part12:Python 文件I/O(pathlib模块:PurePath、Path,os.path,fnmatch,open,with,linecache,os模块操作文件和目录,tempfile)
I/O(输入/输出)是所有程序必需的部分:
- 使用输入机制,程序可读取外部数据(包括磁盘、光盘等)、用户输入数据;
- 使用输出机制,程序可记录运行状态,将数据输出到光盘、磁盘等设备中。
Python有丰富的I/O支持:
- 提供了 pathlib 和 os.path 操作各种路径。
- 提供了 open() 函数打开文件,打开文件后,可读取文件内容、也可向文件输出内容(写入)。
- Python 有多种方式可读取文件内容,非常简单、灵活。
- os 模块下有大量的文件 I/O 函数,使用这些函数读取、写入文件也很方便,可根据需要灵活选择。
- tempfile 模块可创建临时文件和临时目录
- 该模块下的高级 API 会自动管理临时文件的创建和删除;
- 在程序中不再使用临时文件或目录时,就会自动删除。
一、使用 pathlib 模块操作目录
pathlib 模块提供了一组面向对象的类,这些类可代表各种操作系统上的路径,可通过些类操作路径。pathlib 模块下的类如下图一所示。
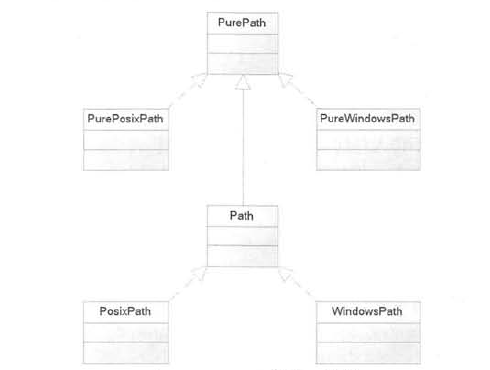
- PurePath:代表并不访问实际文件系统的”纯路径“。简单点说,PurePath 只是负责对路径字符串执行操作,至于该字符串是否对应实际的路径,它并不关心。PurePath 有两个子类,是 PurePosixPath 和 PureWindowsPath,分别代表 UNIX 风格的路径和 Windows 风格的路径。
- Path:是访问实际文件系统的”真正路径“。Path 对象可用于判断对应的文件是否存在、是否为文件、是否为目录等。Path 有两个子类,即 PosixPath 和 WindowsPath。
1、PurePath 的基本功能
使用 PurePath 或它的两个子类可创建 PurePath 对象。使用 PurePath 创建对象时,在 UNIX 或 Mac OS X 系统上返回的是 PurePosixPath 对象;在 Windows 系统上返回的是 PurePosixPath 对象。可使用 PurePath 的两个子类创建明确的对象。
在创建 PurePath 和 Path 时,可以传入单个路径字符串,也可传入多个路径字符串,PurePath 会将多个字符串拼接成一个字符串。示例如下:
from pathlib import *
# 创建 PurePath,在 Windows 中实际上使用的是 PureWidowsPath
pp = PurePath('hello.py') # 传入一个参数
print(type(pp)) # <class 'pathlib.PureWindowsPath'>
pp = PurePath('python', 'some/path', 'info')
# 默认会拼接成 Windows 风格的路径
print(pp) # python\some\path\info
pp = PurePath(Path('python'), Path('info'))
# 在 Windows 系统中,同样默认拼接成 Windows 风格的路径
print(pp) # python\info
# 明确指定创建 PurePosixPath
pp = PurePosixPath('python', 'some/path', 'info')
# 输出的是 UNIX 风格的路径
print(pp) # python/some/path/info
- 在创建 PurePath 时不传入任何参数,会默认创建代表路径的 PurePath,相当于传入点号(当前路径)为参数,示例如下:
# 不传入参数,默认使用当前路径
pp = PurePath()
print(pp) # 输出是:.
- 在创建 PurePath 对象传入的参数包含多个根路径,则只有最后一个根路径及后面的子路径生效。示例如下:
# 传入多个包含根路径的参数,只有最后一个根路径及后面的子路径生效
pp = PurePosixPath('/etc', '/usr', 'lib64')
print(pp) # /usr/lib64
pp = PureWindowsPath('c:/windows', 'd:/info', 'python')
print(pp) # d:\info\python
- 在 Windows 风格路径中,只有盘符才是根路径,只有斜杠是不算的。示例如下:
# Windows 风格路径,只有盘符才算是根路径
pp = PureWindowsPath('c:/windows', '/Program Files')
print(pp) # c:\Program Files
- 在创建 PurePath 对象传入的路径字符串中包含多余斜杠和点号,会忽略掉。但是两个点号不会被忽略,因为两个点表示上一级路径。示例如下:
# 在路径字符串中有多余的斜杠和点号会被忽略
pp = PurePath('foo//bar')
print(pp) # foo\bar
pp = PurePath('foo/./bar')
print(pp) # foo\bar
pp = PurePath('foo/../bar') # 两个点号不会被忽略
print(pp) # foo\..\bar
- PurePath 对象支持各种比较运算符,可以比较是否相等、大小,实际比较的是它们的路径字符串。示例如下:
from pathlib import *
# 比较两个 UNIX 风格的路径,区分大小与
print(PurePosixPath('info') == PurePosixPath('INFO')) # False
# 比较两个 Windows 风格的路径,不区分大小写
print(PureWindowsPath('info') == PureWindowsPath('INFO')) # True
# Windows 风格的路径不区分大小写
print(PureWindowsPath('INFO') in {PureWindowsPath('info') }) # True
# UNIX 风格的路径区分大小写,所以 'D:' 小于 'c:'
print(PurePosixPath('D:') < PurePosixPath('d:')) # True
# Windows 风格的路径不区分大小写,所以 'd:'(D:) 大于 ’c:'
print(PureWindowsPath('D:') > PureWindowsPath('c:')) # True
- 不同风格的 PurePath 对象也可以比较是否相等,结果总是返回 False。但是不能比较大小,否则引发错误。示例如下:
# 不同风格的 PurePath 对象可以判断是否相等,总返回 False
print(PureWindowsPath('python') == PurePosixPath('python')) # False
# 不同风格的路径不能判断大小,否则引发错误
print(PurePosixPath('info') < PureWindowsPath('info')) # TypeError
- PurePath 对象支持斜杠(/)作为运算符,作用是将多个路径连接起来。不区分 UNIX 和 Windows 风格,都使用斜杠作为连接运算符,示例如下:
pp = PureWindowsPath('abc')
# 将多个路径连接起来(Windows 风格的路径)
print(pp / 'xyz' / 'html') # abc\xyz\html
pp = PurePosixPath('foo')
# 将多个路径连接起来(UNIX 风格的路径)
print(pp / 'bar' / 'root') # foo/bar/root
pp2 = PurePosixPath('home', 'michael')
# 将 pp、pp2两个路径连接起来
print(pp / pp2) # foo/home/michael
上面代码第3行使用斜杠连接多个 Windows 路径,连接完成后依然是 Windows 路径分隔符的反斜杠。
- PurePath 对象的本质是字符串,因此可使用 str() 函数将其恢复成字符串对象。默认转换为对应平台风格的字符串。示例如下:
pp = PureWindowsPath('foo', 'bar', 'python')
print(str(pp)) # foo\bar\python
pp = PurePosixPath('home', 'michael', 'pyhton')
print(str(pp)) # home/michael/pyhton
从输出可以看出,路径的分隔符是与系统平台风格对应的。
