虚函数将覆盖虚表中对应的父类虚函数(注意子类与父类拥有各自的一个虚函数表);若子类并无overwrite父类虚函数,而是声明了自己新的虚函数,则该虚函数地址将扩充到虚函数表最后。而对于虚继承,若子类overwrite父类虚函数,同样地将覆盖父类子物体中的虚函数表对应位置,而若子类声明了自己新的虚函数,则编译器将为子类增加一个新的虚表指针vptr,这与一般继承不同,在后面再讨论。


typedef void(*Fun)(void); int main() { Derive d(2000); //[0] cout << "[0]Base::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //vprt[0] cout << " [0]"; Fun fun1 = (Fun)*((int *)*((int *)(&d))); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d))) << endl; //vprt[1]析构函数无法通过地址调用,故手动输出 cout << " [1]" << "Derive::~Derive" << endl; //vprt[2] cout << " [2]"; Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2); fun2(); cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl; //[1] cout << "[2]Base::baseI=" << *(int*)((int *)(&d) + 1); cout << "\t地址:" << (int *)(&d) + 1; cout << endl; //[2] cout << "[2]Derive::DeriveI=" << *(int*)((int *)(&d) + 2); cout << "\t地址:" << (int *)(&d) + 2; cout << endl; getchar(); }
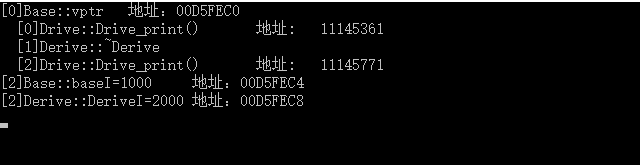
C++对象模型中加入多继承
从单继承可以知道,派生类中只是扩充了基类的虚函数表。如果是多继承的话,又是如何扩充的?
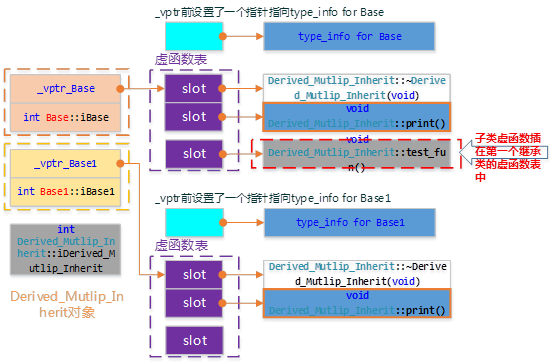
- 每个基类都有自己的虚表。
- 子类的成员函数被放到了第一个基类的表中。
- 内存布局中,其父类布局依次按声明顺序排列。
- 每个基类的虚表中的print()函数都被overwrite成了子类的print ()。这样做就是为了解决不同的基类类型的指针指向同一个子类实例,而能够调用到实际的函数。
class Base { public: Base(int i) :baseI(i){}; virtual ~Base(){} int getI(){ return baseI; } static void countI(){}; virtual void print(void){ cout << "Base::print()"; } private: int baseI; static int baseS; }; class Base_2 { public: Base_2(int i) :base2I(i){}; virtual ~Base_2(){} int getI(){ return base2I; } static void countI(){}; virtual void print(void){ cout << "Base_2::print()"; } private: int base2I; static int base2S; }; class Derive_multyBase :public Base, public Base_2 { public: Derive_multyBase(int d) :Base(1000), Base_2(2000) ,Derive_multyBaseI(d){}; virtual void print(void){ cout << "Derive_multyBase::print" ; } virtual void Derive_print(){ cout << "Derive_multyBase::Drive_print" ; } private: int Derive_multyBaseI; };
typedef void(*Fun)(void); int main() { Drive_multyBase d(3000); //[0] cout << "[0]Base::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //vprt[0]析构函数无法通过地址调用,故手动输出 cout << " [0]" << "Derive::~Derive" << endl; //vprt[1] cout << " [1]"; Fun fun1 = (Fun)*((int *)*((int *)(&d))+1); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl; //vprt[2] cout << " [2]"; Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2); fun2(); cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl; //[1] cout << "[1]Base::baseI=" << *(int*)((int *)(&d) + 1); cout << "\t地址:" << (int *)(&d) + 1; cout << endl; //[2] cout << "[2]Base_::vptr"; cout << "\t地址:" << (int *)(&d)+2 << endl; //vprt[0]析构函数无法通过地址调用,故手动输出 cout << " [0]" << "Drive_multyBase::~Derive" << endl; //vprt[1] cout << " [1]"; Fun fun4 = (Fun)*((int *)*((int *)(&d))+1); fun4(); cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl; //[3] cout << "[3]Base_2::base2I=" << *(int*)((int *)(&d) + 3); cout << "\t地址:" << (int *)(&d) + 3; cout << endl; //[4] cout << "[4]Drive_multyBase::Drive_multyBaseI=" << *(int*)((int *)(&d) + 4); cout << "\t地址:" << (int *)(&d) + 4; cout << endl; getchar(); }

菱形继承(重复继承)
存在的问题
菱形继承也称为钻石型继承或重复继承,它指的是间接基类被某个派生类简单重复继承了多次。这样,派生类对象中拥有多份基类实例(这会带来一些问题):
