
使用.Net Core做个爬虫
最近接手一个新项目,爬亚马逊分类、商品数据。记得大学的时候,自己瞎玩,写过一个爬有缘网数据的程序,那个时候没有考虑那么多,写的还是单线程,因为网站没有反爬,就不停的一直请求,记得放到实验室电脑上一天,跑了30w+的数据。然后当前晚上有缘网网站显示维护中。。。。
毕竟小打小闹,没有真正的写过爬虫。就翻别人博客了解了下爬虫所用到的技术、技巧、套路。然后就翻到这个老哥写的博客, 虽然语言是有点嚣张,但是我还是比较认同的 哈哈哈哈。

下面从爬虫涉及的几任务调度、数据去重、数据解析、并发控制、断点续爬、代理来聊聊项目遇到的坑。
一、数据解析
数据解析就是提取网页上的有效数据。.Net下有个HtmlAgilityPack组件,可以很好地解析HMTL。想都没想 就直接用了它(这就为后面挖了一个大坑)。刚开始单线程测试的时候,一切正常,但是当我开了50个线程的时候,内存在90s内飙升到了3G,而且持续爬升。
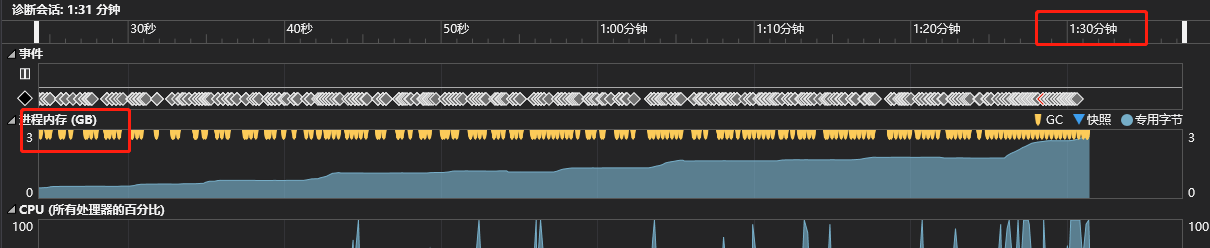
用.Net Memory工具分析发现 内存被大对象沾满了,所以每次GC的时候内存并没有被回收,有5w多HtmlNode,每个对象大小都超过 85000byte。
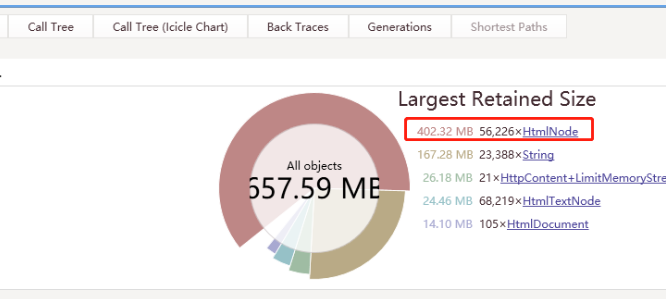
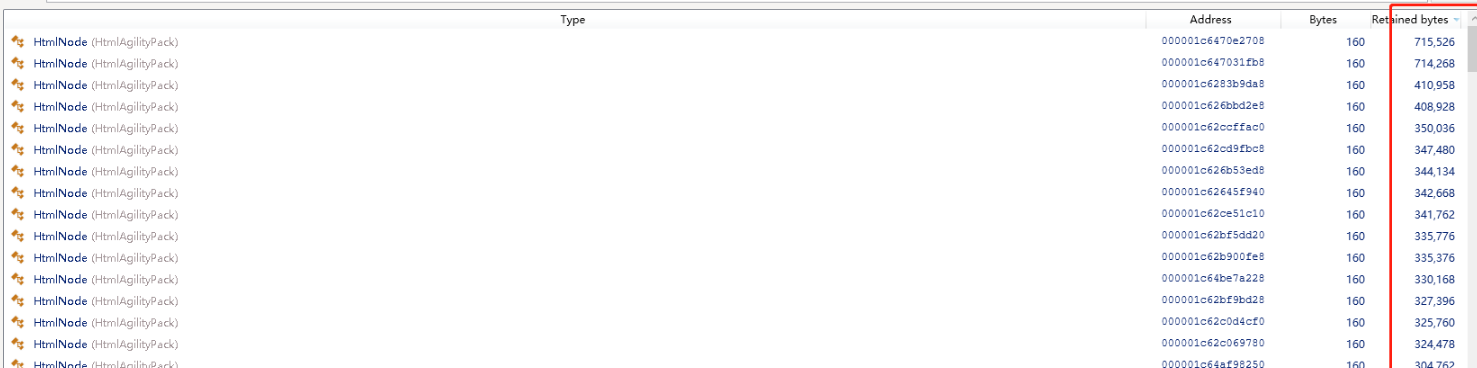
