基于特征和条件随机场的中文地址解析方法
一篇没投的文文章。分享出来。
【摘要】由于中文地址使用缺乏规范和汉语语言的特点,在地址匹配前首先需要进行地址解析,以识别地址中的地址要素和其他成分。传统的基于词典和规则的方法过度依赖词典和规则库,对歧义词和未登录词的识别率低。本文采用自然语言标注的思想,借助条件随机场模型,利用地址成分中的词性特征、用字特征及上下文特征,构建了基于特征的中文地址解析方法,并对地址中空间关系进行了识别。实验表明,基于条件随机场的中文地址解析方法能够达到较好的解析效果,对行政区划、道路和空间关系词汇的识别率均达到了90%以上。由于条件随机场能够表达长距离的上下文依赖,有效地将各种相关或不相关信息融合在一起,因而具有较好的泛化能力和通用性,为进一步的地址匹配打下良好的基础。
【关键词】地址解析;条件随机场;地址特征
0 引言
地理编码将文字描述的地址信息映射到地理空间中,完成了位置文字描述到地理坐标的定量转换。将一系列城市社会经济信息空间化,以便在空间信息地支持下进行信息资源整合、共享、分析和决策应用。地址解析是指将非规范化中文地址转化为赋予地址要素类型的结构化地址的过程[1]。地址解析完成了地址的结构化问题,地址解析是地址标准化和地址匹配的前提,解析的准确性直接影响地址匹配的可行性和匹配的准确性。因此地址解析研究是地理编码研究的核心内容之一。
1 研究背景
在国外,以英语为代表语言中对地址的书写较为规范,如“No.62, Science Avenue, Zhengzhou City, Henan Prov. China”,采用具有独立语义的单词来描述,利用空格和标点符号分割,地址要素类型也较容易确定。而在国内,中文地址命名缺乏规范,加之中文语言的特点,汉语地址解析包含了地址分割和地址要素类型确定两项工作。分割将地址拆分为具有独立地址语义的地址要素,地址要素类型确定是分析各地址要素的含义。如地址“郑州市科学大道62号”分割后为“郑州市/科学大道/62号”;类型标注后为“郑州市[CITY] 科学大道[ROAD] 62号[BNO]”。中文地址解析与中文自然语言处理有很大相似性,研究方法经历了从基于规则(词典)到基于统计的方法的发展历程。在基于词典(规则)的方法方面,张林曼[2]提出了基于双字哈希和数组的三层组合分词词典数据结构,并逐次增字的最大正向分词算法,也通过地名通名识别地址未登录词。张雪英[3]以地名词典和地址数据库为数据源,系统分析了地址要素构词特征和句法模式,从而构建了各类地址要素的特征字库,解析规则库,设计了RBAI中文地址要素解析算法。基于词典的分词方法简单、效率高,但过度依赖词典和规则库,词典的完备性、规则的一致性等原因使其对歧义词和未登录词的识别率低。在基于统计的方法方面:陈旭[4]采用基于N-最短路径的分词算法来识别电话区号、手机号码区段、邮政编码区段等可定位信息。宋子辉[1]使用了隐马尔科夫模型进行了地址要素的标注,并在使用Viterbi算法时加入了地址要素之间的关系约束。唐旭日[5]基于条件随机场(CRF)和篇章地名关系的地名进行识别、提出局部模糊匹配的地名标准化方法和基于认知显著度的地理编码方法,提高了地名的识别精度。蒋文明[6]基于条件随机场(CRF)的中文地址要素识别的方法,对地名地址进行识别和标注。基于语料的统计学习是当前自然语言处理的主流范式,其中条件随机场模型顾及了上下文标记间的转移概率,以序列化形式进行全局参数优化和解码,避免了其他判别式模型(如最大熵马尔科夫模型)的标记偏置问题;能够表达长距离的上下文依赖,有效地将各种相关或不相关信息融合在一起,具有较好的泛化能力和通用性。鉴于这些优点,条件随机场理论也被广泛用于分词、词性标注命名实体识别等诸多领域。
