多线程和多进程
Q:为什么要引入多线程
A:提升程序运行的速度
进程和线程的定义
- 一个工厂,至少有一个车间,一个车间至少有一个工人,最终是工人在工作
- 一个程序,至少有一个进程,一个进程中至少有一个线程,最终是线程在工作
- python程序运行时,内部会创建一个进程(主进程),在进程中创建了一个线程(主线程),由线程逐行运行代码
- 线程,是计算机中可以被cpu调度的最小单元
- 进程,是计算机资源分配的最小单元(进程为线程提供资源)
多线程
一个工厂,创建一个车间,这个车间里面有3个工人并行处理任务
一个程序,创建一个进程,这个进程里面有3个线程并行处理任务
# 导入包
import threading
# 创建一个线程
t = threading.Thread(target='该线程要执行的函数名', args=('参数1', '参数2', '参数3',))
# 执行名为t的线程
t.start()多进程
一个工厂,创建3个车间,每个车间里面有1个工人(共3人)并行处理任务
一个程序,创建3个进程,每个进程里面有1个线程(共3个)并行处理任务
# 导入包
from multiprocessing import Process
# 创建进程的时候,默认会创建一个线程,线程是cpu调度的最小单元
p = Process(target='该进程要执行的方法', args=('方法的参数',))
# 启动进程
p.start()GIL全局解释器锁
GIL,全局解释器锁是Cpython特有解释器特有的,让一个进程中同时只有一个线程可以被CPU调用
如果程序想利用计算机多核优势,让CPU同时同时处理一些任务,适合用多进程并发(资源消耗大)
如果程序不利用多核优势,适用于多线程并发
计算密集型,用多进程,例如大量的数据计算
IO密集型,用多线程,例如文件读写、网络数据传输
join()
程序执行的时候,会创建一个进程,默认创建一个主线程,主线程里面可以创建有多个子线程
join方法是等待当前子线程执行完毕,继续往下执行主线程,如果不用join,子线程执行过程中会继续执行主线程
import threading
t = threading.Thread(target='',args=('',))
t.start()
t.join()守护线程
t.setDeamon(布尔值) 必须放在start之前
t.setDeamon(True) 设置为守护线程,主线程执行完毕之后,子线程也自动关闭
t.setDeamon(False) 设置为非守护线程,主线程等待子线程执行完毕之后,主线程才结束(默认)线程名设置和获取
t.setname() start之前设置,给当前线程创建线程名
threading.current_thread() 获取当前执行的线程名自定义线程类
import threading
# 创建类,继承threading.Thread
class MyThread(threading.Thread):
# 定义run方法,内部逻辑为线程要执行的逻辑
# run方法是内置方法,不可修改函数名
def run(self):
...
t = MyThread(args=('参数',))
t.start()线程安全
一个进程中可以有多个线程,且线程共享所有进程中的资源
多个线程同时操作一个东西,可能会出现数据混乱的情况
如下 两个线程t1和t2,给线程加锁,两个线程会先申请加锁,先加锁成功的线程继续执行,没有申请成功的线程等待有锁的线程完毕释放锁,再次申请加锁执行
import threading
# 创建线程锁
lock_object = threading.RLock()
def t1():
lock_object.acquire() # 加锁
...
lock_object.release() # 释放锁
def t2():
lock_object.acquire() # 加锁
...
