深度学习之数据预处理
预处理与权重初始化之间的关系
如果做过DNN的实验,大家可能会发现在对数据进行预处理,例如白化或者z-score,甚至是简单的减均值操作都是可以加速收敛的,例如下图所示的一个简单的例子:
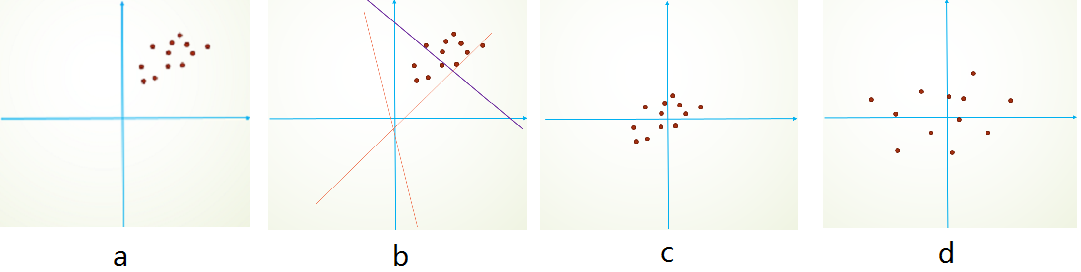
图中红点均代表二维的数据点,由于图像数据的每一维一般都是$0~255$之间的数字,因此数据点只会落在第一象限,而且图像数据具有很强的相关性,比如第一个灰度值为$30$,比较黑,那它旁边的一个像素值一般不会超过$100$,否则给人的感觉就像噪声一样。由于强相关性,数据点仅会落在第一象限的很小的区域中,形成类似上图a所示的狭长分布。
而神经网络模型在初始化的时候,权重$W$是随机采样生成的,一个常见的神经元表示为:$ReLU(Wx + b) = \max(Wx + b,0)$,即在$Wx + b = 0$的两侧,对数据采用不同的操作方法。具体到ReLU就是一侧收缩,一侧保持不变。随机的$Wx + b = 0$表现为图b中的随机虚线,由于初始化参数一般都是$0$均值的,因此开始的拟合$y =Wx + b$,基本过原点附近,如图b中的红色虚线。注意到,这两条红色虚线实际上并没有什么意义(没有分割到数据点)。在使用梯度下降时,可能需要很多次迭代才会使这些虚线对数据点进行有效的分割(如紫色虚线),即网络需要经过多次学习才能逐步达到如紫色实线的拟合=》收敛比较慢。
更何况,我们这只是个二维的演示,数据占据四个象限中的一个,如果是几百、几千、上万维呢?而且数据在第一象限中也只是占了很小的一部分区域而已,可想而知不对数据进行预处理带来了多少运算资源的浪费,而且大量的数据外分割面在迭代时很可能会在刚进入数据中时就遇到了一个局部最优,导致overfit的问题。
这时,如果我们对输入数据先作减均值操作,数据点就不再只分布在第一象限了,如图c,这时一个随机分界面落入数据分布的概率增加了多少呢?$2^n$倍!更进一步的,我们对数据再使用去除相关性的算法,例如PCA和ZCA白化,数据不再是一个狭长的分布而更加容易区分,这样又会加快训练,如图d。随机分界面有效的概率就又大大增加了。
不过计算协方差矩阵的特征值太耗时也太耗空间,我们一般最多只用到z-score处理,即每一维度减去自身均值,再除以自身标准差,这样能使数据点在每维上具有相似的宽度,可以起到一定的增大数据分布范围,进而使更多随机分界面有意义的作用。
常见的预处理方法
预处理为什么要归一化