本文将将条件随机场作为地址标注解析的统计模型,并着重研究了地址特征选取,在空间关系地址模型地址标注体系下,训练了地址标注的条件随机场模型,并进行了地址要素标注实验,分析不同地址标注特征对地址解析性能的影响。
(主要讲现有的解析方法和存在的问题,落脚点要落到地址特征和条件随机场上面)
2 地址标注特征选取
地址解析标注除了需要良好的语言模型和大规模的地址标注语料库,还需要与地址标注特征和模板结合起来。本文将地址分割和地址类型确定两个问题一并处理,选取地址中的字(含标点)作为最基本的单元,即条件随机场中所要标注的原子。选用的特征包括了地址的语法特征、用字特征及地址框架特征。语法特征包含了单个汉字、汉字所在的词以及汉字所在词的词性等。用字特征包含了地址要素用字特征、地址空间关系描述词汇用字特征及其他成分的用字特征。框架特征表现为地址的句式,通过地址中长距离上下文依赖特征体现。
2.1地址的语法特征
完成地址的初级分割后,形成的原子包括单个汉字、英文单词、标点符号等,其本身在一定程度上反映了地址用字特征,也是整个特征模板的基础,因此被选为了最基础的地址解析特征。除了单个汉字以外,单字所处的词语及上下文可以反映出单字所在词常用的搭配习惯,特别在地名地址使用中。本文在基于字的模型上,通过分词工具对句子分词,将字所在的词也作为地址解析的参考特征。另外,单字所构成词的词性对于整个句子结构特征有很强的提示作用,无论是地址要素还是地址空间关系词汇,其组成词汇都具有词性要求。如规范的中文地址一般是名词短语,每个名词即地址要素;又如方向特征词为方位词等。这些地址词汇的词性信息不仅能够用来帮助确定地址成分的类型,而且能够用来确定地址成分的分割边界。
本文利用中国科学院计算技术研究所研制ICTCLAS词法分析系统,来分析词的词性,将原子的词性特征标记为其所属词的词性。并将该系统的词位标注也作为条件随机场的模型观测特征。
2.2地址用字特征
地名地址的构成有其丰富的自然环境和历史文化背景。金祖孟在《地名通论》想先阐述通名与地名专名问题[7]。地址是地名的结构化描述,地址的用字特征实际上是地址中地址要素和地址空间关系描述等成分的用字特征。文献[8]分析了中文地名内部结构,将地名成分分为区别性词素、方位词素、类型词素、部位词素以及描写词素几种并分别进行了统计分析。地址中的各成分与地名用字具有相似的的特征,这些地名地址结构特征能够帮助用来进行地名地址解析。本文解析总结了地址要素的用字特征、空间关系词汇用字特征及其他成分用字特征。
1)地址要素的用字特征
地址中经常会出现各级行政区划名、道路名、门址、组织机构名,这些名称通常由通名和专名构成,专名在前、通名在后。除门址外,地址要素的专名复杂而富于变化,如道路名可能由人名作为专名,如“靖宇路”,有可能以城市名作为专名,如“南阳路”,还有可能以河流作为专名,如“黄河路”。专名识别可用的知识库主要依靠地名库。但地址通名相对稳定,具有一定规律,如道路名的后缀有路、街、大道等。本文将原子是否为地址要素通名作为地址解析的特征之一。通过对地址标注语料中各类地址要素的尾字及末尾两字进行统计,得到常用的地址要素通名。如表4.2.
