第三部分 基本库的使用(urllib库, requests库, re库)
Python提供了功能齐全的类库来完成网络请求。基础库的HTTP库有urllib, httplib2, requests, treq等。
比如说rullib库,不用关心底层怎么实现的,只要关心请求的链接是什么,要传的参数是什么,以及如何设置可选的请求。有这些库,可能两行代码就可完成一个请求和响应的处理过程,得到网页内容。
一 使用urllib
Python2中,有urllib和urllib2两个库实现请求的发送。在Python3中,统一为urllib,其官方文档链接为: https://docs.python.org/3/library/urllib.html
urllib库是Python内置的HTTP请求库,不需要额外安装即可使用。包含如下4个模块。
request:最基本的HTTP请求模块,可用来模拟发送请求。就像在浏览器里输入网址然后回车一样,只需要给库方法传入URL 以及额外的参数,就可以模拟实现这个过程。
error:异常处理模块,如果出现请求错误,可以捕获这些异常,然后进行重试或其他操作以保证程序不会意外终止。
parse:一个工具模块,提供了许多URL处理方法,比如拆分、解析、合并等。
robotparser:主要是用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬,用得比较少。
(一) 发送请求
使用urllib的request模块。
1、urlopen()
urllib.request模块提供了最基本的构造HTTP请求的方法,它可以模拟浏览器的一个请求发起过程,同时它还带有处理授权验证(authenticaton)、重定向(redirection)、浏览器Cookies以及其他内容。
下面使用它获取Python的官网内容。
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
请求成功,输出就是网页的源代码。有了网页源代码,想要的链接、图片地址、文本信息都可以提取出来。
可利用type()方法输出响应的类型:
print(type(response)) # 输出如下:
<class 'http.client.HTTPResponse'>
可以发现,它是一个HTTPResposne类型的对象,主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等属性。
调用read()方法得到返回的网页内容,status属性返回结果的状态码,200表示请求成功,404网页未找到。
print(response.status) # 响应的状态码,输出:200
print(response.getheaders()) # 响应的头信息,输出如下:
[('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'),
('X-Frame-Options', 'SAMEORIGIN'), ('x-xss-protection', '1; mode=block'),
('X-Clacks-Overhead', 'GNU Terry Pratchett'), ('Via', '1.1 varnish'),
('Content-Length', '48990'), ('Accept-Ranges', 'bytes'),
('Date', 'Thu, 17 Jan 2019 08:08:11 GMT'), ('Via', '1.1 varnish'),
('Age', '3326'), ('Connection', 'close'), ('X-Served-By', 'cache-iad2125-IAD, cache-lax8645-LAX'),
('X-Cache', 'HIT, HIT'), ('X-Cache-Hits', '1, 123'), ('X-Timer', 'S1547712491.241675,VS0,VE0'),
('Vary', 'Cookie'), ('Strict-Transport-Security', 'max-age=63072000; includeSubDomains')]
print(response.getheader('Server')) # 获取服务的信息,输出:nginx
下面了解下urlopen()函数的API:
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)
a、data参数
可选参数。如果要添加该参数,并且如果它是字节流编码格式的内容,即bytes类型,则需要通过bytes()方法转化。另外,如果传递了这个参数,则它的请求方式就不再是GET方式,而是POST方式。
用下面例子来解释:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read().decode('utf-8'))
上面代码中,传递一个参数word,值是hello。被转码成bytes(字节流)类型。使用bytes()方法,该方法第一个参数是str(字符串)类型,需要用urllib.parse模块里的urlencode()方法来将参数字典转化为字符串;第二个参数指定编码格式,这里指定为utf8。
httpbin.org可提供HTTP请求测试。本次请求的URL为http://httpbin.org/post,这个链接可以用来测试POST请求,它可以输出请求的一些信息,其中包含我们传递的data参数。运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"word": "hello"
},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6"
},
"json": null,
"origin": "183.221.39.13",
"url": "http://httpbin.org/post"
}
传递的参数出现在form字段中,说明模拟表单提交的方式,以POST方式传输数据。
b、timeout参数
设置超时时间,单位是秒。表示到达这个时间没有得到响应,会抛出异常,异常属于urllib.error模块。不指定该参数,就使用全局默认时间。支持HTTP,HTTPS,FTP请求。实例如下:
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/post', timeout=1)
print(response.read().decode('utf-8'))
可以设置超时时间来控制一个网页长时间未响应,就路过它的抓取。可以利用try except语句实现。代码如下:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/post', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
上面代码设置超时时间0.1秒,捕获URLerror异常,接着判断异常是socket.timeout类型,从而得出确实是因超时报错。程序运行后正常输出是:TIME OUT。
c、其他参数
context参数:必须是ssl.SSLContext类型,用来指定SSL设置。
cafile和capath: 分别指定CA证书和它的路径,在请求HTTPS链接是会有用。
cadefault: 已经弃用,默认是False。
前面urlopen()方法的基本用法。可完成简单的请求和网页抓取。更多详细信息参考:https://docs.python.org/3/library/urllib.request.html
2、Request
Request类比urlopen更强大,可以在请求中加入Headers等信息。具体用法如下:
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
在上面代码中,仍然使用urlopen()方法发送这个请求,但这次的参数不是URL,而是一个Request类型对象。通过构造这个这个数据结构,一方面将请求独立成一个对象,另一方面可更加丰富和灵活的配置参数。
下面来看下Request有哪些参数,它的构造方面如下:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
第一个参数url,必须有的参数,其余是可选参数。
第二个参数data,如果要传该参数,必须传bytes(字节流)类型的。如果是字典,可先用urllib.parse模块的urlencode()编码。
第三个参数headers,是一个字典,就是请求头,可以在构造请求时通过headers参数直接构造,也可以通过调用请求实例的add_header()方法添加。添加请求头最常用的用法是通过修改User-Agent来伪装浏览器,默认的User-Agent是Python-urllib ,可以通过修改它来伪装浏览器。比如要伪装火狐浏览器,可以把它设置为:
Mozilla/5.o (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
第四个参数origin_req_host指的是请求方的host名称或者IP地址。
第五个参数unverifiable表示这个请求是否是无法验证的,默认是False,意思就是说用户没有足够权限来选择接收这个请求的结果。例如,请求一个HTML文档中的图片是,没有自动抓取图像的权限,这时unverifiable的值就是True 。
第六个参数method是一个字符串,用来指示请求使用的方法,比如GET、POST和PUT等。
下面例子一次传递多个参数,代码如下所示:
1 from urllib import request, parse
2 url = 'http://httpbin.org/post'
3 headers = {
4 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
5 'Host': 'httpbin.org'}
6 dict = {'name': 'michael'}
7 data = bytes(parse.urlencode(dict), encoding='utf-8')
8 req = request.Request(url=url, data=data, headers=headers, method='POST')
9 response = request.urlopen(req)
10 print(response.read().decode('utf-8'))
上面代码通过4个参数构造了一个请求,其中url即请求URL, headers中指定了User-Agent和Host,参数data用urlencode()和bytes()方法转成字节流。另外,指定了请求方式为POST。输出如下:
1 {
2 "args": {},
3 "data": "",
4 "files": {},
5 "form": {
6 "name": "michael"
7 },
8 "headers": {
9 "Accept-Encoding": "identity",
10 "Connection": "close",
11 "Content-Length": "12",
12 "Content-Type": "application/x-www-form-urlencoded",
13 "Host": "httpbin.org",
14 "User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"
15 },
16 "json": null,
17 "origin": "117.136.63.139",
18 "url": "http://httpbin.org/post"
19 }
从输出中可以看到,成功设置了data, headers和method的。
此外,headers也可以用add_header()方法来添加:
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent','Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
这样可以更加方便的构造请求,实现请求的发送。
3、高级用法
高级操作,如处理Cookies、代理设置等。需要用更强大的工具Handler。可理解为它是各种处理器,有专门处理登录验证的,有处理Cookies的,有处理代理设置的。利用这些,可以做到HTTP请求所有的事情。
首先了解下urllib.request模块里的BaseHandler类,它是所有其他Handler的父类,它提供最基本的方法,如default_open()、protocol_request()等。接下来就是各种Handler子类继承这个BaseHandler类,举例如下。
HITPDefaultErrorHandler:用于处理HTTP响应错误,错误都会抛出HTTPError类型的异常。
HTTPRedirectHandler:用于处理重定向。
HTTPCookieProcessor:用于处理Cookies。
ProxyHandler:用于设置代理,默认代理为空。
HTTPPasswordMgr:用于管理密码,它维护了用户名和密码的表。
HTTPBasicAuthHandler:用于管理认证,如果一个链接打开时需要认证,那么可以用它来解决认证问题。
其它的Handler类可参考:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler
另一个重要的类是OpenerDirector,可简称为Opener。前面用过的urlopen()方法,就是urllib提供的一个Opener。
前面用的Request和urlopen()是类库封装好了常用的请求方法,利用它可以完成基本请求。现在要使用更高级的功能,所以需要深入一层进行配置,使用底层的实例来完成操作,这就要用到Opener。
Opener可以用open()方法,返回的类型和urlopen()是一样的。Opener和Handler的关系,Opener是利用Handler来构建Opener。下面来了解下它的用法。
a. 验证
有些网站在打开时就弹出提示框,要输入用户名和密码,验证成功后才能查看页面。要请求这样的页面,就要借助HTTPBasicAuthHandler来完成。代码如下所示:
1 from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
2 from urllib.error import URLError
3
4 username = 'username'
5 password = 'password'
6 url = 'http://localhost:5000'
7
8 # 实例化HTTPPasswordMgrWithDefaultRealm对象
9 p = HTTPPasswordMgrWithDefaultRealm()
10 # 调用实例p的add_password方法,传递usrl, 用户名,密码参数
11 p.add_password(None, url, username, password)
12 # 实例化HTTPBasicAuthHandler类,传递参数p
13 auth_handler = HTTPBasicAuthHandler(p)
14 opener = build_opener(auth_handler)
15
16 try:
17 result = opener.open(url)
18 html = result.read().decode('utf-8')
19 print(html)
20 except URLError as e:
21 print(e.reason)
这里首先实例化HTTPBasicAuthHandler对象,其参数是HTTPPasswordMgrWithDefaultRealm对象,它利用add_password()添加进去用户名和密码,这样就建立了一个处理验证的Handler。
