
Chrome历史记录分析
360浏览器采用的是Chrome开源内核。两个浏览器的数据库文件结构一样。
参考文献:www.doc88.com/p-6971366976640.html 杨雪 靳慧云 《Chrome 浏览器历史记录提取与分析》
1、历史记录的提取
sqlite是一款基于磁盘的轻量级关系型数据库管理系统,。浏览器中 Chrome、Firefox、Safari等常用浏览器均使用sqlite存储及管理用户的web访问行为。
Chrome浏览器历史记录数据存储在名为History的sqlite数据库文件中。
- 数据库表urls存储用户访问的URL,
- visits 存储用户每次web浏览的属性,
- keyword_search_terms 存储用户检索过的关键字。
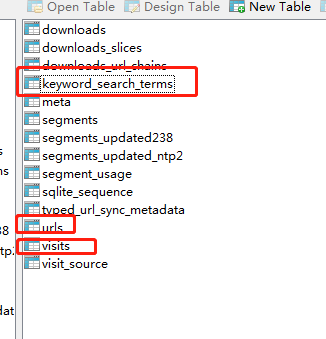
URLS表结构
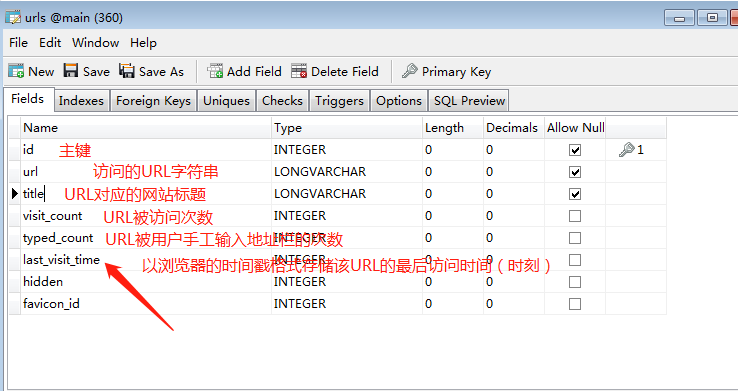
visits 表结构
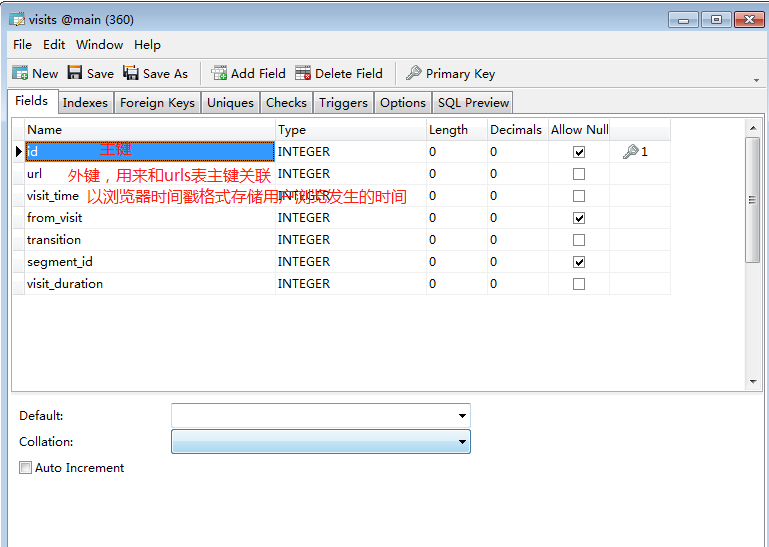
keyword_search_terms 表结构
时间数据的处理
由于Chrome浏览器在sqlite中存储的时间是以1601-01-01 00:00:00 为起始时间点的微妙计数,与Unix时间戳存在时间间隔。因此研究人员输入时间后,需要先把该时间转换为Unix时间戳,再通过时间间隔补偿得到与Chrome浏览器历史记录相匹配的时间戳格式,从而筛选出对应的记录。
此处进行时间转换的具体代码为:
datetime(datetime(visite_time/1000000)+(strftime('%s','1601-01-01')),'unixe-poch','localtime')
举例:

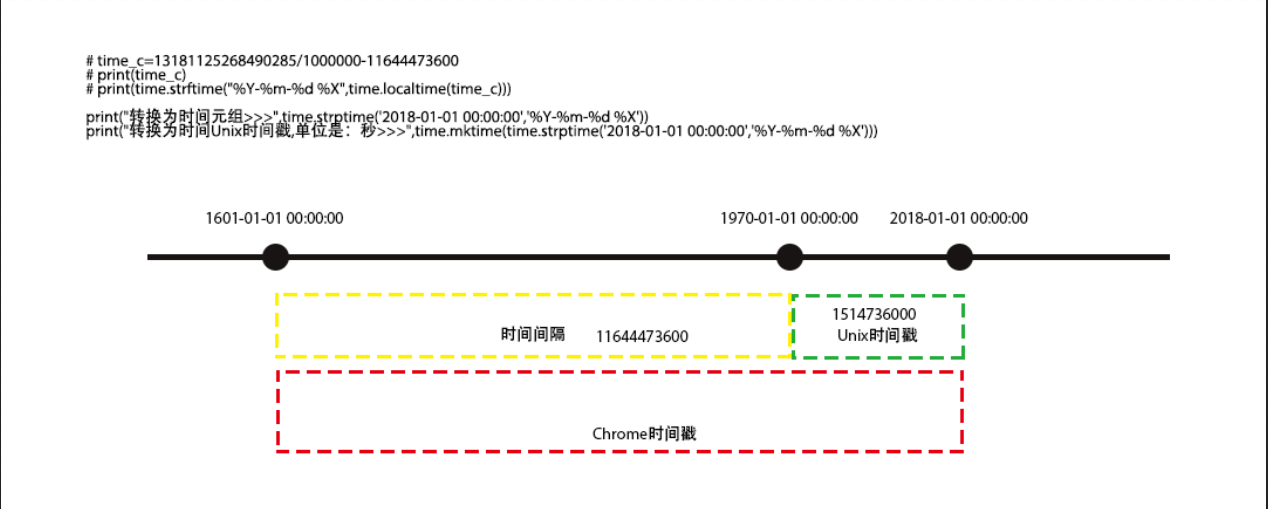
DOS的时间基准是1980年1月1日,
Unix的时间基准是1970年1月1日上午12 点,
Linux的时间基准是1970年1月1日凌晨0点。
Windows的时间基准是1601年1月1日。
时间转换:
1秒(s) = 1000毫秒(ms)
1毫秒(ms) = 1000微秒(us)
1微秒(us) = 1000纳秒(ns)
1 纳秒(ns) = 1000皮秒(ps)



#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import time ''' -- 13181125268490285 微秒 -- select datetime('now') -- 2018-10-17 03:07:55 -- select datetime('now','localtime') -- 2018-10-17 11:07:23 -- 13181125268490285 微秒 Chrome时间戳 -- 13181125268.490285 秒 Chrome时间戳 -- 11644473600 间隔 -- 13181125268490-11644473600 拿到的是Unix时间戳 -- 先转换为时间元组''' time_c=13181125268490285/1000000-11644473600 print(time_c) print(time.strftime("%Y-%m-%d %X",time.gmtime(time_c)))
1 2 | print("转换为时间元组>>>",time.strptime('2018-01-01 00:00:00','%Y-%m-%d %X'))print("转换为时间Unix时间戳,单位是:秒>>>",time.mktime(time.strptime('2018-01-01 00:00:00','%Y-%m-%d %X'))) |
2、域名聚合
取到二级域名。将用户访问的大量URL访问记录转化为用户访问的域名,以便在此基础上进行数据挖掘及关联分析。
3、频繁项集挖掘
假设 所有聚合后的域名为集合D,统计D中的中子项出现的频数。 可以展示出用户最常访问的TOP-N 个网站的域名。
4、关键词关联分析
用户检索的关键词是其WEB浏览行为的重要组成部分。支持按照设定的时间段展示检索关键词,且能够把用户检索的关键词与搜索引擎相关联。
采用Python+window平台+pycharmIDE
历史记录提取与筛选
1 | SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id |
从数据库中提取历史记录信息。提取用户的访问url 、网页标题、及访问时间。
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time def parse(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") return domain except IndexError: print('URL format error!') if __name__=="__main__": data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() # new_data={} # for item in data: # url=parse(item[0]) # title=item[1] # visit_time=(item[2]/1000000)-11644473600 # if url in new_data: # new_data[url][2] += 1 # else: # new_data[url]=[title,visit_time,1] new_data = [] for item in data: url = parse(item[0]) title = item[1] # visit_time = (item[2] / 1000000) - 11644473600#这是时间戳 Unix visit_time = time.strftime("%Y-%m-%d %X",time.localtime((item[2] / 1000000) - 11644473600)) new_data.append([url,title, visit_time]) print(new_data) cursor.close() conn.close()
部分整理的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 | ['hao.360.cn', '360导航_新一代安全上网导航', '2018-10-17 09:10:11']['hao.360.cn', '360导航_新一代安全上网导航', '2018-10-17 11:43:05']['baidu.com', '百度一下,你就知道', '2018-10-17 11:43:09']['baidu.com', '中国_百度搜索', '2018-10-17 11:43:13']['baidu.com', '中华人民共和国_百度百科', '2018-10-17 11:43:15']['baike.baidu.com', '中华人民共和国_百度百科', '2018-10-17 11:43:16']['hao.360.cn', '360导航_新一代安全上网导航', '2018-10-17 11:49:20']['hao.360.cn', '360导航_新一代安全上网导航', '2018-10-17 13:16:57']['liaoxuefeng.com', 'Day 1 - 搭建开发环境 - 廖雪峰的官方网站', '2018-10-17 13:17:09']['liaoxuefeng.com', '访问数据库 - 廖雪峰的官方网站', '2018-10-17 13:17:15']['liaoxuefeng.com', '使用SQLite - 廖雪峰的官方网站', '2018-10-17 13:17:17']Process finished with exit code 0 |
