shardingsphere核心分片-sql改写
数据分片的核心流程第三步就是SQL改写,是由改写引擎完成的。其中包括正确性改写、和优化改写。

这是摘自shardingSphere官网的一张图片。
其中正确性改写将面向开发人员操作的逻辑表改写为通过路由后获取的真实表,如果有分库也需要改写为真实的数据源。除此以外还需要设计补列、分页信息修正等,用来保证
结果的正确性。
优化改写的目的是在不影响查询正确性的情况下,对性能进行提升的有效手段。它分为单节点优化和流式归并优化。
标识符改写
需要改写的标识符包括 :表名称、索引名称以及schema名称。比如一个逻辑表操作:
select user_id from t_order where order_id = 90。
将逻辑表替换为真实表后:
select user_id from t_order_0 where order_id = 90。
补列
shardingsphere在查询语句中需要进行补列的情况一般有两种:
1.shardingSphere需要对结果进行归并时但是该数据并未通过查询的SQL返回。典型的就是order by 和group by 分组、排序场景。
如一条语句:SELECT order_id FROM t_order ORDER BY user_id;
查询order_id根据 user_id排序,但是返回的结果中并没有user_id,shardingShpere怎么怎么将多个表甚至库中的结果做归并呢?
这里就需要进行补列,将本条SQL改写为 SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
这样进行结果归并的时候我们就可以根据补列之后的user_id数据进行归并。
对于avg这类求平均值的聚合函数也需要进行补列,这里不再过多赘述。
分页修正
从单库分页取数据和多个库分页取数据是不同的,如这条SQL:
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;
下图展示了不进行 SQL 的改写的分页执行结果。(来自shardingShpere官网)
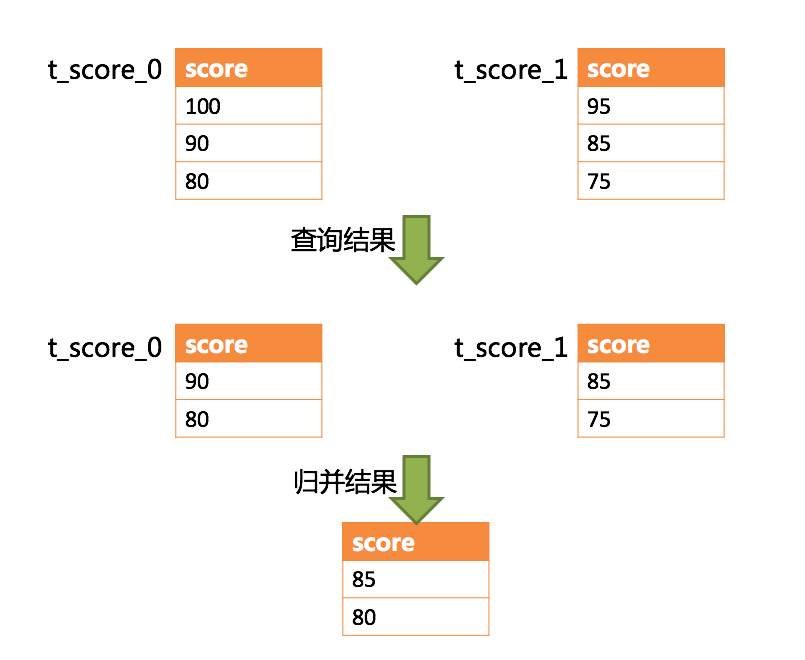
通过图中所示,想要取得两个表中共同的按照分数排序的第 2 条和第 3 条数据,应该是 95 和 90。 由于执行的 SQL 只能从每个表中获取第 2 条和第 3 条数据,即从 t_score_0 表中获取的是 90 和 80;从 t_score_1 表中获取的是 85 和 75。 因此进行结果归并时,只能从获取的 90,80,85 和 75 之中进行归并,那么结果归并无论怎么实现,都不可能获得正确的结果。
正确的做法是将分页条件改写为 LIMIT 0, 3,取出所有前两页数据,再结合排序条件计算出正确的数据。 下图展示了进行 SQL 改写之后的分页执行结果。
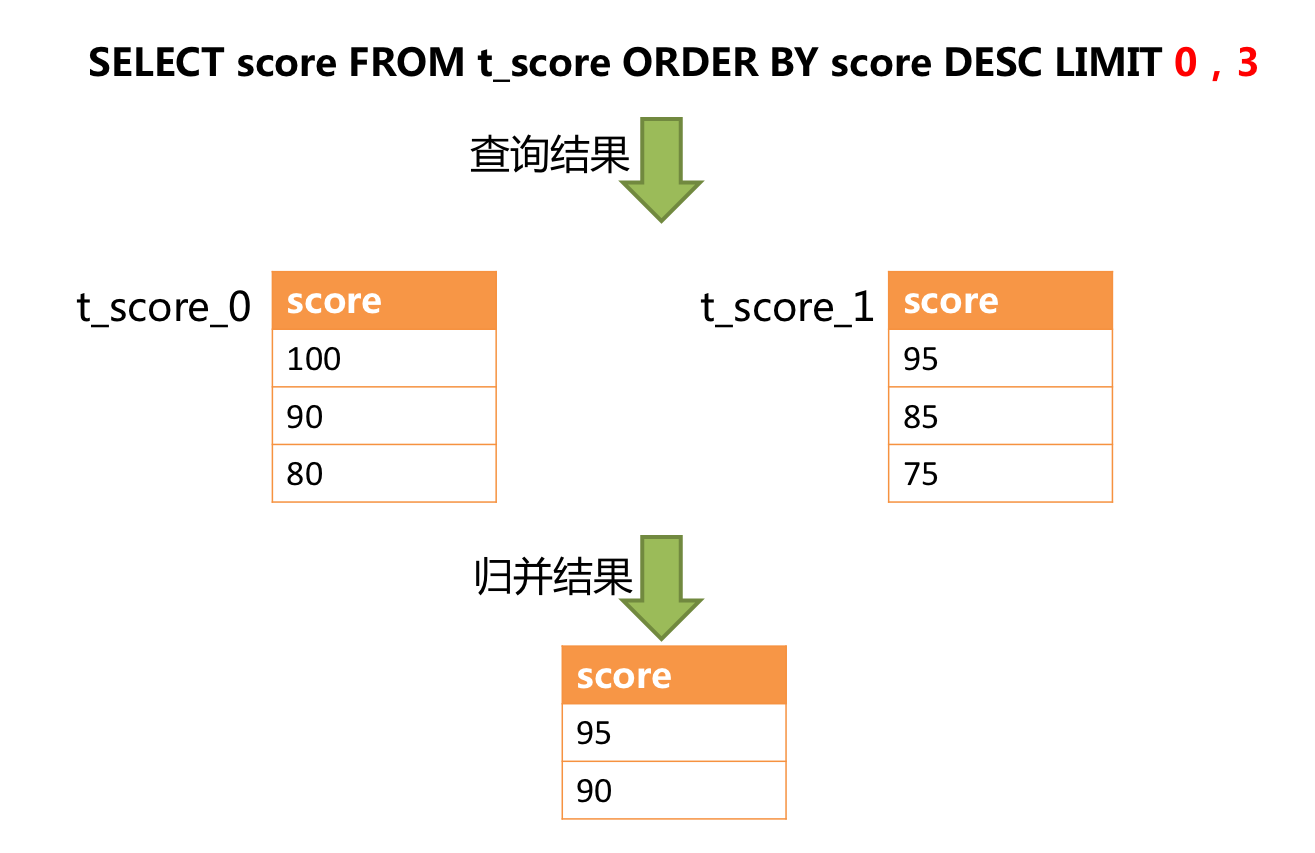
越获取偏移量位置靠后数据,使用 LIMIT 分页方式的效率就越低。 有很多方法可以避免使用 LIMIT 进行分页。比如构建行记录数量与行偏移量的二级索引,或使用上次分页数据结尾 ID 作为下次查询条件的分页方式等。
分页信息修正时,如果使用占位符的方式书写 SQL,则只需要改写参数列表即可,无需改写 SQL 本身。
批量拆分
当使用批量插入语句的时候,如果插入的数据是跨分片的则需要对SQL进行改写防止多余的数据插入库中。如一条SQL:
INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx');如果存在多个分片则需要改成:
insert into t_order_0 (order_id,xxx) values (1,'xxx');
