part10-2 Python常见模块(random模块、time模块、JSON模块)
三、 random 模块
random 模块的各种变量和函数主要用于生成伪随机数。在 Python 交互式解释器中导入 random 模块,可使用 random.__all__ 命令查看该模块的公开接口,这些接口是该模块包含的全部属性和函数。
>>> random.__all__
['Random', 'seed', 'random', 'uniform', 'randint', 'choice', 'sample', 'randrange', 'shuffle', 'normalvariate',
'lognormvariate', 'expovariate', 'vonmisesvariate', 'gammavariate', 'triangular', 'gauss', 'betavariate',
'paretovariate', 'weibullvariate', 'getstate', 'setstate', 'getrandbits', 'choices', 'SystemRandom']
这些属性和函数的含义不用强记,官方参考网站是 https://docs.python.org/3/library/random.html。常用函数如下:
(1)、random.seed(a=None,version=2):指定种子来初始化伪随机数生成器。
(2)、random.randrange(start,stop[,step]):返回从 start 开始到 stop 结束、步长为 step 的随机数。与choice(range(start,stop,step))的效果一样,只不过实际在底层并不生成区间对象。
(3)、random.randint(a,b):生成一个范围在 a<=N<=b 的随机数。等同于 randrange(a,b+1)的效果。
(4)、random.choice(seq):从 seq 中随机抽取一个元素,如果 seq 为空,则引发 IndexError 异常。
(5)、random.choices(seq,weights=None,*,cum_weights=None,k=1):从 seq 序列中抽取 k 个元素,还可通过 weights 指定各元素被抽取的权重(代表被抽取的可能性高低)。
(6)、random.shuffle(x[,random]):对 x 序列执行洗牌“随机排列”操作。
(7)、random.sample(population,k):从 population 序列中随机抽取 k 个独立的元素。
(8)、random.random():生成一个从 0.0(包含)到 1.0(不包含)之间的伪随机浮点数。
(9)、random.uniform(a,b):生成一个范围为 a<=N<=b 的随机数。
(10)、random.expovariate(lambd):生成呈指数分布的随机数。其中 lambd 参数(实际应该是lambda,只是lambda是Python关键字,所以简写成lambd)为1除以期望平均值。如果 lambd 是正值,则返回的随机数是从 0 到正无穷大;如果 lambd 是负值,则返回的随机数是从负无穷大到 0。
此外,random 模块还有 random.triangular(low,high,mode)、random.gauss(mu,sigma)等函数,用于生成呈对称分布、高斯分布的随机数,这些函数需要一些数学知识来理解,平时用得不多。
下面是 random 模块的常用函数的功能和用法。
import random # 生成范围为 0.0<=x<1.0 的伪随机浮点数 print(random.random()) # 生成范围为 2.5<=x<10.0 的伪随机浮点数 print(random.uniform(2.5, 10.0)) # 生成呈指数分布的伪随机浮点数 print(random.expovariate(1 / 5)) # 生成从 0 到 33 的伪随机整数 print(random.randrange(34)) # 生成从 0 到 100 的随机偶数 print(random.randrange(0, 101, 2)) # 随机抽取一个元素 print(random.choice(['python', 'linux', 'michael', 'stark'])) book_list = ['python', 'linux', 'java', 'html'] # 对列表元素进行随机排列 random.shuffle(book_list) print(book_list) # 随机抽取 4 个独立元素 print(random.sample([10, 20, 30, 40, 50, 60], k=4)) 运行程序,输出结果如下: 0.9460895371013778 4.026276430084499 8.989374079499285 16 34 stark ['html', 'java', 'python', 'linux'] [60, 20, 50, 40]