1 #!/usr/bin/env python3 2 #-*- coding:utf-8 -*- 3 ''' 4 Administrator 5 2018/10/17 6 ''' 7 import os # 访问系统的包 8 import sqlite3 # 链接数据库文件胡包 9 import time 10 def parse(url): 11 try: 12 parsed_url_components = url.split('//') 13 sublevel_split = parsed_url_components[1].split('/', 1) 14 domain = sublevel_split[0].replace("www.", "") 15 return domain 16 except IndexError: 17 print('URL format error!') 18 def FormatToStamp(): 19 flag=True 20 while flag: 21 try: 22 formatTime=input("请输入时间(格式:2018-06-24 11:50:00)").strip() 23 formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) 24 return formatTime 25 except Exception as e: 26 print("转换失败,请重新输入。失败原因:%s"%e) 27 28 29 30 if __name__=="__main__": 31 data_path = r"D:\360浏览器\360se6\User Data\Default" 32 files=os.listdir(data_path) 33 history_db = os.path.join(data_path, 'History') 34 conn = sqlite3.connect(history_db) 35 cursor = conn.cursor() 36 SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" 37 cursor.execute(SQL) 38 data=cursor.fetchall() 39 # new_data={} 40 # for item in data: 41 # url=parse(item[0]) 42 # title=item[1] 43 # visit_time=(item[2]/1000000)-11644473600 44 # if url in new_data: 45 # new_data[url][2] += 1 46 # else: 47 # new_data[url]=[title,visit_time,1] 48 new_data = [] 49 start_time=FormatToStamp() 50 for item in data: 51 url = parse(item[0]) 52 title = item[1] 53 # visit_time = (item[2] / 1000000) - 11644473600#这是时间戳 Unix 54 visit_time=(item[2] / 1000000) - 11644473600 55 if visit_time>start_time: 56 visit_time = time.strftime("%Y-%m-%d %X",time.localtime(visit_time)) 57 58 new_data.append([url,title, visit_time]) 59 for i in new_data: 60 print(i) 61 cursor.close() 62 conn.close()
频繁访问网站的数据挖掘
首先对数据进行域名聚合
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time,re def parse(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") return domain except IndexError: print('URL format error!') def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def FormatToStamp(): flag=True while flag: try: formatTime=input("请输入时间(格式:2018-06-24 11:50:00)").strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() # new_data={} # for item in data: # url=parse(item[0]) # title=item[1] # visit_time=(item[2]/1000000)-11644473600 # if url in new_data: # new_data[url][2] += 1 # else: # new_data[url]=[title,visit_time,1] new_data = [] # start_time=FormatToStamp() for item in data: url=item[0] url_2= filter_data(item[0]) title = item[1] # visit_time = (item[2] / 1000000) - 11644473600#这是时间戳 Unix visit_time=(item[2] / 1000000) - 11644473600 # if visit_time>start_time: visit_time = time.strftime("%Y-%m-%d %X",time.localtime(visit_time)) new_data.append([url,url_2,title, visit_time]) for i in new_data: print(i) print(address_count) cursor.close() conn.close()

#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time,re def parse(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") return domain except IndexError: print('URL format error!') def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def FormatToStamp(): flag=True while flag: try: formatTime=input("请输入时间(格式:2018-06-24 11:50:00)").strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() # new_data={} # for item in data: # url=parse(item[0]) # title=item[1] # visit_time=(item[2]/1000000)-11644473600 # if url in new_data: # new_data[url][2] += 1 # else: # new_data[url]=[title,visit_time,1] # new_data = [] new_data = {} # start_time=FormatToStamp() for item in data: # url=item[0] url_2= filter_data(item[0]) title = item[1] if url_2 in new_data: new_data[url_2]+=1 else: new_data[url_2]=1 # visit_time = (item[2] / 1000000) - 11644473600#这是时间戳 Unix # visit_time=(item[2] / 1000000) - 11644473600 # # if visit_time>start_time: # visit_time = time.strftime("%Y-%m-%d %X",time.localtime(visit_time)) # new_data.append([url,url_2,title, visit_time]) for i,j in new_data.items(): print(i,">>>",j) print(address_count) cursor.close() conn.close()

频繁访问网站前25的数据(top-X可设置)