因为亚马逊的图片不是通过链接外链的,而是通过base64编码的,所以导致下载的网页Html超过1M,而85000byte就算大对象了。导致每爬取一个商品详情页,都会加载到HtmlNode中变成一个大对象,由于GC不压缩大对象,而C对大对象的回收只有在回收2代的时候才触发。所以只能改变策略,通过正则、切分字符串来处理。
二、任务调度、并行爬取
目的是爬取亚马逊的分类和分类下的商品,我做了个3个任务,
1、找到分类入口,爬取分类Id、标题、url 、分类等级存储到数据库。
2、根据1任务爬取的分类Id,获取分类下商品列表。爬取列表上商品部分信息,包括商品的Id、名称、缩略图。
3、根据2任务爬取的商品Id,获取商品详情页,爬取商品详情页的其他信息。
一个分类下有几百页商品列表,而每个列表一般有22个商品。所以1任务爬取完一次,2任务要爬取几百次(当然不会将分类下的所有页码都爬完,设定只爬20页) ,3任务要爬 20 x 22次。这样分任务的好处就是 3个任务中,不论哪个任务挂了,其他2个任务是不受影响的,可以继续跑。
比如2任务挂掉了,1任务不受它影响,虽然3任务的需要2任务的数据,但是3任务的速度是比2任务慢了22倍还多(获取详情的时候 还需要在请求其他页面)所以任务线程相同的情况下 2任务的会有很多剩余商品 3还没有来得及跑。
调度采用了QuartZ 使用Cron配置定时任务。使用Parallel并行爬取,线程数量可以配只需要将方法和方法所需要的参数集合放到ForEach
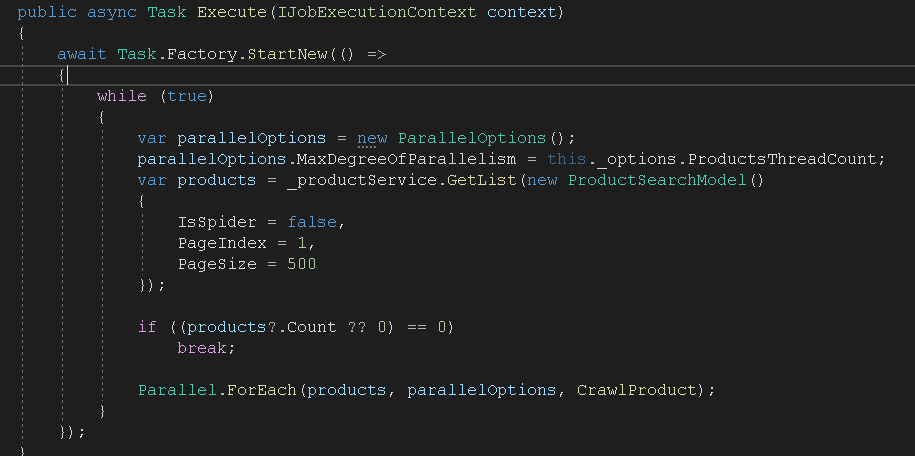
合理配置每个任务的线程数量,我设置爬取分类线程数1,商品列表的线程是2,商品详情爬取线程为50。爬取的速度不同线程数量就不同,而且并不是线程越高越好,这个值是不断的调试采集相同时间的数据分析得出来的。

