计算机系统结构复习笔记(五)
第五章 存储系统
5.1 存储系统的层次结构
5.1.1 存储系统的层次结构
人们对计算机系统结构指标的要求:容量大、速度快、价格低
三个要求相互矛盾:
速度越快,每位价格就越高;
容量越大,每位价格就越低;
容量越大,速度越慢。
追求“容量大,价格低”需要采用大容量存储技术;
追求高性能访存速度需要采用价格昂贵的快速存储器;
程序访问的局部性原理:
对于绝大多数程序,它们所访问的指令和数据在地址上不是均匀分布的,而是相对簇聚的。
程序访问的局部性包含两个方面:
时间局部性:程序马上将要用到的信息很可能就是现在正在使用的信息。(如循环逻辑)
空间局部性:程序马上将要用到的信息很可能与现在正在使用的信息在存储空间上是相邻的。(如顺序存放、顺序访问)
解决方法:采用多种存储器技术,构成多级存储层次结构:

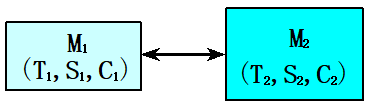
整个存储系统要达到的目标:从CPU来看,该存储系统的速度接近于\(M_1\)的,而容量和每位价格都接近于\(M_n\)的。
为了达到这一目标就要做到存储器越靠近CPU,则CPU对它的访问频度越高,而且最好大多数的访问都能在\(M_1\)完成。
5.1.2 存储层次的性能参数
下面仅考虑由\(M_1\)和\(M_2\)构成的两级存储层次:
\(M_1\)的参数:\(S_1\),\(T_1\),\(C_1\)
\(M_2\)的参数:\(S_2\),\(T_2\),\(C_2\)
1.存储容量\(S\)
一般来说,整个存储系统的容量即是第二级存储器\(M_2\)的容量,即\(S=S_2\)。
2.每位价格\(C\)
\(C= \frac{C_1S_1+C_2S_2}{S_1+S_2}\)
当\(S_1<<S_2\)时,\(C \approx C_2\)
3.命中率\(H\)和不命中率\(F\)
命中率:CPU访问存储系统时,在\(M_1\)中找到所需信息的概率。
\(H=\frac{N_1}{N_1+N_2}\)
\(N_1\) ── 访问\(M_1\)的次数
\(N_2\) ── 访问\(M_2\)的次数
不命中率(失效率) :\(F=1-H\)
4.平均访问时间\(T_A\)
分两种情况来考虑CPU的一次访存:
当命中时,访问时间即为\(T_1\)(命中时间)
当不命中时,情况比较复杂。