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time,re import matplotlib.pyplot as plt def parse(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") return domain except IndexError: print('URL format error!') def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def FormatToStamp(): flag=True while flag: try: formatTime=input("请输入时间(格式:2018-06-24 11:50:00)").strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) def analyze(results): #条形图 prompt = input("[.] Type <c> to print or <p> to plot\n[>] ") if prompt == "c": with open('./history.txt', 'w') as f: for site, count in sites_count_sorted.items(): f.write(site + '\t' + str(count) + '\n') elif prompt == "p": key = [] value = [] for i in results: key.append(i[0]) value.append(i[1]) n = 25 X=range(n) Y = value[:n]#数量 plt.bar( X,Y, align='edge') plt.xticks(rotation=45) plt.xticks(X, key[:n]) for x, y in zip(X, Y): plt.text(x + 0.4, y + 0.05, y, ha='center', va='bottom') plt.show() else: print("[.] Uh?") quit() def analyze2(results): print("我一看就知道你要打印折线图") key=[] value=[] for i in results: key.append(i[0]) value.append(i[1]) n = 20 X = key[:n] Y = value[:n] plt.plot(X,Y,label="number count") plt.xticks(rotation=45) plt.xlabel('numbers') plt.ylabel('webname') plt.title('number count') plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() # new_data={} # for item in data: # url=parse(item[0]) # title=item[1] # visit_time=(item[2]/1000000)-11644473600 # if url in new_data: # new_data[url][2] += 1 # else: # new_data[url]=[title,visit_time,1] # new_data = [] new_data = {} # start_time=FormatToStamp() for item in data: # url=item[0] url_2= filter_data(item[0]) title = item[1] if url_2 in new_data: new_data[url_2]+=1 else: new_data[url_2]=1 # visit_time = (item[2] / 1000000) - 11644473600#这是时间戳 Unix # visit_time=(item[2] / 1000000) - 11644473600 # # if visit_time>start_time: # visit_time = time.strftime("%Y-%m-%d %X",time.localtime(visit_time)) # new_data.append([url,url_2,title, visit_time]) # for i,j in new_data.items(): # print(i,">>>",j) #我们对拿到的字典数据进行排序 del new_data["ok"] sites_count_sorted = sorted(new_data.items(),key=lambda item:item[1],reverse=True) # print(sites_count_sorted) analyze(sites_count_sorted) # print(type(sites_count_sorted)) #print(sites_count_sorted) #print("不符合条件的域名",address_count) cursor.close() conn.close()
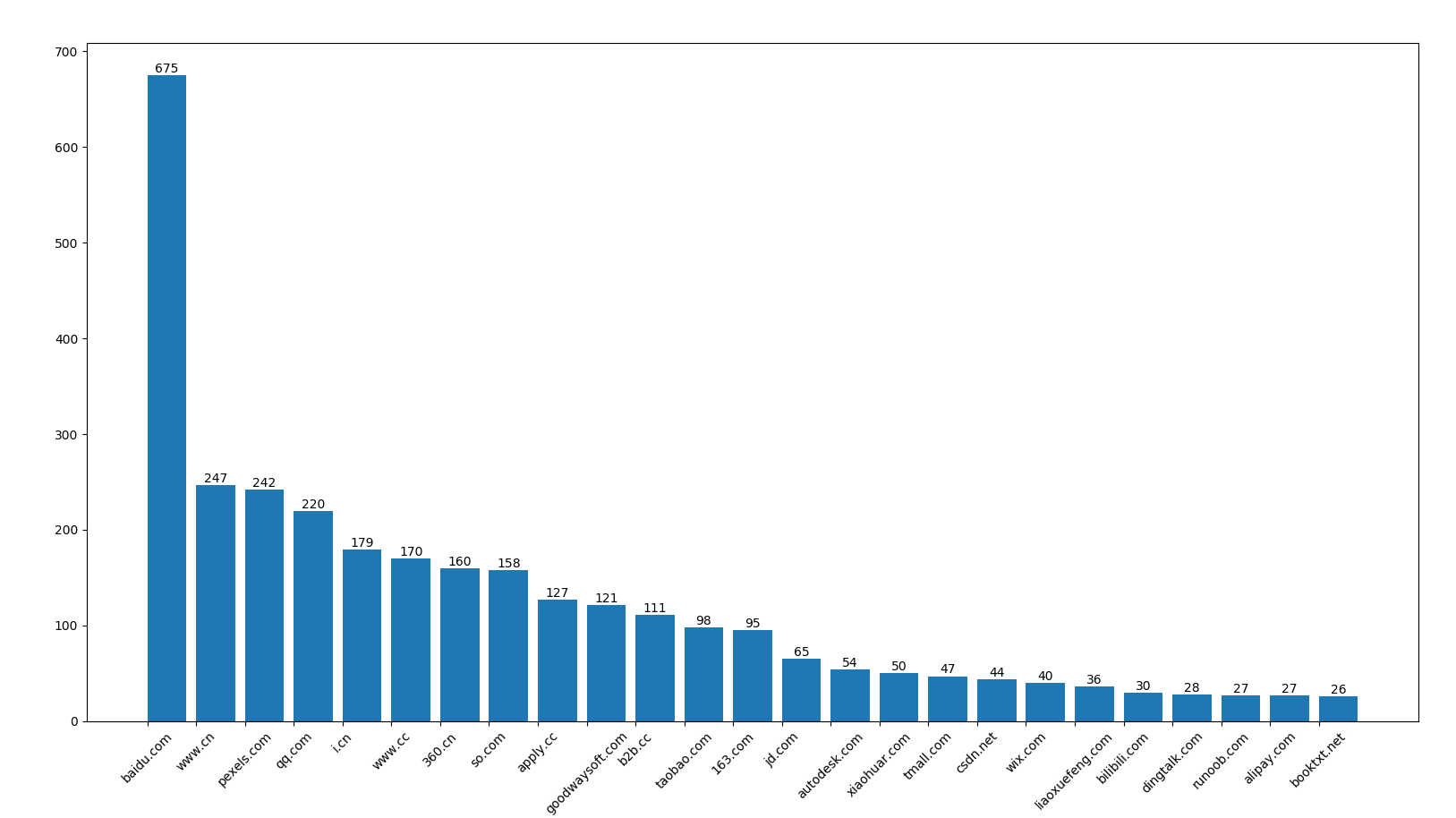
可以看出 访问百度的频数最高,依次递减。
关联检索关键词
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import time,os,sqlite3,re def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT keyword_search_terms.term,urls.url,urls.visit_count,urls.last_visit_time from keyword_search_terms LEFT JOIN urls on keyword_search_terms.url_id=urls.id;" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() print("取得数据:关键词keyword,url,访问次数,访问时间",data) new_data = [] for item in data: keyword=item[0] url= filter_data(item[1]) count=item[2] last_vist_time=time.strftime("%Y-%m-%d %X",time.localtime((item[3] / 1000000) - 11644473600)) new_data.append([keyword,url,count, last_vist_time]) for i in new_data: print(i)
部分数据如下:
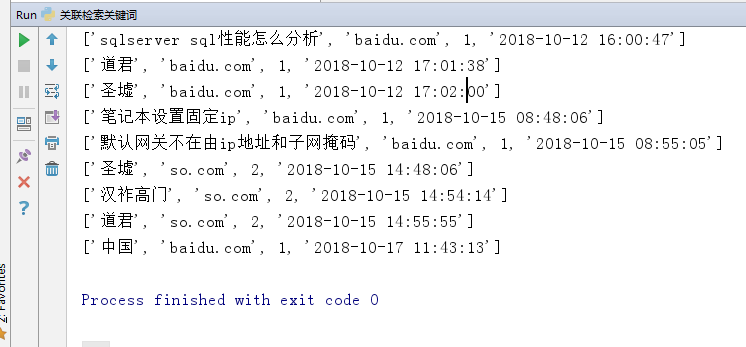
用户行为分析——统计搜索的前十大关键词:
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/17 ''' import time,os,sqlite3,re def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') #统计一下搜索引擎使用占比 if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT keyword_search_terms.term,urls.url,urls.visit_count,urls.last_visit_time from keyword_search_terms LEFT JOIN urls on keyword_search_terms.url_id=urls.id;" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() #print("取得数据:关键词keyword,url,访问次数,访问时间",data) new_data = [] ky_count={}#统计关键词数量 search_engines_count={}#统计搜索引擎使用数量 for item in data: keyword=item[0] url= filter_data(item[1]) count=item[2] last_vist_time=time.strftime("%Y-%m-%d %X",time.localtime((item[3] / 1000000) - 11644473600)) new_data.append([keyword,url,count, last_vist_time]) if keyword in ky_count: ky_count[keyword]+=1 # elif url in search_engines_count: # search_engines_count[url]+=1 else: ky_count[keyword]=1 # search_engines_count[url] = 1 # for i in new_data: # print(new_data) # print(ky_count) # print(search_engines_count) #对关键词进行排序 ky_count_sorted = sorted(ky_count.items(), key=lambda item: item[1], reverse=True) print(ky_count_sorted)
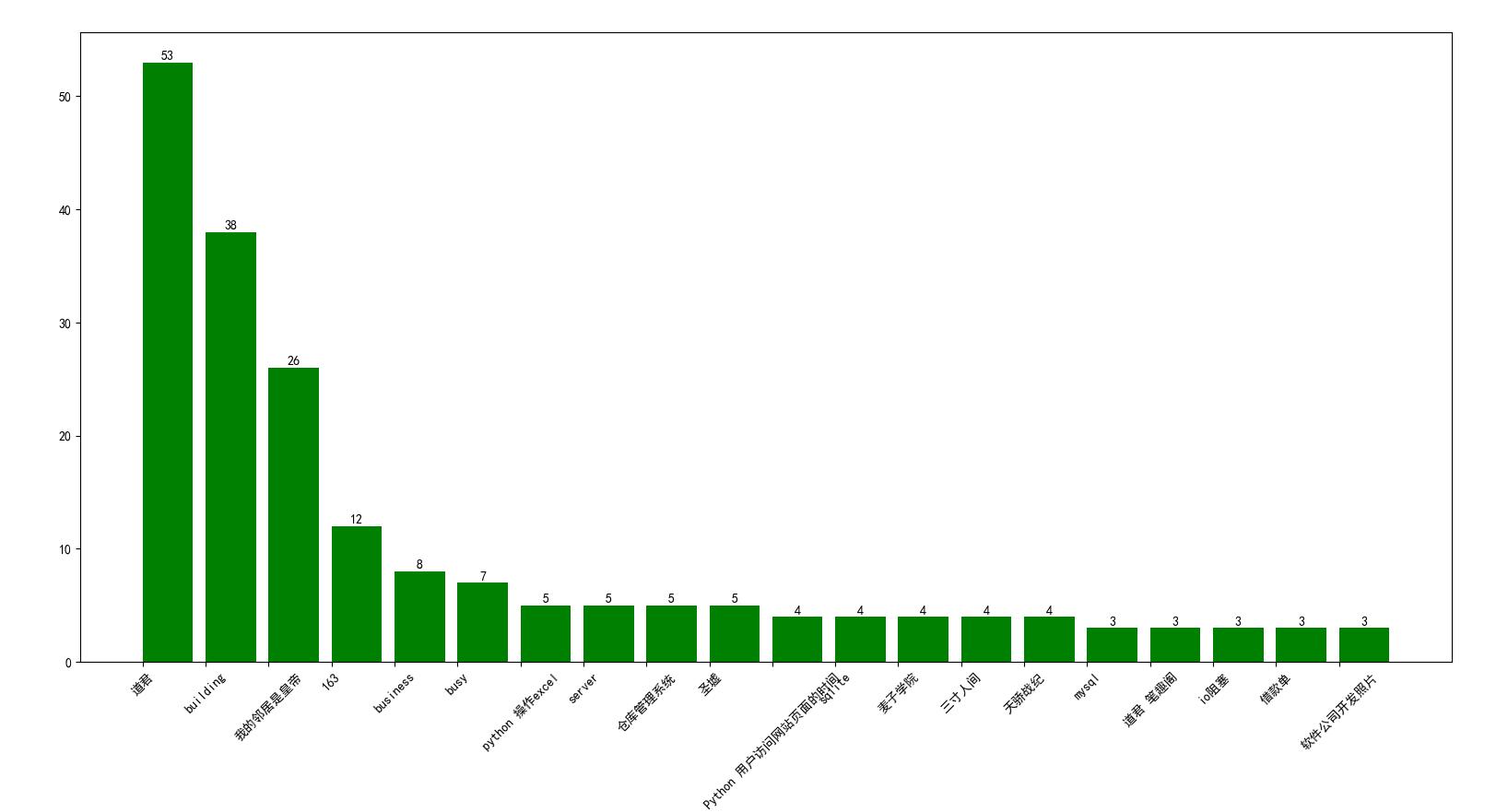
用直方图显示频数前20个 top-20的关键词。
