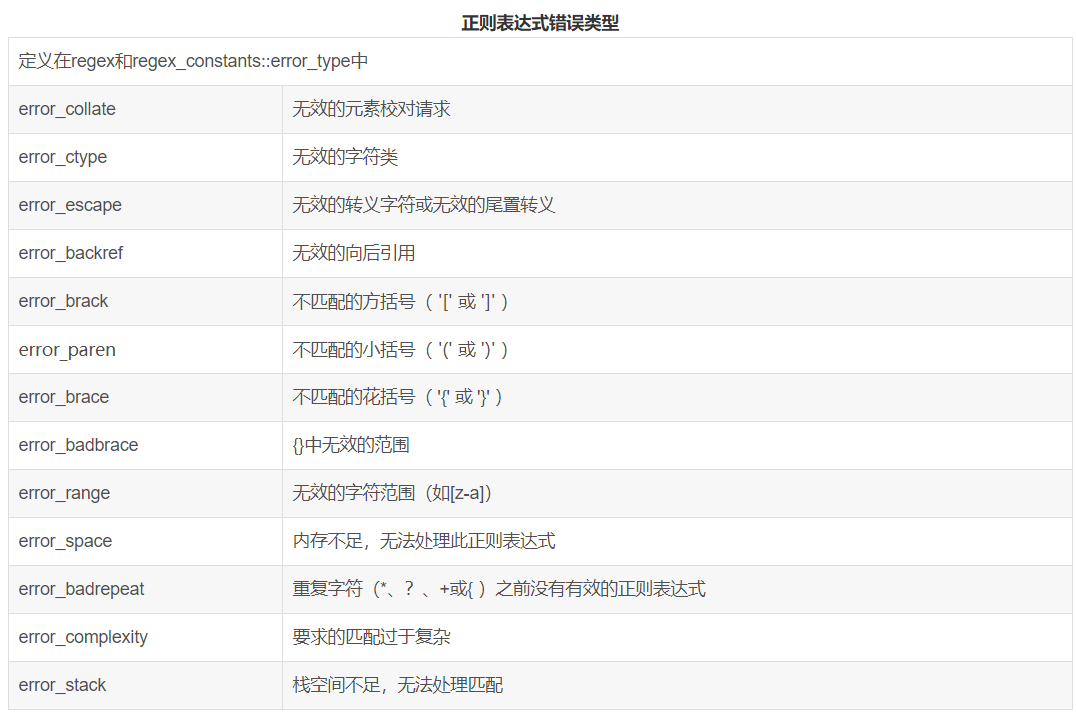
正则表达式
# 正则表达式
正则表达式是一种描述字符序列的方法,是一种极其强大的计算工具。本文 重点介绍如何是使用C++正则表达式库(RE库),它是C++11新标准的一部分。
RE库定义在头文件regex中,它包含多个组件,如下表所示:
| 正则表达式库组件 | |
|---|---|
| regex | 表示有一个正则表达式的类 |
| regex_match | 将一个字符序列与一个正则表达式匹配 |
| regex_search | 寻找第一个与正则表达式匹配的子序列 |
| regex_replace | 使用给定格式替换一个正则表达式 |
| sregex_iterator | 迭代器适配器,调用regex_search来遍历一个string中所有匹配的子串 |
| smatch | 容器类,保存在string中搜索的结果 |
| ssub_match | string中匹配的子表达式的结果 |
使用正则表达式库
从一个简单的例子开始——查找违反拼写规则“i除非在c之后,否则必须在e之前”的单词
#include <iostream>
#include <regex>
using namespace std;
int main()
{
string pattern("[^c]ei");
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern); //构造一个用于查找模式的regex
smatch results; //定义一个对象保存搜索结果
string test_str = "receipt freind theif receive";
if (regex_search(test_str, results, r))
{
cout << results.str() << endl;
}
return 0;
}
正则表达式[c]表明我们希望匹配任意不是'c'的字符,而[c]ei指出我们想要匹配这种字符后接ei的字符串。此模式描述的字符串刚好是三个字符,为了与整个单词匹配,还需要一个正则表达式与这三个字母模式之前和之后的字母匹配。
默认情况下,regex使用的正则表达式语言是ECMAScript。在ECMAScript中,模式[[:alpha:]]匹配任意字母,符号 + 和 * 分别表示我们希望“一个或多个” 或“零个或多个”匹配。
函数regex_search在输入序列中只要找到一个匹配子串就会停止查找,因此结果输出是
freind
指定regex对象的选项
regex r(re)
regex r(re, f)
re表示一个正则表达式,它可以是一个string、一个表示字符范围的迭代对、一个指向空字符结尾的字符数组的指针、一个字符指针和一个计数器或是一个花括号包围的字符列表。
f是指出对象如何处理的标志。f通过下面列出的值来设置。如果未指定f,默认值为ECMAScript。
r1 = re
将r1中的正则表达式替换成re。
re表示一个正则表达式,它可以是另一个regex对象、一个string、一个指向空字符结尾的字符数组的指针或是一个花括号包围的字符列表。
r1.assign(re, f)
与使用赋值运算符(=)效果相同
r.mark_count()
r中子表达式的数目
r.flags()
返回r的标志集
| 定义regex时指定的标志 | |
|---|---|
| icase | 在匹配过程中忽略大小写 |
| nosubs | 不保存匹配的子表达式 |
| optimize | 执行速度优于构造速度 |
| ECMAScript | 使用ECMA-262语法 |
一个正则表达式来识别扩展名的示例:
//1个或多个字母或数字字符后面接一个'.'再接"cpp"或"cxx"或"cc"
regex r("([[:alnum:]+)\\.(cpp|cxx|cc)$", regex::icase);
smatch results;
string filename;
while( cin >> filename)
