浮点数如何存储与表示(精度问题)
计算机中的数值表示
为特定数据选择其在计算机中的存储与表示方式时,主要考虑以下几个因素:
- 要表示的数的类型(小数、整数、实数或复数);
- 可能需要的数值范围;
- 数值的精确度要求;
- 数据存储和处理所需要的硬件代价;
定点数与浮点数
整数在计算机中一般使用整型处理,其在内存中的存储形式为二进制补码,有关整型数据的存储与表示详见机器码与位运算这篇文章。下面重点讲一讲实数中的另一块儿——小数。
小数是实数的一种特殊的表现形式,小数中的圆点叫做小数点,它是一个小数的整数部分和小数部分的分界号。其中整数部分是零的小数叫做纯小数,整数部分不是零的小数叫做带小数。
小数点在计算机中通常有两种表示方法,一种是约定所有数据的小数点隐含在某一个固定位置上,称为定点表示法,简称定点数;另一种是小数点的位置可以浮动,称为浮点表示法,简称浮点数。
定点数表示法(fixed-point number)
所谓定点格式,即约定机器中所有数据的小数点位置是固定不变的。在计算机中通常采用两种简单的约定:将小数点的位置固定在数据的最高位之前,或者是固定在最低位之后。一般常称前者为定点小数,后者为定点整数。
定点小数
定点小数是纯小数,约定的小数点位置在符号位之后、有效数值部分最高位之前。若数据x的形式为$x = x_0.x_1x_2...x_n$(其中$x_0$为符号位,$x_1~x_n$是数值的有效部分,也称为尾数,$x_1$为最高有效位),则在计算机中的表示形式为:
 一般说来,如果最末位$x_n = 1$,前面各位都为$0$,则数的绝对值最小,即$|x|_{min} = 2^{-n}$。如果各位均为$1$,则数的绝对值最大,即$|x|_{max} = 1-2^{-n}$。所以定点小数的表示范围是:$$2^{-n} \le |x| \le 1-2^{-n}$$
一般说来,如果最末位$x_n = 1$,前面各位都为$0$,则数的绝对值最小,即$|x|_{min} = 2^{-n}$。如果各位均为$1$,则数的绝对值最大,即$|x|_{max} = 1-2^{-n}$。所以定点小数的表示范围是:$$2^{-n} \le |x| \le 1-2^{-n}$$
定点整数
定点整数是纯整数,约定的小数点位置在有效数值部分最低位之后。若数据x的形式为$x = x_0x_1x_2...x_n.$(其中$x_0$为符号位,$x_1~x_n$为尾数,$x_n$为最低有效位 ),则在计算机中的表示形式为:

定点整数的表示范围是:$$1 \le |x| \le 2^n-1$$
溢出
当数据的绝对值小于定点数能表示的最小值时,计算机将它们作$0$处理,称为下溢;大于定点数能表示的最大值时,计算机将无法表示,称为上溢,上溢和下溢统称为溢出。
运算机制与缺陷
计算机采用定点数表示时,对于既有整数又有小数的原始数据,需要设定一个比例因子,数据按其缩小成定点小数或扩大成定点整数再参加运算,运算结果,根据比例因子,还原成实际数值。若比例因子选择不当,往往会使运算结果产生溢出或降低数据的有效精度。
用定点数进行运算处理的计算机被称为定点机。
浮点数表示法(floating-point number)
定点数表达法的缺点在于其形式过于僵硬,固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数。所以,绝大多数现代的计算机系统采纳了所谓的浮点数表示法。
原理
利用科学计数法来表达实数,即任意一个$J$进制数$N$,总可以写成$$N = J^E \times M$$
式中$M$称为数$N$的尾数(mantissa),是一个纯小数;$E$为数$N$的阶码(exponent),是一个整数,$J$称为比例因子$J^E$的底数。这种表示方法相当于数的小数点位置随比例因子的不同而在一定范围内可以自由浮动,所以称为浮点表示法。