random 模块可以做一些有趣的事情,示例如下:
import random
import collections
# 指定随机抽取 6 个元素,各元素被抽取的权重(概率)不同
print(random.choices(['python', 'linux', 'html'], [6, 5, 1], k=6))
# 模拟从52张扑克牌中抽取20张
# 在抽取的 20 张牌中,牌面为 10 (包括J、Q、K)的牌占多的比例
# 生成一个 16 个 tens(代表10)和36个 low_cards(代表其他牌)的集合
deck = collections.Counter(tens=16, low_cards=36)
# 从52张牌中随机抽取 20 张
seen = random.sample(list(deck.elements()), k=20)
# 统计 tens 元素有多少个,再除以 20
print(seen.count('tens') / 20)
运行程序,输出信息如下所示:
['linux', 'python', 'python', 'linux', 'linux', 'python']
0.4
从输出可知,抽取的6个元素中,html 因为权重太低,完全没有被抽取到。
四、 time 模块
time 模块提供了日期、时间功能的类和函数。该模块有把日期、时间格式化为字符串的功能,也有从字符串恢复日期、时间的功能。在Python 交互式解释器中先导入 time 模块,使用列表解析式过滤下划线的模块,示例如下:
>>> import time
>>> [e for e in dir(time) if not e.startswith("_")]
['altzone', 'asctime', 'clock', 'ctime', 'daylight', 'get_clock_info', 'gmtime', 'localtime', 'mktime',
'monotonic', 'perf_counter', 'process_time', 'sleep', 'strftime', 'strptime', 'struct_time', 'time',
'timezone', 'tzname']
在 time 模块内有一个 time.struct_time 类,该类代表一个时间对象,主要有9个属性,每个属性的信息如下所示:

例如可以用 time.struct_time(tm_year=2019, tm_mon=11, tm_day=11, tm_hour=15, tm_min=10, tm_sec=33, tm_wday=0, tm_yday=315, tm_isdst=0) 清楚的代表时间。此外还可用一个包含9个元素的元组来代表时间,该元组的9个元素和 struct_time 对象中 9 个属性的含义是一一对应的。比如用 (2019,11,11,15,10,33,1,1,0) 来清楚的代表时间。time 模块的常用功能函数如下:
(1)、time.asctime([t]):将时间元组或 struct_time 转换为时间字符串。如果不指定参数 t,则默认转换当前时间。
(2)、time.ctime([secs]):将以秒数代表的时间转换为时间字符串。
这里要注意的是:Python 的时间从 1970 年1月1日0点整到现在所经过的秒数来代表当前时间。比如写30秒,就意味着时间是1970年1月1日0点30秒。在实际输出的时候还会受到时区的影响,比如我国处于东八区,因此实际上会输出1970年1月1日8点0分30秒。
(3)、time.gmtime([secs]):将以秒数代表的时间转换为 struct_time 对象。如果不传入参数,则使用当前时间。
(4)、time.localtime([secs]):将以秒数代表的时间转换为代表当前时间的 struct_time 对象。如果不传入参数,则使用当前时间。
(5)、time.mktime(t):它是 localtime 的反转函数,用于将 struct_time 对象或元组代表的时间转换为从1970年1月1日0点整到现在过了多少秒。
(6)、time.perf_counter():返回性能计数器的值。以秒为单位。
(7)、time.process_time():返回当前进程使用 CPU 的时间。以秒为单位。
(8)、time.sleep(secs):暂停 secs 秒,什么都不做。
(9)、time.strftime(format[,t]):将参数 t 代表的时间元组或 struct_time 对象按照 format 格式转化为时间字符串。如果不指定参数 t,则默认转换当前时间。