三、代理
现在有很多代理商,普遍分为两种:
第一种通过接口返回代理IP和这个代理的可用时间,在这个时间段内,这个代理是可用的。注意:这种代理方式需要有个代理池,因为爬虫一般都是多线程,如果在代理IP可用时间段内,多个线程一直使用同一个代理IP,很大可能会被封。所以保险的做法就是一个线程一个代理,降低每个代理的请求次数。
第二种代理直接给你一个固定的IP,这个代理IP没有时间限制,代理商那边会帮你自动帮你换不同的IP请求目标地址。
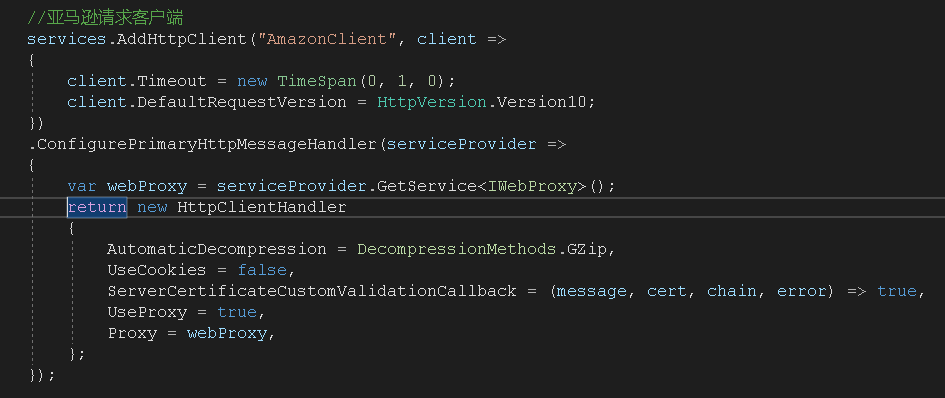
.Net Core中使用代理很简单,因为我使用的是HttpClientFactory,所以在添加服务的时候配置 HttpClientHandler的代理就可以,需要实现一个IWebProxy类,返回对应的代理IP和端口号就可以了。
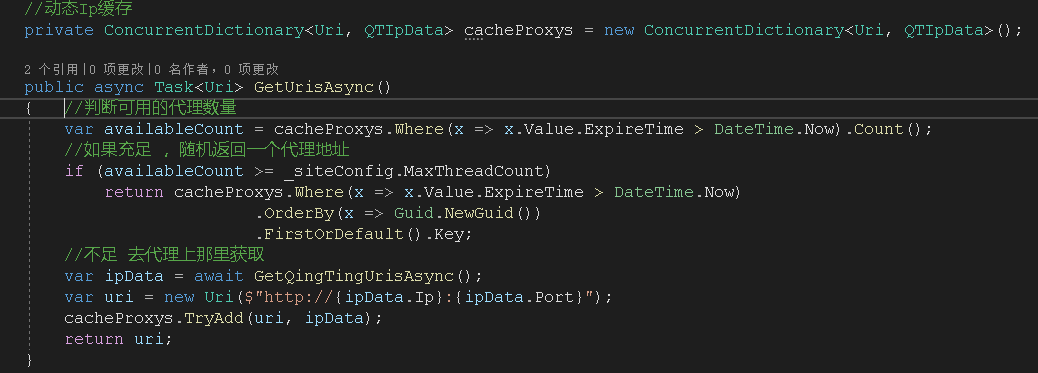
刚开始使用的是第一种代理,为了实现一个线程一个代理,我创建了一个代理池,在程序启动的时候,每个线程都会从代理商那获取到一个代理IP,然后放到代理池中,每次获取代理的时候,通过代理池中随机挑选一个代理IP,在挑选前会判断当前代理池中的代理数量,如果小于线程数据,就会去获取填充到代理池中。
后面发现国内的代理商的IP访问国外网址太慢了,就换了国外代理,国外代理使用的是第二种方案。但是这个代理商不是自动帮你更换IP,而是需要每次传递一个随机数 SessionId,随机数不同,代理商访问目标网站的IP就不同,而且要传用户名和密码。