1 #!/usr/bin/env python3 2 #-*- coding:utf-8 -*- 3 ''' 4 Administrator 5 2018/10/17 6 ''' 7 import time,os,sqlite3,re 8 import matplotlib.pyplot as plt 9 10 11 def filter_data(url): 12 try: 13 parsed_url_components = url.split('//') 14 sublevel_split = parsed_url_components[1].split('/', 1) 15 data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) 16 if data: 17 return data.group() 18 else: 19 address_count.add(sublevel_split[0]) 20 return "ok" 21 except IndexError: 22 print('URL format error!') 23 24 #统计一下搜索引擎使用占比 25 def analyze(results): 26 #条形图 27 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 28 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 29 # 有中文出现的情况,需要u'内容' 30 print("I will generate histograms directly !!") 31 key = [] 32 value = [] 33 for i in results: 34 key.append(i[0]) 35 value.append(i[1]) 36 n = 20 37 X=range(n) 38 Y = value[:n]#数量 39 40 plt.bar( X,Y, align='edge',color="g") 41 plt.xticks(rotation=45) 42 plt.xticks(X, key[:n]) 43 for x, y in zip(X, Y): 44 plt.text(x + 0.4, y + 0.05, y, ha='center', va='bottom') 45 plt.show() 46 47 48 49 if __name__=="__main__": 50 address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 51 data_path = r"D:\360浏览器\360se6\User Data\Default" 52 files = os.listdir(data_path) 53 history_db = os.path.join(data_path, 'History') 54 conn = sqlite3.connect(history_db) 55 cursor = conn.cursor() 56 SQL = "SELECT keyword_search_terms.term,urls.url,urls.visit_count,urls.last_visit_time from keyword_search_terms LEFT JOIN urls on keyword_search_terms.url_id=urls.id;" 57 cursor.execute(SQL) 58 data = cursor.fetchall() 59 cursor.close() 60 conn.close() 61 #print("取得数据:关键词keyword,url,访问次数,访问时间",data) 62 63 new_data = [] 64 ky_count={}#统计关键词数量 65 search_engines_count={}#统计搜索引擎使用数量 66 for item in data: 67 keyword=item[0] 68 url= filter_data(item[1]) 69 count=item[2] 70 last_vist_time=time.strftime("%Y-%m-%d %X",time.localtime((item[3] / 1000000) - 11644473600)) 71 new_data.append([keyword,url,count, last_vist_time]) 72 if keyword in ky_count: 73 ky_count[keyword]+=count 74 # elif url in search_engines_count: 75 # search_engines_count[url]+=1 76 else: 77 ky_count[keyword]=count 78 # search_engines_count[url] = 1 79 80 # for i in new_data: 81 # print(new_data) 82 # print(ky_count) 83 # print(search_engines_count) 84 #对关键词进行排序 85 ky_count_sorted = sorted(ky_count.items(), key=lambda item: item[1], reverse=True) 86 analyze(ky_count_sorted)
从关键词上可以看出,作者还是挺喜欢看小说的。业余时间喜欢用浏览器去搜索小说。特别是《道君》的搜索频数最大,O(∩_∩)O哈哈~ 其次技术类的信息也喜欢使用浏览器查找。
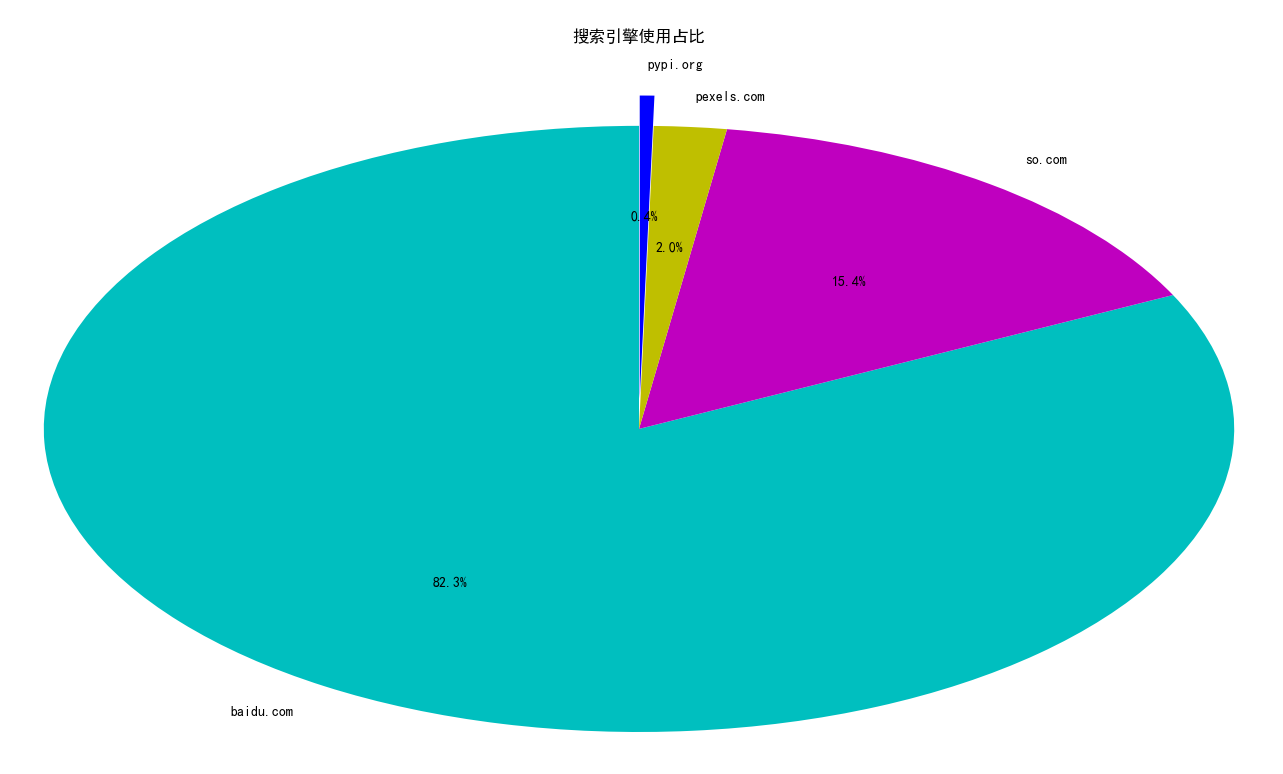
使用最多的搜索引擎是baidu.com ,其次是so.com pypi.org则使用最少。仅占比0.4%
1 #!/usr/bin/env python3 2 #-*- coding:utf-8 -*- 3 ''' 4 Administrator 5 2018/10/17 6 ''' 7 import time,os,sqlite3,re 8 import matplotlib.pyplot as plt 9 10 11 def filter_data(url): 12 try: 13 parsed_url_components = url.split('//') 14 sublevel_split = parsed_url_components[1].split('/', 1) 15 data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) 16 if data: 17 return data.group() 18 else: 19 address_count.add(sublevel_split[0]) 20 return "ok" 21 except IndexError: 22 print('URL format error!') 23 24 #统计一下搜索引擎使用占比 25 def analyze(results): 26 #条形图 27 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 28 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 29 # 有中文出现的情况,需要u'内容' 30 print("I will generate histograms directly !!") 31 key = [] 32 value = [] 33 for i in results: 34 key.append(i[0]) 35 value.append(i[1]) 36 n = 20 37 X=range(n) 38 Y = value[:n]#数量 39 40 plt.bar( X,Y, align='edge',color="g") 41 plt.xticks(rotation=45) 42 plt.xticks(X, key[:n]) 43 for x, y in zip(X, Y): 44 plt.text(x + 0.4, y + 0.05, y, ha='center', va='bottom') 45 plt.show() 46 47 def analyze2(results): 48 #饼图 49 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 50 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 51 # 有中文出现的情况,需要u'内容' 52 slices=[] 53 activities=[] 54 for i,j in results.items(): 55 activities.append(i) 56 slices.append(j) 57 cols=['c','m','y','b']#给饼图配颜色 58 num=len(slices)#取到一个需要几个数组 59 cols=cols[:num]#需要一个颜色,取几个 60 plt.pie(slices, 61 labels=activities, 62 colors=cols, 63 startangle=90, 64 # shadow=True, 65 explode=(0,0,0,0.1), 66 autopct='%1.1f%%') 67 plt.title(u"搜索引擎使用占比") 68 plt.show() 69 70 if __name__=="__main__": 