class B { public: int ib; public: B(int i=1) :ib(i){} virtual void f() { cout << "B::f()" << endl; } virtual void Bf() { cout << "B::Bf()" << endl; } }; class B1 : public B { public: int ib1; public: B1(int i = 100 ) :ib1(i) {} virtual void f() { cout << "B1::f()" << endl; } virtual void f1() { cout << "B1::f1()" << endl; } virtual void Bf1() { cout << "B1::Bf1()" << endl; } }; class B2 : public B { public: int ib2; public: B2(int i = 1000) :ib2(i) {} virtual void f() { cout << "B2::f()" << endl; } virtual void f2() { cout << "B2::f2()" << endl; } virtual void Bf2() { cout << "B2::Bf2()" << endl; } }; class D : public B1, public B2 { public: int id; public: D(int i= 10000) :id(i){} virtual void f() { cout << "D::f()" << endl; } virtual void f1() { cout << "D::f1()" << endl; } virtual void f2() { cout << "D::f2()" << endl; } virtual void Df() { cout << "D::Df()" << endl; } };
这时,根据单继承,我们可以分析出B1,B2类继承于B类时的内存布局。又根据一般多继承,我们可以分析出D类的内存布局。我们可以得出D类子对象的内存布局如下图:
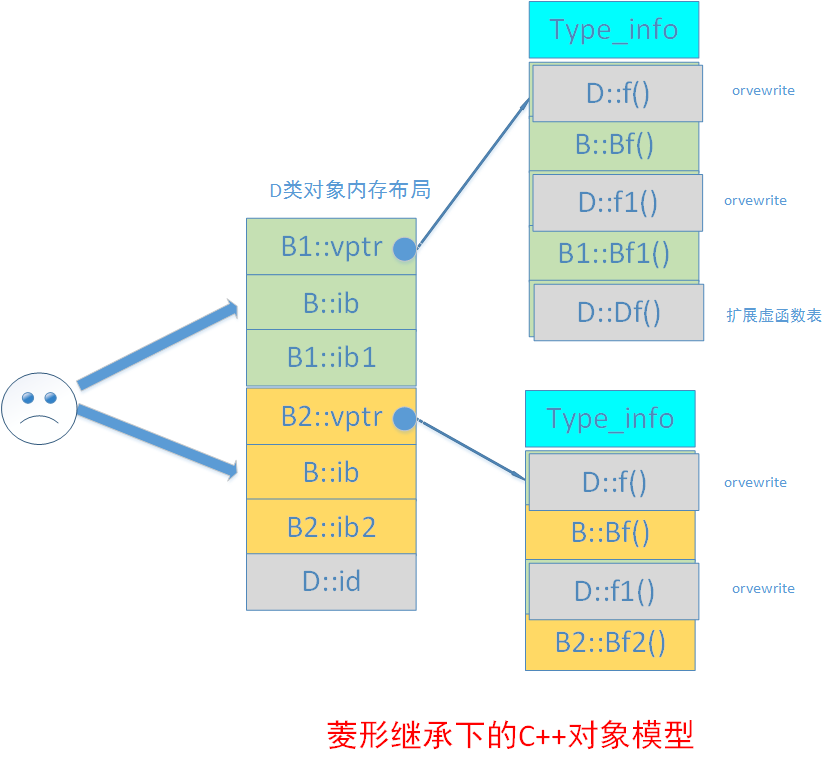
D类对象内存布局中,图中青色表示b1类子对象实例,黄色表示b2类子对象实例,灰色表示D类子对象实例。从图中可以看到,由于D类间接继承了B类两次,导致D类对象中含有两个B类的数据成员ib,一个属于来源B1类,一个来源B2类。这样不仅增大了空间,更重要的是引起了程序歧义:
D d; d.ib =1 ; //二义性错误,调用的是B1的ib还是B2的ib? d.B1::ib = 1; //正确 d.B2::ib = 1; //正确
尽管我们可以通过明确指明调用路径以消除二义性,但二义性的潜在性还没有消除,我们可以通过虚继承来使D类只拥有一个ib实体。
C++对象模型中加入虚继承
虚继承是为了解决重复继承中多个间接父类的问题的,所以不能使用上面简单的扩充并为每个虚基类提供一个虚函数指针(这样会导致重复继承的基类会有多个虚函数表)形式。
- 虚继承的子类,如果本身定义了新的虚函数,则编译器为其生成一个虚函数指针(vptr)以及一张虚函数表。该vptr位于对象内存最前面。
- vs非虚继承:直接扩展父类虚函数表。
- 虚继承的子类也单独保留了父类的vprt与虚函数表。这部分内容接与子类内容以一个四字节的0来分界。
- 虚继承的子类对象中,含有四字节的虚表指针偏移值。
因此,在虚继承中,派生类和基类的数据,是完全间隔的,先存放派生类自己的虚函数表和数据,中间以0x00000000分界,最后保存基类的虚函数和数据。如果派生类重载了父类的虚函数,那么则将派生类内存中基类虚函数表的相应函数替换。
虚基类表
在C++对象模型中,虚继承而来的子类会生成一个隐藏的虚基类指针(vbptr),在Microsoft Visual C++中,虚基类表指针总是在虚函数表指针之后,因而,对某个类实例来说,如果它有虚基类指针,那么虚基类指针可能在实例的0字节偏移处(该类没有vptr时,vbptr就处于类实例内存布局的最前面,否则vptr处于类实例内存布局的最前面),也可能在类实例的4字节偏移处。