不命中时的访问时间为:
\(T_1+T_2+T_B=T_1+T_M\)
\(T_M=T_2+T_B\)
不命中开销\(T_M\):从向\(M_2\)发出访问请求到把整个数据块调入\(M_1\)中所需的时间。
传送一个信息块所需的时间为\(T_B\)。
所以\(T_A= HT_1+(1-H)(T_1+T_M)\)
\(~~~~~~~~~~~= T_1+(1-H)T_M\)
或 \(T_A = T_1+FT_M\)
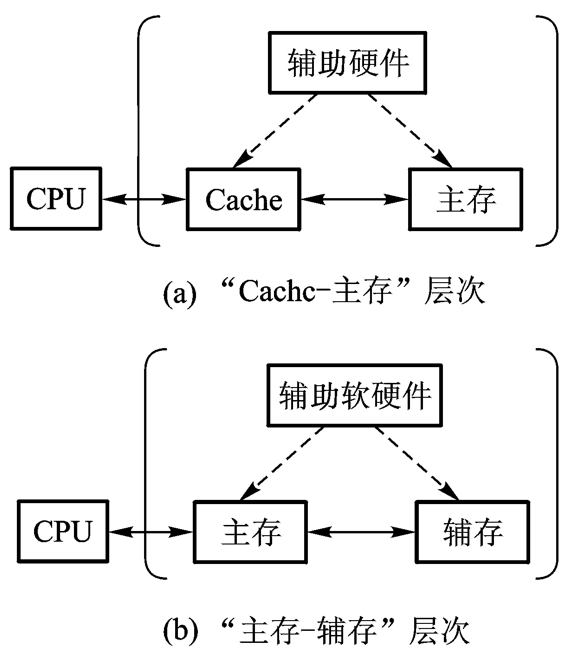
5.1.3 三级存储系统
三级存储系统:
Cache(高速缓冲存储器)
主存储器
磁盘存储器(辅存)
可以看成是由“Cache—主存”层次和“主存—辅存”层次构成的系统。
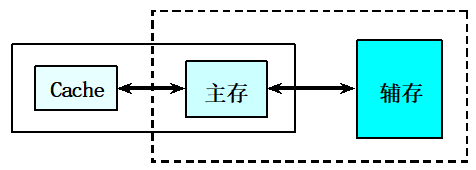
从主存的角度来看:
“Cache-主存”层次:弥补主存速度的不足
“主存-辅存”层次: 弥补主存容量的不足
5.1.4 存储层次的四个问题
映像规则:当把一个块调入高一层(靠近CPU)存储器时,可以放在哪些位置上?
查找算法:当所要访问的块在高一层存储器中时,如何找到该块?
替换算法:当发生不命中时,应替换哪一块?
写策略:当进行写访问时,应进行哪些操作?
5.2 Cache基本知识
5.2.1 基本结构和原理
Cache是按块进行管理的。
Cache和主存均被分割成大小相同的块。信息以块为单位调入Cache。

主存块地址(块号)用于查找该块在Cache中的位置。
块内位移用于确定所访问的数据在该块中的位置。
5.2.2 映像规则
全相联映像 (fully associative):主存中的任一块可以被放置到Cache中的任意一个位置。
特点:空间利用率最高,冲突概率最低,实现最复杂。
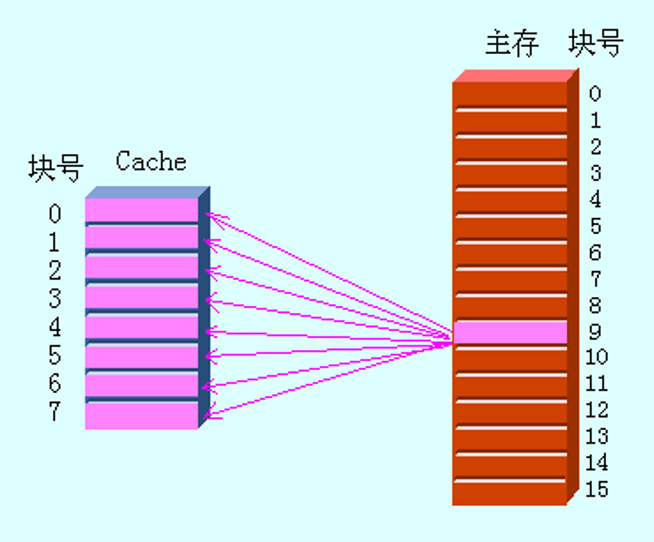
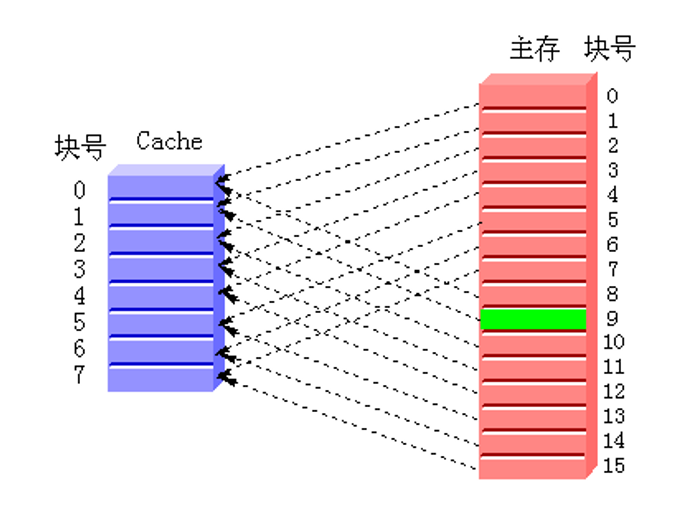
直接映像(directly associative):主存中的每一块只能被放置到Cache中唯一的一个位置。
特点:空间利用率最低,冲突概率最高,实现最简单。
组相联映像(set associative):主存中的每一块可以被放置到Cache中唯一的一个组中的任何一个位置。
组相联是直接映像和全相联的一种折中。