接下来,利用这个Handler并使用build_opener()方法构建一个Opener,这个Opener在发送请求时就相当于已经验证成功了。
再接下来,利用Opener的open()方法打开链接,就可以完成验证了。这里获取到的结果就是验证后的页面源码内容。
b.代理
爬虫时免不了要使用代理,要添加代理,可以这样做:
1 from urllib.error import URLError
2 from urllib.request import ProxyHandler, build_opener
3
4 proxy_handler = ProxyHandler({
5 'http': 'http://127.0.0.1:9743',
6 'https': 'https://127.0.0.1:9743'
7 })
8 opener = build_opener(proxy_handler)
9 try:
10 response = opener.open('https://www.baidu.com')
11 print(response.read().decode('utf-8'))
12 except URLError as e:
13 print(e.reason)
这里首先在本地搭建了一个代理,运行在9743端口上。后面使用了ProxyHandler类,其参数是一个字典,键名是协议类型(比如HTTP或者HTTPS等),键值是代理链接,可以添加多个代理。
然后,利用这个Handler及build_opener()方法构造一个Opener,之后发送请求即可。
c. Cookies
处理Cookies需要相关的Handler。
下面用实例获取网站的Cookies,代码如下:
1 import http.cookiejar, urllib.request
2
3 cookie = http.cookiejar.CookieJar()
4 handler = urllib.request.HTTPCookieProcessor(cookie)
5 opener = urllib.request.build_opener(handler)
6 response = opener.open('http://www.baidu.com')
7 for item in cookie:
8 print(item.name+"="+item.value)
首先,必须声明一个CookieJar对象。接下来,就需要利用HTTPCookieProcessor来构建一个Handler,最后利用build_opener()方法构建出Opener,执行open()函数即可。输出结果如下:
BAIDUID=F32278B4981A6592572137FDED2EE024:FG=1
BIDUPSID=F32278B4981A6592572137FDED2EE024
H_PS_PSSID=2433_21395_25329_28162_26340_25267_27247_22358
PSTM=1557086442
delPer=0
BDSVRTM=0
BD_HOME=0
上面输出了每条cookie的名称和值。当然也可以输出到文件。例如下面这样:
1 import http.cookiejar, urllib.request
2 filename = 'cookies.txt'
3 cookie = http.cookiejar.MozillaCookieJar(filename)
4 handler = urllib.request.HTTPCookieProcessor(cookie)
5 opener = urllib.request.build_opener(handler)
6 response = opener.open('http://www.baidu.com')
7 cookie.save(ignore_discard=True, ignore_expires=True)
这里CookieJar就需要换成MozillaCookieJar ,在生成文件时会用到,是CookieJar的子类,可以用来处理Cookies和文件相关的事件,比如读取和保存Cookies,可以将Cookies保存成Mozilla型浏览器的Cookies格式。运行之后,就生成了一个cookies.txt文件,内容如下:
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# This is a generated file! Do not edit.
.baidu.com TRUE / FALSE 3695270865 BAIDUID 50D28F44EC61A7DCA87C34798F344EAA:FG=1
.baidu.com TRUE / FALSE 3695270865 BIDUPSID 50D28F44EC61A7DCA87C34798F344EAA
.baidu.com TRUE / FALSE H_PS_PSSID 26125_1464_21355_28128_28532_28766
.baidu.com TRUE / FALSE 3695270865 PSTM 1573785219
.baidu.com TRUE / FALSE delPer 0
www.baidu.com FALSE / FALSE BDSVRTM 0
www.baidu.com FALSE / FALSE BD_HOME 0
LWPCookieJar同样可以读取和保存Cookies,但是保存的格式和MozillaCookieJar不一样,它会保存成libwww-perl(LWP)格式的Cookies文件。
要保存成LWP格式的Cookies文件,在声明时就改为:
cookie = http.cookiejar.LWPCookieJar(filename)
此时生成的内容与前面的有很大的差异。文件内容省略。
生成Cookies后,还可以读取并利用。以LWPCookieJar格式为例:
1 import http.cookiejar, urllib.request
2 cookie = http.cookiejar.LWPCookieJar()
3 cookie.load('cookies.txt', ignore_discard=True, ignore_expires=True)
4 handler = urllib.request.HTTPCookieProcessor(cookie)
5 opener = urllib.request.build_opener(handler)
6 response = opener.open('http://www.baidu.com')
7 print(response.read().decode('utf-8'))
上面代码调用load()方法来读取本地的Cookies文件,获取到前面生的LWPCookieJar格式的Cookies的内容。在读取Cookies之后使用同样的方法构建Handler和Opener即可完成操作。
运行正常就输出百度网页的源代码。
这些是urllib库中request模块的基本用法,详细功能参考:https://docs.python.org/3/library/urllib.request.html#basehandler-objects
(二) 处理异常
在爬虫的时候,可能因网络问题产生异常。不处理这些异常,程序就会终止运行,所以需要处理异常。
urllib的error模块定义了由request模块产生的异常。出现问题,request模块就抛出error模块中定义的异常。
1、URLError
urllib库中的error模块下的URLError类,它继承自OSError类,是error异常模块的基类,由request模块生的异常都可以通过捕获这个类来处理。
它具有一个属性reason,即返回错误的原因。用下面例子了解。
1 from urllib import request, error
2 try:
3 response = request.urlopen('https://helloworld.com/index.html')
4 except error.URLError as e:
5 print(e.reason)
上面代码打开了一个不存在页面,却没有报错。这是由于捕获到了URLError这个异常。运行结果是:Not Found。这样程序没有报错,也避免了异常终止。同时异常也得到有效处理。
2、HTTPError
它是URLError的子类,专门用来处理HTTP请求错误,比如认证请求失败等。它有如下3个属性。
code:返回HTTP状态码,比如404表示网页不存在,500表示服务器内部错误等。
reason:同父类一样,用于返回错误的原因。
headers:返回请求头。
下面看几个例子:
1 from urllib import request, error
2 try:
3 response = request.urlopen('https://helloworld.com/index.html')
4 except error.HTTPError as e:
5 print(e.reason, e.code, e.headers, sep='\n')
运行结果如下:
Not Found
404
Server: nginx/1.10.3 (Ubuntu)
Date: Fri, 18 Jan 2019 06:36:34 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: close
Vary: Cookie
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Cache-Control: no-cache, must-revalidate, max-age=0
Link: <https://helloworld.com/wp-json/>; rel=https://api.w.org/
同样的网站,这次捕获了HTTPError异常,输出了reason, code, headers属性。
由于URLError是HTTPError的父类,可以先捕获子类的错误,再捕获父类的错误,所以更好的写法如下:
1 from urllib import request, error
2 try:
3 response = request.urlopen('https://cuiqingcai.com/index.html')
4 except error.HTTPError as e:
5 print(e.reason, e.code, e.headers, sep='\n')
6 except error.URLError as e:
7 print(e.reason)
8 else:
9 print('Request Successfull')
这次是先捕获HTTPError,获取它的错误状态码、原因、headers等信息。如果不是HTTPError异常,就会捕获URLError异常,输出错误原因。最后,用else来处理正常的逻辑。
有时候,reason属性返回的不一定是字符串,也可能是一个对象或者字符串。看下面的实例:
1 import socket
2 import urllib.request
3 import urllib.error
4 try:
5 response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
6 except urllib.error.URLError as e:
7 print(type(e.reason))
8 if isinstance(e.reason, socket.timeout):
9 print('TIME OUT')
代码中设置强制超时时间来抛出timeout异常,输出如下:
<class 'socket.timeout'>
TIME OUT
可以看出,reason属性的结果是socket.timeout类。所以,这里用isinstance()方法来判断它的类型,作出更详细的异常判断。合理捕获异常做出准确判断,使程序更加稳健。
(三) 解析链接 parse模块
urllib库的parse模块定义了处理URL的标准接口,例如实现URL各部分的抽取、合并以及链接转换。支持这些协议的URL处理:file、ftp、gopher、hdl、http、https、imap、mailto、mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、sip、sips、snews、svn、svn+ssh、telnet和wais。下面了解几个该模块中的常用方法。
1、urlparse()
实现URL的识别和分段,看一个实例:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result, sep='\n')
这里利用了urlparse()方法进行一个URL的解析。首先输出解析结果的类型,然后是结果。输出如下:
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
可以看到,返回结果是一个ParseResult类型的对象,包含6个部分,分别是scheme、netloc、path、params、query和fragment。观察下代码中的URL:
http://www.baidu.com/index.html;user?id=5#comment
可以发现,urlparse()方法将其拆分成了6个部分。观察可以发现,解析时有特定的分隔符。比如,://前面的就是scheme,代表协议;第一个/符号前面便是netloc,即域名,后面是path,即访问路径;分号;后面是params,代表参数;问号?后面是查询条件query,一般用作GET类型的URL;井号#后面是锚点,用于直接定位页面内部的下拉位置。
从上面说明,可以得出一个标准的链接格式,如下所示:
scheme://netloc/path;params?query#fragment
标准的URL都符合这个规则,可利用urlparse()方法进行拆分开。
urlparse()方法还有其它配置,下面看下它的API用法。
urllib.parse.urlparse(url, scheme='', allow_fragments=True)
从上面这行代码看出,它有3个参数。
url: 必须有,待解析的URL。
scheme: 默认的协议(http or https等)。如果url没有带协议信息,将这个作为默认的协议。例如:
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)
输出如下:
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html', params='user', query='id=5', fragment='comment')
从输出可看出,scheme的信息是通过指定默认的scheme参数得到的。
scheme参数只有在URL中不包含scheme信息时才生效。如果URL中有scheme信息,就会返回解析出的scheme。
allow_fragments:是否忽略fragment。如果设置为False,fragment部分就会被忽略,会被解析为path、parameters或者query的一部分,而fragment部分为空。例如:
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result) # 输出如下:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment', fragment='')
输出结果中,allow_fragment的值被解析到query中。
再假设URL中不包含params和query,看下输出结果是什么:
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result) # 输出如下:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html#comment', params='', query='', fragment='')
从输出可见,当URL中不包含params和query时,fragment便会被解析为path的一部分。
结果ParseResult实际是一个元组,可以通过索引和属性名获取。
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result.scheme, result[0], result.netloc, result[1],sep='\n')
上面代码分别用属性名和索引获取scheme和netloc。输出如下:
http
http
www.baidu.com
www.baidu.com
2、urlunparse()
urlparse()方法的对立方法urlunparse()方法。它接受一个可迭代参数对象,参数长度必须是6,参数过多或过少都会抛出错误信息。例如:
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data)) # 输出如下:
http://www.baidu.com/index.html;user?a=6#comment
参数data用的列表类型,也可以用其他类型,如元组或者特定的数据结构。这样就成功构造了URL。
3、urlsplit()
与urlparse()方法相似,只是它不单独解析params这一部分,只运回5个结果。上面例子中的params会合并到path中。例如:
from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result) # 输出如下:
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.html;user', query='id=5', fragment='comment')
返回结果是SplitResult,同样是一个元组类型,可通过属性和索引获取值。
4、urlunsplit()
与urlunparse()相似,也是将链接各个部分组合成完整链接的方法。传的参数是可迭代对象且长度必须是5。参数可以是列表、元组等。例如:
from urllib.parse import urlunsplit
data = ('http', 'www.baidu.com', 'index.html','a=6', 'comment')
print(urlunsplit(data)) # 输出如下:
http://www.baidu.com/index.html?a=6#comment
5、urljoin()
urlunparse()和urlunsplit()方可以完成链接的合并,但前提是必须要有特定长度的对象,链接的每一部分要清晰分开。
urljoin()方法有一个base_url(基础连接)作为第一个参数,将新的链接作为第二个参数,该方法会分析base_url的scheme、netloc和path这3个内容并对新链接缺失的部分进行补充,最后返回结果。下面看几个实例:
1 from urllib.parse import urljoin
2 print(urljoin('http://www.baidu.com', 'FAQ.html'))
3 print(urljoin('http://www.baidu.com', 'https://cuiqingcqi.com/FAQ.html'))
4 print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcqi.com/FAQ.html'))
5 print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcqi.com/FAQ.html?question=2'))
6 print(urljoin('http://www.baidu.com?wd=abc', 'https://cuiqingcqi.com/index.php'))
7 print(urljoin('www.baidu.com', '?category=2#comment'))
8 print(urljoin('www.baidu.com#comment', '?category=2'))
9 # 输出如下:
10 http://www.baidu.com/FAQ.html
11 https://cuiqingcqi.com/FAQ.html
12 https://cuiqingcqi.com/FAQ.html
13 https://cuiqingcqi.com/FAQ.html?question=2
14 https://cuiqingcqi.com/index.php
15 www.baidu.com?category=2#comment
16 www.baidu.com?category=2
输出可以发现,base_url提供了三项内容scheme、netloc和path。如果这3项在新的链接里不存在,就予以补充;如果新的链接存在,就使用新的链接的部分。而base_url中的params、query和fragment是不起作用的。使用urljoin()方法可以轻松实现链接的解析、拼合与生成。
6、urlencode()
urlencode()方法在构造GET请求参数的时候非常有用,例如:
1 from urllib.parse import urlencode
2 params = {
3 'name': 'germey',
4 'age': 22
5 }
6 base_url = 'http://www.baidu.com?'
7 url = base_url + urlencode(params)
8 print(url)
这里声明一个字典将参数表示出来,然后调用urlencode()方法将其序列化为GET请求参数。输出如下:
http://www.baidu.com?name=germey&age=22
输出可知参数被成功的由字典类型转化为GET请求参数。这个方法非常常用。有时为更加方便地构造参数,会事先用字典来表示。要转化为URL的参数时,只需要调用该方法即可。
7、parse_qs()
反序列化,利用parse_qs()方法,可将GET请求参数转回字典。例如:
from urllib.parse import parse_qs
query = 'name=germey&age=22'
print(parse_qs(query))
输出如下,成功转换回字典:
{'name': ['germey'], 'age': ['22']}
8、parse_qsl()
parse_qsl()方法,用于将参数转化为元组组成的列表,示例如下:
from urllib.parse import parse_qsl
query = 'name=germey&age=22'
print(parse_qsl(query))
输出如下:
[('name', 'germey'), ('age', '22')]
输出是一个列表,列表中的每一个元素是一个元组,元组第一个内容是参数名,第二参数内容是参数值。
9、quote()
该方法可将内容转化为URL编码的格式。URL中带有中文参数时,有时可能会导致乱码的问题,此时用这个方法可以将中文字符转化为URL编码,示例如下:
from urllib.parse import quote
kewword = '壁纸'
url = 'https://www.baidu.com/?wd=' + quote(kewword)
print(url)
这里声明了一个中文的搜索文字,然后用quote()方法对其进行URL编码,最后得到的结果如下:
https://www.baidu.com/?wd=%E5%A3%81%E7%BA%B8
10、unquote()
unquote()方法可以进行URL解码,示例如下:
from urllib.parse import unquote
url = 'https://www.baidu.com/?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))
利用unquote()方法还原,结果如下:
https://www.baidu.com/?wd=壁纸
本节介绍了parse模块的一些常用URL处理方法。有了这些方法,可以方便地实现URL的解析和构造,要熟练掌握。
(四) 分析Robots 协议
利用urllib的robotparser模块,可以实现网站Robots协议的分析。下面来简单了解一下该模块的用法。
1、 Robots协议
Robots协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作robots.txt的文本文件,一般放在网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检查这个站点根目录下是否存在robots.txt文件,如果存在,搜索爬虫会根据其中定义的爬取范围来爬取。如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。下面看一下robots.txt的样例:
User-agent: *
Disallow: /
Allow: /public/
这实现了对所有搜索爬虫只允许爬取public目录的功能,将上述内容保存成robots.txt文件,放在网站的根目录下,和网站的入口文件(比如index.php、index.html和index.jsp等)放在一起。
上面的User-agent描述了搜索爬虫的名称,这里将其设置为*则代表该协议对任何爬取爬虫有效。比如,可以设置:User-agent: Baiduspider。这代表设置的规则对百度爬虫有效。如果有多条User-agent记录,就会有多个爬虫会受到爬取限制,但至少需要指定一条。
Disallow指定了不允许抓取的目录,比如上例子中设置为/则代表不允许抓取所有页面。Allow一般和Disallow一起使用,不会单独使用,用来排除某些限制。现在设置为/public/,则表示所有页面不允许抓取,但可以抓取public目录。
下面这个例子,禁止所有爬虫访问任何目录的代码如下:
User-agent: *
Disallow: /
允许所有爬虫访问任何目录的代码如下:
User-agent: *
Disallow:
可以把robots.txt文件留空也行。
禁止所有爬虫访问网站某些目录的代码如下:
User-agent: *
Disallow: /private/
Disallow: /tmp/
只允许某一个爬虫访问的代码如下:
User-agent: WebCrawler
Disallow:
User-agent: *
Disallow: /
2、爬虫名称
爬虫有固定的名字,比如百度叫作BaiduSpider。表3-1列出了一些常见的搜索爬虫名称及对应的网站。
表3-1 一些常见搜索爬虫的名称及其对应的网站


3、robotparser
使用robotparser模块解析robots.txt。该模块提供一个类RobotFileParser,可以根据某网站的robots.txt文件判断一个爬取爬虫是否有权限来爬取这个网页。
该类使用简单,只要在构造方法里传人robots.txt的链接即可。首先看一下它的声明:
urllib.robotparser.RobotFileParser(url='')
也可以在声明时不传人,默认为空,最后再使用set_url()方法设置一下也可。下面是个类的常用方法。
set_url():设置robots.txt文件的链接。在创建RobotFileParser对象时传入了链接,就不再使用这个方法设置。
read():读取robots.txt文件并进行分析。执行一个读取和分析操作,如果不调用这个方法,接下来的判断都会为False ,所以一定记得调用这个方法。这个方法不会返回任何内容,但是执行了读取操作。
parse():解析robots.txt文件,传人的参数是robots.txt某些行的内容,它会按照robots.txt的语法规则来分析这些内容。
can_fetch():该方法传入两个参数,第一个是User-agent,第二个是要抓取的URL。返回的内容是该搜索引擎是否可以抓取这个URL,返回结果是True或False。
mtime(): 返回的是上次抓取和分析robots.txt的时间,对于长时间分析和抓取的搜索爬虫是很有必要的,需要定期检查来抓取最新的robots.txt。
modified():同样对长时间分析和抓取的搜索爬虫很有帮助,将当前时间设置为上次抓取和分析robots.txt的时间。
下面用实例来看一下:
1 rom urllib.robotparser import RobotFileParser
2 rp = RobotFileParser()
3 rp.set_url('http://www.jianshu.com/robots.txt')
4 rp.read()
5 print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
6 print(rp.can_fetch('*', 'http://www.jianshu.com/search?q=python&page=1&type=collections'))
以简书网站为例,先创建了RobotFileParser对象,通过调用set_url()方法设置了robots.txt的链接。不用这个方法,可以在创建对象的传递这个参数。
接下来调用can_fetch方法判断网页是否可以被抓取。运行结果如下:
False
False
也可以使用parse()方法执行读取和分析,如下所示:
1 from urllib.robotparser import RobotFileParser
2 from urllib.request import urlopen
3 rp = RobotFileParser()
4 rp.parse(urlopen('http://www.jianshu.com/robots.txt').read().decode('utf-8').split('\r\n'))
5 print(rp.can_fetch('*', 'https://www.jianshu.com/p/b9dac280f0b4'))
6 print(rp.can_fetch('*', 'https://www.jianshu.com/search?q=python&page=1&type=collections'))
运行结果一样:(可能会运行不成功)
False
False
二 使用requests
在使用urllib时,处理网页验证和Cookies时,需要写Opener和Handler来处理。使用更为强大的库requests,Cookies、登录验证、代理设置等操作都变得容易。
(一) 基本用法
1、准备工作
确保已经正确安装了requests库。
2、实例引入
urllib库中的urlopen()方法是以GET方式请求网页,而requests中相应的方法就是get()方法。下面看一下实例:
1 import requests
2 r = requests.get('https://www.baidu.com/')
3 print(type(r))
4 print(r.status_code)
5 print(type(r.text))
6 print(r.text)
7 print(r.cookies)
8 # 运行结果如下:
9 <class 'requests.models.Response'>
10 200
11 <class 'str'>
12 <!DOCTYPE html>
13 ...