一个类的虚基类指针指向的虚基类表,与虚函数表一样,虚基类表也由多个条目组成,条目中存放的是偏移值。第一个条目存放虚基类表指针(vbptr)所在地址到该类内存首地址的偏移值,由第一段的分析我们知道,这个偏移值为0(类没有vptr)或者-4(类有虚函数,此时有vptr)。我们通过一张图来更好地理解。
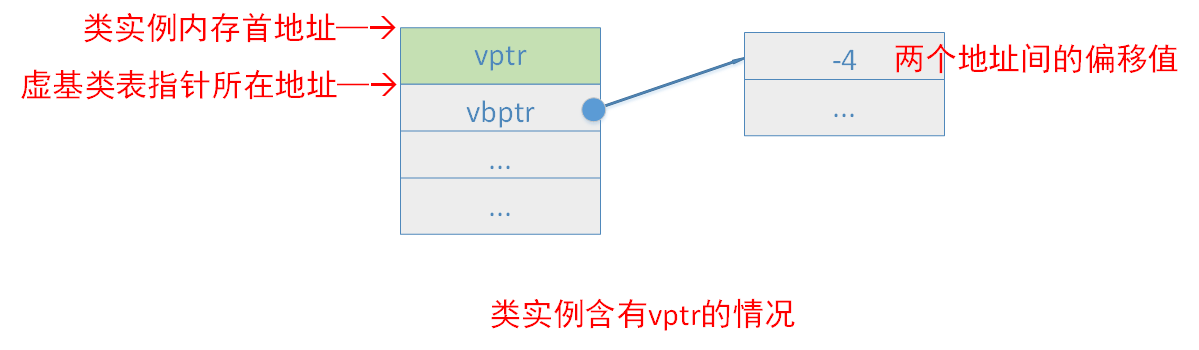
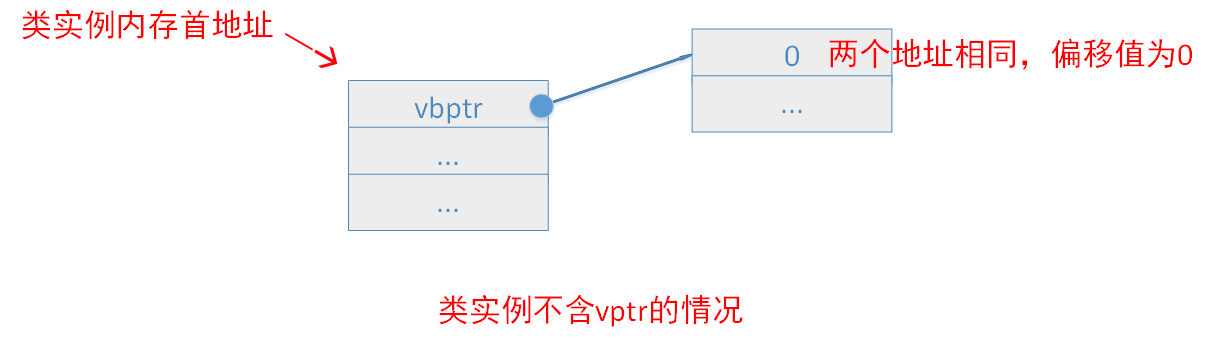
虚基类表的第二、第三...个条目依次为该类的最左虚继承父类、次左虚继承父类...的内存地址相对于虚基类表指针的偏移值,这点我们在下面会验证。
简单虚继承(无重复继承情况)
Derived_Virtual_Inherit1的对象模型如下图:
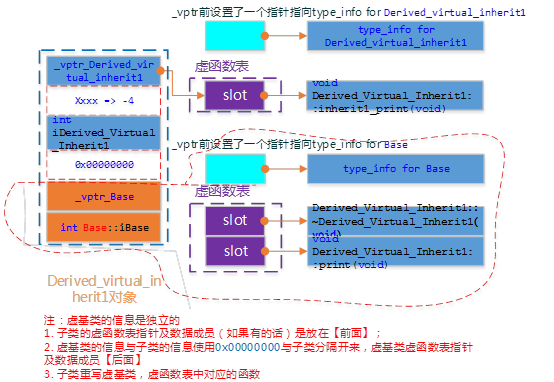
虚继承的子类,有单独的虚函数表,另外也单独保存一份父类的虚函数表,两部分之间用一个四个字节的0x00000000来作为分界(不同编译器这里存在差异,在GCC下没有0x00000000分隔的,在VC++下有)。派生类的内存中,首先是自己的虚函数表,虚基类表,然后是派生类的数据成员,之后就是基类的虚函数表,之后是基类的数据成员。
如果派生类没有自己的虚函数,那么派生类就不会有虚函数表,但是派生类数据和基类数据之间,还是需要0x0来间隔(GCC下没有)。
int main() { B1 a; cout <<"B1对象内存大小为:"<< sizeof(a) << endl; //取得B1的虚函数表 cout << "[0]B1::vptr"; cout << "\t地址:" << (int *)(&a)<< endl; //输出虚表B1::vptr中的函数 for (int i = 0; i<2;++ i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*(int *)(&a) + i); fun1(); cout << "\t地址:\t" << *((int *)*(int *)(&a) + i) << endl; } //[1] cout << "[1]vbptr " ; cout<<"\t地址:" << (int *)(&a) + 1<<endl; //虚表指针的地址 //输出虚基类指针条目所指的内容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&a) + 1) + i); cout << endl; } //[2] cout << "[2]B1::ib1=" << *(int*)((int *)(&a) + 2); cout << "\t地址:" << (int *)(&a) + 2; cout << endl; //[3] cout << "[3]值=" << *(int*)((int *)(&a) + 3); cout << "\t\t地址:" << (int *)(&a) + 3; cout << endl; //[4] cout << "[4]B::vptr"; cout << "\t地址:" << (int *)(&a) +3<< endl; //输出B::vptr中的虚函数 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&a) + 4) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&a) + 4) + i) << endl; } //[5] cout << "[5]B::ib=" << *(int*)((int *)(&a) + 5); cout << "\t地址: " << (int *)(&a) + 5; cout << endl; }
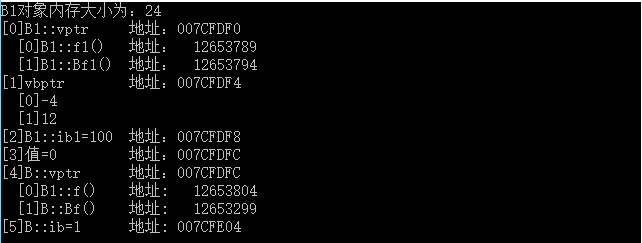
结果分析
这个结果与我们的C++对象模型图完全符合。这时我们可以来分析一下虚表指针的第二个条目值12的具体来源了,回忆上文讲到的:
第二、第三...个条目依次为该类的最左虚继承父类、次左虚继承父类...的内存地址相对于虚基类表指针的偏移值。
在我们的例子中,也就是B类实例内存地址相对于vbptr的偏移值,也即是:[4]-[1]的偏移值,结果即为12,从地址上也可以计算出来:007CFDFC-007CFDF4结果的十进制数正是12。现在,我们对虚基类表的构成应该有了一个更好的理解。
虚继承(菱形继承)
class B{...} class B1: virtual public B{...} class B2: virtual public B{...} class D : public B1,public B2{...}
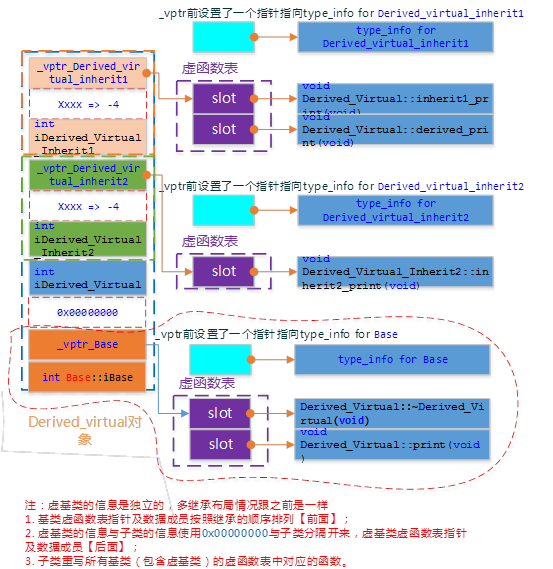
菱形虚拟继承下,最后派生类D类的对象模型又有不同的构成了。在D类对象的内存构成上,有以下几点:
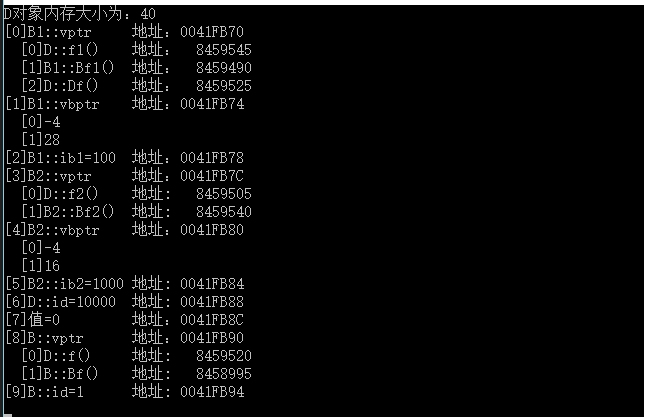
- 在D类对象内存中,基类出现的顺序是:先是B1(最左父类),然后是B2(次左父类),最后是B(虚祖父类)
- D类对象的数据成员id放在B类前面,两部分数据依旧以0来分隔。
- 编译器没有为D类生成一个它自己的vptr,而是覆盖并扩展了最左父类的虚基类表,与简单继承的对象模型相同。
- 超类B的内容放到了D类对象内存布局的最后。
Derived_Virtual的对象模型如下图:
int main() { D d; cout << "D对象内存大小为:" << sizeof(d) << endl; //取得B1的虚函数表 cout << "[0]B1::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //输出虚表B1::vptr中的函数 for (int i = 0; i<3; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*(int *)(&d) + i); fun1(); cout << "\t地址:\t" << *((int *)*(int *)(&d) + i) << endl; } //[1] cout << "[1]B1::vbptr "; cout << "\t地址:" << (int *)(&d) + 1 << endl; //虚表指针的地址 //输出虚基类指针条目所指的内容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&d) + 1) + i); cout << endl; } //[2] cout << "[2]B1::ib1=" << *(int*)((int *)(&d) + 2); cout << "\t地址:" << (int *)(&d) + 2; cout << endl; //[3] cout << "[3]B2::vptr"; cout << "\t地址:" << (int *)(&d) + 3 << endl; //输出B2::vptr中的虚函数 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&d) + 3) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d) + 3) + i) << endl; } //[4] cout << "[4]B2::vbptr "; cout << "\t地址:" << (int *)(&d) + 4 << endl; //虚表指针的地址 //输出虚基类指针条目所指的内容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&d) + 4) + i); cout << endl; } //[5] cout << "[5]B2::ib2=" << *(int*)((int *)(&d) + 5); cout << "\t地址: " << (int *)(&d) + 5; cout << endl; //[6] cout << "[6]D::id=" << *(int*)((int *)(&d) + 6); cout << "\t地址: " << (int *)(&d) + 6; cout << endl; //[7] cout << "[7]值=" << *(int*)((int *)(&d) + 7); cout << "\t\t地址:" << (int *)(&d) + 7; cout << endl; //间接父类 //[8] cout << "[8]B::vptr"; cout << "\t地址:" << (int *)(&d) + 8 << endl; //输出B::vptr中的虚函数 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&d) + 8) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d) + 8) + i) << endl; } //[9] cout << "[9]B::id=" << *(int*)((int *)(&d) + 9); cout << "\t地址: " << (int *)(&d) +9; cout << endl; getchar(); }
补充
对象大小问题
#include <iostream> using namespace std; class Base { public: Base() {} virtual ~Base() {} void print() {} virtual void print_virtual() {} }; class Derived: public Base { public: Derived() {} virtual ~Derived() {} void print() {} virtual void print_virtual() {} }; class Derived_Virtual: virtual public Base { public: Derived_Virtual() {} virtual ~Derived_Virtual() {} void print() {} virtual void print_virtual() {} }; void test_size() { Base b; Derived d; Derived_Virtual dv; cout << "sizeof(b):\t" << sizeof(b) << endl; cout << "sizeof(d):\t" << sizeof(d) << endl; cout << "sizeof(dv):\t" << sizeof(dv) << endl; } int main() { test_size(); return 0; } /*output: 8 8 8 Linux Ubuntu 18.04 64 */
空类(无数据成员,无虚函数)
class Empty { public: Empty(void); ~Empty(void); }; //Empty p,sizeof(p)的大小是多少?事实上并不是空的,它有一个隐晦的1byte,
//那是被编译器安插进去的一个char。这将使得这个class的两个对象得以在内中有独一无二的地址。
数据成员如何访问(直接取址)
跟实际对象模型相关联,根据对象起始地址+偏移量取得。
静态绑定与动态绑定