比如$123.45$用十进制科学计数法可以表达为$1.2345 × 10^2$,其中$1.2345$为尾数,$10$为底数,$2$为指数。浮点数利用指数达到了浮动小数点的效果,从而可以灵活地表达更大范围的实数。提示: 尾数有时也称为有效数字(Significand),尾数实际上是有效数字的非正式说法。
底数是事先约定好的(常取2),在计算机中不出现。在机器中表示一个浮点数时,
一是要给出尾数,用定点小数形式表示。尾数部分给出有效数字的位数,因而决定了浮点数的表示精度。
二是要给出阶码,用整数形式表示,阶码指明小数点在数据中的位置,因而决定了浮点数的表示范围。
三是浮点数也有符号位。
因此一个机器浮点数应当由阶码、尾数及其符号位组成:

其中$E_S$表示阶码的符号,占一位,$E_1~E_n$为阶码值,占$n$位,尾符是数$N$的符号,也要占一位。当底数取$2$时,二进制数$N$的小数点每右移一位,阶码减小$1$,相应尾数右移一位;反之,小数点每左移一位,阶码加$1$,相应尾数左移一位。
规范浮点数
若不对浮点数的表示作出明确规定,同一个浮点数的表示就不是唯一的。例如比如上面例子中的$123.45$可以表达为$12.345 × 10^1$,$0.12345 × 10^3$或者 $1.2345 × 10^2$。因为这种多样性,有必要对其加以规范化以达到统一表达的目标。规范的(Normalized)浮点数表达方式具有如下形式:
$$d.dd...d \times \beta^{e}, (0 \le d_i \le \beta)$$
其中$d.dd...d$即尾数,$\beta$为底数,$e$为指数。尾数中数字的个数称为精度,在本文中用$p$(precision)来表示。每个数字$d$介于0和底数$\beta$之间,包括$0$,小数点左侧的数字不为$0$。
基于规范表达的浮点数对应的具体值可由下面的表达式计算而得:$$\pm(d_0 + d_ 1\beta^{-1} + ... + d_{p-1}\beta^{-(p-1)}\beta^e), (0 \le d_i < \beta)$$
二进制浮点数
对于十进制的浮点数,即底数$\beta$等于$10$的浮点数而言,上面的表达式非常容易理解,也很直白。而计算机内部的数值表达是基于二进制的,上面的表达式同样适用于二进制。
二进制的浮点数,其科学记数法的形式为:$$\pm X_nX_{n-1}...X_0.X_{-1}X_{-2}...X_{-m} = \pm X_{n}.X_{n-1}...X_0X_{-1}X_{-2}...X_{-m} \times 2^n$$
其中$X_i$只能是0或1。规范化表示为:$$\pm X_nX_{n-1}...X_0.X_{-1}X_{-2}...X_{-m} = \pm 1.X_{n-1}...X_0X_{-1}X_{-2}...X_{-m} \times 2^n$$
即约定小数点位于最高位的1之后,因此$X_n$不能是0。既然整数位只能是1,那么这一位可以不用存储,称之为隐含位,也就是说大家心里明白就行。
这样做的好处是可以多存储一位小数部分,但是在作浮点运算时需要特殊处理,运算之前要补齐这一位,运算之后又得略去这一位,会有一点点性能损耗;如果有效位本来就足够多,省去整数位也赚不了多少便宜,这可能是扩展双精度浮点数不采用这种方案的原因。
例如:二进制数$1001.101$相当于:$$1 \times 2^3 + 0 \times 2^2 + 0 \times 2^1 + 1 \times 2^0 + 1 \times 2^{-1} + 0 \times 2^{-2} + 1 \times 2^{-3}$$
对应于十进制的$9.6254$,其规范浮点数表达为$1.001101 \times 2^3$。
