

shardingsphere核心分片-sql解析
shardingshopere数据分片功能中的主要内核实现流程:sql解析->sql路由->sql改写->sql执行->结果归并
分别由解析引擎、路由引擎、改写引擎、执行引擎以及归并引擎实现。解析引擎作为实现数据分片功能
的第一步,为接下来的路由获取分片键condition做下基础工作。
首先我们进入sql解析引擎的入口类ShardingSphereSQLParserEngine看一下这个类都做了什么。
public final class ShardingSphereSQLParserEngine { private final SQLStatementParserEngine sqlStatementParserEngine; private final DistSQLStatementParserEngine distSQLStatementParserEngine; public ShardingSphereSQLParserEngine(final String databaseTypeName) { sqlStatementParserEngine = SQLStatementParserEngineFactory.getSQLStatementParserEngine(databaseTypeName); distSQLStatementParserEngine = new DistSQLStatementParserEngine(); } /* * To make sure SkyWalking will be available at the next release of ShardingSphere, a new plugin should be provided to SkyWalking project if this API changed. * * @see <a href="https://github.com/apache/skywalking/blob/master/docs/en/guides/Java-Plugin-Development-Guide.md#user-content-plugin-development-guide">Plugin Development Guide</a> */ /** * Parse to SQL statement. * * @param sql SQL to be parsed * @param useCache whether use cache * @return SQL statement */ @SuppressWarnings("OverlyBroadCatchBlock") public SQLStatement parse(final String sql, final boolean useCache) { try { return parse0(sql, useCache); // CHECKSTYLE:OFF // TODO check whether throw SQLParsingException only } catch (final Exception ex) { // CHECKSTYLE:ON throw ex; } } private SQLStatement parse0(final String sql, final boolean useCache) { try { return sqlStatementParserEngine.parse(sql, useCache); } catch (final SQLParsingException | ParseCancellationException originalEx) { try { return distSQLStatementParserEngine.parse(sql); } catch (final SQLParsingException ignored) { throw originalEx; } } } }
我们可以看到这个类很简单,有一个构造方法需要传入一个对应的databaseType,有一个public方法parse和private方法parse0。
从这里我们可以知道,parse方法作为整个sql解析的开始,之后再调用私有方法parse0交由SQLStatementParserEngine 来进
行解析。SQLStatementParserEngine这是一个专门用来解析SQL的引擎,最终会将sql信息封装为一个SQLStatement对象返回。
值得我们注意的是,构造方法中通过databaseType获取对应数据库类型的SQLStatementParserEngine,然后又构造了一个Dist
SQLStatementParserEngine的对象,这个对象是专门用来解析DistSQL语句的,所谓distSql就是shardingSphere自身的一套语言,
比如我们创建一个表的分片规则,除了yaml配置、javaAPI构造等还可以通过shardingSphere定义的distSQL规则去创建。在这里
如果解析正常的sql失败抛出异常后就会调用DistSQLStatementParserEngine去尝试解析看是否是一个distSQL。
再调用SQLStatementParserEngine进行解析时useCache这个参数会传为true,意味着将会使用缓存,对用相同的sql提高解析的效率,
避免再次解析。
我们进入SQLStatementParserEngine看一下这里面做了什么?
private final SQLStatementParserExecutor sqlStatementParserExecutor;
private final LoadingCache<String, SQLStatement> sqlStatementCache;
public SQLStatementParserEngine(final String databaseType) {
sqlStatementParserExecutor = new SQLStatementParserExecutor(databaseType);
// TODO use props to configure cache option
sqlStatementCache = SQLStatementCacheBuilder.build(new CacheOption(2000, 65535L, 4), databaseType);
}
/**
* Parse to SQL statement.