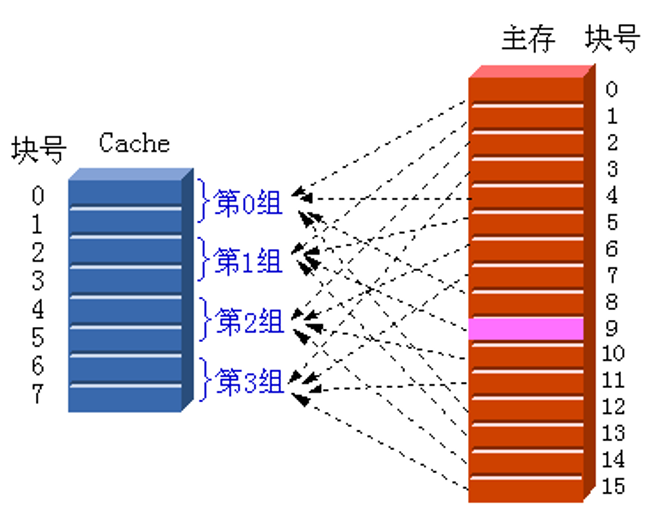
n 路组相联:每组中有n个块(n=M/G ),n 称为相联度。
相联度越高,Cache空间的利用率就越高,块冲突概率就越低,不命中率也就越低。
块冲突:向cache内调入主存块时,对应的位置已被占用。
绝大多数计算机采用直接映像或 n ≤4的组相联
全相联仅适用于小容量Cache
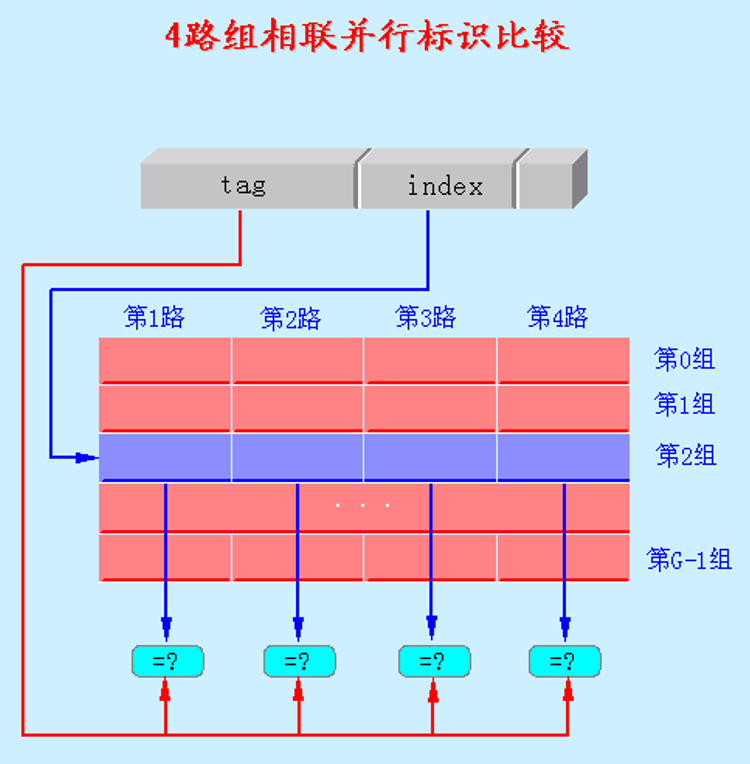
5.2.3 查找算法
目录表的结构
每一个cache块对应有一个目录表项
主存块的块地址的高位部分,称为标识
每个主存块能唯一地由其标识来确定
并行查找的实现方法
相联存储器

单体多字存储器+比较器
5.2.4 Cache的工作过程
5.2.5 替换算法
主要的替换算法有三种
随机法 优点:实现简单
FIFO先进先出法
LRU最近最少使用法
5.2.6 写策略
两种写策略
写策略是区分不同Cache设计方案的一个重要标志。
1.写直达法(也称为存直达法):
执行“写”操作时,不仅写入Cache,而且也写入下一级存储器。
2.写回法(也称为拷回法) :
执行“写”操作时,只写入Cache。仅当Cache中相应的块被替换时,才写回主存。 (设置“修改位”)
两种写策略的比较
写回法的优点:速度快,提高主存写效率,所使用的存储器带宽较低。
写直达法的优点:易于实现,一致性好。
采用写直达法时,若在进行“写”操作的过程中CPU必须等待,直到“写”操作结束,则称CPU写停顿。
减少写停顿的一种常用的优化技术:采用写缓冲器
“写”不命中时两种策略
按写分配(写时取):
先把所写单元所在的块调入Cache,再行写入。
不按写分配(绕写法):
写不命中时,直接写入下一级存储器而不调块。
5.2.7 Cache的性能分析
1.不命中率
优点:评价方便
缺点:
与硬件速度无关
容易产生一些误导
2.平均访存时间(更好,但仍是间接评价)
平均访存时间 = 命中时间+不命中率×不命中开销
3.程序执行时间 (最直接的评价)
CPU时间=(CPU执行周期数+存储器停顿周期数)× 时钟周期时间
假设:所有的访存停顿都是由Cache不命中引起的
其中:
存储器停顿时钟周期数=“读”的次数×读不命中率×读不命中开销+“写”的次数×写不命中率×写不命中开销
存储器停顿时钟周期数=访存次数×不命中率×不命中开销