程序调用函数时,将使用那个可执行代码块呢?编译器负责回答这个问题。将源代码中的函数调用解析为执行特定的函数代码块被称为函数名绑定(binding,又称联编)。在C语言中,这非常简单,因为每个函数名都对应一个不同的额函数。在C++中,由于函数重载的缘故,这项任务更复杂。编译器必须查看函数参数类型以及函数名才能确定使用哪个函数。然而编译器可以在编译过程中完成这种绑定,这称为静态绑定(static binding),又称为早期绑定(early binding)。
然而虚函数是这项工作变得更加困难。使用哪一个函数不是能在编译阶段时确定的,因为编译器不知道用户将选择哪种类型。所以,编译器必须能够在程序运行时选择正确的虚函数的代码,这被称为动态绑定(dynamic binding),又称为晚期绑定(late binding)。
使用虚函数是有代价的,在内存和执行速度方面是有一定成本的,包括:
- 每个对象都将增大,增大量为存储虚函数表指针的大小;
- 对于每个类,编译器都创建一个虚函数表;
- 对于每个函数调用,都需要执行一项额外的操作,即到虚函数表中查找地址。
虽然非虚函数比虚函数效率稍高,但不具备动态联编能力。
函数成员如何访问(间接取址)
跟实际对象模型相关联,普通函数(nonstatic、static)根据编译、链接的结果直接获取函数地址;如果是虚函数根据对象模型,取出虚函数表地址,然后在虚函数表中查找函数地址。
多态的实现
多态(Polymorphisn)在C++中是通过虚函数实现的。通过前面的模型知道,如果类中有虚函数,编译器就会自动生成一个虚函数表,对象中包含一个指向虚函数表的指针。能够实现多态的关键在于:虚函数是允许被派生类重写的,在虚函数表中,派生类函数会覆盖(override)基类函数。除此之外,还必须通过指针或引用调用方法才行,将派生类对象赋给基类对象。
void test_polmorphisn(){ Base b; Derived d; b = d; b.print(); //Base:print() b.print_virtual(); //Base::print_virtual() Base *p; p = &d; p->print(); //Base::print() p->print_virtual(); //Derived::print_virtual() }
根据模型推测只有 p->print_virtual() 才实现了动态,其他3种调用都是调用基类的方法。原因如下:
b.print();b.print_virtual(); 不能实现多态是因为通过基类对象调用,而非指针或引用所以不能实现多态。
p->print(); 不能实现多态是因为,print函数没有声明为虚函数(virtual),派生类中也定义了基类的print()函数,只是隐藏了。
为什么析构函数设为虚函数是必要的?
析构函数应当都是虚函数,除非明确该类不做基类(不被其他类继承)。基类的析构函数声明为虚函数,这样做是为了确保释放派生对象时,按照正确的顺序调用析构函数。
从前面介绍的C++对象模型可以知道,如果析构函数不定义为虚函数,那么派生类就不会重写基类的析构函数,在有多态行为的时候,派生类的析构函数不会被调用到(有内存泄漏的风险!)。
例如,通过new一个派生类对象,赋给基类指针,然后delete基类指针
void test_vitual_destructor(){ Base *p = new Derived(); delete p; } /*基类的析构函数不是函数: Base::Base() Derived::Derived() Base::~Base() 基类的析构函数是函数: Base::Base() Derived::Derived() Derived::~Derived() Base::~Base()*/
注意,前者缺少了派生类的析构函数调用。
后记
其中一位作者提供了测试代码下载:https://github.com/saylorzhu/CppObjectDataModelTestCode
还未在Linux 64平台上测试通过,待后续补充完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号