前面讲了数据预处理对于模型训练的重要性,那么回归到输入数据的整体分布来看,在训练开始前,都要对输入数据做一个归一化处理,本质原因还是在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们对输入数据都需要做一个归一化预处理的原因。
归一化、标准化与中心化
归一化、标准化可以说是数据处理中最常被提及的词汇之二了,关于二者的定义比较相似,也容易混淆。查阅了网上的各种资料,发现其实所谓“归一化”和“标准化”在不同人的不同文章中,可能有着不一样的定义。那么撇开指代模糊的名字,从最明确公式定义来看,“归一化”和“标准化”通常指的是这四种特征缩放(Feature Scaling):
- Rescaling (min-max normalization) 有时简称normalization(有点坑):$$x' = \frac{x - min(x)}{max(x) - min(m)}$$
- Mean normalization:$$x' = \frac{x - mean(x)}{max(x) - min(x)}$$
- Standardization(Z-score normalization):$$x' = \frac{x - mean(x)}{\sigma}$$
- Scaling to unit length:$$x' = \frac{x}{||x||}$$
一般把第一种叫做归一化,第三种叫做标准化。而正则化的英文应该是Regularization,有时也被弄混,正则化是完全不同的事情了。而关于在机器学习中是用第一个好还是第三个好,可参考这篇文章:标准化和归一化,请勿混为一谈,透彻理解数据变换,里面有详细的归一化与标准化的区别与联系的讨论,以及使用决策,讲得很好。
中心化比较简单,就是将均值变为0($x' = x - mean(x)$),对方差没要求。
z-score
z-score即上述第三种的“标准化”,将每一个维度的特征都处理为符合标准正态分布$N(0, 1)$,核心公式为$$\begin{align}\mu &= \frac{1}{N}\sum_{i = 1}^{N} x^{(i)} \\ \sigma^2 &= \frac{1}{N}\sum_{i = 1}{N}(x^{(i)} - \mu)^2 \\ \widetilde x^{(i)} &= \frac{x^{(i)} - \mu}{\sigma}\end{align}$$
每一维特征都服从标准正态分布。经过处理后的数据符合均值为0,标准差为1的分布,如果原始的分布是正态分布,那么z-score标准化就将原始的正态分布转换为标准正态分布,机器学习中的很多问题都是基于正态分布的假设,这是更加常用的归一化方法。