5.2.8 改进Cache的性能
可以从三个方面改进Cache的性能:
1.降低不命中率
2.减少不命中开销
3.减少Cache命中时间
下面介绍17种Cache优化技术
8种用于降低不命中率 \(~~~~~\) 5.3节
5种用于减少不命中开销 \(~~\) 5.4节
4种用于减少命中时间 $~~~~~~$5.5节
5.3 降低Cache不命中率
5.3.1 三种类型的不命中
三种类型的不命中:
强制性不命中(冷启动不命中,首次访问不命中)
当第一次访问一个块时,该块不在Cache中,需从下一级存储器中调入Cache,这就是强制性不命中。
容量不命中:
如果程序执行时所需的块不能全部调入Cache中,则当某些块被替换后,若又重新被访问,就会发生不命中。这种不命中称为容量不命中。
冲突不命中(碰撞不命中,干扰不命中):
在组相联或直接映像Cache中,若太多的块映像到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。这就是发生了冲突不命中。
减少三种不命中的方法
强制性不命中:增加块大小,预取(本身很少)
容量不命中:增加容量 (抖动现象)
冲突不命中:提高相联度(理想情况:全相联,但代价昂贵)
5.3.2 增加Cache块大小----最简单
对于给定的Cache容量,当块大小增加时,不命中率开始是下降,后来反而上升了。
原因:
一方面它减少了强制性不命中;
另一方面,由于增加块大小会减少Cache中块的数目,所以有可能会增加冲突不命中。
5.3.3 增加Cache的容量----最直接
5.3.4 提高相联度
2:1 Cache经验规则: 容量为N的直接映像Cache的不命中率和容量为N/2的两路组相联Cache的不命中率差不多相同。
提高相联度是以增加命中时间为代价。
5.3.5 伪相联 Cache (列相联 Cache )
基本思想及工作原理
在逻辑上把Cache的空间上下平分为两个区。对于任何一次访问,伪相联Cache先按直接映像Cache的方式去处理。若命中,则其访问过程与直接映像Cache的情况一样。(快)
若不命中,则再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。(慢)
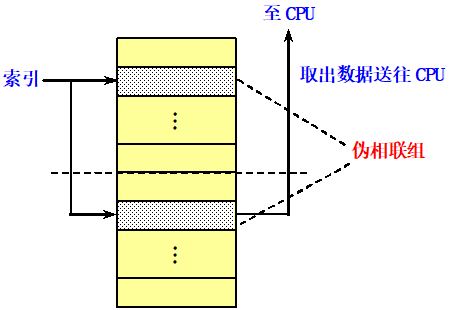