*
* @param sql SQL to be parsed
* @param useCache whether use cache
* @return SQL statement
*/
public SQLStatement parse(final String sql, final boolean useCache) {
return useCache ? sqlStatementCache.getUnchecked(sql) : sqlStatementParserExecutor.parse(sql);
}
除了构造器就是一个parse方法,这里明显又是一个门面,并不是真正执行解析的地方,这里只有一个构造器和parse方法,
当useCache为true时会直接从本地缓存中获取解析的sql否则则调用SQLStatementParserExecutor这个执行器去解析sql。
在这里,使用的是google guava包中的本地缓存,通过SQLStatementCacheBuilder这个类我们去看一下这个缓存怎么构建
的。
public final class SQLStatementCacheBuilder { /** * Build SQL statement cache. * * @param option cache option * @param databaseType database type * @return built SQL statement cache */ public static LoadingCache<String, SQLStatement> build(final CacheOption option, final String databaseType) { return CacheBuilder.newBuilder().softValues() .initialCapacity(option.getInitialCapacity()).maximumSize(option.getMaximumSize()).concurrencyLevel(option.getConcurrencyLevel()).build(new SQLStatementCacheLoader(databaseType)); } }
通过CacheBuilder提供的API去构造并且传入了一个CacheLoader->SQLStatementCacheLoader,SQLStatementCacheLoader这个类主要重写了CacheLoader的load方法,调用
SQLStatementParserExecutor来解析sql。总的来说就是使用缓存的时候会调用到LocalCache的getOrLoad,当缓存中没有数据时就会通过传入的CacheLoader缓存加载器来执行
load方法将数据缓存并返回结果。具体和这个缓存怎么用有兴趣可以去看看guava的源码,这里不再多赘述。
以上我们可知经过ShardingSphereSQLParserEngine->SQLStatementParserEngine后会调用SQLStatementParserExecutor这个解析执行器来执行我们解析。
public final class SQLStatementParserExecutor {
private final SQLParserEngine parserEngine;
private final SQLVisitorEngine visitorEngine;
public SQLStatementParserExecutor(final String databaseType) {
parserEngine = new SQLParserEngine(databaseType);
visitorEngine = new SQLVisitorEngine(databaseType, "STATEMENT", new Properties());
}
/**
* Parse to SQL statement.
*
* @param sql SQL to be parsed
* @return SQL statement
*/
public SQLStatement parse(final String sql) {