if( regex_search(filename, results, r))
cout << results.str() << endl;
在正则表达式语言中,字符点(.)通常匹配任意字符。与C++一样,可以在字符之前放置一个反斜线\来去掉其特殊含义。由于反斜线\也是C++中的一个特殊字符,我们在字符串常量中必须连续使用两个反斜线。
一个正则表达式的语法是否正确是在运行时解析的。如果我们编写的正则表达式存在错误,则在运行时标准库会抛出一二类型为regex_error的异常。类似标准库异常类型,regex_error有一个描述发生什么错误的what操作,和一个返回错误类型对应的数值编码的code成员。
try{
regex r("([[:alnum:]+)\\.(cpp|cxx|cc)$", regex::icase);
}catch (regex_error e)
{
cout << e.what() << "\ncode:" << e.code() << endl;
}
- 正则表达式类和输入序列类型
我们使用的RE库类型必须与输入序列类型匹配。例如
regex r("([[:alnum:]+)\\.(cpp|cxx|cc)$", regex::icase);
smatch results;
if( regex_search("myfile.cc", results, r)) //错误:输入为char*
cout << results.str() << endl;
这段代码编译失败,因为match参数的类型与输入序列的类型不匹配。
cmatch results;
if( regex_search("myfile.cc", results, r)) //正确
cout << results.str() << endl;
匹配与Regex迭代器类型
在第一个查找违反单词拼写规则例子中,它只打印输入序列中第一个匹配的单词。我们可以使用sregex_iterator来获取所有匹配。regex迭代器是一种迭代器适配器,被绑定到一个输入序列和一个regex对象上。
| sregex_iterator it(b, e, r); | 一个sregex_iterator,遍历迭代器b和e表示的string。它调用sregex_search(b, e, r)将it定位到输入中第一个匹配的位置 |
|---|---|
| sregex_iterator end; | sregex_iterator的尾后迭代器 |
当我们将一个sregex_iterator绑定到一个string和一个regex对象时,迭代器自动定位到给定string中第一个匹配位置。
//查找不在字符c之后的字符串ei
string pattern("[^c]ei");
pattern = "[[:alpha:]]" + pattern + "[[:alpha:]]*";
regex r(pattern, regex::icase); //构造一个用于查找模式的regex
string test_str = "receipt freind theif receive";
for (sregex_iterator it(test_str.begin(), test_str.end(), r), end_it;
it != end_it; ++it)
cout << it->str() << endl;
end_it是一个空的sregex_iterator,起到尾后迭代器的作用。
Output:
freind
thief
匹配类型有两个名为prefix和suffix的成员,分别返回表示输入序列中当前匹配之前和之后部分的ssub_match对象。一个ssub_match对象有两个名为str和length的成员,分别返回匹配的string和该string的大小
for( sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it)
{
auto pos = it->prefix().length(); //前缀大小