(10)、time.strptime(string[,format]):将 format 格式的 string 时间字符串解析成 struct_time 对象。如果不指定参数 format,则要求 string 字符串的格式要与 '%a %b %d %H:%M:%S %Y' 格式相匹配。
(11)、time.time():返回从 1970年1月1日0点整到现在经过了多少秒。
(12)、time.timezone:返回本地时区的时间偏移,以秒为单位。
(13)、time.tzname:返回本地时区的名字。
time 模块的常用功能函数示例如下:
import time
# 将当前时间转换时间字符串
print(time.asctime()) # 不传入参数,默认是当前时间
# 将指定时间转换为时间字符串,时间元组的后面3个元素没有设置
print(time.asctime((2019, 11, 12, 10, 18, 22, 0, 0, 0)))
# 将以秒数为代表的时间转换为时间字符串,默认是从1970年1月1日0点开始
print(time.ctime(50)) # Thu Jan 1 08:00:50 1970
# 将以秒数为代表的时间转换为 struct_time 对象
print(time.gmtime(50))
# 将当前时间转换为 struct_time 对象
print(time.gmtime())
# 将以秒数代表的时间转换为代表当前时间的 struct_time 对象
print(time.localtime(50))
# 将元组格式的时间转换为以秒数代表的时间
print(time.mktime((2019, 11, 12, 10, 20, 31, 0, 0, 0))) # 1573525231.0
# 返回性能计数器的值
print(time.perf_counter()) # 4e-07
# 返回当前进程使用 CPU 的时间
print(time.process_time()) # 0.40625
# 当前程序暂停 3 秒
time.sleep(3)
# 将当前时间转换为指定格式的字符串
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2019-11-12 09:27:44
st = '2019年11月12日'
# 将指定时间字符串转换(或恢复)成 struct_time 对象
print(time.strptime(st, '%Y年%m月%d日')) # 格式化字符串要与时间字符串格式相匹配
# 查看从1970年1月1日0点开始到现在经过了多少秒
print(time.time()) # 1573522064.3641815
# 返回本地时区的时间偏移,以秒为单位
print(time.timezone) # 我国在东八区输出是 -28800,-28800 / 3600 = -8,相差8小时
运行上面代码,输出如下结果:
Tue Nov 12 09:27:41 2019
Mon Nov 12 10:18:22 2019
Thu Jan 1 08:00:50 1970
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=50, tm_wday=3, tm_yday=1, tm_isdst=0)
time.struct_time(tm_year=2019, tm_mon=11, tm_mday=12, tm_hour=1, tm_min=27, tm_sec=41, tm_wday=1, tm_yday=316, tm_isdst=0)
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=8, tm_min=0, tm_sec=50, tm_wday=3, tm_yday=1, tm_isdst=0)
1573525231.0
4e-07
0.40625
2019-11-12 09:27:44
time.struct_time(tm_year=2019, tm_mon=11, tm_mday=12, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=316, tm_isdst=-1)
1573522064.3641815
-28800
在 time 模块中的 strftime() 和 strptime() 两个函数是互为逆函数,其中 strftime() 是将 struct_time 对象或时间元组转换为时间字符串;strptime() 是将时间字符串转换为 struct_time 对象。在实际应用中,可使用 localtime() 获取当前时间,再将当前时间以参数形式传递给 strftime() 函数的第二个参数,将按照该函数的第一个参数格式转换为时间字符串。另外,这两个函数都需要编写格式模板,在 Python 中时间格式字符串的指令有:
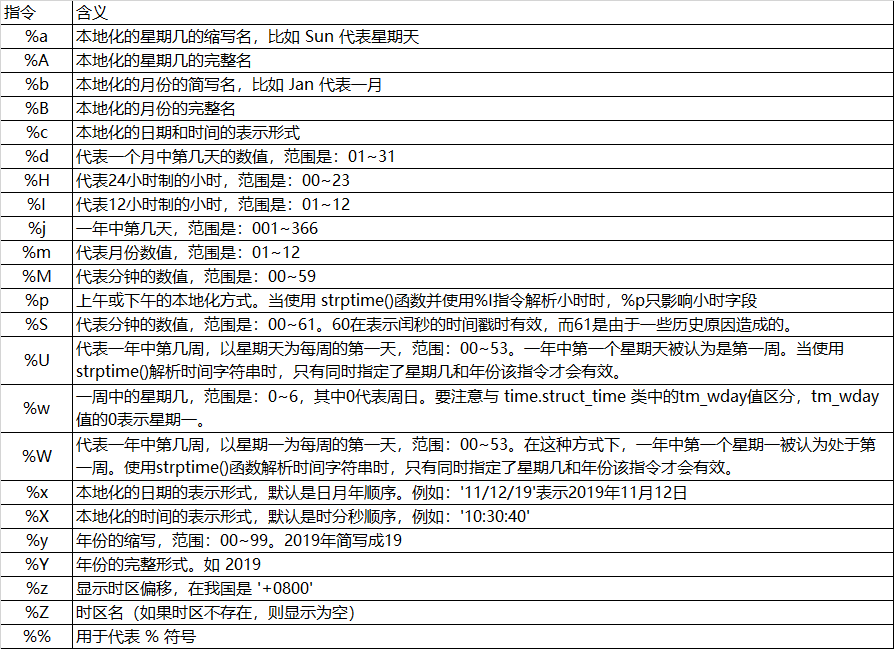
五、 JSON 支持