以上都是线性变换,对输入向量$X$按比例压缩再进行平移,操作之后原始有量纲的变量变成无量纲的变量。不过它们不会改变分布本身的形状,下面以一个指数分布为例:
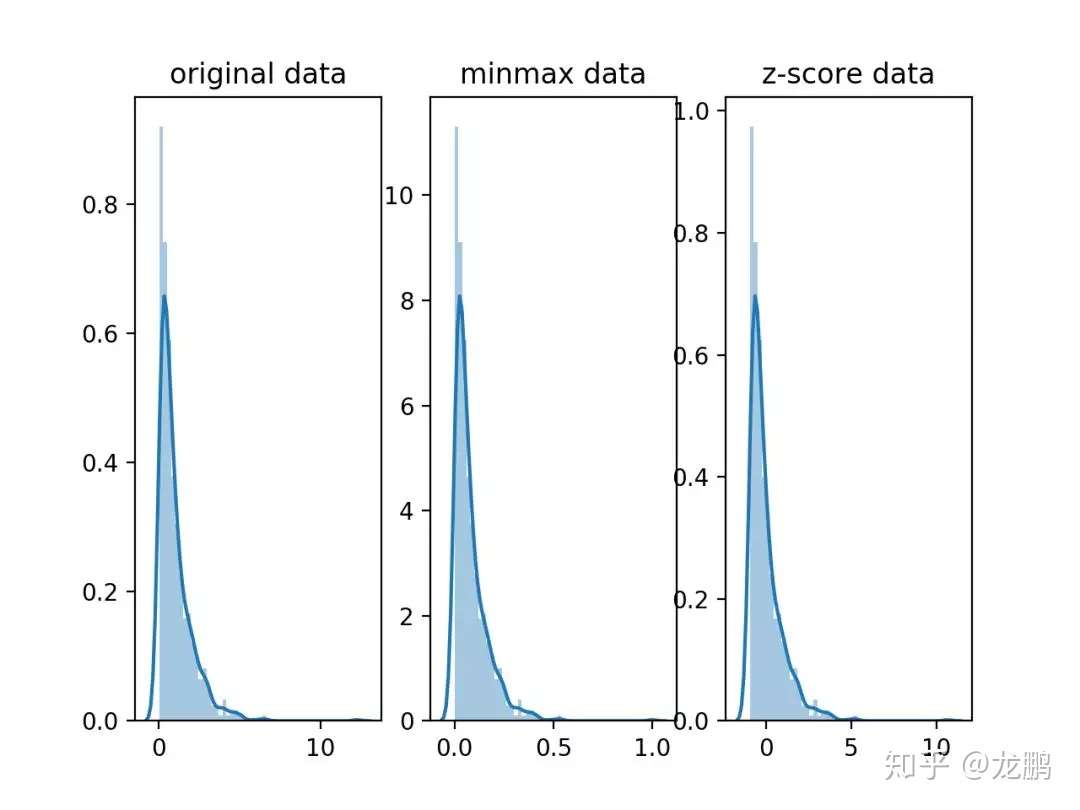
如果要改变分布本身的形状,下面也介绍两种。
正态分布Box-Cox变换
Box-Cox变换可以将一个非正态分布转换为正态分布,使得分布具有对称性,变换公式如下:$$Y^{(\lambda)} = \begin{cases} \frac{Y^{\lambda} - 1}{\lambda},\quad\text{$\lambda \neq 0$} \\ \ln \lambda,\quad \text{$\lambda = 0$} \end{cases}$$
在这里$\lambda$是一个基于数据求取的待定变换参数,Box-Cox的效果如下: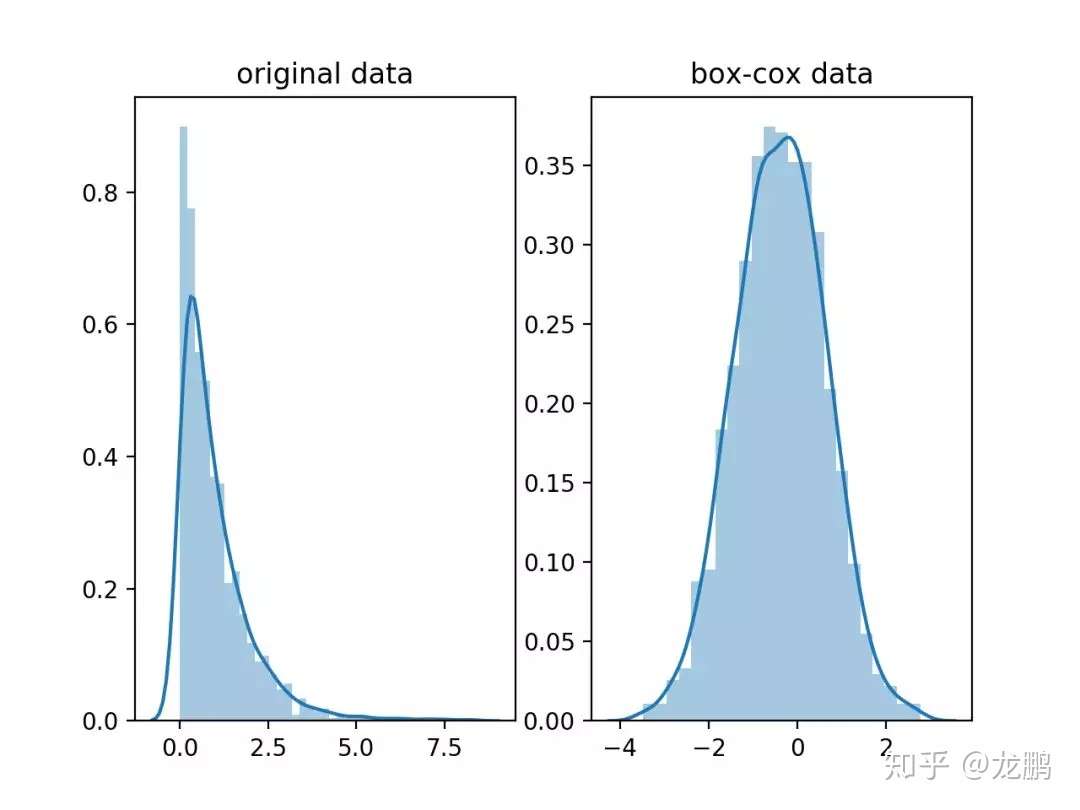
直方图均衡化
直方图均衡也可以将某一个分布归一化到另一个分布,它通过图像的灰度值分布,即图像直方图来对图像进行对比度进调整,可以增强局部的对比度。
它的变换步骤如下:
(1)计算概率密度和累积概率密度。
(2)创建累积概率到灰度分布范围的单调线性映射T。
(3)根据T进行原始灰度值到新灰度值的映射。
直方图均衡化将任意的灰度范围映射到全局灰度范围之间,对于$8$位的图像就是$(0, 255)$,它相对于直接线性拉伸,让分布更加均匀,对于增强相近灰度的对比度很有效,如下图。
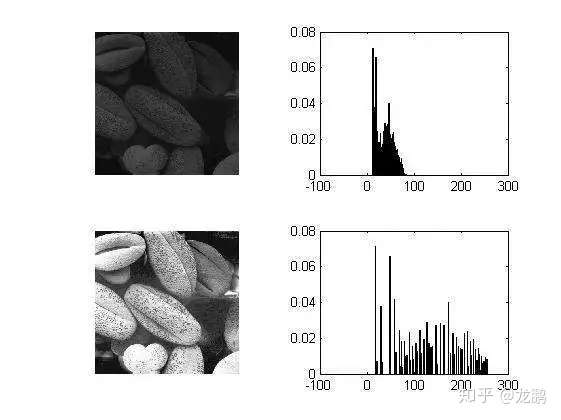
综上,归一化数据的目标,是为了让数据的分布变得更加符合期望,增强数据的表达能力。
在深度学习中,因为网络的层数非常多,如果数据分布在某一层开始有明显的偏移,随着网络的加深这一问题会加剧(这在BN的文章中被称之为internal covariate shift),进而导致模型优化的难度增加,甚至不能优化。所以,归一化就是要减缓这个问题。
白化(Whitening)
白化是一种重要的数据预处理方式,用来降低输入数据特征之间的冗余性。输入数据经过白化处理后,特征之间相关性低,并且所有特征具有相同的方差。
白化具有两个目的:1. 使数据的不同维度去相关;2. 数据每个维度的方差为1。
假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性。
PCA白化
PCA即主成分分析(Principal Component Analysis),其思想是将$N$维特征映射到$K$维上(通常$K < N$),这$K$维是全新的正交特征。这$K$维特征称为主成分,是重新构造出来的$K$维特征,而不是简单地从$N$维特征中直接挑选出的$K$维特征。