IEEE (美国电气和电子工程师学会)754标准
计算机中是用有限的连续字节保存浮点数的。
IEEE定义了多种浮点格式,但最常见的是三种类型:单精度、双精度和扩展双精度,分别适用于不同的计算要求。一般而言,单精度适合一般计算,双精度适合科学计算,扩展双精度适合高精度计算。一个遵循IEEE 754标准的系统必须支持单精度类型(强制类型),最好也支持双精度类型(推荐类型),至于扩展双精度类型可以随意。
IEEE 754 标准定义的单精度浮点数存储格式为32位,双精度浮点数存储格式为64位。此外,它还定义了两种扩展格式,即float-extended-exponent和double-extended-exponent扩展格式。后两种这里不做介绍,感兴趣的读者可自行查找资料学习。
浮点数的存储规范

在 IEEE 标准中,浮点数是将特定长度的连续字节的所有二进制位分割为特定宽度的符号域,指数域和尾数域三个域,其中保存的值分别用于表示给定二进制浮点数中的符号,指数和尾数。这样,通过尾数和可以调节的指数(所以称为“浮点“”)就可以表达给定的数值了。
下表列出C++中不同精度浮点数内存布局:
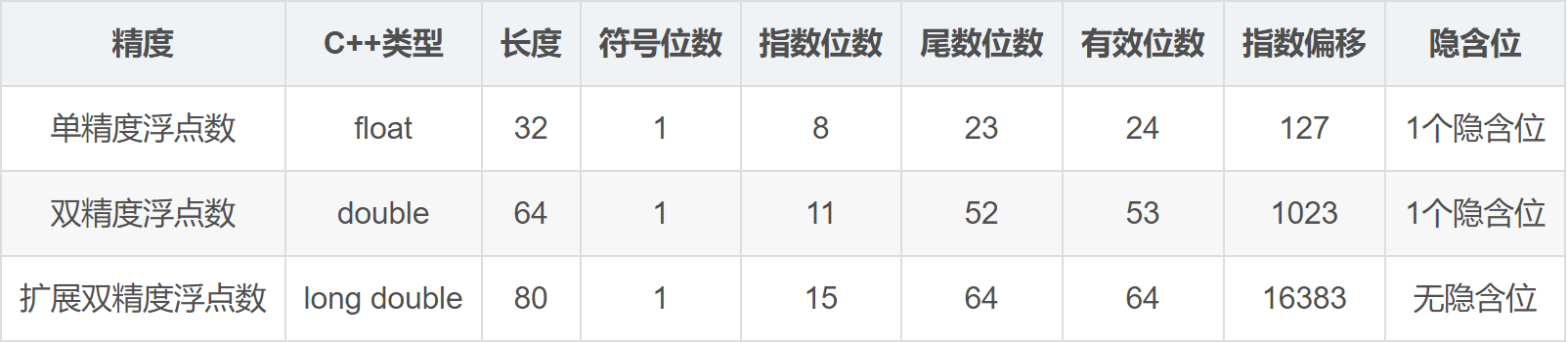
需要特别注意的是,扩展双精度类型没有隐含位,因此它的有效位数与尾数位数一致,而单精度类型和双精度类型均有一个隐含位,因此它的有效位数比尾数位数多一个。
表示方法
IEEE 754标准规定一个实数$V$可以用:$V = (-1)^S \times 2^{E - bias} \times (1.M)$ V=(-1)s×M×2^E的形式表示,以单精度浮点数为例,则有:
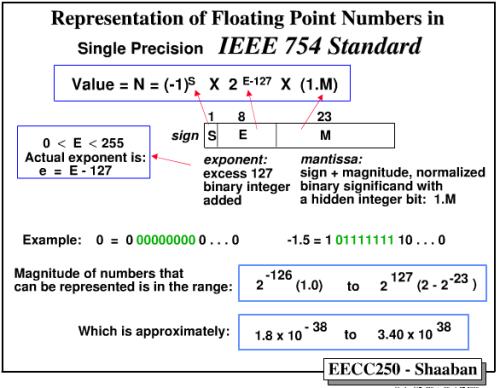
其中
S:符号位
0表示数值为正数,而1则表示负数,对数值$0$的符号位特殊处理。
E:指数域
对应于二进制科学计数法中的指数部分,通常使用移码表示(移码和补码只有符号位相反,其余都一样)。
其中单精度数为8位,双精度数为11位。以单精度数为例,8位的指数为可以表达0~255之间的256个指数值。
指数偏移
但是,指数可以为正数,也可以为负数。为了处理负指数的情况,实际的指数值加上了一个偏移(Bias)值作为保存在指数域中的值。单精度浮点数的bias为127(0-111 1111)(8位),而双精度bias为1023(0-11 1111 1111)(11位)。
实际存储值 = 真值 + 对应浮点数类型的偏移值
N位指数的编码和真值有下列关系:$$E = e + 2^{N-1} - 1$$
其中,$E$是指数实际存储值,$e$是真值,float类型的指数编码就是:$E = e + 127$,[1, 127)是负数,[127, 254]是正数,0和255有特殊用途。
边界指数值
<1> 实际指数值为-127(保存为全0),则有:-127原码1-111 1111 => 补码1-000 0001 => 加上单精度偏移值: 0-111 111(127) => 结果:0-000 0000(全0)。所以0-000 0000指数位表示:-127,即$e^{-127}$。
<2> 实际指数值为+128(保存为全1),则有:+128原码1-000 0000 => 补码1-000 0000 => 加上单精度偏移值:0-111 111(127) => 结果:1-111 1111(全1)。所以1-111 1111指数位表示:+128,即$e^{+128}$。
这些特殊的指数值,保留用作特殊浮点数的处理。(特殊浮点数将在下文重点介绍)
M:尾数域
M也称为有效数字,是二进制小数,取值范围为$0 \le M < 1$。