表4.2 地址要素通名表
|
地址要素类型 |
标注 |
通名举例 |
|
省份 |
PRO |
省、自治区 |
|
城市 |
CITY |
市、州 |
|
区县 |
COUNTY |
县、区 |
|
乡镇/街道办 |
STREET |
镇、乡、街道… |
|
居委会/行政村/社区 |
COMMITTEE |
村、社区、坊…… |
|
居民小区/自然村 |
AREA |
小区、屯、寨、院 |
|
道路 |
ROAD |
路、街、胡同、巷、大道、弄…… |
|
门牌号/楼牌号/单元号/楼层/房间号 |
BNO |
号、层、院、座、#、楼、室、栋、元、排、幢、排、#…… |
|
标识物/兴趣点 |
POI |
大厦、广场、公司、店、超市…… |
与将通名作为切分标志进行地址分割的方法相比,将其加入到条件随机场模型特征中的方法仅在一定概率下将尾字作为分词和判定地址要素类型的依据,避免了解析过程的机械性,减少了歧义,同时增强了地址解析灵活性,允许将地址通名特征与词性特征等一同运用到模型中。
2)地址空间关系描述词汇的用字特征
由于人们的空间认知与语言描述习惯,在地址中出现的空间关系词汇是相对稳定的、可以枚举的。参照相关文献对地址中空间关系词汇的分类,对标注语料库中的空间关系词汇进行统计,得到地址中各种空间关系指示词。如表4.3.
4.3 地址中的空间关系词汇用字
|
空间关系词汇类型 |
标注 |
空间关系词汇 |
|
交叉口/邻接关系 |
JUNK |
交叉口、交汇处、交叉处、十字口、十字路口、丁字路口、交叉处、十字 |
|
相接/相接关系 |
BESIDE |
附近、对面、旁、后面、隔壁、斜对面、旁边、斜对面、旁侧 |
|
方向/方向关系 |
ORI |
见表3.4 |
|
距离/距离关系 |
DIS |
米、m、公里、km |
3)其他成分的用字特征
地址中的其他成分包括了连词(如”与”、”和”等,表示并列)、标点符号(逗号、顿号、括号等)和无意义成分三类。无意义成分主要是非规范地址中出现的非地址信息和模糊信息,如”步行20分钟”。前两类成分也可以通过统计大致枚举出来。如表4.4
4.4 地址中其他成分枚举
|
类型 |
标注 |
常用字 |
|
连词 |
AND |
与、和、同、及 |
|
标点符号 |
PUN |
“,”“-”“(”“)”“&” |
首先构建各类地址地址成分的用字词典,将其作为外部知识库。生成用字特征时通过分别与到各类词典中进行匹配,匹配成功标记为”Y”,否则标记为”N”。
2.3地址的框架特征
地址的框架特征对应于自然语言中的句法特征。这是因为地址要素类型的搭配关系具有很强的约束性,以便地址符合语言规范且有意义。如行政区划名严格从大到小、从高到低,某种地址类型前后可能出现的地址类型是相对确定的。张雪英[3]基于规则的地址解析和程昌秀[9]基于规则的地址匹配均使用了这种地址特征字先后顺序特征。条件随机场模型能够融合长距离的上下文相关信息,以便在学习中使用该特征。
3 基于条件随机场的中文地址解析
(解析与标注的关系)[10]
3.1 地址标注的原理