lock_object.release() # 释放锁也可以基于上下文的方式管理锁
# 创建线程锁
lock_object = threading.RLock()
with lock_object: # 内部自动执行acquire和release
print('开始执行')线程锁
Lock 同步锁,性能效率更高
Lock不支持嵌套锁,比如一个线程内执行方法 多个内容 加锁、释放锁、加锁....会形成死锁
Rlock 递归锁
Rlock支持嵌套锁,不会形成死锁

死锁
死锁,由于竞争资源或者彼此通信而造成的一种阻塞现象
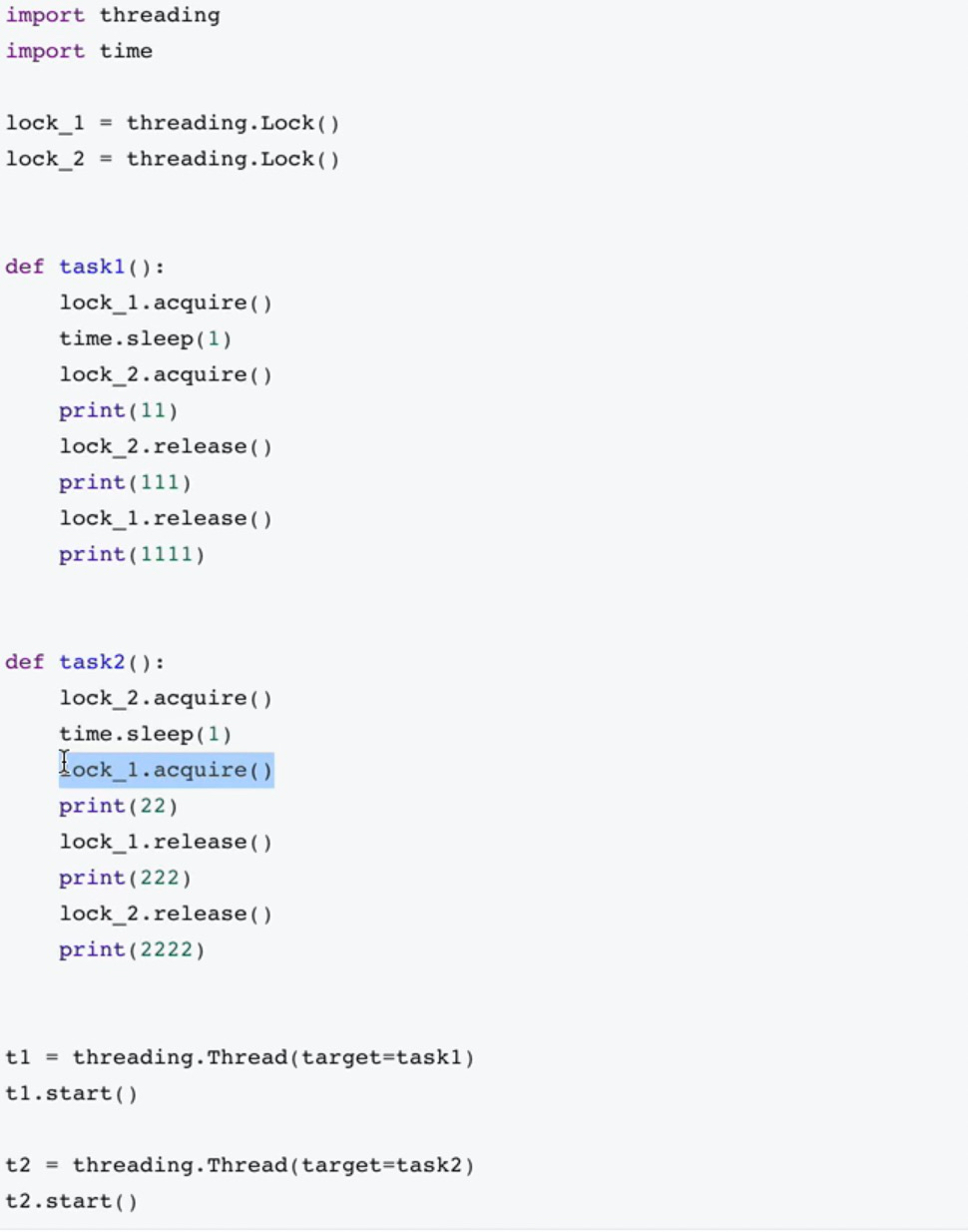
线程池
线程不是开的越多越好,开的多了可能会导致系统性能更低
# 导入
from concurrent.futures import ThreadPoolExecutor
# 创建线程池
# max_workers 代表该线程池维护的线程数
pool = ThreadPoolExecutor(max_workers=100)
# 使用submit将要执行的方法交给线程池
# 线程池会使用一个线程进行执行
pool.submit('函数名','参数1','参数2')
# 等待线程池中的所有任务执行完毕,才会继续往下执行
# 类似线程的join
pool.shutdown(True) 如果线程池维护数量为10,但是我们提交了20次线程任务,那么线程池会先执行10个任务,等有线程释放继续执行后续
线程分工
def done(response):
# 线程返回值的内容
print(response.result)
# 线程池会使用一个线程进行执行
future = pool.submit('函数名', '参数1', '参数2')
# 子线程执行完毕 执行该方法
future.add_done_callback(done)
例如我们可以启动一个线程做上传,done来做下载
风月都好看,人间也浪漫.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号