伪相联Cache的优点:
命中时间小
不命中率低
缺点:多种命中时间,增加流水线设计复杂度,常被用在离CPU较远的Cache中。
5.3.6 硬件预取
指令和数据都可以预取
5.3.7 编译器控制的预取
在编译时加入预取指令,在数据被用到之前发出预取请求。
编译器控制预取的目的:使执行指令和读取数据能重叠执行。
按照预取数据所放的位置,可把预取分为两种类型:
寄存器预取:把数据取到寄存器中。
Cache预取:只将数据取到Cache中。
按照预取的处理方式不同,可把预取分为:
故障性预取:在预取时,若出现虚地址故障或违反保护权限,就会发生异常。
非故障性预取:在遇到这种情况时则不会发生异常,因为这时它会放弃预取,转变为空操作。
5.3.8 编译器优化
基本思想:通过对软件进行优化来降低不命中率。(特色:无需对硬件做任何改动)
编译优化技术包括:
数组合并
循环融合
内外循环交换
分块
5.3.9 “牺牲” Cache
基本思想
在Cache和它下一级存储器的数据通路之间设置一个全相联的小Cache,称为“牺牲”Cache。
作用
对于减小冲突不命中很有效,特别是对于小容量的直接映像数据Cache,作用尤其明显。
减少不命中率方法中伪相联、预取技术、牺牲cache同时也会减少不命中开销。
5.4 减少Cache不命中开销
5.4.1 采用两级Cache
第一级Cache(L1)小而快
第二级Cache(L2)容量大
\(平均访存时间 = 命中时间_{L1}+不命中率_{L1}×(命中时间_{L2}+不命中率_{L2}×不命中开销_{L2})\)

评价第二级Cache时,应使用全局不命中率这个指标。
5.4.2 让读不命中优先于写
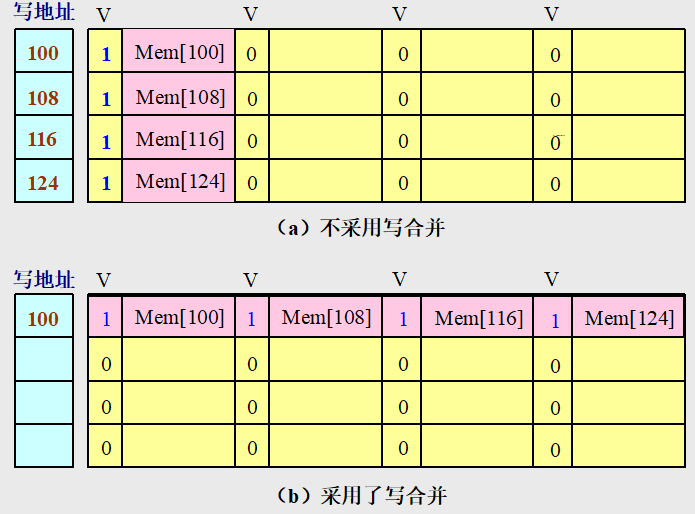
5.4.3 写缓冲合并
写直达Cache
依靠写缓冲来减少对下一级存储器写操作的时间。
如果写缓冲器为空,就把数据和相应地址写入该缓冲器。
如果写缓冲器中已经有了待写入的数据,就要把这次的写入地址与写缓冲器中已有的所有地址进行比较,看是否有匹配的项。如果有地址匹配而对应的位置又是空闲的,就把这次要写入的数据与该项合并。这就叫写缓冲合并。
5.4.4 请求字处理技术
请求字:从下一级存储器调入Cache的块中,只有一个字是立即需要的。这个字称为请求字。
应尽早把请求字发送给CPU:
尽早重启动:调块时,从块的起始位置开始读起。一旦请求字到达,就立即发送给CPU,让CPU继续执行。
请求字优先:调块时,从请求字所在的位置读起。这样,第一个读出的字便是请求字。将之立即发送给CPU。
5.4.5 非阻塞Cache技术
5.5 减少命中时间
5.5.1 容量小、结构简单的Cache
硬件越简单,速度就越快;
应使Cache足够小,以便可以与CPU一起放在同一块芯片上。
5.5.2 虚拟Cache
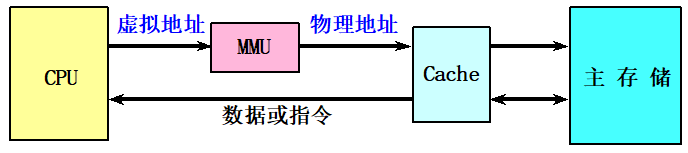
物理Cache
使用物理地址进行访问的传统Cache。
标识存储器中存放的是物理地址,进行地址检测也是用物理地址。
缺点:地址转换和访问Cache串行进行,访问速度很慢。
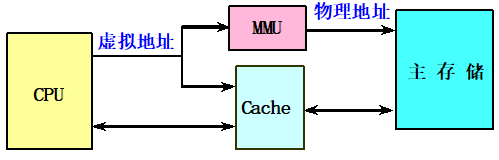
虚拟Cache
可以直接用虚拟地址进行访问的Cache。标识存储器中存放的是虚拟地址,进行地址检测用的也是虚拟地址。
优点:
在命中时不需要地址转换,省去了地址转换的时间。即使不命中,地址转换和访问Cache也是并行进行的,其速度比物理Cache快很多。
5.5.3 Cache访问流水化
5.5.4 踪迹 Cache
5.5.5 Cache优化技术总结
| 优化技术 | 不命中率 | 不命中开销 | 命中时间 | 硬件复杂度 | 说明 |
|---|---|---|---|---|---|
| 增加块大小 | + | - | 0 | 实现容易;Pentium 4 的第二级Cache采用了128字节的块 | |
| 增加Cache容量 | + | 1 | 被广泛采用,特别是第二级Cache | ||
| 提高相联度 | + | - | 1 | 被广泛采用 | |
| 牺牲Cache | + | 2 | AMD Athlon采用了8个项的Victim Cache | ||
| 伪相联Cache | + | 2 | MIPS R10000的第二级Cache采用 | ||
| 硬件预取指令和数据 | + | 2~3 | 许多机器预取指令,UltraSPARC Ⅲ预取数据 | ||
| 编译器控制的预取 | + | 3 | 需同时采用非阻塞Cache;有几种微处理器提供了对这种预取的支持 | ||
| 用编译技术减少Cache不命中次数 | + | 0 | 向软件提出了新要求;有些机器提供了编译器选项 | ||
