
shardingsphere核心分片-sql路由
sql路由作为数据分片的核心步骤在shardingSphere中由路由引擎来实现,通过解析引擎解析后的statement,提取关键的信息构建statementContext
为路由引擎提供支持。
我们从一条sql语句执行时去看看路由引擎如何路由的
public ResultSet executeQuery() throws SQLException { ShardingSphereResultSet result; try {
//清除上一次的缓存信息 this.clearPrevious();
//创建执行上下文 this.executionContext = this.createExecutionContext();
//调用执行器真正执行sql List<QueryResult> queryResults = this.executeQuery0();
//结果归并,这是一个查询的sql可能会需要结果集进行归并 MergedResult mergedResult = this.mergeQuery(queryResults); result = new ShardingSphereResultSet(this.getResultSetsForShardingSphereResultSet(), mergedResult, this, this.executionContext); } finally { this.clearBatch(); } this.currentResultSet = result; return result; }
上述代码属于ShardingSpherePreparedStatement这个类,我们知道shardingsphere中sharding-jdbc实现分片功能是通过包装jdbc层来实现的,这里
就是包装了PreparedStatement。真正的路有隐情在创建执行上下文的时候会进行,执行上下文中包含了已经路由好的结果已经sql改写的结果。
进入这个创建执行上下文的方法
private ExecutionContext createExecutionContext() { LogicSQL logicSQL = this.createLogicSQL(); SQLCheckEngine.check(logicSQL.getSqlStatementContext().getSqlStatement(), logicSQL.getParameters(), this.metaDataContexts.getDefaultMetaData().getRuleMetaData().getRules(), "logic_db", this.metaDataContexts.getMetaDataMap(), (Grantee)null); ExecutionContext result = this.kernelProcessor.generateExecutionContext(logicSQL, this.metaDataContexts.getDefaultMetaData(), this.metaDataContexts.getProps()); this.findGeneratedKey(result).ifPresent((generatedKey) -> { this.generatedValues.addAll(generatedKey.getGeneratedValues()); }); return result; }
在这里第一步 创建LogicSQL这样一个对象,这个对象比较简单,里面包含了StatementContext、当前的sql以及向sql中设置的参数信息。
第二步通过SQLCheckEngine对SQL进行检查,校验合法性等信息,这个校验我看shardingShpere中没有具体的实现SQLChecker的类,
通过shardingsphere这种SPI实现的微内核架构,我们可以快速的将自己的SQLChecker注册到shardingSphere中进行我们自定义的校验。
接下来第三部就是通过核心处理器来真正生成执行上下文。
public ExecutionContext generateExecutionContext(LogicSQL logicSQL, ShardingSphereMetaData metaData, ConfigurationProperties props) { RouteContext routeContext = this.route(logicSQL, metaData, props); SQLRewriteResult rewriteResult = this.rewrite(logicSQL, metaData, props, routeContext); ExecutionContext result = this.createExecutionContext(logicSQL, metaData, routeContext, rewriteResult); this.logSQL(logicSQL, props, result); return result; }
进入我们的KernelProcessor类,这里我们终于看到了路由的真正入口。这个方法中第一步就是路由之后进行sql改写然后将结果生成执行上下文。
接下来就会通过路由引擎执行路由逻辑
public RouteContext route(LogicSQL logicSQL, ShardingSphereMetaData metaData) { SQLRouteExecutor executor = this.isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement()) ? new AllSQLRouteExecutor() : new PartialSQLRouteExecutor(this.rules, this.props); return ((SQLRouteExecutor)executor).route(logicSQL, metaData); }
通过SQLRouteExecutor路由执行器来进行路由,其中第一步会进行一个路由器的选择,如果我们的SQL类型属于MySQLShowTablesStatement这时会创建一个AllSQLRouteExecutor,否则
则会创建PartialSQLRouteExecutor。MySQLShowTablesStatement包含什么?比如就是 show tables这条语句,AllSQLRouteExecutor顾名思义就是一个全部路由,里面的路由返回的结果
就是将我们所有的数据库配置和表配置组成对应的节点返回。重点是我们的PartialSQLRouteExecutor。