2、PurePath 的属性和方法
PurePath有很多属性和方法,主要用于操作路径字符串。PurePath 并不真正执行底层的文件操作,因此不理会路径字符串在底层是否有对应的路径。所以这些操作类似于字符串方法。
(1)、PurePath.parts:返回路径字符串中所包含的各部分。
(2)、PurePath.drive:返回路径字符串中的驱动器盘符。
(3)、PurePath.root:返回路径字符串中的根路径。
(4)、PurePath.anchor:返回路径字符串中的盘符和根路径。
(5)、PurePath.parents:返回当前路径的全部父路径。
(6)、PurePath.parent:返回当前路径的上一级路径,相当于 parents[0] 的返回值。
(7)、PurePath.name:返回当前路径中的文件名。
(8)、PurePath.suffixes:返回当前路径下所有文件的后缀名。
(9)、PurePath.suffix:返回当前文件的后缀名,相当于 suffixes 属性的最后一个元素。
(10)、PurePath.stem:返回当前文件的主文件名。
(11)、PurePath.as_posix():将当前路径转换为 UNIX 风格的路径。
(12)、PurePath.as_uri():将当前路径转换为 URI。只有绝对路径才能转换,否则引发 ValueError。
(13)、PurePath.is_absolute():判断当前路径是否为绝对路径。
(14)、PurePath.joinpath(*other):将多个路径连接在一起,类似于斜杠运算符。
(15)、PurePath.match(pattern):判断当前路径是否匹配指定通配符。
(16)、PurePath.relative_to(*other):获取当前路径中去除基准路径之后的结果。
(17)、PurePath.with_name(name):将当前路径中的文件名替换为新文件名。如果当前路径中没有文件名,则引发 ValueError。
(18)、PurePath.with_suffix(suffix):将当前路径中的文件名后缀替换成新的后缀名。如果当前路径中没有后缀名,则会添加新的后缀名。
关于这些属性和方法的用法示例如下:
from pathlib import *
# 访问 drive 属性,返回驱动器盘符
print(PureWindowsPath('d:/Program Files/').drive) # d:
print(PureWindowsPath('/Program Files/').drive) # ''
print(PurePosixPath('/etc').drive) # ''
# 访问 root 属性,返回根路径
print(PureWindowsPath('d:/Program Files/').root) # \
print(PureWindowsPath('d:Program Files/').root) # ''
print(PurePosixPath('/etc').root) # /
# 访问 anchor 属性,返回路径中的盘符和根路径
print(PureWindowsPath('d:/Program Files/').anchor) # d:\
print(PureWindowsPath('d:Program Files/').anchor) # d:
print(PurePosixPath('/etc').anchor) # /
# 访问 parents 属性,返回全部父路径
pp = PurePath('abc/xyz/foo/bar')
print(pp.parents[0]) # abc\xyz\foo
print(pp.parents[1]) # abc\xyz
print(pp.parents[2]) # abc
print(pp.parents[3]) # .
# 访问 parent 属性
print(pp.parent) # abc\xyz\foo
# 访问 name 属性,返回当前路径中的文件名
print(pp.name) # bar
pp = PurePath('abc/xyz/foo.py')
print(pp.name) # foo.py
pp = PurePath('abc/xyz/foo.txt.tar.zip')
# 访问 suffixes 属性
print(pp.suffixes[0]) # .txt
print(pp.suffixes[1]) # .tar
print(pp.suffixes[2]) # .zip
# 访问 suffix 属性
print(pp.suffix) # .zip
print(pp.stem) # foo.txt.tar
pp = PurePath('abc', 'xyz', 'foo', 'bar')
print(pp) # abc\xyz\foo\ba
# 转换成 UNIX 风格的路径
print(pp.as_posix()) # abc/xyz/foo/bar
# 将相对路径转换成 URI 会引发异常
# print(pp.as_uri()) # 引发:ValueError
# 创建绝对路径
pp = PurePath('d:/', 'Python', 'Python3.6.exe')
# 将绝对路径转换成 URI
print(pp.as_uri()) # file:///d:/Python/Python3.6.exe
# 判断当前路径是否匹配指定模式
print(PurePath('a/b.py').match('*.py')) # True
print(PurePath('/a/b/c.py').match('b/*.py')) # True
print(PurePath('/a/b/c.py').match('a/*.py')) # False
pp = PurePosixPath('c:/abc/xyz/foo')
# 测试relative_to方法,返回当前路径中去除基准路径后的结果
print(pp.relative_to('c:/')) # abc\xyz\foo
print(pp.relative_to('c:/abc')) # xyz\foo
print(pp.relative_to('c:/abc/xyz')) # foo
# 测试with_name方法,替换当前路径中的文件名,没有文件名会引发 ValueError
p = PureWindowsPath('e:/Downloads/pathlib.tar.gz')
print(p.with_name('foo.py')) # e:\Downloads\foo.py
p = PureWindowsPath('c:/')
print(p.with_name('foo.py')) # 没有文件名,引发异常:ValueError
# 测试with_suffix方法,替换当前路径中文件的后缀名,文件没有后缀名会添加新后缀名
p = PureWindowsPath('e:/Downloads/pathlib.tar.gz')
print(p.with_suffix('.zip')) # e:\Downloads\pathlib.tar.zip
p = PureWindowsPath('README')
print(p.with_suffix('.txt')) # README.txt
3、Path 的功能和用法
- Path 是 PurePath 的子类,Path 继承了 PurePath 的各种操作、属性和方法。
- Path 会真正访问底层文件系统,并判断对应的路径是否存在,获取 Path 对应路径的各种属性(如是否只读、是文件还是文件夹等),还可对文件进行读写。
- PurePath 与 Path 的根本区别:PurePath 的本质是字符串,Path 会真正访问底层的文件路径,Path提供了新的属性和方法来访问底层的文件系统。
Path 有很多的属性和方法,详情情况见:https://docs.python.org/3/library/pathlib.html
- Path 也有两个子类:PosixPath 和 WindowsPath ,分别代表 UNIX 风格和 Windows 风格的路径。
- Path 对象有大量的 is_xxx() 方法,用于判断该 Path 对应的路径是否为 xxx。
- Path 对象的 exists() 方法,用于判断该 Path 对应的目录是否存在。
- Path 对象的一个常用方法 iterdir() 可返回 Path 对应目录下的所有子目录和文件。
- Path 对象的 glob() 方法用于获取对应目录及其子目录下匹配指定模式的所有文件。
- 使用 glob() 方法可以非常方便的查找指定文件。
Path 的简单用法示例如下:
from pathlib import *
# 获取当前目录
p = Path('.')
