

Hadoop学习---Hadoop基础
一、Hadoop背景介绍
- 什么是Hadoop
1. HADOOP是apache旗下的一套开源软件平台
2. HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3. HADOOP的核心组件有:
A. HDFS(分布式文件系统)
B. YARN(运算资源调度系统)
C. MAPREDUCE(分布式运算编程框架)
4. 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
- Hadoop产生背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的
可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
---分布式文件系统(GFS),可用于处理海量网页的存储
---分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3. Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
- Hadoop与云计算大数据之间的关系
1. 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、
SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2. 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3. 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
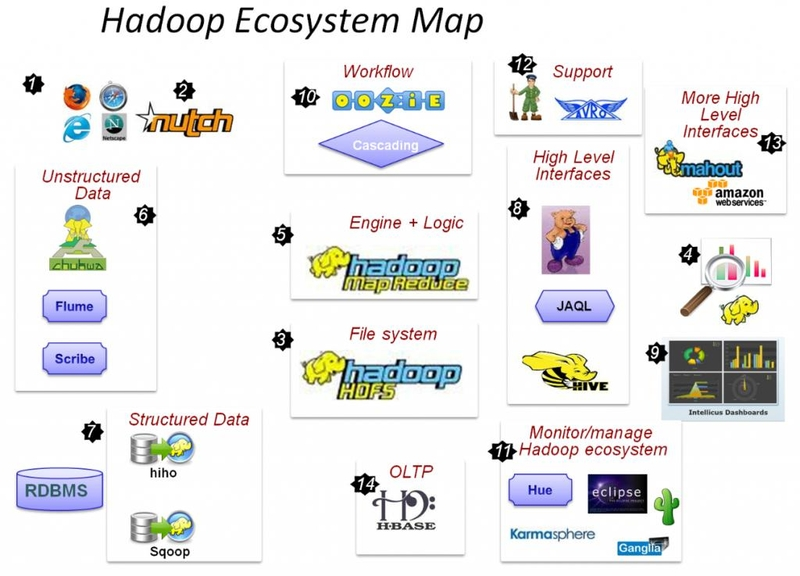
2、Hadoop生态圈组件
Hadoop由HDFS,Mapreduce,yarn三部分组成,这三个模块只提供了基础的服务,除此之外,大数据生态圈其他的
软件提供了一些补充功能,帮助我们更便捷的进行大数据相关任务的处理。
关键组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
3、Hadoop的应用场景
1、HADOOP应用于数据服务基础平台建设
2、HADOOP用于用户画像
3、HADOOP用于网站点击流日志数据挖掘
4、其他海量数据分析处理的工具