JSON 是一种轻量级、跨平台、跨语言的数据交换格式,JSON 格式被广泛应用于各种语言的数据交换中。
1、 JSON 基本知识
JSON 全称是 JavaScript Object Notation,即 JavaScript 对象符号,是一种轻量级的数据交换格式。JSON 格式的数据即适合人阅读,也适合计算机解析和生成。早期,JSON 是 JavaScript 语言的数据交换格式,后来发展成一种与语言无关的数据交换格式,这一点非常类似 XML。
JSON 在C、C++、C#、Java、JavaScript、Perl、Python等编程语言中使用广泛。JSON 提供了在多种语言之间完成数据交换的能力,因此,JSON 是一种非常理想的数据交换格式。JSON 有两种主要的数据结构:
(1)、由 key-value 对组成的数据结构。这种数据结构在不同的语言中不同的实现。例如,在 JavaScript 中是一个对象;在 Python 中是一种 dict 对象;在 C 语言中是一个 struct;在其他语言中可能是 record、dictionary、hash table等。
(2)、有序集合。这种数据结构在 Python 中对应于列表;在其他语言中,可能对应于 list、vector、数组和序列等。
这两种数据在不同的语言中都有对应实现,因此这种简便的数据表示方式可以实现跨语言。所以,JSON 可以作为程序设计语言中通用的
数据交换格式。在 JavaScript 中有两种语法,一种用于创建对象;另一种用于创建数组。
1.1 使用 JSON 语法创建对象
在早期的 JavaScript 版本中要创建 JSON 对象,需要写函数,并且使用 new 关键字。例如下面这样:
// 定义一个函数,可以作为该类的构造器 function Person(name, gender){ this.name = name; this.gender = gender; } // 创建一个 Person 实例 var p = new Person('michael', 'male'); // 输出 Person 实例的 name 属性 alert(p.name);
从 JavaScript 1.2 开始,创建 JSON 对象更快捷的语法如下所示:
var p = {'name': 'michael', 'gender': 'male'}; alert(p);
在新版本的 JavaScript 中创建 JSON 对象的语法更加简捷、方便。从上面示例可知,在 JavaScript 中创建 JSON 对象时,以“{”开始,以“}”结束,对象的每个属性名和属性值之间以英文冒号(:)分隔,多个属性之间用英文逗号(,)分隔。语法格式如下:
object = {
key1: valeu1,
key2: value2,
...
};
在上面这个语法中,最后一个 key-value 对后面不需要有逗号(,),所以在定义时要留意。另外还需要注意的是,JavaScript 中定义JSON对象时,每个对象的 key 可以是字符串,也可以是非字符串,例如下面定义的 JSON 对象也是正确的:
// p 对象的 key 可以不是字符串,在 Python 中 key 必须是可 hash 的对象 var p = {name: 'stark', age: 25}; alert(p.name)
此外,使用 JSON 语法创建 JavaScript 对象时,属性值可以是普通字符串,也可以是任何基本数据类型,还可以是函数、数组,甚至是另外一个使用 JSON 语法创建的对象。例如:
person = { name: 'michael', age: 25, // 使用 JSON 语法创建一个属性 son: { name: 'stark', grade: 1 }, // 使用 JSON 语法为 person 直接创建一个方法 info: function(){ console.log('姓名:' + this.name + '性别:' + this.sex); } }
1.2 使用 JSON 语法创建数组
在早期的 JavaScript 语法中,使用下面的方式来创建数组:
// 创建数组对象 var a = new Array(); // 为数组元素赋值 a[0] = 'michael'; a[1] = 25;
也可通过下面的方式来创建数组:
// 创建数组对象时直接赋值 var a = new Array('michael', 25); 使用 JSON 语法创建数组非常简单,如下所示: // 使用 JSON 语法创建数组 var a = ['michael', 25];
从上面这行代码可知,使用 JSON 创建数组时以英文左方括号([)开始,接着放入数组元素,各元素之间用英文逗号(,)分隔,最后一个
元素后面不需要英文逗号,而是以英文右方括号(])结束。使用 JSON 创建数组的语法格式如下:
arr = [val1, val2, ...]