insert into t_order_1(order_id,xxx) values (2,'xxx');
insert into t_order_2(order_id,xxx) values (3,'xxx');
这样的三条语句。
使用 IN 的查询与批量插入的情况相似,不过 IN 操作并不会导致数据查询结果错误。通过对 IN 查询的改写,可以进一步的提升查询性能。如以下 SQL:
select * from t_order where order_id in (1,2,3);可以改写为:
sleect * from t_order_0 where order_in in(1) 和 select * from t_order_1 where order_id in(2,3)。
但是当前版本的shardingSphere(5.0.0)还未实现此策略。目前改写的结果是:
sleect * from t_order_0 where order_in in(1,2,3);
select * from t_order_1 where order_id in(1,2,3);
单节点优化
路由至单节点的 SQL,则无需优化改写。 当获得一次查询的路由结果后,如果是路由至唯一的数据节点,则无需涉及到结果归并。因此补列和分页信息等改写都没有必要进行。 尤其是分页信息的改写,无需将数据从第 1 条开始取,大量的降低了对数据库的压力,并且节省了网络带宽的无谓消耗。
流式归并优化
它仅为包含 GROUP BY 的 SQL 增加 ORDER BY 以及和分组项相同的排序项和排序顺序,用于将内存归并转化为流式归并。具体如何归并是归并引擎的处理。
以上就是shardingSphere中改写引擎的一些说明,主要是参考了shardingSphere的官网文档。下面看一下具体运行流程是如何的
在KernelProcessor核心处理器类中我们可以找到SQL改写的入口处
public ExecutionContext generateExecutionContext(LogicSQL logicSQL, ShardingSphereMetaData metaData, ConfigurationProperties props) { RouteContext routeContext = this.route(logicSQL, metaData, props); SQLRewriteResult rewriteResult = this.rewrite(logicSQL, metaData, props, routeContext); ExecutionContext result = this.createExecutionContext(logicSQL, metaData, routeContext, rewriteResult); this.logSQL(logicSQL, props, result); return result; }
将上一步路由后的上下文作为参数交由改写引擎进行改写。
之后进入SQLRewriteEntry类的rewite方法。
public SQLRewriteResult rewrite(final String sql, final List<Object> parameters, final SQLStatementContext<?> sqlStatementContext, final RouteContext routeContext) { SQLRewriteContext sqlRewriteContext = createSQLRewriteContext(sql, parameters, sqlStatementContext, routeContext); return routeContext.getRouteUnits().isEmpty() ? new GenericSQLRewriteEngine().rewrite(sqlRewriteContext) : new RouteSQLRewriteEngine().rewrite(sqlRewriteContext, routeContext); }