这里先简单讲一下PCA的主要操作:
(1)求出训练样本$X$的协方差矩阵$\varSigma$,公式如下($m个$输入数据$X$已经均值化过):$$\varSigma = \frac{1}{m}\sum_{i = 1}^{m}(x^{(i)})(x^{(i)})^T$$
(2)将$\varSigma$进行SVD分解,取前$K$大特征值对应的的特征向量作为列向量,组成特征向量矩阵$U$;
(3)将$X$投影到$U$上即得$Z$:$$z = U^Tx = \left[ \begin{array}{c} u_1^Tx \\ u_2^Tx \end{array} \right]$$
如此,样本$x$经过PCA后被映射成了$z$。
那么,PCA白化的两个主要步骤:
1. 通过PCA将数据$X$映射得到$Z$,可以看出$Z$中每一维都是相互独立的(去相关);
(如果$K < N$,就是PCA降维,如果$K = N$,则只是降低特征间得相关性。这里的$K$是指PCA处理过后的特征数。)
2. 再除以$Z$中每一维对应的方差,使得每一维的方差均为1。
ZCA白化
$$X_{ZCA_{white}} = UX_{PCA_{white}}$$
只是在PCA白化的基础上做了一个旋转操作,使得白化之后的数据更加接近原始数据。
ZCA白化首先通过PCA去除了各个特征相关性(没降维,$K = N$),然后使输入特征方差为1,此时得到PCA白化后的结果。之后再将数据旋转回去,得到ZCA白化结果。
升级版的“预处理”——BN
对输入数据进行预处理,减均值->z-score->白化可以逐级提升随机初始化的权重对数据分割的有效性,还可以降低overfit的可能性。我们都知道,现在的神经网络的层数都是很深的,如果我们对每一层的数据都进行处理,训练时间和overfit程度是否可以降低呢?答案是可以,用Batch Normalization。
参考资料:
https://blog.csdn.net/hjimce/article/details/50866313
https://www.zhihu.com/question/20467170
https://blog.csdn.net/weixin_36604953/article/details/102652160
https://www.zhihu.com/question/38102762/answer/607815171

 浙公网安备 33010602011771号
浙公网安备 33010602011771号