14 <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
调用get()方法实现与urlopen()相同的操作,得到一个Response对象,然后分别输出了Response的类型、状态码、响应体的类型、内容以及Cookies。
这里使用get()方法成功实现一个GET请求,更方便的在于其他的请求类型依然可以用一句话来完成,示例如下:
r = requests.post('http://httpbin.org/post')
r = requests.put('http://httpbin.org/put')
r = requests.delete('http://httpbin.org/delete')
r = requests.head('http://httpbin.org/get')
r = requests.options('http://httpbin.org/get')
这里分别用post()、put()、delete()等方法实现了POST、PUT、DELETE等请求。方便了很多。
3、GET请求HTTP中最常见的请求之一就是GET请求,首先了解利用requests构建GET请求的方法。
a. 基本实例
首先,构建一个最简单的GET请求,请求的链接为http://httpbin.org/get,该网站会判断如果客户端发起的是GET请求的话,它返回相应的请求信息:
1 import requests
2 r = requests.get('http://httpbin.org/get')
3 print(r.text) # 运行结果如下:
4 {
5 "args": {},
6 "headers": {
7 "Accept": "*/*",
8 "Accept-Encoding": "gzip, deflate",
9 "Connection": "close",
10 "Host": "httpbin.org",
11 "User-Agent": "python-requests/2.18.4"
12 },
13 "origin": "183.221.39.21",
14 "url": "http://httpbin.org/get"
15 }
输出可以发现,GET请求是成功的,结果中含有请求头、URL、IP等信息。
如果要在GET请求中添加额外信息,比如添加name是germey,age是22。可以直接写成:
r = requests.get('http://httpbin.org/get?name=germey&age=22')
这种信息数据可用字典来存储,利用params参数就可以构造。示例如下:
1 import requests
2 data = {
3 'name': 'germey',
4 'age': 22
5 }
6 r = requests.get("http://httpbin.org/get", params=data)
7 print(r.text) # 输出如下:
8 {
9 "args": {
10 "age": "22",
11 "name": "germey"
12 },
13 "headers": {
14 "Accept": "*/*",
15 "Accept-Encoding": "gzip, deflate",
16 "Connection": "close",
17 "Host": "httpbin.org",
18 "User-Agent": "python-requests/2.18.4"
19 },
20 "origin": "183.221.39.21",
21 "url": "http://httpbin.org/get?name=germey&age=22"
22 }
通过输出可以看出,请求的连接自动被构造成:http://httpbin.org/get?name=germey&age=22。
另外,网页的返回类型实际上是str类型,是特殊的JSON格式。所以,想直接解析返回结果,得到一个字典格式的话,可以直接调用json()方法。示例如下:
1 import requests
2 r = requests.get('http://httpbin.org/get')
3 print(type(r.text))
4 print(r.json())
5 print(type(r.json()))
6 # 输出如下所示:
7 <class 'str'>
8 {'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate',
9 'Connection': 'close', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.18.4'},
10 'origin': '183.221.39.21', 'url': 'http://httpbin.org/get'}
11 <class 'dict'>
调用json()方法可以将结果是JSON格式的字符串转化为字典。当结果不是JSON格式时,会出现解析错误。抛出json.decoder.JSONDecodeError异常。
b. 抓取网页
下面请求普通网页。以“知乎”--“发现”页面为例做请求:
1 import requests
2 import re
3 headers = {
4 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)'
5 'Chrome/52.0.2743.116 Safari/537.36'
6 }
7 r = requests.get("https://www.zhihu.com/explore", headers=headers)
8 pattern = re.compile('explore-feed.*?question_link.*?>(.*?)</a>', re.S)
9 titles = re.findall(pattern, r.text)
10 print(titles)
在这段代码中加入了headers信息,包含了User-Agent字段信息,也就是浏览器标识信息。不加这个,知乎会禁止抓取。
输出结果如下:
['\n身为律师碰到的最奇葩的离婚案件是什么?\n', '\nT72真的很不堪吗?\n', '\n如何评价《弦音 风舞高中弓道部》初动1414?\n',
'\n为什么那么多三四十岁的大哥大姐喜欢杨超越?\n', '\n如何看待动画电影《我想吃掉你的胰脏》官方宣发的营销行为?\n',
'\n为什么黄磊的女儿黄多多这么优秀?\n', '\n1/a=1/b+1/c+1/d+…+1/n 有什么特殊内涵吗?\n',
'\n如何看待朱一龙在《知否知否应是绿肥红瘦》中的表现?\n', '\n如何评价杨超越赖美云傅菁三人的合作歌曲《101个愿望》?\n',
'\n粉团体中的非人气成员是什么体验?\n']
上面输出中,成功提取了所有匹配的内容。
c. 抓取二进制数据
前面抓取的是一个HTML文档。图片、音频、视频这些文件本质上是由二进制码组成的,由于有特定的保存格式和对应的解析方式,才可以看到这些形形色色的多媒体。所以,要抓取它们,就要拿到它们的二进制码。下面以GitHub的站点图标为例来看一下:
1 import requests
2 r = requests.get("https://github.com/favicon.ico")
3 print(r.text)
4 print(r.content)
抓取的内容是站点图标,即浏览器每一个标签上显示的小图标。打印了Response对象的两个属性,一个是text,另一个是content。在运行结果r.text的结果是乱码。r.content的结果前带有字母b,表示bytes类型数据。由于图片是二进制数据r.text在打印时转化为str类型,即直接转化为字符串,所以是乱码。输出如下所示:省略了大部分输出内容。
( & ( N (
� �i
b'\x00\x00\x01\x00\x02\x00\x10\x10\x00\x00\x01\x00 \x00(\x05\x
可以将刚才提取到的图片保存下来,用open()方法,以二进制写的形式打开,可写入二进制数据。
1 with open('favicon.ico', 'wb') as f:
2 f.write(r.content)
执行上面代码后,在本地代码所在的文件内保存了favicon.ico的图标。对音频和视频文件也可用这种方法。
d. 添加headers
在前面知乎的例子中,不传递headers,就不能正常请求:
1 import requests
2 r = requests.get("https://www.zhihu.com/explore")
3 print(r.text) # 输出如下:
4 <html>
5 <head><title>400 Bad Request</title></head>
6 <body bgcolor="white">
7 <center><h1>400 Bad Request</h1></center>
8 <hr><center>openresty</center>
9 </body>
10 </html>
如果加上headers并加上User-Agent信息就没问题。在headers这个参数中可以任意添加其他字段信息。
4、POST请求
使用requests实现POST请求。如下:
import requests
data = {'name': 'germey', 'age': '22'}
r = requests.post('http://httpbin.org/post', data=data)
print(r.text)
以http://httpbin.org/post为例,该网站可以判断请求是否是POST方式,是就把相关请求信息返回。输出如下:
{ "args": {}, "data": "", "files": {}, "form": { "age": "22", "name": "germey" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Content-Length": "18", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.18.4" }, "json": null, "origin": "183.221.39.21", "url": "http://httpbin.org/post" }
从输出可以看出,成功获得了返回结果,其中form部分就是提交的数据,这就证明POST请求成功发送。
5、响应
发送请求后,得到的是响应。上面的实例中,使用text和content获取了响应的内容。还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies等。示例如下:
import requests
r = requests.get('https://www.sina.com.cn')
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)
上面代码中分别输出status_code属性、headders属性、cookies属性、url属性、history属性。运行结果如下:
<class 'int'> 200 <class 'requests.structures.CaseInsensitiveDict'> {'Server': 'esnssl/1.14.1', 'Date': 'Tue, 22 Jan 2019 00:49:54 GMT', 'Content-Type': 'text/html', 'Content-Length': '129713', 'Connection': 'keep-alive', 'Last-Modified': 'Tue, 22 Jan 2019 00:48:01 GMT', 'Vary': 'Accept-Encoding', 'X-Powered-By': 'shci_v1.03', 'Expires': 'Tue, 22 Jan 2019 00:50:38 GMT', 'Cache-Control': 'max-age=60', 'Content-Encoding': 'gzip', 'Age': '16', 'Via': 'https/1.1 ctc.guangzhou.ha2ts4.181 (ApacheTrafficServer/6.2.1 [cHs f ]), https/1.1 cmcc.guangzhou.ha2ts4.136 (ApacheTrafficServer/6.2.1 [cRs f ]), https/1.1 cmcc.sichuan.ha2ts4.145 (ApacheTrafficServer/6.2.1 [cRs f ])', 'X-Via-Edge': '15481181948828b3f88759108137001db0f5f', 'X-Cache': 'HIT.145', 'X-Via-CDN': 'f=edge,s=cmcc.sichuan.ha2ts4.145.nb.sinaedge.com,c=117.136.63.139;f=edge,s=cmcc.sichuan.ha2ts4.146.nb.sinaedge.com,c=112.19.8.145;f=Edge,s=cmcc.sichuan.ha2ts4.145,c=112.19.8.146'} <class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[]> <class 'str'> https://www.sina.com.cn/ <class 'list'> []
上面输出中,headers和cookies这两个属性得到的结果分别是CaselnsensitiveDict和RequestsCookieJar类型。
状态码用来判断请求是否成功,requests还提供了一个内置的状态码查询对象requests.codes,示例如下:
import requests
r = requests.get('https://www.sina.com.cn')
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')
通过比较返回码和内置的成功返回码,来保证请求得到正常响应,输出成功请求的消息,否则程序终止,这里用requests.codes.ok得到的是成功的状态码200。
除了ok这个条件码,还有其它的返回码和相应的查询条件:


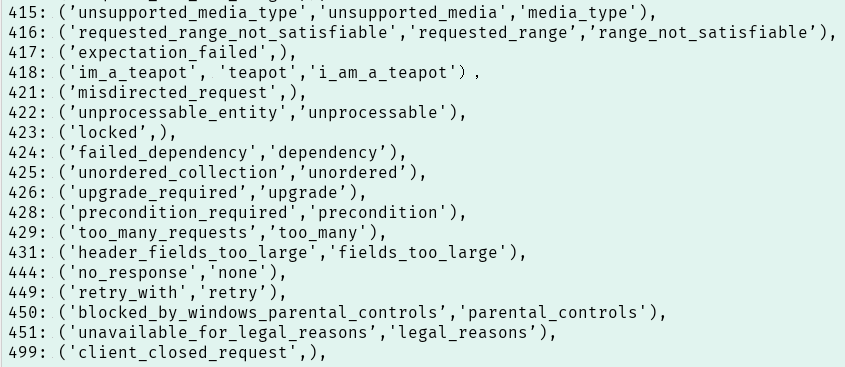
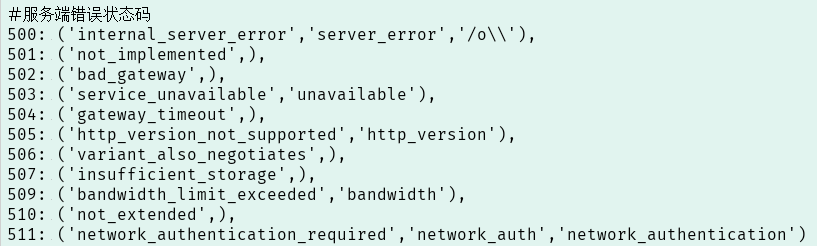
例如要判断结果是不是404状态,可以用requests.codes.not_found来比对。
(二) 高级用法