其中单精度浮点数为23位长,双精度为52位长。除了我们将要讲到的某些特殊浮点数外,IEEE 标准要求浮点数必须是规范的。这意味着尾数的小数点左侧必须为1,因此我们在保存尾数的时候,可以省略小数点前面这个1,从而腾出一个二进制位来保存更多的尾数。这样我们实际上用23位长的尾数域表达了24位的尾数。比如对于单精度数而言,二进制的$1001.101$(对应于十进制的$9.625$)可以表达为$1.001101 × 2^3$,所以实际保存在尾数域中的值为$001 1010 0000 0000 0000 0000$,即去掉小数点左侧的1,并用0在右侧补齐。
示例
以float为例:$$\pm 1.f \times 2^{E-127}$$

比如十进制数$123.125$,其二进制表示为:$1111011.001$,规格化表示为:$1.111011001 \times 2^6$也就是$1.111011001 \times 2^{133-127}$,$f=111011001$,$E=133$,二进制为$10000101$,图示如下

因为尾数域实际上可以精确表示24位尾数,所以这里可以得出一个结论:任意一个int值(二进制表示),只要存在这样的序列:从最低位开始找到第一个1,然后从这个1向高位数移动24位停下,如果更高的位上不再有1,那么该int值即可被float精确表示,否则就不行。简单说,就是第一个1开始到最后一个1为止的总位数超过24,那么该int值就不能被float类型精确表示,例:

图中能被丢弃的0,在尾数上体现出来,丢弃一个0,尾数的1就前移1位,并没有损失精度。
很容易得出,从1开始的连续整数里面第一个不能被float精确表示的整数,其二进制形式为:1 0000 0000 0000 0000 0000 0001,即16777217:$1.000000000000000000000001 \times 2^{24}$,$f$有24位,最后一个1只能舍弃,也就是$1.00000000000000000000000 \times 2^{24}$,即$1.0 \times 2^{24}$,这个数实际上是16777216。也就是说16777217和16777216的内存表示是一样的:

那么16777217之后的下一个可以被float精确表示的int值是多少呢?很简单,向16777217上不断的加1,直到满足“第一个1开始到最后一个1为止的总位数为24位”:

$1 0000 0000 0000 0000 0000 0010$就是16777218,规范化表示为:$1.00000000000000000000001 \times 2^{24} = 1.00000000000000000000001 \times 2^{151-127}$,其$f$是23位(最后一位是1)。
特殊浮点数
IEEE标准定义了6类浮点数:
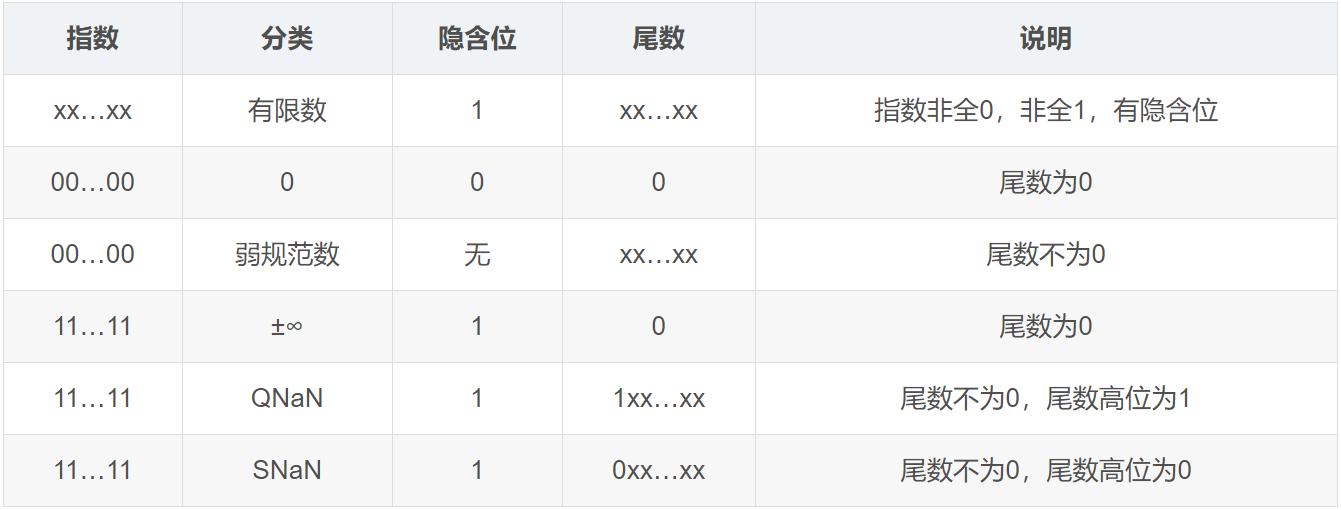
有限数就是遵循规范的常规浮点数,其指数在最小值(-127)和最大值(+128)之间(两边均不包含),且整数位恒为1,其形式为:$$\pm1.f \times 2^{e-bias}$$
例如float,其指数E有8位,取值范围为(0, 255)也就是[1, 254]。有限数在运算过程中最常见的问题就是溢出,即运算结果无法用有限数表示。
以下约定$e_{min} = -126$,$e_{max} = +127$。
有符号的零
$$\pm(0.0) \times 2^{0-bias}$$
因为IEEE标准的浮点数格式中,小数点左侧的$1$是隐藏的,而零显然需要尾数必须全是零。所以,零也就无法直接用这种格式表达而只能特殊处理。实际上,零保存为尾数域为全为$0$,指数域为$e_{min} - 1 = -127$,也就是说指数域也全为$0$。考虑到符号域的作用,所以存在着两个零,即$+0$和$-0$。不同于正负无穷之间是有序的,IEEE 标准规定正负零是相等的。
零为什么要分正负?