public PartialSQLRouteExecutor(final Collection<ShardingSphereRule> rules, final ConfigurationProperties props) { this.props = props; routers = OrderedSPIRegistry.getRegisteredServices(SQLRouter.class, rules); } @Override @SuppressWarnings({"unchecked", "rawtypes"}) public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) { RouteContext result = new RouteContext(); for (Entry<ShardingSphereRule, SQLRouter> entry : routers.entrySet()) { if (result.getRouteUnits().isEmpty()) { result = entry.getValue().createRouteContext(logicSQL, metaData, entry.getKey(), props); } else { entry.getValue().decorateRouteContext(result, logicSQL, metaData, entry.getKey(), props); } } if (result.getRouteUnits().isEmpty() && 1 == metaData.getResource().getDataSources().size()) { String singleDataSourceName = metaData.getResource().getDataSources().keySet().iterator().next(); result.getRouteUnits().add(new RouteUnit(new RouteMapper(singleDataSourceName, singleDataSourceName), Collections.emptyList())); } return result; }
在PartialSQLRouteExecutor中主要有一个构造器和route方法,在构造器里根据rules(分片规则)去获取了所有的SQLRouter,包括shardingSQLRouter、ReadwriteSplittingSQLRouter、ShadowSQLRouter
等。我们现在配置的Rules只有shardingRules也就是分库分表的规则配置,并不涉及读写分离的规则或者影子库的规则等,没有与之共同使用。所以这里根据ruls获取的SQLRouter
只有我们的ShardingSQLRouter进行分库分表的路由配置。
通过shardingSQLRouter进入我们的构造上下文
public RouteContext createRouteContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ShardingRule rule, final ConfigurationProperties props) { RouteContext result = new RouteContext(); SQLStatement sqlStatement = logicSQL.getSqlStatementContext().getSqlStatement(); Optional<ShardingStatementValidator> validator = ShardingStatementValidatorFactory.newInstance(sqlStatement); validator.ifPresent(optional -> optional.preValidate(rule, logicSQL.getSqlStatementContext(), logicSQL.getParameters(), metaData.getSchema())); ShardingConditions shardingConditions = createShardingConditions(logicSQL, metaData, rule); boolean needMergeShardingValues = isNeedMergeShardingValues(logicSQL.getSqlStatementContext(), rule); if (sqlStatement instanceof DMLStatement && needMergeShardingValues) { mergeShardingConditions(shardingConditions); } ShardingRouteEngineFactory.newInstance(rule, metaData, logicSQL.getSqlStatementContext(), shardingConditions, props).route(result, rule); validator.ifPresent(v -> v.postValidate(rule, logicSQL.getSqlStatementContext(), result, metaData.getSchema())); return result; }
在这个构建上下文的方法中,主要对Statement进行一个校验,之后创建shardingConditions,shardingConditions就是分片条件,里面包含了我们分片键的列名以及分片键的值。
可以看到:
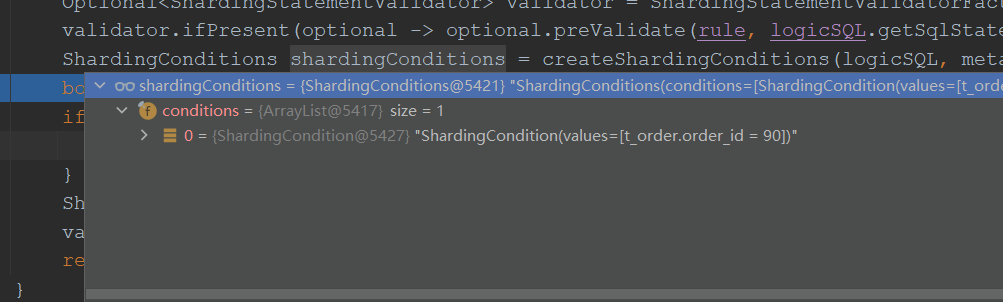
这是shardingConditions里面有一个ShardingCondition的list,里面存储了每个分片键以及对应的信息。这里我作为演示的是使用的标准分片策略用来处理单键分片,
而且是一个精确分片算法,不是between 、in这种范围分片。我们可以看到我们的分片键order_id以及分片键的值为90。这些信息就是通过我们sql解析时生成的statement
对象和参数信息生成的。之后就可以根据这些conditions信息进行路由。
之后进入我们的shardingRouteEngine中的getDataNodes方法中。
private Collection<DataNode> getDataNodes(final ShardingRule shardingRule, final TableRule tableRule) { ShardingStrategy databaseShardingStrategy = createShardingStrategy(shardingRule.getDatabaseShardingStrategyConfiguration(tableRule), shardingRule.getShardingAlgorithms()); ShardingStrategy tableShardingStrategy = createShardingStrategy(shardingRule.getTableShardingStrategyConfiguration(tableRule), shardingRule.getShardingAlgorithms()); if (isRoutingByHint(shardingRule, tableRule)) { return routeByHint(tableRule, databaseShardingStrategy, tableShardingStrategy); } if (isRoutingByShardingConditions(shardingRule, tableRule)) { return routeByShardingConditions(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy); } return routeByMixedConditions(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy); }
在这里我们datasource的配置和table的配置都使用的是标准分片策略,所以shardingsphere这里选择是 ShardingStandardRoutingEngine来进行处理。
通过这个方法我们可以看到,首先会根据配置的分片策略和算法去创建对应的表的和数据库的ShardingStrategy,在demo中这里两个都是StandardShardingStrategy。