requests的基本用法,有基本的GET、POST请求以及Response对象。下面了解requests的高级用法,如文件上传、Cookies设置、代理设置等。
1、文件上传
requests可以模拟提交一些数据。比如上传文件,示例如下:
1 import requests
2 files = {'file': open('favicon.ico', 'rb')}
3 r = requests.post("http://httpbin.org/post", files=files)
4 print(r.text)
这里使用前面保存的文件favicon.ico来模拟上传,要注意favicon.ico文件要与脚本文件在同一个目录下。运行结果如下:
{
"args": {},
"data": "",
"files": {
"file":"data:application/octetstream;base64,AAAAAA...="
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "6665",
"Content-Type": "multipart/form-data; boundary=53395f073fcb443d8dce7bb21f1d9540",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "183.221.39.21",
"url": "http://httpbin.org/post"
}
上面输出中,网站返回了响应,里面有files字段,而form字段是空。这说明文件上传部分会有单独一个files字段来标识。
2、Cookies
使用requests获取和设置Cookies比用urllib处理Cookies方便,只需一步即可完成。先用一个例子看下获取Cookies的过程:
import requests
r = requests.get("https://www.163.com")
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)
# 运行结果如下:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315
调用cookies属性得到Cookies,它是RequestCookieJar类型。用items()方法转化为元组组成的列表,遍历输出每一个Cookie的名称和值,实现Cookie的遍历解析。
可以直接用Cookies来维持登录状态,以知乎为例。先登录知乎,将Headers中的Cookies内容复制下来。将其设置到Headers里面,然后发送请求,示例如下:
1 import requests
2 headers = {
3 'Cookie': 'cookie省略',
4 'Host': 'www.zhihu.com',
5 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)'
6 'Chrome/52.0.2743.116 Safari/537.36'
7 }
8 r = requests.get('https://www.zhihu.com', headers=headers)
9 print(r.text)
从输出信息可能看出是否是登录成功。输出省略
也可以通过cookies参数来设置,需要先构造RequestsCookieJar对象,而且需要分割一下cookies。这相对烦琐,不过效果是一样的,示例如下:
1 import requests
2 cookies = 'cookies信息省略'
3 jar = requests.cookies.RequestsCookieJar()
4 headers = {
5 'Host': 'www.zhihu.com',
6 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)'
7 'Chrome/52.0.2743.116 Safari/537.36'
8 }
9 for cookie in cookies.split(';'):
10 key, value = tuple(cookie.split('=', 1))
11 jar.set(key, value)
12 r = requests.get('https://www.zhihu.com', cookies=jar, headers=headers)
13 print(r.text)
输出信息与前面一样。这里先新建了一个RequestCookieJar对象,然后将复制下来的cookies利用split()方法分割,分割后是一个列表,使用tuple()方法转化为元组。接着利用set()方法设置好每个Cookie的key和value,然后通过调用requests的get()方法并传递给cookies参数即可。由于知乎的限制,headers参数也不能少,只不过不需要在原来的headers 参数里面设置cookie字段了。
3、会话维持
在requests中,用get()和post()方法模拟网页请求,实际上是不同的会话,也就是相当于两个浏览器打开了不同的页面。
Session对象,可以方便维护一个会话,且不用担心cookies的问题,它会帮我们自动处理好。示例如下:
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
r = requests.get('http://httpbin.org/cookies')
print(r.text)
上面代码请求一个测试网址http://httpbin.org/cookies/set/number/123456789,在请求时设置一个cookie,名称是number,内容是123456789,随后又请求http://httpbin.org/cookies网址可以获取当前的cookies。这样做并不能获取到设置的cookies,输出如下:
{
"cookies": {}
}
下面再用Session试试看:
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
运行结果如下:
{
"cookies": {
"number": "123456789"
}
}
输出中已经成功获取。这就是同一个会话和不同会话的区别。
利用Session可模拟同一个会话而不用担心Cookies问题。常用于模拟登录功能后再进行下一步操作。Session使用广泛,还可用于模拟在一个浏览器中打开同一站点的不同页面。
4、SSL证书验证
requests有证书验证功能,发送HTTP请求时,会检查SSL证书。可用verify参数控制是否检查证书。默认verify参数是True,会自动验证。
由于以前12306的证书没有被CA官方机构信息,所以打开12306时会出现证验证错误的结果。用requests测试一下:
import requests
response = requests.get('https://www.12306.cn')
print(response.status_code)
目前可以正常请求。如果运行结果中出现SSLError错误,表示证书验证错误。要避这样的错误就把verify参数设置为False即可。
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
这样强行不验证的时候会收到警告信息。可通过设置来屏蔽这个警告:
import requests
import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
通过使用urllib3.disable_warnings()方法屏蔽警告信息。或者通过捕获警告到日志的方式忽略警告:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
上面代码可以正常输出,将捕获到的警告到日志方式忽略警告。
也可以指定本地证书作用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件的路径元组:
import requests
response = requests.get('https://www.12306.cn', cert('/path/server.crt', '/path/key'))
print(response.status_code)
注意,本地私有证书的key必须是解密状态,加密状态的key是不支持的。
5、代理设置
避免因频繁访问网站,被网站封禁、重新登录、弹出维码等问题,需要用代理来解决这个问题。可proxies参数进行设置。
import requests
proxies = {
'http': 'http://10.10.1.10:3328',
'https': 'http://10.10.1.10:1080',
}
requests.get("https://wwww.taobao.com", proxies=proxies)
这里的代理IP要换成有效的代理IP试验。
若代理需要使用HTTP Basic Auth,可以使用类似http://user:password@host:port这样的语法来设置代理,示例如下:
import requests
proxies = {
'http': 'http://user:password@10.10.1.10:3328',
}
requests.get("https://wwww.taobao.com", proxies=proxies)
除了基本的HTTP代理,requests还支持SOCKS协议的代理。需要先安装socks库:
pip3 install 'requests[socks]'
接下来就可以使用SOCKS协议代理,示例如下:
import requests
proxies = {
'http': 'socks5://user:password@host:port',
'https': 'socks5://user:password@host:port',
}
requests.get("https://wwww.taobao.com", proxies=proxies)
6、超时设置
设置超时时间防止服务器不能及时响应,即超过规定时间还没有响应就报错。用timeout参数进行设置。这个时间的计算是发出请求到服务器返回的时间。示例如下:
import requests
r = requests.get("https://www.taobao.com", timeout=1)
print(r.status_code)
上面代码设置超时是1秒,1秒没有响应就抛出异常。请求分为两个阶段,即连接(connect)和读取(read)。前面设置的1秒是这个时间的总和。如果要分别指定,可以传入一个元组:
r = requests.get("https://www.taobao.com", timeout=(5, 11, 30))
timeout参数设置为None或为空,就永远不会返回超时错误。
7、身份认证
某些网站在打开时就弹出“需要身份认证”的对话框。此时可用requests自带的身份认证功能,示例如下:
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:5000', auth=HTTPBasicAuth('username', 'password'))
print(r.status_code)
认证成功,状态码是200;认证失败是401。认证参数也可以是一个元组,默认使用HTTPBasicAuth这个类认证。
import requests
r = requests.get('http://localhost:5000', auth=('username', 'password'))
print(r.status_code)
requests还有其它认证方式,如OAuth认证,需要安装oauth包,安装命令是:
pip3 install requests_oauthlib
使用OAuthl认证的方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECERT'
'USER_OAUTH_TOKEN', 'USER_OAUT_TOKEN_SECRET')
requests.get(url, auth=auth)
参考requests_oauthlib的官方文档https://requests-oauthlib.readthedocs.org/了解更多。
8、 Prepared Request
requests的数据结构叫Prepared Request。
from requests import Request, Session
url = 'http://httpbin.org/post'
data = {'name': 'michael'}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/52.0.2743.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
这里使用了Request,用url, data和headers参数构造一个Request对象。需要再调用Session的prepare_request()方法将其转换为一个Prepared Request对象,然后调用send()方法发送。输出如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "michael"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "12",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/52.0.2743.116 Safari/537.36"
},
"json": null,
"origin": "183.221.39.21",
"url": "http://httpbin.org/post"
}
输出可以看到,这同样达到了POST请求效果。这个Request对象可以把请求当作独立的对象来看待,这在进行列队调度时会非常方便。更多用法可参数官方文档:http://docs.python-requests.org/。
三 正则表达式
正则表达式是处理字符串的强大工具,有特定的语法结构,实现字符串的检索、替换、匹配验证等。对于爬虫来说,从HTML提取信息非常方便。
1、引入实例
用几个实例来了解正则表达式用法。开源中国网站提供了正则表达式测试工具http://tool.oschina.net/regex/,输入要匹配的文本, 选择常用的正则表达式,就可以得相应的匹配结果了。例如,输入待匹配的文本如下:
Hello, my phone number is 028-88661234 and email is 276313077@qq.com, and my website is https://www.michael.com.