零有正负之分,的确非常容易让人困惑。这一点是基于数值分析的多种考虑,经利弊权衡后形成的结果。
有符号的零可以避免运算中,特别是涉及无穷的运算中,符号信息的丢失。
举例而言,如果零无符号,则等式$1/(1/x) = x$当$x = \pm \infty$时不再成立。原因是如果零无符号,$1$和正负无穷的比值为同一个零,然后$1$与$0$的比值为正无穷,符号没有了。解决这个问题,除非无穷也没有符号。但是无穷的符号表达了上溢发生在数轴的哪一侧,这个信息显然是不能不要的。
为什么正负零相等?
零有符号也造成了其它问题,比如当$x = y$时,等式$1/x = 1/y$在$x$和$y$分别为$+0$和$-0$时,两端分别为正无穷和负无穷而不再成立。当然,解决这个问题的另一个思路是和无穷一样,规定零也是有序的。但是,如果零是有序的,则即使 if (x == 0) 这样简单的判断也由于$x$可能是$±0$而变得不确定了。两害取其轻者,零还是无序的好(正0应该和负0相等,而不应正0大于负0)。
弱规范数
我们来考察浮点数的一个特殊情况。
选择两个绝对值极小的浮点数,以单精度的二进制浮点数为例,比如$1.001 \times 2^{-125}$和$1.0001 \times 2^{-125}$这两个数(分别对应于十进制的$2.6448623 \times 10^{-38}$和$2.4979255 \times 10^{-38}$)。显然,他们都是普通的浮点数(指数为-125,大于允许的最小值-126,尾数更没问题),按照 IEEE 754可以分别保存为$0000 0001 0001 0000 0000 0000 0000 0000(0x1100000)$和$0000 0001 0000 1000 0000 0000 0000 0000(0x1080000)$。
现在我们看看这两个浮点数的差值。不难得出,该差值为$0.0001 \times 2^{-125}$,表达为规范浮点数则为$1.0 \times 2^{-129}$。问题在于其指数大于允许的最小指数值,所以无法保存为规范浮点数。最终,只能近似为零(Flush to Zero)。这中特殊情况意味着下面本来十分可靠的代码也可能出现问题:
if (x != y) { z = 1 / (x -y); }
正如我们精心选择的两个浮点数展现的问题一样,即使x不等于y,x和y的差值仍然可能绝对值过小,而近似为零,导致除以0的情况发生。
为了解决此类问题,IEEE标准中引入了非规范(Denormalized)浮点数。规定当浮点数的指数为允许的最小指数值($e_{min}$ )时,尾数不必是规范化的。比如上面例子中的差值可以表达为非规范的浮点数$0.001 \times 2^{-126}$,其中指数-126等于$e_{min}$。注意,这里规定的是“不必”,这也就意味着“可以”。
指数域特殊处理(无隐含位)
当浮点数实际的指数为$e_{min}$,且指数域也为$e_{min}$时,该浮点数仍是规范的,也就是说,保存时隐含着一个隐藏的尾数位。为了保存非规范浮点数,IEEE标准采用了类似处理特殊值零时所采用的办法,即用特殊的指数域值$e_{min} - 1$加以标记,当然,此时的尾数域不能为零。这样,例子中的差值可以保存为$0000 0000 0001 0000 0000 0000 0000 0000(0x100000),没有隐含的尾数位。
弱规范数的指数域和零一样,都是全0,但没有隐含位,尾数部分不为0,其形式为:$$\pm(f) \times 2^{0-bias}$$
去掉了隐含的尾数位的制约,可以保存绝对值更小的浮点数。也由此,上述关于极小差值的问题也不存在了,因为所有可以保存的浮点数之间的差值同样可以保存了。
弱规范数 <=> 有限数
弱规范数的整数位是尾数的最高位(没有隐含位),在向有限数转换时,要向高位移一位,以产生隐含位,但指数不变(不减1);从有限数形式转换成弱规范数形式时,正好相反,向低位移1位,指数仍不变。