| 使读不命中优先于写 | + | - | 1 | 在单处理机上实现容易,被广泛采用 | |
| 写缓冲归并 | + | 1 | 与写直达合用,广泛应用,例如21164,UltraSPARC Ⅲ | ||
| 尽早重启动和关键字优先 | + | 2 | 被广泛采用 | ||
| 非阻塞Cache | + | 3 | 在支持乱序执行的CPU中使用 | ||
| 两级Cache | + | 2 | 硬件代价大;两级Cache的块大小不同时实现困难;被广泛采用 | ||
| 容量小且结构简单的Cache | - | + | 0 | 实现容易,被广泛采用 | |
| 对Cache进行索引时不必进行地址变换 | + | 2 | 对于小容量Cache来说实现容易,已被Alpha 21164和UltraSPARC Ⅲ采用 | ||
| 流水化Cache访问 | + | 1 | 被广泛采用 | ||
| Trace Cache | + | 3 | Pentium 4 采用 |
5.6 并行主存系统
主存的主要性能指标:延迟和带宽
并行主存系统是在一个访存周期内能并行访问多个存储字的存储器。
一个单体单字宽的存储器:

字长与CPU的字长相同。
每一次只能访问一个存储字。假设该存储器的访问周期是\(T_M\),字长为\(W\)位,则其带宽为:
在相同的器件条件(即TM相同)下,可以采用两种并行存储器结构来提高主存的带宽:
单体多字存储器
多体交叉存储器
5.6.1 单体多字存储器
一个单体m字(这里m=4)存储器:
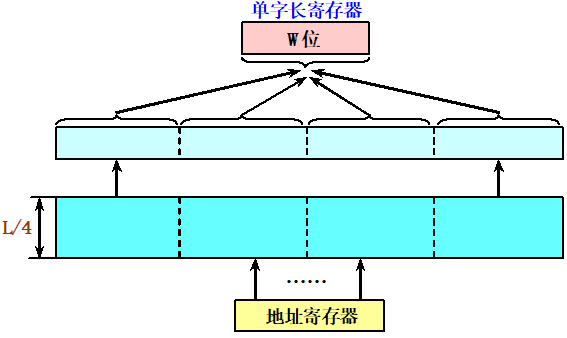
存储器能够每个存储周期读出m个CPU字。因此其最大带宽提高到原来的m倍 。
单体多字存储器的实际带宽比最大带宽小:读取的多字中有些可能当前无用
5.6.2 多体交叉存储器
多体交叉存储器:由多个单字存储体构成,每个体都有自己的地址寄存器以及地址译码和读/写驱动等电路。
多体(m=4)交叉存储器 :
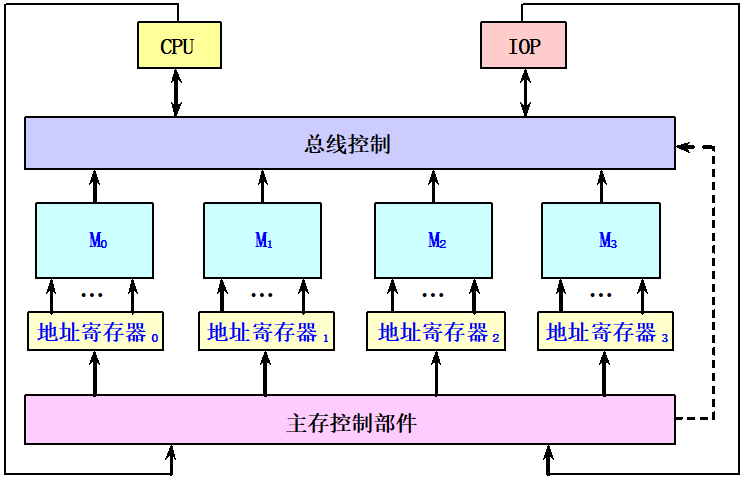
5.6.3 避免存储体冲突
解决体冲突的方法:
软件方法(编译器)
·循环交换优化
·扩展数组的大小,使之不是2的幂。
硬件方法
·使体数为素数,体内地址=地址A mod (存储体中的字数)可以直接截取