如果没有路由单元信息直接进行改写,如果有路由单元信息则调用RouteSQLRewriteEngine对每个路由单元进行改写。所谓路由单元简单理解就是shardingSphere对每一个最终路由的结果的
封装。
我们直接看RouteSQLRewriteEngine内部:
public RouteSQLRewriteResult rewrite(final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) { Map<RouteUnit, SQLRewriteUnit> result = new LinkedHashMap<>(routeContext.getRouteUnits().size(), 1); for (RouteUnit each : routeContext.getRouteUnits()) { result.put(each, new SQLRewriteUnit(new RouteSQLBuilder(sqlRewriteContext, each).toSQL(), getParameters(sqlRewriteContext.getParameterBuilder(), routeContext, each))); } return new RouteSQLRewriteResult(result); }
这里构建了一个HashMap来存储每个路由单元改写的结果,之后就是循环遍历每个路由单元进行改写放入Map之后组装为RouteSQLRewriteResult返回。
真正的改写在new RouteSQLBuilder(sqlRewriteContext, each).toSQL()这个toSQL()。通过AbstractSQLBuilder这个顶级抽象类我们看一下
public final String toSQL() { if (context.getSqlTokens().isEmpty()) { return context.getSql(); } Collections.sort(context.getSqlTokens()); StringBuilder result = new StringBuilder(); result.append(context.getSql(), 0, context.getSqlTokens().get(0).getStartIndex()); for (SQLToken each : context.getSqlTokens()) { result.append(each instanceof ComposableSQLToken ? getComposableSQLTokenText((ComposableSQLToken) each) : getSQLTokenText(each)); result.append(getConjunctionText(each)); } return result.toString(); }
这里构建了一个StringBuilder将经过sql解析后的sqlToken排序进行追加,并且SQL解析步骤已经标记了改写位置,在合适的位置将会从路由信息中拿到真实表名称进行token的替换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号