弱规范数的意义
在计算过程中,如果中间结果小于最小的有限数却不是0,即出现下溢,如果当做0处理,可能会导致计算终止,引入“弱规范数”之后,在0和最小的有限数之间有相当一部分数可以表示为“弱规范数”,从而提高了计算能力。
无穷
特殊值无穷(Infinity)$\infty$的指数部分为全1(即最大值),整数位是1(即隐含位),尾数是0,其形式为:$$\pm(1.0) \times 2^{MAX-bias}$$
float类型即:$\pm(1.0) \times 2^{255-bias}$,产生$\infty$的情形一般有:
- 自身运算,例如$\infty + 1.0 = \infty$
- 被0除,例如$1/+0 = +\infty, 1/-0 = -\infty$
- 上溢,及计算结果超出了类型范围
无穷用于表达计算中产生的上溢(Overflow)问题。
比如两个极大的数相乘时,尽管两个操作数本身可以保存为浮点数,但其结果可能大到无法保存为浮点数,而必须进行舍入。根据 IEEE 标准,此时不是将结果舍入为可以保存的最大的浮点数(因为这个数可能离实际的结果相差太远而毫无意义),而是将其舍入为无穷。对于负数结果也是如此,只不过此时舍入为负无穷,也就是说符号域为1的无穷。特殊值无穷使得计算中发生的上溢错误不必以终止运算为结果。
无穷和除NaN及零以外的其它浮点数一样是有序的,从小到大依次为:负无穷 => 负的有穷非零值 => 正负零 => 正的有穷非零值 => 正无穷。
除NaN以外的任何非零值除以零,结果都将是无穷,而符号则由作为除数的零的符号决定。
NaN(Not a Number)
NaN,即Not a Number,和$\infty$一样,指数部分为全1(即最大值),整数位是1(即隐含位),但尾数部分不为0,其形式为:$$\pm(1.f) \times 2^{MAX-bias}$$其中,$f$不为0。
NaN用于处理计算中出现的错误情况,比如0.0除以0.0或者求负数的平方根。
NaN有SNaN(Signal NaN)和QNaN(Quiet NaN)之分,IEEE标准要求:SNaN参与运算要触发异常,而QNaN则不触发异常。两者的区别在于,SNaN的尾数最高位是0,而QNaN的尾数最高位是1。
IEEE标准只规定NaN的尾数不为0,没有要求具体的尾数域,所以NaN实际上不是一个,而是一族。这就给予了具体实现一定的空间:不同的实现可以自由选择尾数域的值来表达NaN,当计算出现问题时,在尾数部分设置的这些特殊值将有利于调试。
实际上,所有的NaN值都是无序的。NaN有一些晦涩的运算规则:
- $0 \times \infty$ = NaN,因此“0乘任何数都是0”不是恒成立的。
- 逻辑运算:关系运算符 <, <=, >, >= 和 == 在任一操作数为NaN时均返回false。即使是两个具有相同位模式的NaN,== 也返回false。而操作符 != 则当任一操作数为NaN时返回true(这个规则的一个有趣结果是 x != x 当x为NaN时竟然为真!)。因此在浮点数的逻辑运算中,编译器没有办法做积极的优化,因为如果有NaN参与逻辑运算,比如x = NaN,那么 !(x < y) 和 x >= y 就不等价了。
- 零除以零,结果不是无穷而是NaN。原因:当除数和被除数都逼近于零时,其商可能为任何值,所以IEEE标准决定此时用NaN作为商比较合适。
- 此外,任何有NaN作为操作数的操作也将产生NaN。
用特殊的NaN来表达上述运算错误的意义在于避免了因这些错误而导致运算的不必要终止。例如,如果一个被循环调用的浮点运算方法,可能由于输入的参数问题而导致发生这些错误,NaN使得即使某次循环发生了这样的错误,也可以简单地继续执行循环以进行那些没有错误的运算。你可能想到,既然Java有异常处理机制,也许可以通过捕获并忽略异常达到相同的效果。但是,要知道,IEEE标准不是仅仅为Java而制定的,各种语言处理异常的机制不尽相同,这将使得代码的迁移变得更加困难。何况,不是所有语言都有类似的异常或者信号(Signal)处理机制。