JSON 语法简单易用,作为数值传输载体时,数据传输量小,在跨平台的数据交换中,经常采用 JSON 作为数据交换格式。在 Python 中有将 JSON 格式的字符串恢复成对象的方法(或函数),也有将某个对象转换成 JSON 字符串的方法。关于 JSON 的更多信息,可参考官方网站 http://www.json.org。
2、 Python 的 JSON 支持
json 模块可用于操作 JSON,该模块有的函数是将 JSON 字符串恢复成 Python 对象的,有的函数是将 Python 对象转换成 JSON 字符串的。
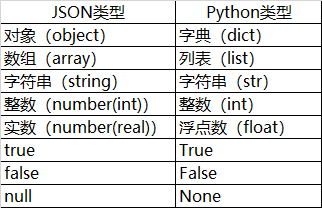
当把 JSON 对象或 JSON 字符串转换成 Python 对象时,从 JSON 类型到 Python 类型的对应转换关系如下所示:
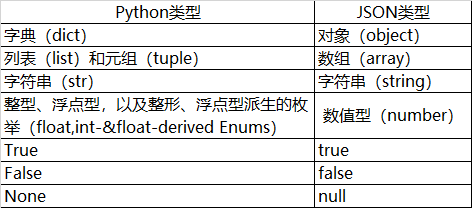
当把 Python 对象转换成 JSON 格式字符串时,从 Python 类型到 JSON 类型的对应转换关系如下所示:
json 模块提供的属性和函数并不多,在交互式解释器中导入 json 模块,使用 json.__all__ 命令可查看全部属性和函数。
>>> import json
>>> json.__all__
['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONDecodeError', 'JSONEncoder']
json 模块中常用的函数和类的功能如下:
(1)、json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):将obj 对象转换成 JSON 字符串输出到 fp 流中,fp 是一个支持 write() 方法的类文件对象。
(2)、json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True,cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):将 obj 对象转换为 JSON 字符串,并返回该 JSON 字符串。
(3)、json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):从 fp 流读取 JSON 字符串,将其恢复成 JSON对象,其中 fp 是一个支持 write()方法的类文件对象。
(4)、json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):将 JSON 字符串 s 恢复成 JSON 对象。
上面 4 个功能函数实现了 JSON 的两个主要应用场景,JSON 是一种轻量级的数据交换格式,它的主要应用场景是:
(1)、JSON字符串 decode(用load或loads) 转换成 Python 对象。
(2)、将 Python 对象 encode(用dump或dumps) 转换成 JSON 字符串。
下面代码将 Python 对象转换成 JSON 字符串,主要使用 dumps()和dump()函数的encode操作。代码如下:
import json
# 将 Python 对象转换为 JSON 字符串,元组会被当成数组
s = json.dumps(['michael', {'fav': ('coding', None, 'game', 25)}])
print(s) # ["michael", {"fav": ["coding", null, "game", 25]}]
# 将简单的 Python 字符串转换为 JSON 字符串
s2 = json.dumps("\"foo\bar")
print(s2) # "\"foo\bar"
# 将简单的 Python 字符串转换为 JSON 字符串
s3 = json.dumps("\\")
print(s3) # "\\"
# 将 Python 的 dict 对象转换为 JSON 字符串,并对 key 排序
s4 = json.dumps({'c':3, 'b': 2, 'a': 1}, sort_keys=True)
print(s4) # {"a": 1, "b": 2, "c": 3}
# 将 Python 列表转换为 JSON 字符串,并指定 JSON 分隔符,在逗号和冒号之后没有空格(默认有空格)
s5 = json.dumps([1, 2, 3, {'x': 5, 'y': 7}], separators=(',', ':'))
# 在输出的 JSON 字符串中,在逗号和冒号之后没有空格
print(s5) # [1,2,3,{"x":5,"y":7}]
# 指定 indent 为4,此时转换的 JSON 字符串有缩进,缩进是4个空格
s6 = json.dumps({'Python': 5, 'Linux': 7}, sort_keys=True, indent=4)
print(s6)
# 伤脑筋 JSONEncoder 的 encode 方法将 Python 对象转换为 JSON 字符串
s7 = json.JSONEncoder().encode({'city': ('成都', '上海')})
print(s7) # {"city": ["\u6210\u90fd", "\u4e0a\u6d77"]}
f = open('a.json', 'w')
# 使用 dump() 函数将转换得到的 JSON 字符串输出到文件中
json.dump(['Linux', {'Python': 'excellent'}], f, indent=4)
运行代码,输出结果如下:
["michael", {"fav": ["coding", null, "game", 25]}]
"\"foo\bar"
"\\"
{"a": 1, "b": 2, "c": 3}
[1,2,3,{"x":5,"y":7}]
{
"Linux": 7,
"Python": 5
}
{"city": ["\u6210\u90fd", "\u4e0a\u6d77"]}