条件随机场模型(Conditional Random Field, CRF)是一种给定一组输入随机变量X(观测序列)条件下另一组输出随机变量Y(状态序列)的条件概率分布模型,其特点是假设输出随机变量之间的联合概率分布构成概率无向图模型,即马尔科夫随机场。用于序列标注的条件随机场是一种线性条件随机场(Linear Chain),最早由John Lafferty[11]在2001年提出用于NLP技术领域。CRF是一种无向图模型,在给定待标记观察序列的条件下,计算整个标记序列的联合概率分布。它一种统计机器学习方法,将该方法应用到地址解析标注中,其精度与地址标注体系、地址语料库大小和准确性、地址标注特征有关。
CRF代表了新一代的机器学习技术分词,利用条件随机进行地址分割,将地址分割过程转换成字符串序列中基于字的词位标注问题。利用分词标注语料集训练出CRF模型,解码时依据成词概率完成词位标注,进而完成分割。基于CRF的分词方法不仅考虑了词语出现的频率信息,而且考虑了长距离的上下文语境,具备较好的学习能力。对歧义词和未登录词的识别也具有良好的效果。
利用条件随机场进行地址成分类型标注就是要确定地址成分的类型。条件随机场模型将地址成分序列看作条件随机场中的观测序列,将地址成分的类型序列作为标注序列(状态序列),求解地址成分类型问题转换为求解地址成分最佳状态序列(标注序列)问题。同样通过利用标注语料库训练CRF模型,解码时再利用模型对输入地址要素序列完成地址要素类型标注。本文采用的地址观测序列包括了地址的语法特征、用字特征和框架特征等。
将地址分割与地址要素解析一同进行时,地址的标注形式为地址成分标注和词位的组合。如下图2.4,在完成单字的标注后,只需利用词位标注前缀完成分词即可。
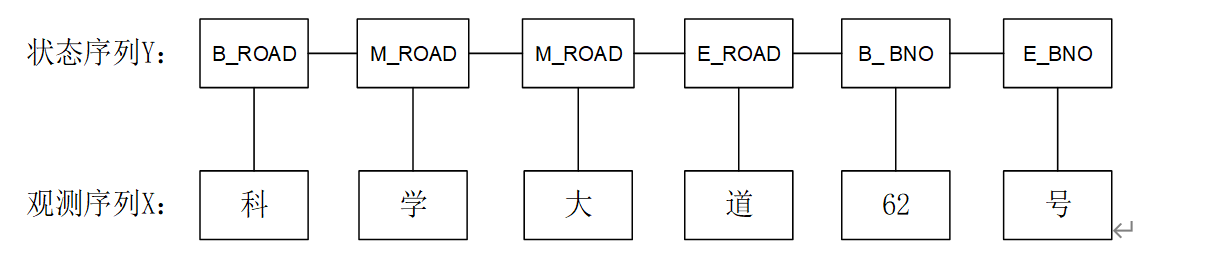
图2.4 基于条件随机场的地址标注原理
3.2 地址标注的一般过程
基于条件随机场的中文地址标注的一般过程如下图:
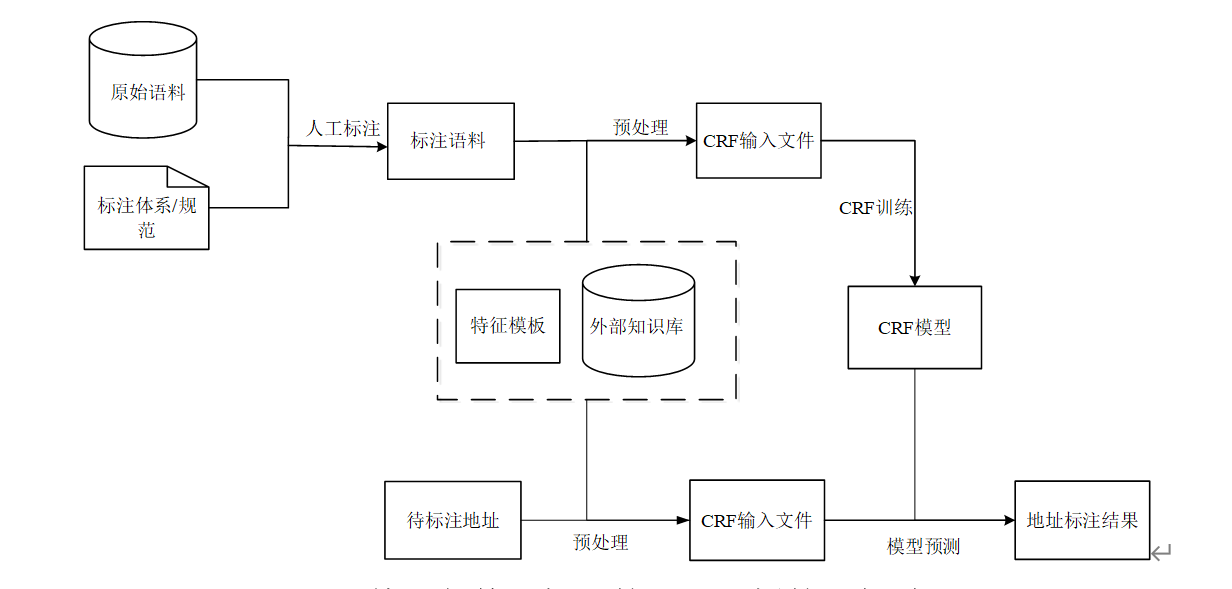
图4.1 基于条件随机场的地址解析的一般过程
基于条件随机场模型的中文地址解析是一种监督的统计学习方法,首先是利用现有地址标注语料训练出条件随机场模型,然后利用模型对测试地址进行标注解析。标注语料和测试语料具有相同的结构,前n-1列均为观测序列,利用选取的标注特征生成相应的观测值;标注语料的第n列为人工标注结果,测试语料的第n列为机器标注的结果。标注语料和测试语料需要进行预处理,以符合条件随机场的输入要求。最后将机器与人对测试语料的标注结果进行对比,以评价模型的标注性能。
3.3 地址标注体系
地址标注体系是地址成分的分类和标识,地址成分的分类是根据词汇在地址中所担任的成分和含义来进行划分的。如“郑州市科学大道62号”进行地址标注后为“郑州市[CITY] 科学大道[ROAD] 62号[BNO]”。参照相关模型[12],本文采用了空间关系模型的地址标注体系,地址要素分类和标识如下表3。
表3 地址标注体系分类及其标识对应表
|
大类 |
记号 |
名称 |
示例 |
|
地址要素 |
PRO |
省份 |
河南省 |
|
CITY |
城市 |
洛阳市 |
|
|
COUNTY |
区/县 |
洛龙区 |
|
|
STREET |
乡/镇/街道办 |
开元路街道办事处 |
|
|
COMMITTEE |
居委会/行政村/社区 |
定鼎门社区 |