# 遍历当前目录下的所有文件和子目录
for x in p.iterdir():
print(x)
# 获取上一级目录
p = Path('../')
# 获取上级目录及其所有子目录下的 .py 文件
for x in p.glob('**/*.py'):
print(x)
# 获取 e:/my_module 对应的目录
p = Path('e:/my_module')
# 获取上级目录及其所有子目录下的 cal.py 文件
for x in p.glob('**/cal.py'):
print(x)
上面代码中第6行调用 Path 的 iterdir() 方法返回当前目录下的所有文件和子目录;第12行代码调用了 glob() 方法,获取上一级目录及其所有子目录下的 *.py 文件;第18行代码获取 e:/my_module 目录及其所有子目录下的 cal.py 文件。这段代码的运行结果如下所示:
path_test1.py
purepath_test.py
purepath_test2.py
purepath_test3.py
..\12.1\path_test1.py
..\12.1\purepath_test.py
..\12.1\purepath_test2.py
..\12.1\purepath_test3.py
e:\my_module\cal.py
从输出结果可知,Path 对象用一个 glob() 方法就能遍历当前目录下的文件和子目录,还能搜索指定目录及其子目录。在其他语言中,Path 的 glob() 方法的功能,通常需要递归才能实现,这也正是 Python 的强大之处。
Path 对象的另一些常用方法:
- read_bytes()方法:读取 Path 对应文件的字节数据(二进制数据)。
- read_text(encoding=None,errors=None)方法:读取 Path 对应文件的文本数据。
- write_bytes(data) 和 Path.write_text(data,encoding=None,errors=None) 方法输出字节数据(二进制数据)文本数据到文件。
下面代码示例用 Path 来读写文件:
from pathlib import Path
p = Path('a_text.txt')
# 指定以 utf-8 字符集输出文本内容
result = p.write_text('''有一个美丽的新世界
它在远方等我
那里有天真的孩子
还有姑娘的酒窝''', encoding='utf-8')
# 返回输出的字符串
print(result)
# 指定以 utf-8 字符集读取文本内容
content = p.read_text(encoding='utf-8')
# 输出所读取的内容
print(content)
# 读取字节内容
bb = p.read_bytes()
print(bb)
上面代码的第5行使用 utf-8 字符集调用 write_text() 方法输出字符串内容到文件中,该方法返回的是实际输出的字符个数;第14行代码使用 utf-8 字符集读取文件的字符串内容,该方法返回的是整个文件的内容。
4、使用 os.path 操作目录
os.path 模块下的函数可以操作系统的目录本身,该模块提供了 exists() 函数判断该目录是否存在;也提供了 getctime()、getmtime()、getatime() 函数来获取该目录的创建时间、最后一次修改时间、最后一次访问时间;提供了 getsize() 函数获取指定文件的大小。
下面代码是 os.path 模块下操作目录的常见函数的功能和用法:
import os
import time
# 获取绝对路径
print(os.path.abspath('a_text.txt')) # E:\python_work\cp12\12.1\a_text.txt
# 获取共同前缀名
print(os.path.commonprefix(['/usr/lib', '/usr/local/lib'])) # /usr/l
# 获取共同路径
print(os.path.commonpath(['/usr/lib', '/usr/local/lib'])) # \usr
# 获取目录
print(os.path.dirname('abc/xyz/readme.txt')) # abc/xyz
# 判断指定目录是否存在
print(os.path.exists('abc/xyz/readme.txt')) # False
# 获取最近一次访问时间
print(time.ctime(os.path.getatime('a_text.txt')))
# 获取最后一次修改时间
print(time.ctime(os.path.getmtime('a_text.txt')))
# 获取创建时间
print(time.ctime(os.path.getctime('a_text.txt')))
# 获取文件大小
print(os.path.getsize('a_text.txt')) # 96
# 判断是否为文件
print(os.path.isfile('a_text.txt')) # True
# 判断是否为目录
print(os.path.isdir('a_text.txt')) # False
# 判断是否为同一个文件
print(os.path.samefile('a_text.txt', './a_text.txt')) # True
5、使用 fnmatch 处理文件名匹配
fnmatch 模块支持类似于 UNIX shell 风格的文件名匹配,支持的通配符有:
*:可匹配任意个任意字符。
?:可匹配一个任意字符。
[字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。比如[a-c]代表a、b、c 字符中任意一个。
[!字符序列]:匹配不在中括号里字符序列中的任意字符。
fnmatch 模块提供的函数有:
(1)、fnmatch.fnmatch(filename, pattern):判断文件名与 pattern 是否匹配。
(2)、fnmatch.fnmatchcase(filename,pattern):功能同上一样函数,只是这个函数要区分大小写。
(3)、fnmatch.filter(names, pattern):对 names 列表根据 pattern 进行过滤,返回过滤后的文件名组成的列表。
(4)、fnmatch.translate(pattern):用于将一个 UNIX shell 风格的 pattern 转换为正则表达式 pattern。
fnmatch 模块的代码示例如下:
from pathlib import *
import fnmatch
# 遍历当前目录下的所有文件和子目录
for file in Path('.').iterdir():
# 访问所有以 .py 结尾的文件
if fnmatch.fnmatch(file, '*.py'):
print(file)
names = ['a.py', 'b.py', 'c.py', 'd.py']
# 对 names 列表进行过滤
sub = fnmatch.filter(names, '[ac].py')
print(sub) # ['a.py', 'c.py']
# translate 将 UNIX shell 风格的 pattern 转换为正则表达式 pattern
print(fnmatch.translate('?.py')) # (?s:.\.py)\Z
print(fnmatch.translate('[ac].py')) # (?s:[ac]\.py)\Z
print(fnmatch.translate('[a-c].py')) # (?s:[a-c]\.py)\Z
二、打开文件
有了目录操作的函数,接下来就是打开文件进行读写操作。Python有内置的 open() 函数用于打开指定文件,语法如下:
open(file_name, [, access_mode], [, buffering])
- file_name 参数是必须的,代表文件路径及文件名,只给文件名是在当前路径下打开
- access_mode 参数是打开方式,可选,有读、写、追加、二进制等方式。
- buffering 参数是可选的,表示是否缓冲,1 或 True 要缓冲,0 或 False 不缓冲。
文件打开后得到的文件对象有一些属性和方法可以调用。常见的属性如下:
file.closed:该属性返回文件是否已经关闭。
file.mode:返回被打开文件的访问模式。
file.name:返回被打开文件的名称。
# 以默认方式打开文件
f = open('open_test.py')
# 访问文件的编码方式
print(f.encoding) # cp936
# 访问文件的打开模式
print(f.mode) # r
# 查看文件是否已经关闭
print(f.closed) # False
# 查看打开文件的文件名
print(f.name) # open_test.py
1、文件的打开模式
open() 函数支持的文件打开模式如下:
r:只读模式
w:写模式
a:追加模式
+:读写模式,可与其他模式结合使用,比如 r+ 是读写模式,w+ 也是读写模式
b:二进制模式,可与其他模式结合使用,比如 rb 代表二进制只读模式,rb+ 代表二进制读写模式,ab 代表二进制追加模式。
关于这几个模式的一些注意点:
- w 和 w+ 的差别不大,这两种模式都会新建文件,如果目标文件已经存在,则会清空目标文件。