上面代码中使用了 dumps() 函数的 encode 操作,在调用 dumps() 函数时指定了不同的选项。最后一行代码使用 dump() 函数将通过 encode 操作得到的 JSON 字符串输出到文件中。dumps() 和 dump() 函数的功能、所支持的选项基本相同,只是 dumps() 函数直接返回转换得到的 JSON 字符串,而 dump() 函数则将转换得到的 JSON 字符串输出到文件中。运行上面的代码,会在当前工作目录下生成一个 a.json 文件,文件内容就是转换得到的 JSON 字符串。
在上面代码中还调用了 json.JSONEncoder 对象的 encode() 方法,同样可以将 Python 对象转换为 JSON 字符串。而 dumps() 和dump() 函数是更高级的调用方式,通常调用 dumps() 和 dump() 函数对 Python 对象进行转换即可。
下面代码使用 loads() 和 load() 函数的 decode 操作将 JSON 字符串转换成 Python 对象。代码如下:
import json
# 将 JSON 字符串恢复成 Python 列表
r1 = json.loads('["michael", {"fav": ["coding", null, "game", 25]}]')
print(r1) # ['michael', {'fav': ['coding', None, 'game', 25]}]
# 将 JSON 字符串恢复成 Python 字符串
r2 = json.loads('"\\"foo\\"bar"')
print(r2) # "foo"bar
# 定义一个自定义的转换函数,将 real 数据转换成复数的实部,将 imag 转换成复数的虚部
def as_complex(dct):
if '__complex__' in dct:
return complex(dct['real'], dct['imag'])
return dct
# 使用自定义的恢复函数
r3 = json.loads('{"__complex__": true, "real": 1, "imag": 2}', object_hook=as_complex)
print(r3) # (1+2j)
f = open('a.json')
# 从文件中恢复 JSON 列表
r4 = json.load(f)
print(r4) # ['Linux', {'Python': 'excellent'}]
运行代码,输出信息如下所示:
['michael', {'fav': ['coding', None, 'game', 25]}]
"foo"bar
(1+2j)
['Linux', {'Python': 'excellent'}]
在上面代码中,使用 loads() 函数将 JSON 字符串转换成 Python 列表、Python字符串。接下来使用自定义的转换函数,将原本应该恢复成 dict 对象的 JSON 字符串恢复成复数,并将字典中 real 对应的值转换成复数的实部,将字典中 imag 对应的值转换成复数的虚部。
通过使用自定义的恢复函数,可以完成 JSON 类型到 Python 特殊类型(如复数、矩阵)的转换。上面代码最后使用 load() 函数从文件流来恢复 JSON 列表。
此外,Python 支持的类型中有些是 JSON 所不支持的,比如复数、矩阵等,这些不能直接使用 dumps() 或 dump() 函数进行转换,直接转换会出问题。此时需要对 JSONEncoder 类进行扩展,通过扩展来完成从 Python 特殊类型到 JSON 类型的转换。
下面代码通过扩展 JSONEncoder 来实现从 Python 复数到 JSON 字符串的转换。代码如下:
import json
# 定义 JSONEncoder 的子类
class ComplexEncoder(json.JSONEncoder):
def default(self, o):
# 如果要转换的对象是复数类型,就进行处理
if isinstance(o, complex):
return {"__complex__": 'true', 'real': o.real, 'imag': o.imag}
# 对于其他类型,还是使用 JSONEncoder 默认处理
return json.JSONEncoder.default(self, o)
# 第一种转换方式,将自定义的转换类传递给 dumps() 函数的 cls 参数
s1 = json.dumps(2 + 1j, cls=ComplexEncoder)
print(s1) # {"__complex__": "true", "real": 2.0, "imag": 1.0}
# 第二种调用方式,直接调用自定义类的 encode() 实例方法转换
s2 = ComplexEncoder().encode(2 + 1j)
print(s2) # {"__complex__": "true", "real": 2.0, "imag": 1.0}
运行代码,输出结果如下所示:
{"__complex__": "true", "real": 2.0, "imag": 1.0}
{"__complex__": "true", "real": 2.0, "imag": 1.0}
上面代码中对 JSONEncoder 类进行了扩展,并重写父类的 default() 方法,在方法中对被转换的目标类型进行判断,如果是复数类型(complex)就使用自定义转换将复数转换成 JSON 对象,且该对象包含 "__complex__":"true" 属性。
对 JSONEncoder 类扩展后,有两种调用自定义的子类。
(1)、在 dumps() 或 dump() 函数中通过 cls 参数指定使用 JSONEncoder 的自定义子类。
(2)、直接使用自定义子类的 encode() 方法执行转换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号