|
|
AREA |
居民小区/自然村 |
二郎庙村 |
|
|
ROAD |
道路/街/巷 |
龙门大道 |
|
|
BNO |
楼牌号/单元号/门牌号/楼层/房间号 |
436号 |
|
|
POI |
兴趣点/标志物 |
帝都国际城 |
|
|
空间关系 |
JUNK |
交叉口/邻接关系 |
交叉口 |
|
BESIDE |
模糊偏移关系 |
附近 |
|
|
ORI |
方向/方向关系 |
向东 |
|
|
DIS |
距离/距离关系 |
100m |
|
|
BELONG |
包含关系 |
内 |
|
|
其他成分 |
AND |
连词(表并列) |
与 |
|
PUN |
标点符号(逗号,括号等) |
“,”“-”“#”“&” |
|
|
NONE |
其他 |
|
3.4 特征模板
CRF能够表达长距离的上下文依赖信息,将各种相关、不相关的信息融合在一起使用。设计能充分体现地址序列特性的学习特征模板是决定训练模型识别性能优劣的关键因素之一。在特征模板中,要考虑的上下文特征通过特征及其相对位置来确定。形式化地,特征模板采用%x[row, column]的格式及其组合描述,分别对应原子特征和组合特征。其中row指代与当前条目相邻的其他条目的相对位置,0表示当前条目,正数代表之后的条目,负数代表之前的条目;column指代对应的特征项,0表示第1列的特征,n表示第n+1列特征。row 的取值在“上下文”窗口范围内,窗口的选择要恰当。窗口过大,特征的增加会影响运行效率,并产生过拟合现象;窗口过小,丢失上下文信息,并影响标注的性能。一般选取的窗口为2,即[-2,+2]。有了特征模板就能够更加灵活的处理特征,并结合上下文产生具体标注特征。
4 实验验证及结果分析
4.1评价指标及实验数据
(1)评价指标
采用自然语言处理领域的评测指标评测地址要素识别的性能,即准确率P(Precision)、召回率R(Recall Rate)和综合指标(F值)。
|
正确的 |
不正确的 |
|
|
识别出来的 |
true positives(tp) |
false positives(fp) |
|
未识别出来的 |
false negatives(fn) |
true negatives(tn) |
召回率是模型实际识别的正确结果占应该正确识别结果的比例;准确率是模型实际识别的正确结果占被识别出的结果的比例;F值是对召回率和准确率的一种综合评价。
(2)实验数据
将地址分割的词位标注与成分的类型标注结合在一起进行,标注集为词位标注与类型标注的乘积,如“B_ PRO”表示省份的开头,“E_ CITY”表示城市的结尾。实验采用郑州市和洛阳市城区地址标注语料共计有58000余条,400多万字。条件随机场实例为付仲恺的开源项目CRFSharp,该项目公布了条件随机场所有源码,便于修改以便测评。测试数据采用另外不重复的729条语料。
4.2实验结果及分析
实验对比不同地址标注特征对条件随机场模型标注性能的影响,设计4组对比实验,上下文窗口均设为[-2,+2]。四组实验条件所采用的特征如下表4.5
表4.5 各组实验条件对比
|
实验编号 |
原子特征 |
词性特征 |
用字特征 |
|
1 |
√ |
|
|
|
2 |
√ |