- r 和 r+ 模式打开文件,需要目标文件是已经存在的,这两种模式都不会新建文件。文件指针指向打开文件的起始处(开头)。
- a 和 a+ 模式打开文件,如果目标文件不存在,同样会自动创建文件。文件指针指向打开的末尾。
- b 模式通常用于打开图片文件、音频文件、视频文件等。在计算机中大部分文件都是二进制文件。
- 使用文本方式操作二进制文件,会得不到正确的内容。
2、缓冲
- 由于硬盘、网络等的 I/O 比内存的 I/O慢很多,程序是直接操作的内存数据,内存数据就是从硬盘、I/O等设设备来的。在读写硬盘等数据时,建立缓冲区,会提高程序运行效率。
- open() 函数的 buffering 参数是 0(或False),则打开的文件不带缓冲;如果是1(或True),则打开的文件带缓冲。如果是大于 1 整数,则用于指定缓冲区的大小(单位是字节);如果是任何负数,则表示使用默认缓冲区大小。
三、读取文件
获得文件对象后,可使用其相应的方法读取文件,也可使用其他模块的函数读取文件。
1、按字节或字符读取
- 文件对象的 read() 方法可按字节或字符读取文件内容。当使用 b 模式打开文件时,就按字节读取,否则按字符模式读取。
- read() 方法默认一次读取整个文件内容。可传入一个整数参数用于指定一次读取多少字节或字符。
代码示例如下:
f = open('text.txt', 'r', True)
while True:
# 每次读取一个字符
ch =f.read(1)
# 如果没有读取到数据就退出循环
if not ch: break
print(ch, end='')
f.close()
- 文件使用完后,应正确的调用 close() 方法来关闭文件,避免资源泄露。
- 如果打开文件的操作在 try 块中,可以在 finally 块中调用 close() 方法关闭文件。
- read() 不传入参数,默认读取全部文件内容。
- open() 函数打开文件时,没有明确指定字符集的话,则默认使用当前操作系统的字符集。Windows 平台默认使用GBK字符集,在这段代码中打开的 text.txt 文件也应该使用 GBK 字符集保存。如果字符集不一致,读取的内容就会出现乱码,即 UnicodeDecodeError 。
当读取的文件所使用的字符集和当前操作系统的字符集不匹配时,有两种解决方式:
(1)、使用二进制模式读取,然后用 bytes 的 decode() 方法恢复成字符串。
(2)、利用 codecs 模块的 open() 函数来打开文件,该函数在打开文件时允许指定字符集。或者使用内置的 open() 函数打开文件时,也可指定字符集。
代码示例如下:
# 使用二进制模式读取 text.txt 文件内容
f = open('text.txt', 'rb', True)
# 直接读取全部文件内容,并调用 bytes 的 decode() 方法将字节内容恢复成字符串
# 由于 text.txt 文件保存时的字集是 utf-8,所以使用 decode() 方法是指定使用 utf-8 字符集
print(f.read().decode('utf-8'))
f.close()
import codecs
# 指定使用 utf-8 字符集读取文件内容
file = codecs.open('text.txt', 'r', 'utf-8', buffering=True)
print(file.read())
file.close()
2、按行读取
按行读取文件内容时,通常只能使用文本方式来打开文件,只有文本文件才有行概念。文件对象可用下面两个方法读取行:
(1)、readline([n]):一次读取一行内容。参数 n 用于指定读取此行内的 n 个字符。
(2)、readlines():读取文件对象的所有行。
readline() 方法是逐行读取数据,当读取到结尾时,会返回空(False),可通过取反让条件成立来退出循环。示例如下:
# 使用 utf-8 字符集读取文件内容
f = open('readline_test.py', 'r', encoding='utf-8', buffering=True)
while True:
# 每次读取一行
line = f.readline()
# 如果没有读取到数据,则终止循环
if not line: break
print(line, end='')
f.close()
print('\n','*' * 30)
# 测试 readlines() 方法
f2 = open("readline_test.py", 'r', buffering=True, encoding='utf-8')
for l in f2.readlines():
print(l, end='')
f2.close()
3、使用 fileinput 模块读取多个输入流
fileinput 模块提供了下面这个函数将多个输入流合并在一起:
(1)、fileinput.input(files=None, inplace=False, bufsize=0, mode='r', openhook=None):files 参数可指定多个输入文件输入流,该函数功能是将多个输入流合并在一起。该函数返回一个 FileInput 对象。可通过 for 循环遍历这个 FileInput 对象。
fileinput 模块还提供了下面这些函数来判断正在读取的文件信息:
(1)、fileinput.filename():返回正在读取的文件的文件名。
(2)、fileinput.fileno():返回当前文件的文件描述符(file descriptor),该文件描述符是一个整数。
(3)、fileinput.lineno():返回当前读取的行号。
(4)、fileinput.filelineno():返回当前读取的行在其文件中的行号。
(5)、fileinput.isfirstline():判断当前读取的行是否为第一行。
(6)、fileinput.isstdin():返回最后一行是否从 sys.stdin 读取。可以使用 “-” 代表从 sys.stdin 读取。
(7)、fileinput.nextfile():关闭当前文件,开始读取下一个文件。
(8)、fileinput.close():关闭 FileInput 对象。
缺点:fileinput 在创建 FileInput 对象时,不能指定字符集,因此要求所读取的文件的字符集必须与操作系统默认的字符集保持一致。如果文件内容是纯英文,则不存在字符集问题。示例如下:
import fileinput
# 一次读取多个文件,返回的是 Fileinput 对象,可用 for 遍历
for line in fileinput.input(files=['a.txt', 'b.txt']):
# 输出文件名、文件描述符、当前行在当前文件中的行号、每一行的内容
print(fileinput.filename(), fileinput.fileno(), fileinput.filelineno(), line, end='')
# 关闭文件流
fileinput.close()
使用 fileinput.input() 合并后的文件,可能直接遍历读取文件内容。
4、文件迭代器
- 文件对象本身就是可遍历的,可以使用 for 循环遍历文件内容,每次读取文件的一行内容。
- 可以使用 list() 函数将文件对象转换成 list 列表,就像文件对象的 readlines() 方法的返回值一样。
- sys.stdin 也是一个类文件对象(类似于文件的对象,Python 的很多 I/O 流都是类文件对象),因此在程序中同样可以使用 for 循环遍历 sys.stdin,这意味着可以通过 for 循环来获取用户的键盘输入。
代码示例如下:
f = open('b.txt', 'r', buffering=True, encoding='utf-8')
# 直接使用 for 循环遍历文件对象,每次读取一行内容
for line in f:
print(line)
f.close()
# 使用 list 函数直接将文件对象转换成 list 列表
f2 = open('a.txt', 'r', buffering=True, encoding='utf-8')
print(list(f2))
f2.close()
import sys
# 使用 for 循环遍历用户输入,用户每输入一行,程序就会输出用户当前输入的这行
for line in sys.stdin:
print('用户输入:', line, end='')
5、管道输入
- 使用 sys.stdin 是读取的键盘输入,如果要读取的输入来自于某个命令,就要使用管道输入。
- 管道的作用:将前一个命令的输出,当成下一个命令的输入。UNIX、Windows系统都支持管道输入。
- 管道输入的语法是:
cmd1 | cmd2 | cmd3 ...,cmd1 命令的输出会传给 cmd2 命令作为输入;cmd2 命令的输出,又会传给 cmd3 命令作为输出。
代码示例如下,下面代码中(文件名是pipein_test.py)使用 sys.stdin 读取输入数据,并通过正则表达式识别其中包含多少个 E-mail 地址。
import sys
import re
# 定义匹配 E-Mail 的正则表达式
mailPattern = r'([a-z0-9]*[-_]?[a-z0-9]+)*@([a-z0-9]*[-_]?[a-z0-9]+)+'\
+ '[\.][a-z]{2,3}([\.][a-z]{2})?'