pos = pos > 40 ? pos - 40 : 0; //我们想要最多40个字符
cout << it->prefix().str().substr(pos) //前缀的最后一部分
<< "\n\t\t" << it->str() << " <<<\n" //匹配的单词
<< it->suffix().str().substr(0, 40) //后缀的第一部分
<< endl;
}
这里补充下substr()用法:
// string::substr
#include <iostream>
#include <string>
int main ()
{
std::string str="We think in generalities, but we live in details.";
// (quoting Alfred N. Whitehead)
std::string str2 = str.substr (3,5); // "think"
std::size_t pos = str.find("live"); // position of "live" in str
std::string str3 = str.substr (pos); // get from "live" to the end
std::cout << str2 << ' ' << str3 << '\n';
return 0;
}
Output:
`think live in details. `
使用子表达式
正则表达式中的模式通常包含1个或多个子表达式(subexpression)。一个子表达式是模式的一部分,本身也具有意义。正则表达式语法通常用括号来表示子表达式。
regex r("([[:alnum:]+)\\.(cpp|cxx|cc)$", regex::icase);
这个模式保护两个括号括起来的子表达式:
([[:alnum:]]+),匹配1个或多个字符的序列(cpp|cxx|cc),匹配文件扩展名
if( regex_search(filename, results, r))
cout << results.str(1) << endl;
匹配对象除了提供匹配整体的相关信息外,还提供访问模式中每个子表达式的能力。子匹配是按位置来访问的。第一个子匹配位置为0,表示整个模式对应的匹配,随后是每个子表达式对应的匹配。
例如如果文件名为foo.cpp,则results.str(0)将保存foo.cpp,results.str(1)将保存foo,results.str(2)将保存cpp。
验证必须匹配特定格式的数据
-
{d}表示单个数字,而{d}{n}则表示一个n个数字的序列。(如:{d}{3}匹配三个数字的序列)
-
在方括号中的字符集合表示匹配这些字符中的任意一个。(如:[-. ]匹配一个短横线或一个点或一个空格。注意,点再括号中没有特殊含义)
-
后接'?'的组建是可选的。(如:{d}{3}[-. ]?{d}{4}匹配序列是开始是三个数字,后接一个可选的短横线或点或空格,然后是四个数字。此模式可以匹配555-0132或555.0132或555 0132或5550132)
-
类似C++,ECMAScript使用反斜线\表示一个字符本身而不是其特殊含义。由于我们的模式包括括号,而括号是ECMAScript中的特殊字符,因此必须使用 和和 来表示括号是我们模式的一部分而不是特殊字符。
由于反斜线\是C++的特殊字符,在模式中每次出现\的地方,必须用一个额外的反斜线来告知是反斜线而不是特殊字符。即我们用\{d}{3}来表示正则表达式{d}{3}。
string phone =
"(\\()?\\{d}{3}(\\))?([-. ])?(\\{d}{3})([-. ])?(\\{d}{4})";
regex r(phone);
smatch m;
string s;
while(getline(cin, s))
{
for( sregex_iterator it(s.begin(), s.end(), r), end_it;
it != end_it; ++it)