【编译器不一定遵循IEEE标准的规定,可想而知,浮点运算有多难搞。】
范围和精度
表示范围:浮点数 > 定点数
浮点数所表示的范围比定点数大。假设机器中的数由8位二进制数表示(包括符号位):在定点机中这8位全部用来表示有效数字(包括符号);在浮点机中若阶符、阶码占3位,尾符、尾数占5位,在此情况下,若只考虑正数值,定点机小数表示的数的范围是0.0000000到0.1111111,相当于十进制数的$0$到$\frac{127}{128}$,而浮点机所能表示的数的范围则是$2^{-11} \times 0.0001$到$2^{11} \times 0.1111$,相当于十进制数的$\frac{1}{128}$到$7.5$ 。显然,都用8位,浮点机能表示的数的范围比定点机大得多。
尽管浮点表示能扩大数据的表示范围,但浮点机在运算过程中,仍会出现溢出(Flow)现象。一般称大于最大绝对值的数据为上溢(Overflow),小于最小绝对值的数据为下溢(Underflow)。
下面以阶码占3位,尾数占5位(各包括1位符号位)为例,来讨论这个问题。下图给出了相应的规范化浮点数的数值表示范围。

“可表示的负数区域”和“可表示的正数区域”及“0”,是机器可表示的数据区域;上溢区是数据绝对值太大,机器无法表示的区域;下溢区是数据绝对值太小,机器无法表示的区域。若运算结果落在上溢区,就产生了溢出错误,使得结果不能被正确表示,要停止机器运行,进行溢出处理。若运算结果落在下溢区,也不能正确表示之,机器当0处理,称为机器零。
一般来说,增加尾数的位数,将增加可表示区域数据点的密度,从而提高了数据的精度;增加阶码的位数,能增大可表示的数据区域。
最大最小值
最小的正float有限数
根据有限数的规范化形式,指数取最小值1,隐含位是1,尾数取最小值0(23位都是0):
$$1.0 \times 2^{1-127} = 1.0 \times 2^{-126} = 1.1754943508222875079687365372222e^{-38}$$
如果浮点运算的结果小于这个数,就出现下溢,一般将其结果转换为最小的有限数,或者弱规范数,如果弱规范数也不能表示,那么将转换成0。
最大的float有限数
根据有限数的规格化形式,指数取最大值254,隐含位是1,尾数取最大值(23位都是1):
$$1.11111111111111111111111111 \times 2^{254-127} = (2-2^{-23}) \times 2^{127}$$
$$= 2^{128} - 2^{104} = 3.4028234663852885981170418348452e^{38}$$
如果浮点运算的结果超过这个数,就出现上溢,一般将其结果转换为最近的有限数或$\infty$。
最小的正float弱规范数
根据弱规范数的规格化形式,尾数取最小值:
$$0.0000000000000000000001 \times 2^{0-127} = 2^{-22} \times 2^{-127}$$
$$= 2^{-149} = 1.4012984643248170709237295832899e^{-45}$$
$f$ 是23位,且最高位是整数位,因此小数点之后只有22位,最后一位为1,即可得出该数。
FLT_EPSILON
FLT_EPSILON是C++定义的一个float数,该数是满足$1.0 + FLT_EPSILON ! = 1.0$的最小的float有限数,比该数还小的float有限数会有:$1.0 + x = 1.0$。根据这个定义,从比1.0大的最小float有限数开始推导:
$$1.00000000000000000000001 \times 2^{127-127} = 1.00000000000000000000001$$