开始 我是这么做的: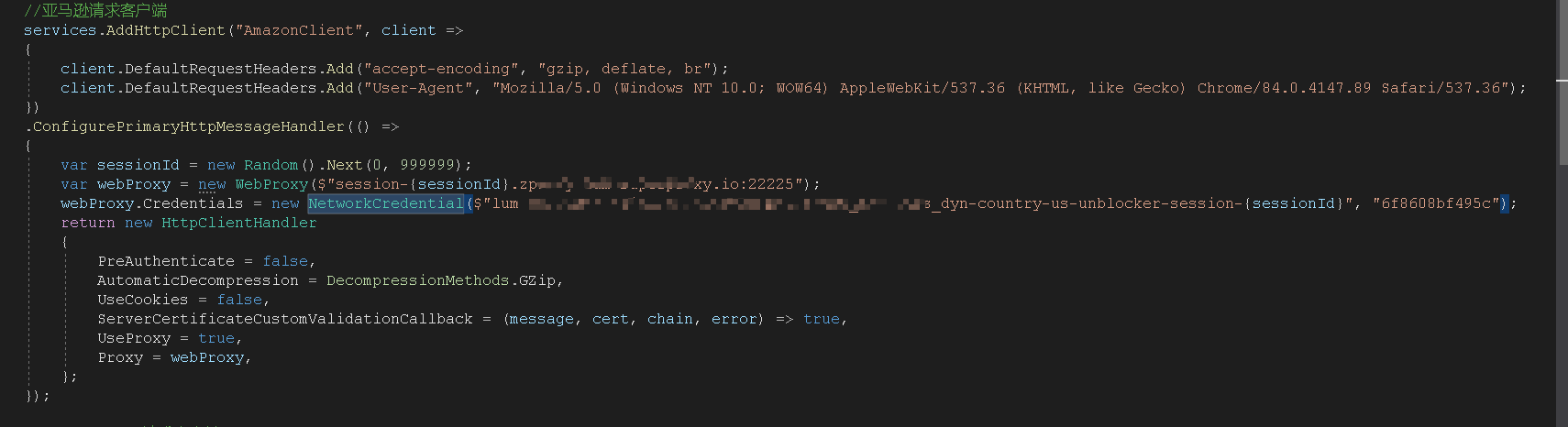
发现这种只有在第一次创建HttpClient的时候才会去走配置ConfigurePrimaryHttpMessageHandler方法,之后创建HttpClient都不会走。就导致一直在使用同一个IP请求。
所以没办法,只能放弃使用HttpClientFactory,自己手动创建HttpClient ,然后释放。但这种又随之带来一个问题HttpClient虽然释放了,但是端口还是被占用着,目前还没有好的解决办法。
四、断点续爬、数据去重
我这个业务中这两个功能就很好实现,每次爬取完成商品页码,就存储下一页的页码和当前爬取的页码数。配置一个参数是否是断点续爬,如果是断点续爬,就从上次记录的页码爬取商品。
数据去重,因为直接可以拿到亚马逊的商品Id和分类Id,所以去重就变的很简单,任务启动的时候,会将已经爬取过的商品Id和分类Id放到缓存中,爬取的时候对比数据。
项目在服务器上跑了2个晚上,表现还是可以的,数据都正确采集到了117w数据(包含未爬取详情的商品),最后的最后。。。。项目被砍了,因为亚马逊的商品详情页数据太大,导致爬了12个小时用了40G流量,1G=6美元 ,一个月就要40x2x6x30=14400美元。忙碌了两周,也算从零写了一个小小的爬虫,还算有所得。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号