return visitorEngine.visit(parserEngine.parse(sql, false));
}
}
这个类的代码也很简单,主要工作是通过访问者模式来处理经过SQLParseEngine解析好的结果。
public final class SQLParserEngine { private final SQLParserExecutor sqlParserExecutor; private final LoadingCache<String, ParseTree> parseTreeCache; public SQLParserEngine(final String databaseType) { this(databaseType, new CacheOption(128, 1024L, 4)); } public SQLParserEngine(final String databaseType, final CacheOption cacheOption) { sqlParserExecutor = new SQLParserExecutor(databaseType); parseTreeCache = ParseTreeCacheBuilder.build(cacheOption, databaseType); } /** * Parse SQL. * * @param sql SQL to be parsed * @param useCache whether use cache * @return parse tree */ public ParseTree parse(final String sql, final boolean useCache) { return useCache ? parseTreeCache.getUnchecked(sql) : sqlParserExecutor.parse(sql); } }
通过SQLParserEngine,最终调用SQLParserExecutor来执行解析。而SQLParserExecutor中会调用真正的SqlParser
去解析SQL并返回一个抽象语法树,我们前边提到的访问者模式的实现SQLVisitorEngine就是来处理这个抽象语法树的,
将这个语法树转换为一个SQLStatement对象返回。
虽然SQL语言相对于其它语言比如java、c、c++等比较来说显得很简单,但是它也是完善的一门编程语言,与其它语言
来说并没有什么不同。
shardingSphere中实现了多种sql的解析如mysqlSQLParser、OracleSQLParser、PGSQLParser以及自身的distSqlParser
等。
解析过程分为词法解析和语法解析。 词法解析器用于将 SQL 拆解为不可再分的原子符号,称为 Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将词法解析器的输出转换为抽象语法树。
比如下面这条sql:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析后的抽象语法树为:
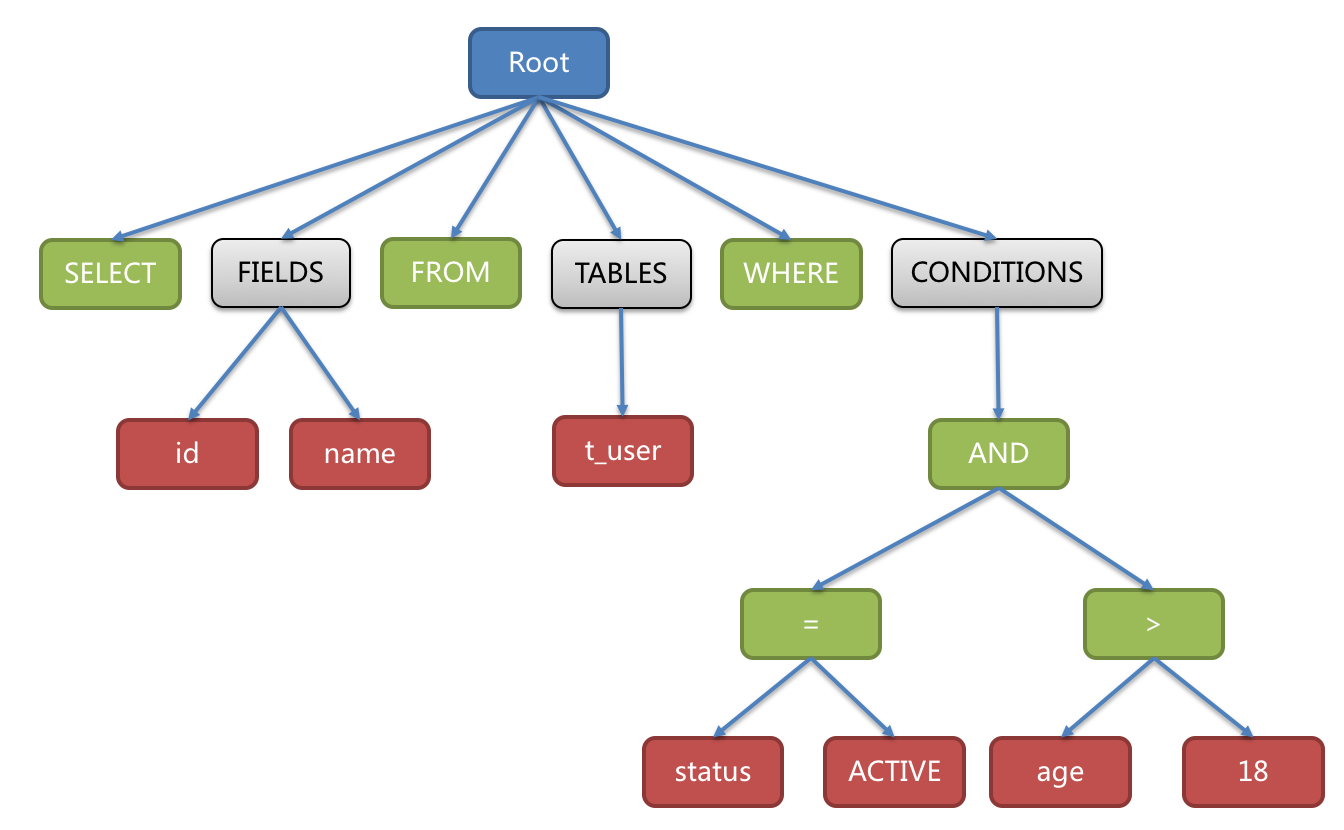
为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进一步拆分。
(上图摘自shardingSphere官网)。
将一条语句经过词法以及语法解析后,会通过SQLVisitorEngine对语法树进行遍历,抽取我们所需要的信息,构建SQL
Statement。我们来看一下SQLStatement中会保存什么信息?以一条带有分片信息的select语句为例。select * from t_order where order_id = ?

我们可以看到有基本的表的信息,where子句信息,分组信息,排序信息等等。
最后在调用PreparedStatement的execute方法时会使用StatementContext来提炼SQLStament中的信息作为本次解析后的上下文。
之后就会进入下一个阶段根据StatementContext上下文信息去通过路由引擎进行路由。