71 address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 72 data_path = r"D:\360浏览器\360se6\User Data\Default" 73 files = os.listdir(data_path) 74 history_db = os.path.join(data_path, 'History') 75 conn = sqlite3.connect(history_db) 76 cursor = conn.cursor() 77 SQL = "SELECT keyword_search_terms.term,urls.url,urls.visit_count,urls.last_visit_time from keyword_search_terms LEFT JOIN urls on keyword_search_terms.url_id=urls.id;" 78 cursor.execute(SQL) 79 data = cursor.fetchall() 80 cursor.close() 81 conn.close() 82 #print("取得数据:关键词keyword,url,访问次数,访问时间",data) 83 84 new_data = [] 85 ky_count={}#统计关键词数量 86 search_engines_count={}#统计搜索引擎使用数量 87 for item in data: 88 keyword=item[0] 89 url= filter_data(item[1]) 90 count=item[2] 91 last_vist_time=time.strftime("%Y-%m-%d %X",time.localtime((item[3] / 1000000) - 11644473600)) 92 new_data.append([keyword,url,count, last_vist_time]) 93 # if keyword in ky_count: 94 # ky_count[keyword]+=count 95 if url in search_engines_count: 96 search_engines_count[url]+=1 97 else: 98 # ky_count[keyword]=count 99 search_engines_count[url] = 1 100 101 # for i in new_data: 102 # print(new_data) 103 # print(ky_count) 104 # print(search_engines_count) 105 #对关键词进行排序 106 # ky_count_sorted = sorted(ky_count.items(), key=lambda item: item[1], reverse=True) 107 108 # analyze(ky_count_sorted) 109 analyze2(search_engines_count)
统计每天打开网页的次数
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/18 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time,re import matplotlib.pyplot as plt class dataForm: """ 本类适用于生成连续的时间。包括时,天,月。 数据用于数据分析,只考虑今年的情况-----2018年。 hours:# 用于生成2018年的任意一个月份的每天的时间字典。单位是小时 """ #hours_dic = {} days_dic={} months_dic={} def __init__(self): pass def hours(self,num): hours_dic = {} if num in [1, 3, 5, 7, 8, 10, 12]: for day in range(1,32): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] elif num == 2: for day in range(1,29): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] elif num in [4, 6, 9, 11]: for day in range(1,31): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] else: print("输入格式不正确") return hours_dic def days(self): pass def months(self): pass def years(self): pass def FormatToStamp(self,string): #转成Unix时间戳 flag = True while flag: try: formatTime = string.strip() formatTime = time.mktime(time.strptime(formatTime, '%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s" % e) def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def analyze2(results): #折线图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' s1="2018-10-15" select_day=a.FormatToStamp("%s 00:00:00"%s1) key=[] value=[] for i in results: if select_day<i[1][1]: key.append(i[0][-8:]) value.append(i[1][0]) X = key[:24] Y = value[:24] #X=list(range(0, 24)) #group_labels=list(range(0, 24)) plt.plot(X,Y,label="%s 当日登陆网站走势图"%s1) plt.xticks(X,rotation=45) plt.xlabel('当日时刻:小时') plt.ylabel('登陆次数:次') plt.title("用户登陆网站走势图") plt.legend() plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() cursor.close() conn.close() new_data1=[]#统计每小时访问网站数量 new_data2=[]#统计每天的访问网站数量 new_data3=[]#统计每月的访问网站数量 new_data4=[]#统计每年的访问网站数量 暂时用不到 for num,item in enumerate(data): #new_data1.append([item,time.strftime("%Y-%m-%d %X",time.localtime((item[2] / 1000000) - 11644473600))]) new_data1.append([item, time.strftime("%Y-%m-%d %X", time.localtime((item[2] / 1000000) - 11644473600))[:-6]+":00:00"]) new_data2.append([item, time.strftime("%Y-%m-%d", time.localtime((item[2] / 1000000) - 11644473600))]) new_data3.append([item, time.strftime("%Y-%m", time.localtime((item[2] / 1000000) - 11644473600))]) new_data_hours = {} # 统计每小时访问网站数量 new_data_days = {} # 统计每天的访问网站数量 new_data_months = {} # 统计每月的访问网站数量 new_data_years = {} # 统计每年的访问网站数量 暂时用不到 # for item in new_data1: # for h in range(24): # if item[1] in new_data_hours: # new_data_hours[item[1]]+=1 # else: # new_data_hours[item[1]]=1 #print("统计每小时访问网站数量", new_data_hours) #print(new_data1) ############## 统计每小时访问网站数量 ############################################# a=dataForm()#定义一个时间生成对象 # print(new_data1) for item in new_data1: if item[1] in new_data_hours: new_data_hours[item[1]][0]+=1 elif item[1] not in new_data_hours: num=item[1][5:7] hours_dic = a.hours(int(num)) new_data_hours.update(hours_dic) new_data_hours[item[1]][0]=1 #对数据进行排序 new_data_hours_sorted=sorted(new_data_hours.items(), key=lambda item: item[0]) # for i in new_data_hours_sorted: # print(i) analyze2(new_data_hours_sorted) #print("统计每小时访问网站数量", new_data_hours) # for item in new_data2: # if item[1] in new_data_days: # new_data_days[item[1]]+=1 # else: # new_data_days[item[1]]=1 # print("统计每天的访问网站数量",new_data_days) # for item in new_data3: # if item[1] in new_data_months: # new_data_months[item[1]]+=1 # else: # new_data_months[item[1]]=1 # # print("统计每月的访问网站数量",new_data_months)
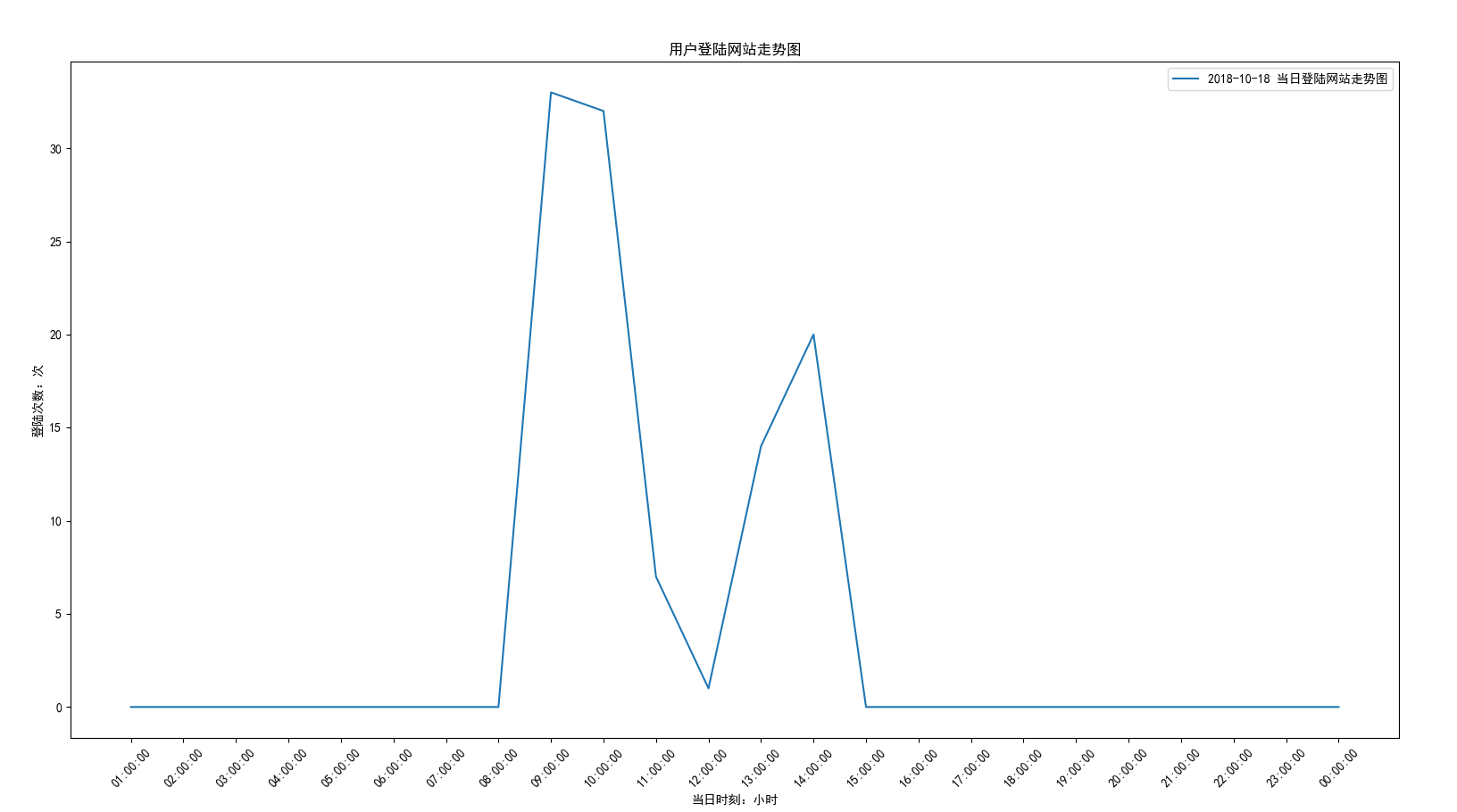
效果图:
1 #!/usr/bin/env python3 2 #-*- coding:utf-8 -*- 3 ''' 4 Administrator 5 2018/10/18 6 ''' 7 import os # 访问系统的包 8 import sqlite3 # 链接数据库文件胡包 9 import time,re 10 import matplotlib.pyplot as plt 11 12 class dataForm: 13 """ 14 本类适用于生成连续的时间。包括时,天,月。 15 数据用于数据分析,只考虑今年的情况-----2018年。 16 hours:# 用于生成2018年的任意一个月份的每天的时间字典。单位是小时 17 """ 18 #hours_dic = {} 19 days_dic={} 20 months_dic={} 21 def __init__(self): 22 pass 23 def hours(self,num): 24 hours_dic = {} 25 if num in [1, 3, 5, 7, 8, 10, 12]: 26 for day in range(1,32): 27 day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) 28 for h in range(24): 29 hour = day_to_str + " "+str(h).zfill(2)+":00:00" 30 hours_dic[hour]=[0,self.FormatToStamp(hour)] 31 elif num == 2: 32 for day in range(1,29): 33 day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) 34 for h in range(24): 35 hour = day_to_str + " "+str(h).zfill(2)+":00:00" 36 hours_dic[hour]=[0,self.FormatToStamp(hour)] 37 elif num in [4, 6, 9, 11]: 38 for day in range(1,31): 39 day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) 40 for h in range(24): 41 hour = day_to_str + " "+str(h).zfill(2)+":00:00" 42 hours_dic[hour]=[0,self.FormatToStamp(hour)] 43 else: 44 print("输入格式不正确") 45 return hours_dic 46 def days(self): 47 pass 48 def months(self): 49 pass 50 def years(self): 51 pass 52 def FormatToStamp(self,string): 53 #转成Unix时间戳 54 flag = True 55 while flag: 56 try: 57 formatTime = string.strip() 58 formatTime = time.mktime(time.strptime(formatTime, '%Y-%m-%d %X')) 59 return formatTime 60 except Exception as e: 61 print("转换失败,请重新输入。失败原因:%s" % e) 62 63 64 65 def filter_data(url): 66 try: 67 parsed_url_components = url.split('//') 68 sublevel_split = parsed_url_components[1].split('/', 1) 69 data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) 70 if data: 71 return data.group() 72 else: 73 address_count.add(sublevel_split[0]) 74 return "ok" 75 except IndexError: 76 print('URL format error!') 77 def analyze2(results): 78 #折线图 79 80 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 81 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 82 # 有中文出现的情况,需要u'内容' 83 def go(string): 84 col=['black','brown','red','goldenrod',"blue","y","g"] 85 s_to=string 86 for i,j in enumerate(col): 87 # s=string[:8]+str(int(string[-2:])-i) 88 select_day = a.FormatToStamp("%s 00:00:00" % s_to)-i*86400*2 89 keys = [] 90 values = [] 91 for i in results: 92 if select_day < i[1][1]: 93 keys.append(i[0][-11:-3]) 94 values.append(i[1][0]) 95 # x = keys[:48] 96 x=range(48) 97 y = values[:48] 98 plt.plot(x, y, label="%s 登陆网站走势图" %(time.strftime("%Y-%m-%d %X",time.localtime(select_day))), color=j) 99 plt.xticks(x, rotation=0) 100 go("2018-10-05") 101 102 plt.xlabel('当日时刻:小时') 103 plt.ylabel('登陆次数:次') 104 plt.title("用户登陆网站48小时走势图") 105 plt.legend() 106 plt.show() 107 108 if __name__=="__main__": 109 address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 110 data_path = r"D:\360浏览器\360se6\User Data\Default" 111 files=os.listdir(data_path) 112 history_db = os.path.join(data_path, 'History') 113 conn = sqlite3.connect(history_db) 114 cursor = conn.cursor() 115 SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" 116 cursor.execute(SQL) 117 