√ |
|
|
3 |
√ |
|
√ |
|
4 |
√ |
√ |
√ |
地址中单字对地址解析的作用较大,在仅使用单字特征时,解析准确性便达到了91.73%,词性和用字特征对提高识别地召回率和准确率均有帮助。该图说明,在基于条件随机场模型的地址解析中,仅利用地址原子及其上下文特征(第一组)便能达到较高性能,词性对解析性能的提高十分明显,用字特征的加入对解析性能的提高不及词性。第四组的准确性不及第二组,说明解析的性能除了与特征数量还与特征模板设计和特征的准确性等因素有关。从数据中还发现,条件随机场模型对于行政区划、道路、门牌号、方向关键词及模糊偏移关键词偏移关键词的解析性能较高,而对居民小区、兴趣点的性能不高,这可能是因为这两种类型的名称一般对应于空间命名实体,结构复杂,形式多变,且这两种类型的名称之间区别较小,即使人工也较难判断。
5 结论
中文地址解析是地理编码研究的核心任务之一。本文采用条件随机场模型,通过选取有效的地址标注特征,通过监督学习的方法完成了对地址的分割与类型标注。与之前的序列标注模型不同,在条件随机场中,当前的状态不只由这一时刻或局部的观测条件给出,而是与整个序列的状态相关,这更符合实际情况,因此标注结果也相应地有所提升。该方法不依赖于词典,避免了其他方法的标注偏置问题,并允许灵活加入各种特征,对非规范地址的地址解析和结构化具有较好效果。
参考文献
[1] 宋子辉. 自然语言理解的中文地址匹配算法[J]. 遥感学报, 2013, 17(4). DOI:10.11834/jrs.20132164.
[2] 张林曼, 吴升. 地理编码系统中地名地址分词算法研究[J]. 测绘科学, 2010, 35(2):46-48.
[3] 张雪英, 闾国年, 李伯秋等. 基于规则的中文地址要素解析方法[J]. 地球信息科学学报, 2010, 12(1):9-16.
[4] 陈旭. 地理编码引擎的设计与实现[D]. 辽宁工程技术大学, 2009.
[5] 唐旭日, 陈小荷, 张雪英. 中文文本的地名解析方法研究[J]. 武汉大学学报:信息科学版, 2010, (8):930-935.
[6] 蒋文明, 张雪英, 李伯秋. 基于条件随机场的中文地址要素识别方法[J]. 计算机工程与应用, 2010, 46(13):129-131.
[7] 华林甫. 中国地名学源流[M]. 湖南人民出版社, 2002.
[8] 唐旭日, 陈小荷. 中文地名结构的定性与定量分析[C]//第四届全国学生计算语言学研讨会会议论文集. 2008.
[9] 程昌秀, 于滨. 一种基于规则的模糊中文地址分词匹配方法[J]. 地理与地理信息科学, 2011, 27(3): 26-29.
[10] 周海. 基于条件随机场和空间推理的地理编码方法[D]. 解放军信息工程大学, 2015.
[11] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[J]. 2001.
[12] 周海, 杜泽欣, 范瑞杰,等. 空间关系地址模型及其表达模式分析[J]. 测绘工程, 2016, 25(5):25-31.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号