{
if(valid(*it))
cout << "valid:" << it->str() << endl;
else
cout << "not valid:" << it->str() << endl;
}
}
上述代码是匹配美国电话号码的模式示例:
- (\()? :表示区号部分可选的左括号
- \{d}{3} :表示区号
- (\))? :表示区号部分可选的右括号
- ([-. ])? :表示区号部分可选的分隔符
- (\{d}{3}) :表示号码的下三位数字
- ([-. ])? :表示可选的分隔符
- (\{d}{4}) :表示号码的最后四位数字
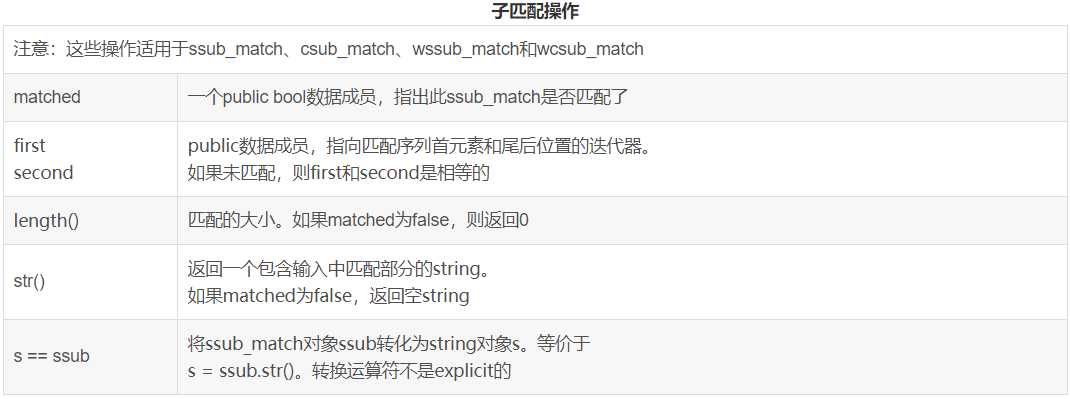
使用子匹配操作
我们将使用下表描述的子匹配操作来编写valid函数。上述代码的pattern有7个子表达式。每个smatch对象会包含8个ssub_match元素。如果一个子表达式是完整匹配的一部分,则其对应的ssub_match对象的matched成员是true。
bool valid(const smatch &m)
{
//如果区号前有一个左括号
if(m[1].matched)
//则区号后面有一个右括号,且之后紧跟剩余号码或一个空格
return m[3].matched &&
(m[4].matched == 0 || m[4].str() == " ");
else
//否则,区号后面不能有由括号,且后两个组成部分间的分隔符必须匹配
return !m[3].matched &&
m[4].str() == m[6].str();
}
使用regex_replace
正则表达式不仅用在我们希望查找一个给定序列的时候,还用在当我们想将找到序列替换成另一个序列的时候。此时,可以调用regex_replace。它接受一个输入字符序列和一个regex对象,还接受一个描述我们想要输出形式的字符串。
m.format(dest, fmt, mft)
m.format(fmt, mft)
使用格式字符串 fmt 生成格式化输出。匹配在m中,可选的match_flag_type标志在mft中。
第一个版本写入迭代器dest指向的目的位置并接受 fmt 参数,可以是一个string,也可以是表示字符数组范围的一对指针。
第二个版本返回一个string,保存输出,并接受 fmt 参数,可以是一个string,也可以是一个指向空字符结尾的字符数组指针。
mft的默认值为format_default
regex_replace(dest, seq, r, fmt ,mft)
regex_replace( seq, r, fmt , mft)
遍历seq,用regex_search查找和regex对象r匹配的子串。使用格式字符串fmt和可选match_flag_type标志来生成输出
第一个版本写入迭代器dest指向的目的位置并接受一对迭代器seq表示范围。
第二个版本返回一个string,保存输出,且seq即可以是一个string,也可以是一个指向空字符结尾的字符数组指针。
在所有情况下, fmt即可以是一个string,也可以是一个指向空字符结尾的字符数组指针。mft的默认值为match_default
替换字符串由我们想要的字符组合与匹配的子串对于的子表达式而组成。我们用一个符号$后跟子表达式的索引号来表示一个特定的子表达式:
string phone =
"(\\()?\\{d}{3}(\\))?([-. ])?(\\{d}{3})([-. ])?(\\{d}{4})";
string fmt = "$2.$5.$7";
regex r(phone);
string number = "(908) 555-1800";
cout << regex_replace(number, r, fmt) << endl;
Output
908.555.1800
参考:《C++ Primer》 第五版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号