这段字符串中有电话号码和电子邮件地址,下面用正则表达式提取出。
正则表达式:[a-zA-Z]+://[^\s]*,提取到的内容是:https://www.michael.com
该网站还提供了一些快捷功能,可以快速匹配。如“匹配Emial地址”就出现:276313077@qq.com。匹配“国内电话号码”就出现:028-88661234。
下表是常用的正则表达式匹配规则


Python的re库提供了整个正则表达式的实现。
2、第一个匹配方法match()
常用匹配方法match(),需要传入要匹配的字符串以及正则表达式。match()方法从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回None。示例如下:
import re
content = 'Hello 123 4567 World_this is a Regex Demo'
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())
输出结果如下所示:
41
<_sre.SRE_Match object; span=(0, 25), match='Hello 123 4567 World_this'>
Hello 123 4567 World_this
(0, 25)
在上面代码中,先声明了一个有字母、数字、空白字符的字符串。接下来写了一个正则表达式“^Hello\s\d\d\d\s\d{4}\s\w{10}”匹配这个字符串。开头的(^)是匹配字符串的开头,这里以Hello开开头;后面是(\s)匹配空白字符;(\d)匹配数字;后面的(\d{4})匹配4个数字;(\w{10})匹配10个字母及下划线。
match()方法的第一个参数是正则表达式,第二个参数是要匹配的字符串。输出结果是SRE_Match对象,说明成功匹配。group()和span(),group()方法输出匹配到的内容;span()方法输出匹配的范围。
a. 匹配目标
只匹配目标字符串的某一部分,如电话号码或邮件等。可使用()括号将想要提取的子字符串括起来。()实际上标记一个子表达式的开始和结束位置,被标记的每个子表达式会依次对应每一个分组。调用group()方法传入分组的索引值即可获取提取的结果。示例如下:
import re
content = 'Hello 1234567 World_this is a Regex Demo'
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
这里需要提取字符串的1234567,此时可以将数字部分的正则表达式用()括起来,然后调用group(1)获取匹配结果。输出如下所示:
<_sre.SRE_Match object; span=(0, 19), match='Hello 1234567 World'>
Hello 1234567 World
1234567
(0, 19)
输出中得到了1234567。这是用的group(1),它与group()有所不同,后者会输出完整的匹配结果,而前者会输出第一个被()包围的匹配结果。假如正则表达式后面还有()包括的内容,那么可以依次用group(2)、group(3)等来获取。
b. 通用匹配
前面写的正则表达式稍显复杂,而且工作量还大。另外还有一个万能匹配是 .*(点星)。其中 .(点)可以匹配任意字符(除换行符), *(星)匹配前面的字符无限次。它们组合使用可以匹配任意字符。例如:
import re
content = 'Hello 123 4567 World_this is a Regex Demo'
result = re.match('^Hello.*Demo$', content)
print(result)
print(result.group())
print(result.span())
上面代码中间部分直接省略,全部用 .* 代替,最后加一个结尾字符串。输出省略。
c. 贪婪与非贪婪
在上面使用的通配符 .* 时,有时可能匹配到的是不想要的结果,例如下面:
import re
content = 'Hello 1234567 World_this is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$', content)
print(result)
print(result.group(1)) # 输出:7
在表达式中 (\d+) 想要匹配中间的数字,由于数字两侧杂乱,在两边都写成 .* 。这时 (\d+) 匹配到的是数字7,这就是贪婪匹配的问题。由于 .* 会匹配尽可多的字符,表达式中 \d+ 表示至少一个数字,并没有指定具体多少个数字。因此, .* 就匹配尽可能多的字符,给 \d+ 留下一个可满足条件的数字7。这里只要使用非贪婪匹配就好了。非贪婪匹配写法是 .*? ,多了一个 ?(问号)。实例代码如下:
import re
content = 'Hello 1234567 World_this is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
print(result.group(1)) # 输出:1234567
将第一个 .* 改成 .*? ,转变为非贪婪匹配,就可得到正确结果。非贪婪匹配就是尽可能匹配少的字符。当 .*? 匹配到Hello后面的空白字符时,再往后的字符就是数字了,而 \d+ 恰好可以匹配,此时这里 .*? 就不再进行匹配,交给 \d+ 去匹配后面的数字。所以这样 .*? 叫匹配了尽可能少的字符, \d+ 的结果就是1234567了。
在做匹配的时候,字符串中间尽量使用非贪婪匹配,也就是用 .*? 来代替 .*,以免出现匹配结果缺失的情况。
需要注意,如果匹配的结果在字符串结尾,.*? 就有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。例如:
import re
content = 'http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)
print('result1', result1.group(1))
print('result2', result2.group(1))
运行结果如下:
result1
result2 kEraCN
从输出可知, .*? 没有匹配到任何结果, 而 .* 则尽量匹配多的内容,成功得到了匹配结果。
d. 修饰符
正则表达式的方法可以传递修饰符来控制匹配模式。修饰符被指定为一个可选的标志。例如:
import re
content = '''Hello 1234567 World_this
is a Regex Demo'''
result = re.match('^He.*?(\d+).*?Demo$', content)
print(result.group(1))
上面代码在字符串加入换行符,正则表达不变,用来匹配其中的数字。此时运行会报错,错误信息如下:
1 AttributeError Traceback (most recent call last)
2 <ipython-input-34-75c815ab8fba> in <module>()
3 3 is a Regex Demo'''
4 4 result = re.match('^He.*?(\d+).*?Demo$', content)
5 ----> 5 print(result.group(1))
6 AttributeError: 'NoneType' object has no attribute 'group'
错误原因是说正则表达式没有匹配到这个字符串,返回结果为None,而又调用了group()方法导致Attribute Error 。
由于 . 匹配的是除换行符之外的任意字符,当遇到换行符是 .*? 就不能匹配,导致匹配失败。这里只要加一个修饰符 re.S 即可修正这个错误:
result = re.match('^He.*?(\d+).*?Demo$', content, re.S)
修饰符的作用是使 . 匹配包括换行符在内的所有字符。此时输出:1234567
这个re.S在网页匹配中经常用到。因为HTML节点有换行,加上它,就可以匹配节点与节点之间的换行。
还有一些修饰符,如下表所示。

在网页匹配中,常用re.S和re.I。
e. 转义匹配
如果待匹配的字符串含有特殊符号,如 . * ? + 等,此时就要需要对这特殊符号进行转义。需要对特殊符号进行进行转义时,在特殊号前加反斜线(\)转义即可。例如:\. \* \? \+表示分别对 . * ? + 这4个特殊符号转义。示例如下:
import re
content = '(百度)www.baidu.com*+?'
result = re.match('(\(百度\)www\.baidu\.com\*\+\?)', content)
print(result.group(1))
运行结果如下所示:
(百度)www.baidu.com*+?