$$= > FLT\_EPSILON = 0.00000000000000000000001 = 2^{-23}$$
$$= 0.00000011920928955078125 \approx 1.192092896e^{-7}$$
它的规范化表示:$1.0 \times 2^{104-127}$,$E = 104$,$f = 0$ 。注意,该数远不是最小的正float有限数,它比最小的正float有限数还要“大很多”,它的指数是-23,而最小的正float有限数的指数是-126。
这个数并没有什么特别的意义,在代码中无条件的使用$fabs(x-y)$ < FLT_EPSILON判断两个浮点数是否相等,可能会导致问题。如果你的系统中浮点数很小,极端来说,甚至小于FLT_EPSILON判断两个浮点数是否相等,可能会导致问题。如果你的系统中浮点数很小,极端来说,甚至小于FLT_EPSILON,那你用$fabs(x-y)$ < FLT_EPSILON来判断相等,显然是错误的,你应该自己定义一个可以接受的误差范围来辅助判断相等问题。
精度与误差
很多小数根本无法在二进制计算机中精确表示(比如最简单的0.1)。
因为浮点数尾数域的位数是有限的,为此,浮点数的处理办法是持续该过程直到由此得到的尾数足以填满尾数域,之后对多余的位进行舍入。
换句话说,除了我们之前讲到的精度问题之外,十进制到二进制的变换也并不能保证总是精确的,而只能是近似值。事实上,只有很少一部分十进制小数具有精确的二进制浮点数表达。再加上浮点数运算过程中的误差累积,结果是很多我们看来非常简单的十进制运算在计算机上却往往出人意料。这就是最常见的浮点运算的“不准确”问题。
存储格式的范围和精度如下表所示:

舍入
值得注意的是,对于单精度数,由于我们只有24位的尾数(其中一位隐藏),所以可以表达的最大指数为$2^{24} - 1 = 16777215$。
特别的,16777216是偶数,所以我们可以通过将它除以2并相应地调整指数来保存这个数,这样16777216同样可以被精确保存。相反的,数值16777217则无法被精确保存。由此,我们可以看到单精度浮点数可以表达的十进制数值中,真正有效的数字不高于8位。
事实上,对相对误差的数值分析结果显示有效的精度大约为7.22位。
实例如下所示:
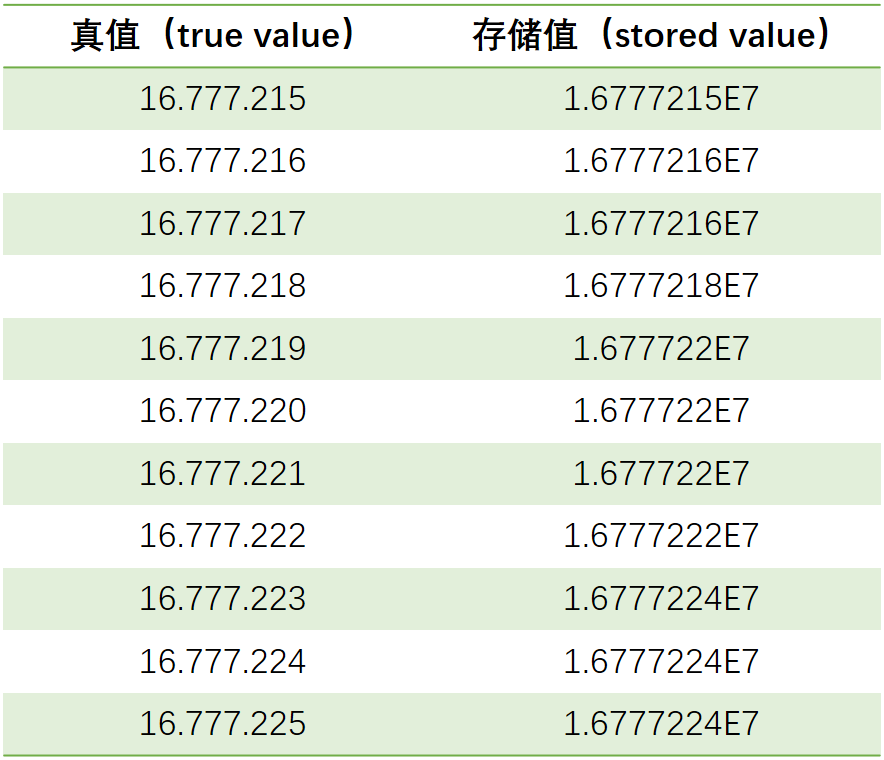
根据标准要求,无法精确保存的值必须向最接近的可保存的值进行舍入。这有点像我们熟悉的十进制的四舍五入,即不足一半则舍,一半以上(包括一半)则进。
不过,对于二进制浮点数而言,还多一条规矩,就是当需要舍入的值刚好是一半时,不是简单地进,而是在前后两个等距接近的可保存的值中,取其中最后一位有效数字为零者。从上面的示例中可以看出,奇数都被舍入为偶数,且有舍有进。我们可以将这种舍入误差理解为“半位”的误差。所以,为了避免7.22对很多人造成的困惑,有些文章经常以7.5位来说明单精度浮点数的精度问题。
注意:这里采用的浮点数舍入规则有时被称为舍入到偶数(Round to Even)。相比简单地逢一半则进的舍入规则,舍入到偶数有助于从某些角度减小计算中产生的舍入误差累积问题,因此为 IEEE 标准所采用。
结语
浮点运算,深奥、晦涩、难懂!我们对浮点运算的所有想当然的假设可能都是不靠谱的。正如Herb Sutter所说,世界上的人可以分3种:
● 一种是知道自己不懂浮点运算(我就是);
● 一种是以为自己懂浮点运算;
● 最后一种是极少的专家级人物,他们想知道自己是否有可能最终完全理解浮点运算。
(整理自网络)
参考资料:
https://blog.csdn.net/qq_36396104/article/details/80045050
https://blog.csdn.net/whyel/article/details/81067989

 浙公网安备 33010602011771号
浙公网安备 33010602011771号