值得一提的是 shardingSphere支持四种策略,标准分片策略、强制路由、复杂分片策略以及不分片策略。标准分片策略用来处理单键分片,与标准分片算法
配合;复杂分片策略用于处理多个分片键的路由与复杂分片算法配置。强制路由使用HintManager自定义传入分片值以及自定义算法实现。不分片策略则是没有分片的
情况下可以使用。
通过判断是否强制路由或者根据condition分片路由来决定如何路由,如果数据库或者表其中一个是hint方式另一个是分片方式则会进行混合路由。
进入分片路由逻辑:
private Collection<DataNode> routeByShardingConditions(final ShardingRule shardingRule, final TableRule tableRule, final ShardingStrategy databaseShardingStrategy, final ShardingStrategy tableShardingStrategy) { return shardingConditions.getConditions().isEmpty() ? route0(tableRule, databaseShardingStrategy, Collections.emptyList(), tableShardingStrategy, Collections.emptyList()) : routeByShardingConditionsWithCondition(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy); }
判断conditions是否为空如果为空则传入一个emptyList直接进行真正的路由,否则遍历我们的conditions通过condition进行路由。
private Collection<DataNode> route0(final TableRule tableRule, final ShardingStrategy databaseShardingStrategy, final List<ShardingConditionValue> databaseShardingValues, final ShardingStrategy tableShardingStrategy, final List<ShardingConditionValue> tableShardingValues) { Collection<String> routedDataSources = routeDataSources(tableRule, databaseShardingStrategy, databaseShardingValues); Collection<DataNode> result = new LinkedList<>(); for (String each : routedDataSources) { result.addAll(routeTables(tableRule, each, tableShardingStrategy, tableShardingValues)); } return result; }
将通过condition解析好的对应的数据库分片键以及表的分片键构建为List类型的ShardingConditionValue,这个shardingVlue就包含了分片键的名称以及值。
先通过数据库的ShardingConditionValue去路由所用的数据库,在根据表的ShardingConditionValue去路由表,然后将路由的每一个表节点添加至上一步路由
后的每一个数据库节点。这样所有需要访问的数据节点就已经确定了。
我们看一下具体是如何路由的
public Collection<String> doSharding(final Collection<String> availableTargetNames, final Collection<ShardingConditionValue> shardingConditionValues, final ConfigurationProperties props) { ShardingConditionValue shardingConditionValue = shardingConditionValues.iterator().next(); Collection<String> shardingResult = shardingConditionValue instanceof ListShardingConditionValue ? doSharding(availableTargetNames, (ListShardingConditionValue) shardingConditionValue) : doSharding(availableTargetNames, (RangeShardingConditionValue) shardingConditionValue); Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER); result.addAll(shardingResult); return result; }
我们可以看分片策略类中的doSharding方法,这里会最终调用配合我们策略使用的算法中的doSharding来实现真正的计算。
主要看一下dmeo中的分片算法使用,这里时用了shardingSphere的内置INLINE算法。
@Override public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Comparable<?>> shardingValue) { Closure<?> closure = createClosure(); closure.setProperty(shardingValue.getColumnName(), shardingValue.getValue()); return closure.call().toString(); } @Override public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Comparable<?>> shardingValue) { if (allowRangeQuery) { return availableTargetNames; } throw new UnsupportedOperationException("Since the property of `" + ALLOW_RANGE_QUERY_KEY + "` is false, inline sharding algorithm can not tackle with range query."); }
INLINE算法就是我们提供一个行表达式,之后shardingSphere通过计算表达式的值来确定具体路由的结构。比如 表的INLINE分片算法的表达式 t_order_${order_id % 2}
最终shardingSphere就会跟个order_id的值对2进行取模组成真正的表结点如 t_order_0或者t_order_1。
我们可以看到这个类有两个doSharding的方法。第一个是精确分片这里时处理 = 和 in这种分片键的,因为这里所有的分片值我们可以枚举出来。对于in中多个值会进行循环
处理,每次传入一个确定的值。
第二个方法是针对范围分片的,主要用来处理 between and , < , >,<=,>=的,这些分片值都是一个范围的东西。当然INLINE算法一般不支持范围分片的。如果允许范围分片
它就会返回所有可用的表或者数据源信息。
以上就上路由的全部流程,当然里面有些部分和细节没有写出来,以后会仔细研究一下在补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号