输出结果中,是成功匹配了原字符串的。
3、 第二个匹配方法search()
前面说的match()方法是从字符串的起始处开始匹配,一旦起始处不匹配,则整个匹配都会失败。此时得到的结果是None。match()方法要考虑起始处的内容,使用进不方便。它更多用于检测某个字符串是否符合某个正则表达式的规则。search()方法在匹配时,返回第一个成功匹配的结果。在匹配时,search()方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完还没有找到,就返回None。例如下面代码所示:
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
result = re.search('Hello.*?(\d+).*?Demo', content)
print(result)
print(result.group(1))
运行结果如下所示:
<_sre.SRE_Match object; span=(13, 53), match='Hello 1234567 World_This is a Regex Demo'>
1234567
输出结果中是成功匹配了想要的内容。将search()方法改为match()方法,第一个输出是None。在匹配时尽量用search()方法。search()方法的使用实例。现有下面这段HTML代码,写几个正则表达式提示相应信息。
html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"></i>但愿人长久</a>
</li>
</ul>
</div>'''
在这个HTML代码中,ul节点包含有许多li节点,其中li节点中有的包含a节点,有的不包含a节点。a节点还有一些相应的属性:超链接和歌手名。
首先,提取class为active的li节点内部的超链接包含的歌手名和歌名,此时需要提取第三个li节点下a节点的singer属性和文本。正则表达式可以以li开头,接着寻找一个标志符active,中间部分用 .*? 匹配。接下来要提取singer这个属性值,所以还要写入singer="(.*?)",这里用括号括起来,方便用group()方法提取出来。然后目标内容依然用(.*?)匹配,所以最后的正则表达式就变成了:
<li.*?active.*?singer="(.*?)">(.*?)</a>
由于代码中有换行,还需要传递第三个参数re.S。调用search()方法找到符合正则表达式的第一个内容就返回。整个匹配代码如下:
result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))
使用group()方法获取想要的数据。输出如下:
齐秦 往事随风
如果正则表达式不加active,得到的结果会不一样,search()方法会返回第一个符合条件的匹配目标。代码修改如下:
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))
这时的运行结果如下:
任贤齐 沧海一声笑
从字符串起始处搜索,由于找到匹配的对象后,search()方法就不再往后继续匹配。所以结果与前一个不一样。注意这里的两次匹配都加了re.S,这使得 .*?可以匹配换行符。如果将 re.S 去掉,结果又会不一样,如下所示:
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html)
if result:
print(result.group(1), result.group(2))
运行结果是:
beyond 光辉岁月
此时结果是第四个li节点的内容,这个节点没有换行符,所以成功匹配这个节点。在实际匹配时尽量加上re.S。
4、 第三个匹配方法findall()
findall()方法会获取匹配正则表达式的所有内容。该方法会搜索整个字符串,然后返回匹配正则表达式的所有内容。继续使用上面那段HTML代码,这次使用findall()方法要获取所有a节点的超链接、歌手和歌名。findall()方法有匹配到结果的话,返回的是列表类型。需要遍历列表获取每组内容。代码如下:
1 results = re.findall('<li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S)
2 print(results)
3 print(type(results))
4 for result in results:
5 print(result)
6 print(result[0], result[1], result[2])
运行结果如下:
[('/2.mp3', '任贤齐', '沧海一声笑'), ('/3.mp3', '齐秦', '往事随风'),
('/4.mp3', 'beyond', '光辉岁 月'), ('/5.mp3', '陈慧琳', '记事本'),
('/6.mp3', '邓丽君', '但愿人长久')]
<class 'list'>
('/2.mp3', '任贤齐', '沧海一声笑')
/2.mp3 任贤齐 沧海一声笑
('/3.mp3', '齐秦', '往事随风')
/3.mp3 齐秦 往事随风
('/4.mp3', 'beyond', '光辉岁月')
/4.mp3 beyond 光辉岁月
('/5.mp3', '陈慧琳', '记事本')
/5.mp3 陈慧琳 记事本
('/6.mp3', '邓丽君', '但愿人长久')
/6.mp3 邓丽君 但愿人长久
从输出可以看出,返回的列表中的每个元素都是元组类型,这里用对应的索引依次取出。只想获取第一个内容,就用search()方法。
5、 第四个匹配方法sub()
sub()方法可以根据正则表达的匹配结果替换为指定的值。当然也可以用replace()方法。例如要把一串文本中的所有数字去掉,可以用sub()方法来做。实例如下:
import re
content = '54ak54yr5oiR54ix8L9g'
content = re.sub('\d+', '', content)
print(content) # 输出是:akyroiRixLg
在sub()方法中第一个参数\d+匹配所有数字,第二个参数为要替换的字符串,第三个参数是被匹配对象。在前面的HTML文本中,假如只获取所有li节点的歌名,可直接写一个长表达式来提取。例如下面所示:
1 results = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>', html, re.S)
2 for result in results:
3 print(result[1])
在上面代码,(\w+)表示要提取的歌名。由于有的li节点内不包含a节点,所以表达式(<a.*?>)?意是匹配a节点0次或1次。运行结果如下所示:
一路上有你
沧海一声笑
往事随风
光辉岁月
记事本
但愿人长久
如果用sub()方法来做会简单些。首先利用sub()方法将a节点去掉,只留下文本,然后利用findall()提取就行。代码如下所示:
1 html = re.sub('<a.*?>|</a>', '', html) # 首先去掉a节点
2 print("替换a节点后的HTML内容如下:")
3 print(html)
4 print("使用findall()方法查找到的内容如下:")
5 results = re.findall('<li.*?>(.*?)</li>', html, re.S)
6 for result in results:
7 print(result.strip())
运行结果如下所示:
1 替换a节点后的HTML内容如下:
2 <div id="songs-list">
3 <h2 class="title">经典老歌</h2>
4 <p class="introduction">
5 经典老歌列表
6 </p>
7 <ul id="list" class="list-group">
8 <li data-view="2">一路上有你</li>
9 <li data-view="7">
10 沧海一声笑
11 </li>
12 <li data-view="4" class="active">
13 往事随风
14 </li>
15 <li data-view="6">光辉岁月</li>
16 <li data-view="5">记事本</li>
17 <li data-view="5">
18 但愿人长久
19 </li>
20 </ul>
21 </div>
22 使用findall()方法查找到的内容如下:
23 一路上有你
24 沧海一声笑
25 往事随风
26 光辉岁月
27 记事本
28 但愿人长久
从输出可知,a节点经过sub()方法处理后就没有了,然后通过findall()方法可直接提取。在适当的时候,使用sub方法可以起到事半功倍的效果。
6、 第五个匹配方法compile()
compile()方法可将正则字符串编译成正则表达式对象,以便在后面的匹配中重复使用。如下面所示:
1 import re
2 content1 = '2019-01-11 08:55'
3 content2 = '2019-01-13 11:30'
4 content3 = '2019-01-15 14:26'
5 pattern = re.compile('\d{2}:\d{2}')
6 result1 = re.sub(pattern, '', content1)
7 result2 = re.sub(pattern, '', content2)
8 result3 = re.sub(pattern, '', content3)
9 print(result1, result2, result3)
运行结果如下:
2019-01-11 2019-01-13 2019-01-15
在上面代码中,将3个日期中的时间去掉,这里使用sub()方法来完成。由于要写3个同样的正则表达式,此时就可以借助compile()方法将正则表达式编译成一个正则表达式对象,以便利用。
另外,compile()还可以传入修饰符,例如re.S等修饰符,这样在search()、findall()等方法中就不需要额外传。所以,compile()方法是给正则表达式做了一层封装,以使更好进行地复用。
四 抓取猫眼电影排行榜
下面利用requests库和正则表达式抓取猫眼电影TOP100相关内容。requests比urllib使用方便。
抓取的目标网站是:https://maoyan.com/board/4。打开网页后可看到榜单信息,在网页的最下方,还有分页的列表,点击第2页,观察页面的URL和内容发生变化。URL变成:https://maoyan.com/board/4?offset=10,比前一个URL多一个参数?offset=10,显示有信息是排行11~20名的电影。再点击下页,发现页面的URL变成了:https://maoyan.com/board/4?offset=20,参数offset变成了20,页面显示结果是排行21~30的电影。所以初步判断offset是一个偏移量的参数。
由上可知,offset代表偏移量值,如果偏移量为n,则显示的电影序号就是n+1到n+10,每页显示10个。所以,要获取TOP1OO电影,只要分开请求10次,而10次的offset参数分别设置为0、10、20 … 90即可,这样获取不同的页面之后,再用正则表达式提取出相关信息,就可以得到TOP1OO的所有电影信息。
1、抓取首页
首先用代码来实现抓取第一面的内容,在代码中定义了一个get_one_page()方法,传递url参数,并将抓取结果返回。通过main()函数进行调用。初步代码如下所示:
1 import requests 2 def get_one_page(url): 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)' 5 'Chrome/65.0.3352.162 Safari/537.36' 6 } 7 response = requests.get(url, headers=headers) 8 # 如果成功获取就返回网页源代码,否则返回None 9 if response.status_code == 200: 10 return response.text 11 return None 12 13 def main(): 14 url = 'https://maoyan.com/board/4' 15 html = get_one_page(url) 16 print(html) 17 main()
运行程序就可成功获取首页源代码。接下来要解析页面,提取出想要的信息。
2、使用正则提取有用信息
在提取之前,先在浏览器上看一下网页的真实源码。进入开发者模式下的Network监听组件中查看源代码。在Network组件下左侧的name框内选择第一条,在右侧选择Response选项,此时看到的就是网页的真实源代码。
注意,不要在Elements选项卡中直接查看源码,因为那里的源码可能经过JavaScript操作而与原始请求不同,而是要从Network选项卡部分查看原始请求得到的源码。
其中一条信息的源代码如下所示:
1 <dd>
2 <i class="board-index board-index-1">1</i>
3 <a href="/films/1203" title="霸王别姬" class="image-link" data-act="boarditem-click" data-val="{movieId:1203}">
4 <img src="//s0.meituan.net/bs/?f=myfe/mywww:/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
5 <img data-src="https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c" alt="霸王别姬" class="board-img" />
6 </a>
7 <div class="board-item-main">
8 <div class="board-item-content">
9 <div class="movie-item-info">
10 <p class="name"><a href="/films/1203" title="霸王别姬" data-act="boarditem-click" data-val="{movieId:1203}">霸王别姬</a></p>
11 <p class="star">
12 主演:张国荣,张丰毅,巩俐
13 </p>
14 <p class="releasetime">上映时间:1993-01-01</p> </div>
15 <div class="movie-item-number score-num">
16 <p class="score"><i class="integer">9.</i><i class="fraction">6</i></p>
17 </div>
18 </div>
19 </div>
20 </dd>
从源码可知,一部电影信息对应的源代码是一个 dd 节点,可用正则表达式提取这里面的一些电影信息。首先提取排名信息,排名信息在 class 为 board-index 的 i 节点内,使用非贪婪方式匹配提取 i 节点内的信息。正则表达式可写为:
<dd>.*?board-index.*?>(.*?)</i>
随后提取电影的图片。可以看到,后面有 a 节点,其内部有两个 img 节点。经过检查后发现,第二个 img 节点的 data-src 属性是图片的链接。这里提取第二个 img 节点的 data-src 属性,正则表达式可以改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
接下还要提取电影的名称,它在后面的 p 节点内, class 为 name 。所以,可以用 name 做一个标志位,然后进一步提取到其内 a 节点的正文内容,此时正则表达式改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
再来提取主演、发布时间、评分等内容,都是同样的原理。最后,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?
fraction.*?>(.*?)</i>.*?</dd>
这样,这个正则表达式就可以匹配一个电影的结果,里面匹配了7个信息。接下来,调用findall()方法提取出所有的内容。
这里还需定义一个解析页面的方法 parse_one_page(),主要是通过正则表达式来从结果中提取出需要的内容。parse_one_page()的代码实现如下所示:
1 def parse_one_page(html):
2 pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?'