# 读取标准输入
text = sys.stdin.read()
# 使用正则表达式进行查找
it = re.finditer(mailPattern, text, re.I)
# 输出所有的电子邮件地址
for e in it:
print(str(e.span()) + "-->" + e.group())
这段代码中使用 sys.stdin 来读取标准输入的内容,并使用正则表达式匹配所读取字符串的 E-mail 地址。如果使用管道输入的方式,可以把前一个命令的输出当成 pipein_test.py 这个程序的输入。使用的命令是:
type ad.txt | python pipein_test.py
在这个命令中使用到两个命令:
(1)、type ad.txt:使用 type 命令读取 ad.txt 文件内容,并将内容输出到控制台。但由于使用了管道,因此该命令的输出会传给下一个命令。
(2)、python pipein_test.py:使用 python 命令执行 pipein_test.py 文件。由于这个命令前面有管道,因此它会把前一个命令的输出当成输入。
命令中读取的 ad.txt 文件内容如下:
编程学习资料,请发送邮件到 michael@michael.com,公限前100名。
搭建云服务请找 Stark@michael.com.cn,价格有优惠
要找工作,可以内推 Job_michael@michael.com.cn
交友,请发邮件到 Friend@python.cn
运行 type ad.txt | python pipein_test.py 命令,pipein_test.py 会把 ad.txt 文件的内容作为标准输入。运行结果如下:
(21, 40)-->michael@michael.com
(66, 86)-->Stark@michael.com.cn
(111, 137)-->Job_michael@michael.com.cn
(152, 168)-->Friend@python.cn
6、使用 with 语句
使用 with 语句可管理资源关闭。可将需要打开的文件放在 with 语句中,这样 with 语句会自动关闭文件。语法格式如下:
with context_expression [as target(s)]:
with 代码块
语法说明:
- context_expression 用于创建可自动关闭的资源。
- with 语句也可处理通过 fileinput.input 合并的多个文件。
示例如下:
# 使用 with 语句打开文件,该语句会负责关闭文件
with open('a.txt', 'r', buffering=True, encoding='utf-8') as f:
for line in f:
print(line, end='')
# 使用 with 语句可以处理通过 fileinput.input 合并的多个文件
import fileinput
with fileinput.input(files=('a.txt', 'b.txt')) as f:
for line in f:
print(line, end='')
with 语句的实现原理:使用 with 语句管理的资源必须是一个实现上下文管理协议(context manage protocol)的类,这个类的对象可被称为上下文管理器。要实现上下文管理协议,必须实现如下两个方法:
(1)、
context_manager.__enter__():进入上下文管理器自动调用的方法。该方法会在 with 代码块执行之前执行。如果有 as 子句,则该方法返回值会被赋值给 as 子句后的变量;该方法可以返回多个值,因此在 as 子句后面也可以指定多个变量(多个变量必须由“()”括起来组成元组)。(2)、
context_manager.__exit__(exec_type,exc_value,exc_traceback):退出上下文管理器自动调用的方法。该方法会在 with 代码块执行之后执行。如果 with 代码块成功执行结束,则自动调用该方法,调用该方法的三个参数都为 None;如果 with 代码块因为异常而中止,该方法也会自动调用。使用 sys.exc_info 得到的异常信息将作为调用该方法的参数。
通过上面介绍可知,只要一个类实现了 __enter__()和__exit__(exc_type, exc_value, exc_traceback)方法,就可以使用 with 语句来管理它;通过 __exit__()方法的参数,即可判断出 with 代码块执行时是否遇到了异常。
换句话说,就是上面的代码中所用的文件对象、FileInput 对象,其实都实现了这两个方法,因此它们可以接受 with 语句的管理。下面代码自定义一个实现上下文管理功能的类,并使用 with 语句来管理它:
class MyResource:
def __init__(self, tag):
self.tag = tag
print('构造器,初始化资源:%s' % tag)
# 定义 __enter__ 方法,它是在 with 代码块执行之前执行的方法
def __enter__(self):
print('[__enter__ %s]:' % self.tag)
# 该返回值将作为 as 子句后的变量的值
return 'mypy' # 可以返回任意类型的值
# 定义__exit__方法,它是在 with 代码块执行之后执行的方法
def __exit__(self, exc_type, exc_val, exc_tb):
print('[__exit__ %s]:' % self.tag)
# exc_tb 为 None 代表没有异常
if exc_tb is None:
print('没有异常时关闭资源')
else:
print('遇到异常时关闭资源')
return False # 可以省略,默认返回 None,也被看作是 False
with MyResource('helloworld') as hw:
print(hw)
print('[with 代码块] 没有异常')
print('-' * 30)
with MyResource('hellopython'):
print('[with代码块] 异常之前的代码')
raise Exception
print('[with代码块] ======== 异常之后的代码')
运行结果如下所示:
构造器,初始化资源:helloworld
[__enter__ helloworld]:
mypy
[with 代码块] 没有异常
[__exit__ helloworld]:
没有异常时关闭资源
------------------------------
构造器,初始化资源:hellopython
[__enter__ hellopython]:
[with代码块] 异常之前的代码
[__exit__ hellopython]:
遇到异常时关闭资源
Traceback (most recent call last):
File "with_theory.py", line 27, in <module>
raise Exception
Exception
- 上面代码定义的 MyResource 类中定义了
__enter__()和__exit__()两个方法,有了这两个方法,该类的对象可以被 with 语句管理。 - 在执行 with 代码块前,会执行
__enter__()方法,并将该方法的返回值赋值给 as 子句后的变量。 - 在执行 with 代码块之后,会执行
__exit__()方法,可根据这个方法的参数来判断 with 代码块是否有异常。 - 在这段代码中,两次使用 with 语句管理 MyResource 对象,其中第一次的 with 代码块没有异常;第二次的 with 代码块出现了异常。两次使用 with 语句对 MyResource 的管理略有差异,主要是在
__exit__()方法中略有差异。 - 从输出结果可以看出,在进入 with 代码块之前总是会执行
__enter__()方法,无论 with 代码块是否有异常,这个部分都是一样的,而且__enter__()方法返回值被赋值给了 as 子句的的变量。 - 对 with 代码块有异常和无异常这两种情况,可通过
__exit__()方法的参数进行判断,在该方法中可针对是否有异常进行分别的处理。
7、使用 linecache 随机读取指定行
- linecache 模块用于读取 Python 源文件中随机指定行,并在内部使用缓存优化存储,使用 UTF-8 字符集读取文件。
- linecache 模块也可读取其他文件,只要该文件使用了 UTF-8 字符集存储。
linecache 模块包含的常用函数如下:
(1)、linecache.getline(filename, lineno, module_globals=None):读取指定模块中指定文件的指定行。filename 参数指定文件,lineno 参数指定行号。
(2)、linecache.clearcache():清空缓存。
(3)、linecache.checkcache(filename=None):检查缓存是否有效。没有指定 filename 参数,则默认检查所有缓存的数据。
linecache 模块的代码示例如下:
import linecache
import random
# 读取random 模块源文件的第 10 行
print(linecache.getline(random.__file__, 10))
# 读取 ad.txt 文件的第3行
print(linecache.getline('ad.txt', 3))
# 读取 Python 源文件 pipein_test.py 的第9行
print(linecache.getline('pipein_test.py', 9))
四、写文件