3 'name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?'
4 'releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?'
5 'fraction.*?>(.*?)</i>.*?</dd>', re.S)
6 items = re.findall(pattern, html)
7 print(items)
这样就将一页的10个电影信息都提取出来了,这是一个元组列表形式。输出如下所示:
1 [('1', 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', '霸王别姬', '\n 主演:张国荣,张丰毅,巩俐\n ', '上映时间:1993-01-01', '9.', '6'),
2 ('2', 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', '肖申克的救赎', '\n 主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿\n ', '上 映时间:1994-10-14(美国)', '9.', '5'),
3 ('3', 'https://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', '罗马假日', '\n 主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特\n ', '上映时间:1953-09-02(美国)', '9.', '1'),
4 ('4', 'https://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', '这个杀手不太冷', '\n 主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼\n ', '上映时间:1994-09-14(法国)', '9.', '5'),
5 ('5', 'https://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', '教父', '\n 主演:马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩\n ', '上映时间:1972-03-24(美国)', '9.', '3'),
6 ('6', 'https://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', '泰坦尼克号', '\n 主演:莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩\n ', '上映时间:1998-04-03', '9.', '5'),
7 ('7', 'https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c', '唐伯虎点秋香', '\n 主演:周星驰,巩俐,郑佩佩\n ', '上映时间:1993-07-01(中国香港)', '9.', '2'),
8 ('8', 'https://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c', '千与千寻', '\n 主演:柊瑠美,入野自由,夏木真理\n ', '上映时间:2001-07-20(日本)', '9.', '3'),
9 ('9', 'https://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c', '魂断蓝桥', '\n 主演:费雯·丽,罗伯特·泰勒,露塞尔·沃特森\n ', '上映 时间:1940-05-17(美国)', '9.', '2'),
10 ('10', 'https://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c', '乱世佳人', '\n 主演:费雯·丽,克拉克·盖博,奥 利维娅·德哈维兰\n ', '上映时间:1939-12-15(美国)', '9.', '1')]
这个结果有些杂乱,下面再将匹配结果处理一下,遍历结果并生成字典,parse_one_page()方法修改如下:
1 def parse_one_page(html):
2 pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?'
3 'name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?'
4 'releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?'
5 'fraction.*?>(.*?)</i>.*?</dd>', re.S)
6 items = re.findall(pattern, html)
7 for item in items:
8 yield {
9 'index': item[0],
10 'image': item[1],
11 'title': item[2].strip(),
12 'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
13 'time': item[4].strip()[5:] if len(item[4]) > 5 else '',
14 'score': item[5].strip() + item[6].strip()
15 }
main()函数修改如下:
1 ef main():
2 url = 'https://maoyan.com/board/4'
3 html = get_one_page(url)
4 for item in parse_one_page(html):
5 print(item)
这时成功提取出电影的排名、图片、标题、演员、时间、评分等内容了,并把它赋值为一个个的字典,形成结构化数据。运行结果如下:
{'index': '1', 'image': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'score': '9.6'}
{'index': '2', 'image': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
{'index': '3', 'image': 'https://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02(美国)', 'score': '9.1'}
{'index': '4', 'image': 'https://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', 'title': '这个杀手不太冷', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14(法国)', 'score': '9.5'}
{'index': '5', 'image': 'https://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', 'title': '教父', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '1972-03-24(美国)', 'score': '9.3'}
{'index': '6', 'image': 'https://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', 'title': '泰坦尼克号', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'time': '1998-04-03', 'score': '9.5'}
{'index': '7', 'image': 'https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c', 'title': '唐伯虎点秋香', 'actor': '周星驰,巩俐,郑佩佩', 'time': '1993-07-01(中国香港)', 'score': '9.2'}
{'index': '8', 'image': 'https://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c', 'title': '千与千寻', 'actor': '柊瑠美,入野自由,夏木真理', 'time': '2001-07-20(日 本)', 'score': '9.3'}
{'index': '9', 'image': 'https://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c', 'title': '魂断蓝桥', 'actor': '费雯·丽,罗伯特·泰勒,露塞尔·沃特森', 'time': '1940-05-17(美国)', 'score': '9.2'}
{'index': '10', 'image': 'https://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c', 'title': '乱世佳人', 'actor': '费雯·丽,克拉克·盖博,奥利维娅·德哈维兰', 'time': '1939-12-15(美国)', 'score': '9.1'}
3、将结果写入文件
将提取结果写入文件,这里直接写入到一个文本文件中。通过JSON库的dumps()方法实现字典的序列化,并指定ensure ascii参数为False,这样可以保证输出结果是中文形式而不是Unicode 编码。代码如下:
1 def write_to_file(content): 2 """将获取结果写入文件,使用json.dumps()方法写入""" 3 with open('result.txt', 'a', encoding='utf-8') as f: 4 print(type(json.dumps(content))) 5 # 先将字符json序列化再写入 6 f.write(json.dumps(content, ensure_ascii=False) + '\n')
通过调用write_to_file()方法就能实现将字典写入到文本文件的过程。content参数就是一部电影的提取结果,是一个字典。
接下来修改main()方法来调用平面的实现的方法,将单面的电影结果写入到文件。main()代码如下所示:
1 def main():
2 """主函数,通过主函数调用其它函数"""
3 url = 'https://maoyan.com/board/4'
4 html = get_one_page(url)
5 for item in parse_one_page(html):
6 #print(item)
7 write_to_file(item)
这样就完成了单页电影的提取,也是首页10部电影的信息成功保存到文本文件中。
4、分页爬取
前面只爬取了一页10部电影的内容,需要给连接传入 offset 参数,继续爬取另外90部电影,添加如下调用即可:
if __name__ == '__main__': for i in range(10): main(offset=i * 10)
还需要将main()方法做下修改,让其接收offset值作为偏移量,然后构造URL进行爬取。修改后如下所示:
1 def main(offset):
2 """主函数,通过主函数调用其它函数"""
3 url = 'https://maoyan.com/board/4?offset=' + str(offset)
4 html = get_one_page(url)
5 for item in parse_one_page(html):
6 print(item)
7 write_to_file(item)
到这里基本完成了猫眼电影TOP100的爬虫。最终完整代码如下所示。由于猫眼多了反爬虫,如果速度过快,则会无响应,所以下面代码增加了延时等待。
1 import requests, re, json, time
2 from requests.exceptions import RequestException
3
4 def get_one_page(url):
5 """获取网页源代码"""
6 try:
7 headers = {
8 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)'
9 'Chrome/65.0.3352.162 Safari/537.36'
10 }
11 response = requests.get(url, headers=headers)
12 # 如果成功获取就返回网页源代码,否则返回None
13 if response.status_code == 200:
14 return response.text
15 return None
16 except RequestException:
17 return None
18
19 def parse_one_page(html):
20 """解析源代码,使用生成器方法生成字典返回"""
21 pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?'
22 'name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?'
23 'releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?'
24 'fraction.*?>(.*?)</i>.*?</dd>', re.S)
25 items = re.findall(pattern, html)
26 for item in items:
27 yield {
28 'index': item[0],
29 'image': item[1],
30 'title': item[2].strip(),
31 'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
32 'time': item[4].strip()[5:] if len(item[4]) > 5 else '',
33 'score': item[5].strip() + item[6].strip()
34 }
35
36 def write_to_file(content):
37 """将获取结果写入文件,使用json.dumps()方法写入"""
38 with open('result.txt', 'a', encoding='utf-8') as f:
39 # print(type(json.dumps(content))) # 字符串类型
40 # 先将字符json序列化再写入
41 f.write(json.dumps(content, ensure_ascii=False) + '\n')
42
43 def main(offset):
44 """主函数,通过主函数调用其它函数"""
45 url = 'https://maoyan.com/board/4?offset=' + str(offset)
46 html = get_one_page(url)
47 for item in parse_one_page(html):
48 print(item)
49 write_to_file(item)
50
51 if __name__ == '__main__':
52 for i in range(10):
53 main(offset=i * 10)
54 time.sleep(1) # 每次循环延时1秒
运行上面程序,打开result.txt文本文件,可以看到TOP100的电影信息成功获取到。例如下面所示:
1 {"index": "1", "image": "https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c", "title": "霸王别姬", "actor": "张国荣,张丰毅,巩俐", "time": "1993-01-01", "score": "9.6"}
2 {"index": "2", "image": "https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c", "title": "肖申克的救赎", "actor": "蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿", "time": "1994-10-14(美国)", "score": "9.5"}
3 ...
4 {"index": "98", "image": "https://p1.meituan.net/movie/a1634f4e49c8517ae0a3e4adcac6b0dc43994.jpg@160w_220h_1e_1c", "title": "迁徙的鸟", "actor": "雅克·贝汉,Philippe Labro", "time": "2001-12-12(法国)", "score": "9.1"}
5 {"index": "99", "image": "https://p0.meituan.net/movie/885fc379c614a2b4175587b95ac98eb95045650.jpg@160w_220h_1e_1c", "title": "阿飞正传", "actor": "张国荣,张曼玉,刘德华", "time": "2018-06-25", "score": "8.8"}
6 {"index": "100", "image": "https://p0.meituan.net/movie/c304c687e287c7c2f9e22cf78257872d277201.jpg@160w_220h_1e_1c", "title": "龙猫", "actor": "帕特·卡洛尔,蒂姆·达利,丽娅·萨隆加", "time": "2018-12-14", "score": "9.2"}
到此就完成了猫眼电影TOP100的抓取任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号