- 以 r+、w、w+、a、a+模式打开文件,都可以写入。
- 当以 r+、w、w+模式打开文件时,文件指针位于文件开始处;以 a、a+模式打开的文件,文件指针位于文件结尾处。
- 当以w、w+模式打开已有文件时,已有文件的内容会被清空。
1、文件指针概念
- 文件指针用于标明文件读写的位置。
- 文件对象用于操作文件指针的方法有下面两个:
(1)、seek(offset[, whence]):该方法把文件指针移动到指定位置。whence 的默认值是 0,表明从文件开头开始计算,比如将 offset 设为 3,就是将文件指针移动到第 3 处;当 whence 为 1 时,表明从指针当前位置开始计算,比如文件指针当前在第 5 处,将 offset 设为 3,就是将文件指针移到第 8 处;当 whence 为 2时,表明从文件结尾开始计算,比如将 offset 设为 -3,表明将文件指针移动到文件结尾倒数第 3 处。
(2)、tell():判断文件指针的位置。
- 当使用文件对象读写数据时,文件指针会自动向后移动:读写了多少个数据,文件指针就自动向后移动多少个位置。
文件指针操作代码示例如下:
f = open('ad.txt', 'rb')
# 判断文件指针的位置
print(f.tell()) # 0
# 将文件指针移动到第 3 处
f.seek(3)
print(f.tell()) # 3
# 读取一个字节,文件指针自动后移 1 个数据
print(f.read(1)) # b'\xe7'
print(f.tell()) # 4
# 将文件指针移动到第 5 处
f.seek(5)
print(f.tell()) # 5
# 将文件指针从当前位置向后移动 5 个数据
f.seek(5, 1)
print(f.tell()) # 10
# 将文件指针移动到倒数第10处
f.seek(-10, 2)
print(f.tell()) # 231
print(f.read(1)) # b'@'
上面代码中使用 seek() 方法移动文件指针,包括从文件开头、指针当前位置、文件结尾处开始计算。运行这段代码,可以从输出结果中体会到文件指针移动的效果。当文件指针位于哪里时,就会读取哪个位置的数据;当读取多少个数据,文件指针就会自动向后移动多少个位置。
2、输出文件内容
文件对象主要有两个用于写文件的方法,分别是:write() 和 writelines()。
- write(str or bytes):输出字符串或字节串(以b模式打开的文件)到文件。
- writelines(可迭代对象):输出多个字符串或多个字节串。
关于之两个方法的使用示例如下:
import os
f = open('x.txt', 'w+')
# os.linesep代表当前操作系统上的换行符
f.write('游子吟' + os.linesep)
f.writelines(('慈母手中线,游子身上衣。' + os.linesep,
'临行密密缝,意恐迟迟归。' + os.linesep,
'谁言寸草心,报得三春晖。' + os.linesep))
这段代码在打开文件时没有指定字符集,默认使用当前操作系统的字符集。open() 函数可以使用 encoding='utf-8'来指定字符集。如果要使用指定字符集来输出文件,则可以采用二进制形式(先将所输出的字符串转换成指定字符集对应的二进制数据(字节串)),然后输出周末进制数据。下面代码使用 UTF-8 字符集保存文件:
import os
f = open('y.txt', 'wb+')
# os.linesep代表当前操作系统上的换行符
f.write(('游子吟' + os.linesep).encode('utf-8'))
f.writelines((('慈母手中线,游子身上衣。' + os.linesep).encode('utf-8'),
('临行密密缝,意恐迟迟归。' + os.linesep).encode('utf-8'),
('谁言寸草心,报得三春晖。' + os.linesep).encode('utf-8')))
上面这段代码使用 wb+ 模式打开文件,则要求以二进制形式输出到文件,此时,输出的必须是字节串,不能是字符串。在接下来的代码中,调用 encode() 方法将字符串转换成字符串,转换时指定使用 UTF-8 字符集。
五、os模块中与文件和目录操作相关的函数
- os模块下也有大量操作文件和目录的函数。官方说明文档是 https://docs.python.org/3/library/os.html。
1、与目录相关的函数
- os.getcwd():获取当前目录。
- os.chdir(path):改变当前目录。
- os.fchdir(fd):通过文件描述符改变当前目录。与上一个函数功能基本相同,只是这个函数多了一个文件描述符。
- os.chroot(path):改变当前进程的根目录。
- os.listdir(path):返回 path 对应目录下的所有文件和子目录。
- os.mkdir(path[,mode]):创建 path 对应的目录,其中 mode 用于指定该目录的权限。mode 参数代表一个 UNIX 风格的权限,比如 0o777 代表所有者、组用户、其他用户均可读/可写/可执行。
- os.makedirs(path[,mode]):可以递归创建目录。比如创建 abc/xyz/python 目录,会先创建 abc,再创建 xyz 子目录,最后创建 python 子目录。mode 参数同上。
关于mkdir() 和 makedirs() 方法的简单示例如下:
import os
path = 'my_dir'
# 使用 mkdir() 方法直接在当前目录下创建子目录
os.mkdir(path, 0o755)
path = 'abc/xyz/michael'
# 使用 makedirs() 方法递归创建目录
os.makedirs(path, 0o755)
- os.rmdir(path):删除 path 对应的空目录。如果目录不为空,则抛出一个 OSError 异常。可先用 os.remove() 函数删除文件。
- os.removedirs(path):递归删除目录。例如递归删除 abc/xyz/python 目录,它会从 python 目录开始删除,然后删除 xyz 子目录,最后删除 abc 目录。
- os.rename(src, dst):重命名文件或目录,将 src 文件重名为 dst 文件。
- os.renames(old, new):对文件或目录进行递归重命名。例如递归重命名 abc/xyz/python 目录,会从 python 子目录开始重命名,然后重命名 xyz 子目录,最后重命名 abc 子目录。
2、与权限相关的函数
- os.access(path, mode):检查 path 对应的文件或目录是否具有mode指定的权限。mode 参数下面四个状态中的一个或多个值。
os.F_OK:判断是否存在。
os.R_OK:判断是否可读。
os.W_OK:判断是否可写。
os.X_OK:判断是否可执行。
示例如下:
import os
# 判断当前目录的权限
ret = os.access('.', os.F_OK|os.R_OK|os.W_OK|os.X_OK)
print('os.F_OK|os.R_OK|os.W_OK|os.X_OK - 返回值:', ret)
# 判断 os_access_test.py 文件的权限
ret = os.access('os_access_test.py', os.F_OK|os.R_OK|os.W_OK)
print('os.F_OK|os.R_OK|os.W_OK - 返回值:', ret)
- os.chmod(path, mode):更改权限。mode 参数代表要改变的权限,该参数的值可以是以下一个或多个值的组合,需要先导入 stat 模块。
stat.S_IXOTH:其他用户有执行权限。
stat.S_IWOTH:其他用户有写权限
stat.S_IROTH:其他用户有读权限。
stat.S_IRWXO:其他用户有全部权限
stat.S_IXGRP:组用户有执行权限。
stat.S__IWGRP:组用户有写权限。
stat.S_IRGRP:组用户有读权限。
stat.S_IRWXG:组用户有全部权限。
stat.S_IXUSR:所有者有执行权限。
stat.S_IWUSR:所有者有写权限。
stat.S_IRUSR:所有者有读权限。
stat.S_IRWXU:所有者有全部权限。
stat.S_IREAD:Windows 将该文件设为只读。
stat.S_IWRITE:Windows将该文件设为可写的。
上面这些权限,除后面两个,其他权限都是 UNIX 文件系统下有效。代码示例如下:
import os, stat
# 将 os_chmode_test.py 文件改为只读的
os.chmod('os_chmode_test.py', stat.S_IREAD)
# 判断是否可写
ret = os.access('os_chmode_test.py', os.W_OK)
print("os.W_OK - 返回值:", ret) # 输出:False
- os.chown(path, uid, gid):更改文件的所有者。其中 uid 代表用户 id,gid 代表组 id。该命名主要在UNIX系统下有效。
- os.fchmod(fd, mode):改变一个文件的访问权限,该文件由文件描述符 fd 指定。该函数的功能与 os.chmod() 相似,只是该函数使用 fd 代表文件。
- os.fchown(fd, uid, gid):改变文件的所有者,该文件由文件描述符 fd 指定,函数功能与 os.chown() 相似。
3、与文件访问相关的函数
- os.open(file, flags[, mode]):打开一个文件,并且设置打开选项,mode 参数可选。返回文件描述符。flags代表打开文件的旗标,可以是下面选项中的一个或多个:
os.O_RDONLY:以只读的方式打开。
os.O_WRONLY:以只写的方式打开。
os.O_RDWR:以读写的方式打开。
os.O_NONBLOCK:打开时不阻塞。
os.O_APPEND:以追加的方式打开。
os.O_CREAT:创建并打开一个新文件。
os.O_TRUNC:打开一个文件并截断它的长度为0(必须有写权限)。
os.O_EXCL:在创建文件时,如果指定的文件存在,则返回错误。
os.O_SHLOCK:自动获取共享锁。
os.O_EXLOCK:自动获取独立锁。
os.O_DIRECT:消除或减少缓存效果。
os.O_FSYNC:同步写入。
os.O_NOFOLLOW:不追踪软链接。
- os.read(fd, n):从文件描述符 fd 中读取最多 n 个字节,返回读到的字节串。如果文件描述符 fd 对应的文件已达到结尾,则返回一个空字符串。
- os.write(fd, str):将字节串写入文件描述符 fd 中,返回实际写入的字节串长度。
- os.close(fd):关闭文件描述符 fd。
- os.lseek(fd, pos, how):移动文件指针。其中 how 参数指定从哪里开始移动,如果 how 设为 0 或 SEEK_SET,则表明从文件起始处开始移动;如果 how 设为 1 或 SEEK_CUR ,则表明从文件指针当前位置开始移动;如果将 how 设为 2 或 SEEK_END,则表明从文件结束处开始移动。
关于上面几个函数的代码示例如下:
import os
# 以读写、创建的方式打开
f = os.open('abc.txt', os.O_RDWR|os.O_CREAT)
# 写入文件内容,返回值是实际写入字符串的长度
len1 = os.write(f, '孤帆远影碧空尽,\n'.encode('utf-8'))
len2 = os.write(f, '烟花三月下扬州。\n'.encode('utf-8'))
# 将文件指针移动到开始处
os.lseek(f, 0, os.SEEK_SET)
# 读取文件内容
data = os.read(f, len1 + len2)
# 打印读取到的字节串
print(data)
# 将字节串恢复成字符串
print(data.decode('utf-8'))
os.close(f)
- os.fdopen(fd[, mode[, bufsize]]):通过文件描述符 fd 打开文件,并返回对应的对象。
- os.closerange(fd_low, fd_high):关闭从 fd_low(包含)到fd_high(不包含)范围的所有文件描述。
- os.dup(fd):复制文件描述符。
- os.dup2(fd, fd2):将一个文件描述符 fd 复制到另一个文件描述符 fd2 中。
- os.ftruncate(fd, length):将 fd 对应的文件截断到 length 长度,因此 length 参数不应该超过文件大小。
- os.remove(path):删除 path 对应的文件。如果 path 是一个文件夹,则抛出 OSError 错误。删除目录用 os.rmdir()。
- os.link(src, dst):创建从 src 到 dst 的硬链接。硬链接是 UNIX 系统的概念,如果在 Windows 系统中就是复制目标文件。
- os.symlink(src, dst):创建从 src 到 dst 的符号链接,对应于 Windows 的快捷方式。在Windows中需要管理员权限。
关于 os.link() 和 os.symlink() 的用法示例如下:
import os
# 为 abc.txt 文件创建快捷方式
os.symlink('abc.txt', 'tt')
# 为 abc.txt 文件创建硬链接(在Windows系统中就是复制文件)
os.link('abc.txt', 'dst') # 将文件 abc.txt 复制为 dst 文件
六、使用 tempfile 模块生成临时文件和临时目录
该模块专用于创建临时文件和临时目录,可在 UNIX 和 Windows 平台上运行良好。该模块提供的常用函数有:
- tempfile.TemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None):创建临时文件。该函数返回一个类文件对象,也就是支持文件I/O。
- tempfile.NamedTemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None, delete=True):创建临时文件。该函数功能与上一个大致相同,只是它生成的临时文件在文件系统中有文件名。
- tempfile.SpooledTemporaryFile(max_size=0, mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None):创建临时文件。与 TemporaryFile 函数相比,当程序向该临时文件输出数据时,会先输出到内存中,直到超过 max_size 才会真正输出到物理磁盘中。
- tempfile.TemporaryDirectory(suffix=None, prefix=None, dir=None):生成临时目录。
- tempfile.gettempdir():获取系统的临时目录。
- tempfile.gettempdirb():与gettempdir()相同,只是该函数返回字节串。
- tempfile.gettempprefix():返回用于生成临时文件的前缀名。
- tempfile.gettempprefixb():与 gettempprefix() 相同,只是该函数返回字节串。
- tempfile 模块还提供了 tempfile.tempdir 属性,对该属性赋值可改变系统的临时目录。
tempfile 模块还提供有 tempfile.mkstemp() 和 tempfile.mkdtemp() 两个低级别的函数。上面4个用于创建临时文件和临时目录的函数都是高级别的函数,高级别的函数支持自动清理,而且可以与 with 语句一起使用。而这两个低级别的函数则不支持,因此推荐使用高级别的函数来创建临时文件和临时目录。
关于使用临时文件和临时目录的代码如下:
import tempfile
# 创建临时文件
fp = tempfile.TemporaryFile()
# 输出临时文件名称
print(fp.name)
fp.write('梅子金黄杏子肥,'.encode('utf-8'))
fp.write('麦花雪白菜花稀。'.encode('utf-8'))
# 将文件指针移动开始处,准备读取文件
fp.seek(0)
print(fp.read().decode('utf-8')) # 输出刚才写入的内容
# 关闭文件,该文件会被自动删除
fp.close()
# 通过 with 语句创建临时文件,with 会自动关闭临时文件
with tempfile.TemporaryFile() as fp:
# 写入内容
fp.write(b'I Love Python')
# 将文件指针移动开始处,准备读取文件
fp.seek(0)
# 读取文件内容
print(fp.read()) # b'I Love Python'
# 通过 with 语句创建临时目录
with tempfile.TemporaryDirectory() as tmpdirname:
print('创建临时目录', tmpdirname)
上面代码中使用了两种方式创建临时文件:
- 第一种方式是手动创建临时文件,读写完临时文件后需要手动关闭。关闭临时文件就会自动被删除。
- 第二种方式是使用 with 语句创建临时文件,with 语句会在使用完后自动关闭临时文件。
上面代码中还使用了 with 语句创建临时目录,同样在使用完也会自动删除该临时目录。运行上面代码,输出结果如下:
C:\Users\mm\AppData\Local\Temp\tmp04mygwji
梅子金黄杏子肥,麦花雪白菜花稀。
b'I Love Python'
创建临时目录 C:\Users\mm\AppData\Local\Temp\tmpi33oa_v4
上面的输出结果中,第一行是程序生成的临时文件的文件名,最后一行是程序生成的临时目录的目录名。不要尝试去找这些临时文件或文件夹,在程序退出后,这些临时文件或临时文件夹都会被删除。
七、小结
- 本节主要是与 Python I/O相关的知识,包括如何管理目录和文件;
- 使用 pathlib 和 os.path 两个模块操作目录的该当;
- 使用 fnmatch 模块处理文件名匹配的方法。
- 文件读写通过全局 open() 函数,打开文件时可指定不同的模式,通过不同的模式能以二进制文件和文本文件的方式来打开文件,既可打开文件进行读写,也可进行追加。
- 打开的文件能以多种方式读取,有按字节/字符读取、按行读取、使用fileinput读取、使用文件迭代器读取,还可直接使用 inecache 读取。
- 写入文件内容可使用 write() 方法输出单独的字符串或字节串,也可使用 writelines() 方法批量输出多个字节串和字符串。
- os 模块有大量与 I/O相关的函数与方法来操作文件和目录。
- tempfile 模块用来创建临时文件和临时目录,临时文件和临时目录使用完就会自动被删除。
八、练习
1、现有两个文件 text1.txt 和 text2.txt 各存放一行英文字母,要求把这两个文件中信息合并(按字母顺序排列),最后输出到一个新文件 text3.txt 中。
with open('text1.txt', 'r') as f1:
text1 = f1.read()
with open('text2.txt', 'r') as f2:
text2 = f2.read()
text3 = list(text1) + list(text2)
text3.sort()
with open('text3.txt', 'w+') as f3:
f3.write("".join(text3))
2、揭示用户不断输入多行内容,并自动将内容保存到 my.txt 文件中,直到用户输入 exit 为止。
import os, sys
print("请开始逐行输入内容:")
f = open('my.txt', 'w+', encoding='utf-8')
while True:
string = input()
if string == 'exit':
sys.exit(0)
f.colse()
f.write(string + os.linesep)
3、实现一个程序,提示用户输入一个文件路径,程序读取这个可能包含手机号码的文本文件(该文件可能点大),要求程序能识别出该文本文件中所有的手机号码,并将这些手机号码保存到 phone.txt 文件中。
import re, os, sys, codecs
from pathlib import *
phone_pattern = '1[358][0-9]\d{8}|14[579]\d{8}|16[6]\d{8}|17[0135678]\d{8}|19[0189]\d{8}'
dir_str = input('请输入文件路径:').strip()
p = Path(dir_str) # 注意数字路径会转换为无效路径
if not p.exists() or not p.is_file():
raise ValueError('您输入的不是有效的文件')
def read_phones(f, wf):
while True:
line = f.readline()
# 如果没有讲到数据,跳出循环
if not line: break
phone_list = re.findall(phone_pattern, line)
for x in phone_list:
wf.write(x + '\n')
f.close()
with open('phone.txt', 'w+', encoding='utf-8') as wf:
# 目标文件内容可能很大,需要逐行读取,可用gbk和utf-8两种字符集读取
try:
f = codecs.open(dir_str, 'r', 'utf-8', buffering=True)
read_phones(f, wf)
except:
try:
f = codecs.open(dir_str, 'r', 'gbk', buffering=True)
read_phones(f, wf)
except:
print('该文件不是文本文件')
sys.exit(0)
4、实现一个程序,提示用户输入一个目录,程序中递归读取该目录及子目录下所有能识别的文本文件,要求程序能识别出所有文件中的所有手机号码,并将手机号码保存到 phones.txt 文件中。
import os, re
from pathlib import *
phone_pattern = '1[358][0-9]\d{8}|14[579]\d{8}|16[6]\d{8}|17[0135678]\d{8}|19[0189]\d{8}'
f = open('phones.txt', 'w+', encoding='utf-8')
def process_dir(p):
for x in p.iterdir():
if Path(x).is_dir():
process_dir(Path(x))
else:
try:
content = Path(x).read_text(encoding='utf-8')
phone_list = re.findall(phone_pattern, content)
for x in phone_list:
f.write(x + '\n')
except:
try:
content = Path(x).read_text(encoding='GBK')
phone_list = re.findall(phone_pattern, content)
for x in phone_list:
f.write(x + '\n')
except:
pass
dir_str = input('请输入路径:').strip()
p = Path(dir_str)
if not p.exists() or not p.is_dir():
raise ValueError('您输入的不是有效的路径')
process_dir(p)
f.close()
5、实现一个程序,提示用户输入一个路径,程序将该路径下(及其子目录下)的所有文件列出来。
from pathlib import *
def process_dir(p):
for x in p.iterdir():
if Path(x).is_dir():
process_dir(x)
else:
print(x)
dir_str = input("请输入一个路径:")
p = Path(dir_str)
# 需要先判断路径是否有效,无效则引发异常并退出程序
if not p.exists() or not p.is_dir():
ValueError("您输入的不是有效路径")
process_dir(p)
6、实现一个程序,提示用户输入一个路径。程序统计该路径下的文件、文件夹的数量。
from pathlib import *
def process_dir(p):
dir_count = file_count = 0
for x in p.iterdir():
if Path(x).is_dir():
dir_count += 1
else:
file_count += 1
return dir_count, file_count
dir_str = input('请输入路径:')
p = Path(dir_str) # 将路径转换为可识别的路径
# 接下来判断路径是否存在、是否是目录
if not p.exists() or not p.is_dir():
ValueError('您输入的不是效的路径')
# 通过路径检测,接下来就统计路径中的文件及文件夹数量
dir_count, file_count = process_dir(p)
print('%s目录下有%d个文件' % (dir_str, file_count))
print('%s目录下有%d个文件夹' % (dir_str, dir_count))
7、编写一个命令行工具,这个命令行工具就像 Windows 提供的 cmd 命令一样,可以执行各种常见的命令,如 dir、md、copy、move等。
import sys, os, shutil
from pathlib import *
while True:
# 获取命令行输入
cmd = input('%s>' % Path('.').resolve())
# cmd = input('%s>' % Path('.').resolve().strip()) # UNIX平台用这条语句
if cmd == 'exit':
sys.exit(0)
elif cmd.startswith('dir'):
params = cmd.split()
if len(params) == 1:
for filename in os.listdir(r'.'):
print(filename)
elif len(params) == 2:
for filename in os.listdir(params[1]):
print(filename)
else:
print('dir命令格式不正确,正确格式为:dif [路径]')
elif cmd.startswith('cd'):
params = cmd.split()
if len(params) == 1:
os.chdir(os.path.expanduser('~'))
elif len(params) == 2 and Path(params[1]).is_dir():
os.chdir(params[1])
else:
print('cd命令格式不正确,正确格式为:cd [路径]')
elif cmd.startswith('md'):
params = cmd.split()
if len(params) < 2:
print('md命令格式不正确,正确格式为:md <路径1> [路径2] ...')
else:
for i in range(1, len(params)):
os.mkdir(params[i])
elif cmd.startswith('copy'):
params = cmd.split()
if len(params) != 3 or (not Path(params[1]).is_file()) or (not Path(params[2]).is_dir()):
print('copy命令格式不正确,正确格式为:copy <文件> <路径>')
else:
shutil.copy(params[1], params[2])
elif cmd.startswith('move'):
params = cmd.split()
if len(params) != 3 or (not Path(params[1]).is_file()) or (not Path(params[2]).is_dir()):
print('move命令格式不正确,正确格式为:move <文件> <路径>')
else:
shutil.move(params[1], params[2])
else:
print('无效命令')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号