data=cursor.fetchall() 118 cursor.close() 119 conn.close() 120 121 new_data1=[]#统计每小时访问网站数量 122 new_data2=[]#统计每天的访问网站数量 123 new_data3=[]#统计每月的访问网站数量 124 new_data4=[]#统计每年的访问网站数量 暂时用不到 125 for num,item in enumerate(data): 126 #new_data1.append([item,time.strftime("%Y-%m-%d %X",time.localtime((item[2] / 1000000) - 11644473600))]) 127 new_data1.append([item, time.strftime("%Y-%m-%d %X", time.localtime((item[2] / 1000000) - 11644473600))[:-6]+":00:00"]) 128 new_data2.append([item, time.strftime("%Y-%m-%d", time.localtime((item[2] / 1000000) - 11644473600))]) 129 new_data3.append([item, time.strftime("%Y-%m", time.localtime((item[2] / 1000000) - 11644473600))]) 130 131 new_data_hours = {} # 统计每小时访问网站数量 132 new_data_days = {} # 统计每天的访问网站数量 133 new_data_months = {} # 统计每月的访问网站数量 134 new_data_years = {} # 统计每年的访问网站数量 暂时用不到 135 136 # for item in new_data1: 137 # for h in range(24): 138 # if item[1] in new_data_hours: 139 # new_data_hours[item[1]]+=1 140 # else: 141 # new_data_hours[item[1]]=1 142 #print("统计每小时访问网站数量", new_data_hours) 143 144 #print(new_data1) 145 ############## 统计每小时访问网站数量 ############################################# 146 a=dataForm()#定义一个时间生成对象 147 # print(new_data1) 148 for item in new_data1: 149 if item[1] in new_data_hours: 150 new_data_hours[item[1]][0]+=1 151 elif item[1] not in new_data_hours: 152 num=item[1][5:7] 153 hours_dic = a.hours(int(num)) 154 new_data_hours.update(hours_dic) 155 new_data_hours[item[1]][0]=1 156 157 158 #对数据进行排序 159 new_data_hours_sorted=sorted(new_data_hours.items(), key=lambda item: item[0]) 160 # for i in new_data_hours_sorted: 161 # print(i) 162 analyze2(new_data_hours_sorted) 163 164 165 #print("统计每小时访问网站数量", new_data_hours) 166 # for item in new_data2: 167 # if item[1] in new_data_days: 168 # new_data_days[item[1]]+=1 169 # else: 170 # new_data_days[item[1]]=1 171 # print("统计每天的访问网站数量",new_data_days) 172 # for item in new_data3: 173 # if item[1] in new_data_months: 174 # new_data_months[item[1]]+=1 175 # else: 176 # new_data_months[item[1]]=1 177 # 178 # print("统计每月的访问网站数量",new_data_months)
效果图 如下:
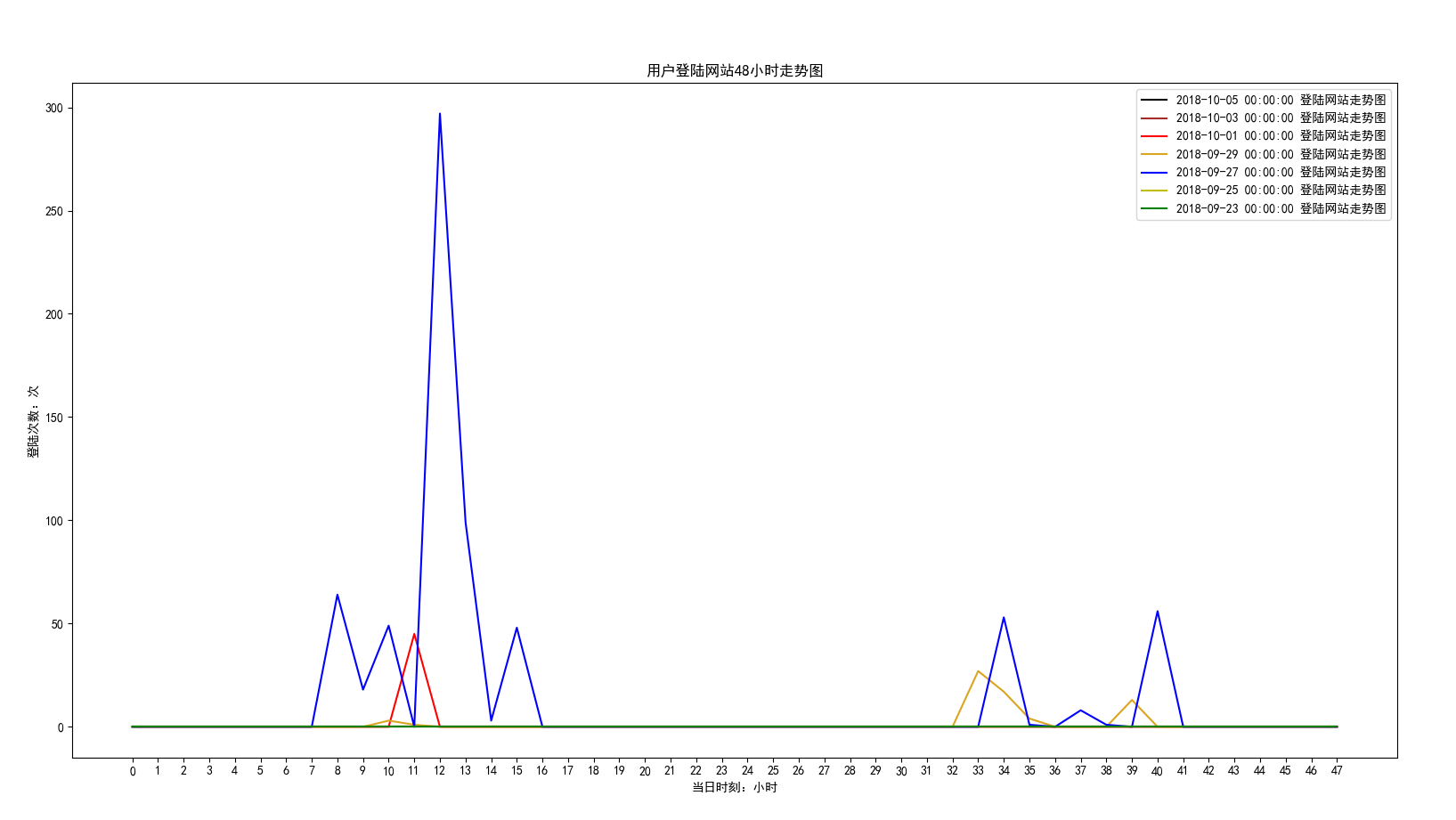
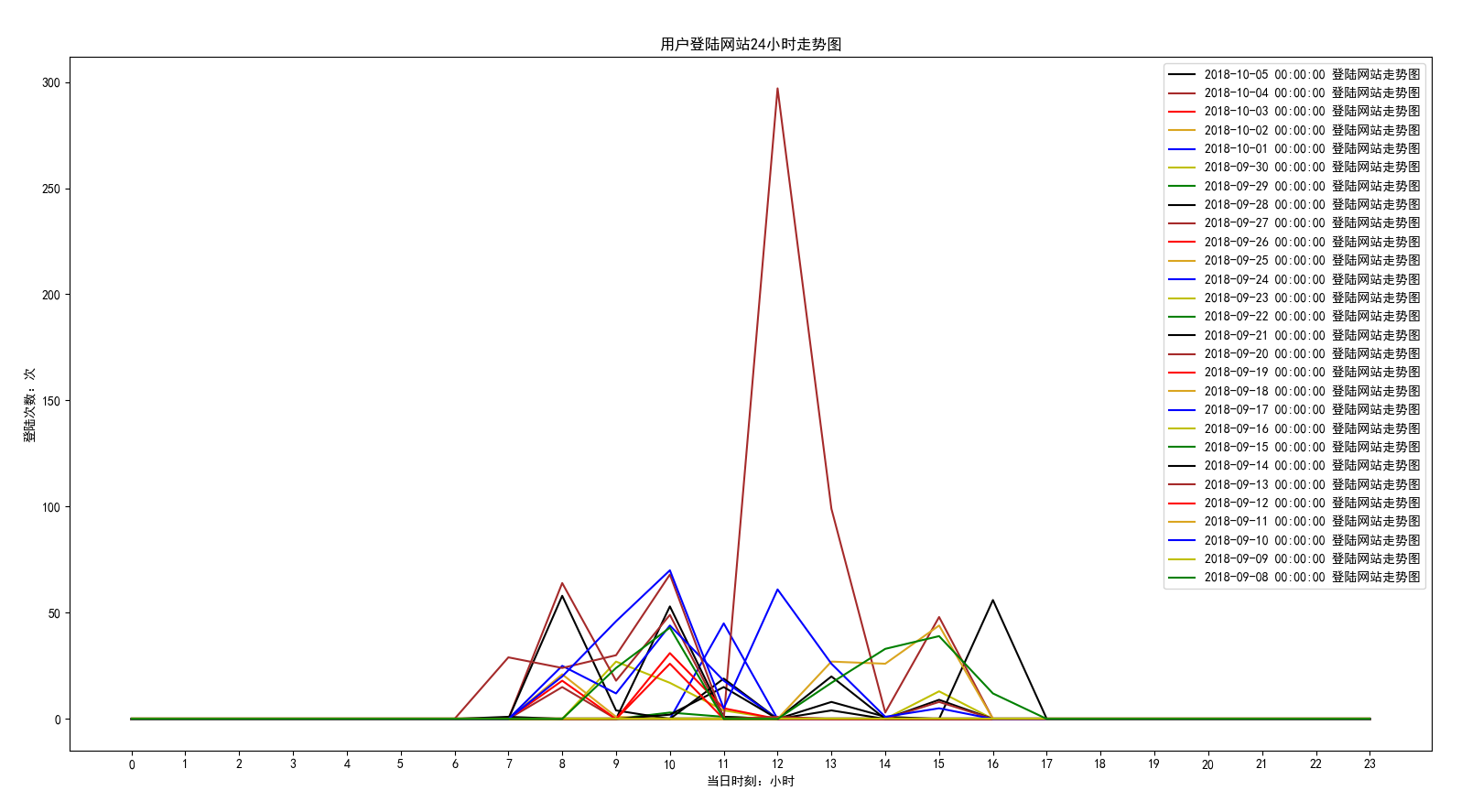
从图中可以看出,每天都是从早上七点开始到下午五点之间会产生登陆行为。非上班时间,不会使用本机电脑。至少证明,本人上班还是听规律的呀。哈哈·······
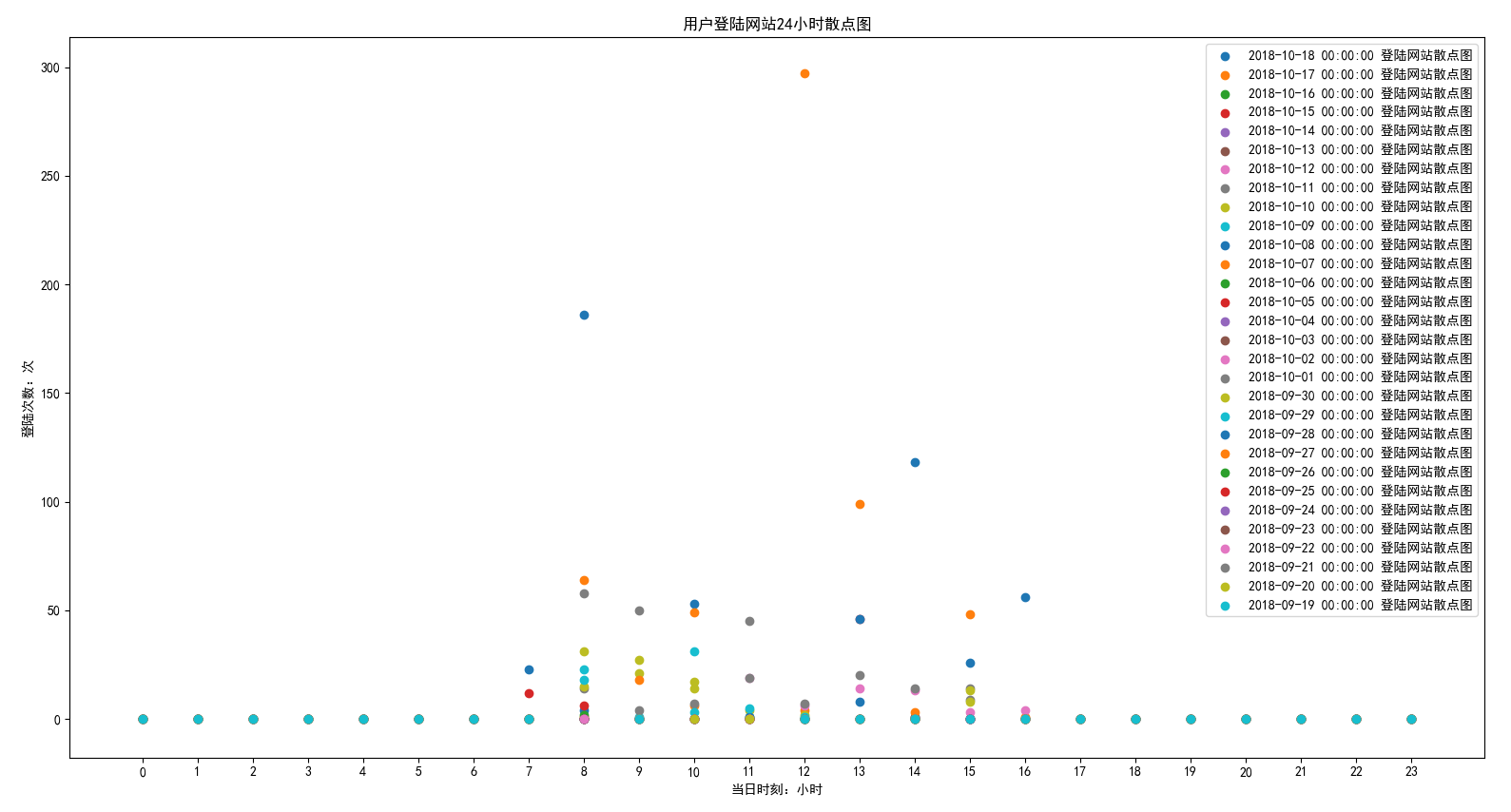
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/18 ''' import os # 访问系统的包 import sqlite3 # 链接数据库文件胡包 import time,re import matplotlib.pyplot as plt class dataForm: """ 本类适用于生成连续的时间。包括时,天,月。 数据用于数据分析,只考虑今年的情况-----2018年。 hours:# 用于生成2018年的任意一个月份的每天的时间字典。单位是小时 """ #hours_dic = {} days_dic={} months_dic={} def __init__(self): pass def hours(self,num): hours_dic = {} if num in [1, 3, 5, 7, 8, 10, 12]: for day in range(1,32): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] elif num == 2: for day in range(1,29): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] elif num in [4, 6, 9, 11]: for day in range(1,31): day_to_str="2018-"+str(num).zfill(2)+"-"+str(day).zfill(2) for h in range(24): hour = day_to_str + " "+str(h).zfill(2)+":00:00" hours_dic[hour]=[0,self.FormatToStamp(hour)] else: print("输入格式不正确") return hours_dic def days(self): pass def months(self): pass def years(self): pass def FormatToStamp(self,string): #转成Unix时间戳 flag = True while flag: try: formatTime = string.strip() formatTime = time.mktime(time.strptime(formatTime, '%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s" % e) def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',sublevel_split[0]) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def analyze2(results): #折线图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' def go(string): col=['black','brown','red','goldenrod',"blue","y","g",'black','brown','red','goldenrod',"blue","y","g",'black','brown','red','goldenrod',"blue","y","g",'black','brown','red','goldenrod',"blue","y","g"] s_to=string for i,j in enumerate(col): # s=string[:8]+str(int(string[-2:])-i) select_day = a.FormatToStamp("%s 00:00:00" % s_to)-i*86400 keys = [] values = [] for i in results: if select_day < i[1][1]: keys.append(i[0][-11:-3]) values.append(i[1][0]) # x = keys[:48] x=range(24) y = values[:24] plt.plot(x, y, label="%s 登陆网站走势图" %(time.strftime("%Y-%m-%d %X",time.localtime(select_day))), color=j) plt.xticks(x, rotation=0) go("2018-10-05") plt.xlabel('当日时刻:小时') plt.ylabel('登陆次数:次') plt.title("用户登陆网站24小时走势图") plt.legend() plt.show() def analyze3(results): #散点图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' def go(string): s_to=string for i in range(30): select_day = a.FormatToStamp("%s 00:00:00" % s_to)-i*86400 keys = [] values = [] for i in results: if select_day < i[1][1]: keys.append(i[0][-11:-3]) values.append(i[1][0]) # x = keys[:48] x=range(24) y = values[:24] print(x) print(y) plt.scatter(x, y, label="%s 登陆网站散点图" %(time.strftime("%Y-%m-%d %X",time.localtime(select_day)))) plt.xticks(x, rotation=0) go("2018-10-18") # plt.xlabel('当日时刻:小时') plt.ylabel('登陆次数:次') plt.title("用户登陆网站24小时散点图") plt.legend() plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files=os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL="SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data=cursor.fetchall() cursor.close() conn.close() new_data1=[]#统计每小时访问网站数量 new_data2=[]#统计每天的访问网站数量 new_data3=[]#统计每月的访问网站数量 new_data4=[]#统计每年的访问网站数量 暂时用不到 for num,item in enumerate(data): #new_data1.append([item,time.strftime("%Y-%m-%d %X",time.localtime((item[2] / 1000000) - 11644473600))]) new_data1.append([item, time.strftime("%Y-%m-%d %X", time.localtime((item[2] / 1000000) - 11644473600))[:-6]+":00:00"]) new_data2.append([item, time.strftime("%Y-%m-%d", time.localtime((item[2] / 1000000) - 11644473600))]) new_data3.append([item, time.strftime("%Y-%m", time.localtime((item[2] / 1000000) - 11644473600))]) new_data_hours = {} # 统计每小时访问网站数量 new_data_days = {} # 统计每天的访问网站数量 new_data_months = {} # 统计每月的访问网站数量 new_data_years = {} # 统计每年的访问网站数量 暂时用不到 # for item in new_data1: # for h in range(24): # if item[1] in new_data_hours: # new_data_hours[item[1]]+=1 # else: # new_data_hours[item[1]]=1 #print("统计每小时访问网站数量", new_data_hours) #print(new_data1) ############## 统计每小时访问网站数量 ############################################# a=dataForm()#定义一个时间生成对象 # print(new_data1) for item in new_data1: if item[1] in new_data_hours: new_data_hours[item[1]][0]+=1 elif item[1] not in new_data_hours: num=item[1][5:7] hours_dic = a.hours(int(num)) new_data_hours.update(hours_dic) new_data_hours[item[1]][0]=1 #对数据进行排序 new_data_hours_sorted=sorted(new_data_hours.items(), key=lambda item: item[0]) # for i in new_data_hours_sorted: # print(i) analyze3(new_data_hours_sorted) #print("统计每小时访问网站数量", new_data_hours) # for item in new_data2: # if item[1] in new_data_days: # new_data_days[item[1]]+=1 # else: # new_data_days[item[1]]=1 # print("统计每天的访问网站数量",new_data_days) # for item in new_data3: # if item[1] in new_data_months: # new_data_months[item[1]]+=1 # else: # new_data_months[item[1]]=1 # # print("统计每月的访问网站数量",new_data_months)
分析用户上网行为
由于用户的网站的URL请求特别多,每次请求一次就会产生一条记录。使用穷举法,我们对用户访问的所有网站进行一次分类。 根据需求,设置分类。 假设如果分成9类,每条记录可以用列表表示: visit_type=[0,0,0,0,0,0,0,0,0]
1、大型门户网站 比如国内知名的新浪、搜狐、网易、腾讯等都属于大型门户网站。大型门户网站类型的特点:网站信息量非常大,海量信息量,同时网站以咨询、新闻等内容为主。网站内容比较全面,包括很多分支信息,比如房产、经济、科技、旅游等。大型门户网站通常访问量非常大,每天有数千万甚至上亿的访问量,是互联网的最重要组成部分。 2、行业网站 以某一个行业内容为主题的网站,行业网站通常包括行业资讯,行业技术信息,产品广告发布等。目前基本每个行业都有行业网站,比如五金行业网站、机电行业网站、工程机械行业网站、旅游服务行业网站等。行业网站类型在该行业有一定的知名度,通常流量也比较大,每天有上万的流量。行业网站盈利模式主要靠广告输入,付费商铺,联盟广告,软文,链接买卖等方式盈利。 3、交易类网站 交易类网站主要包括B2B、B2C、C2C等类型。交易类网站以在网站产生销售为目的,通过产品选择-》订购-》付款-》物流发货-》确认发货等流程实现产品的销售。国内知名的交易网站类型有阿里巴巴、淘宝、京东等。 4、分类信息网站 分类信息网站好比互联网的集贸市场,有人在上面发布信息销售产品,有人在上面购买物品。分类信息主要面向同城,是同城产品销售的重要平台。国内知名的分类信息包括58同城、百姓、列表等。如果你有闲置的物品,那么分类信息为你提供了最好的销售平台,而且还是免费的。 5、论坛 说起论坛,估计大家都不陌生,论坛是一个交流的平台,注册论坛账号并登陆以后,就可以发布信息,也可以信息回帖等,实现交流的功能。 6、政府网站 政府网站有政府和事业单位主办,通常内容比较权威,是政府对外发布信息的平台。目前国内政府和事业单位基本都有自己的网站。 7、功能性质网站 网站提供某一种或者几种功能,比如站长工具、电话手机号码查询、物流信息查询、火车票购买等。功能性网站以实现某一种或者几种功能为主要服务内容。用户也是为了实现某一种功能来浏览该网站。 8、娱乐类型网站 娱乐类型网站主要包括视频网站(优酷、土豆)、音乐网站、游戏网站等。虽然互联网发展非常迅速,但是互联网还是以娱乐为主,大部分人上网还是为了娱乐。通常娱乐网站浏览量非常大,主要是需求非常大,以视频、游戏娱乐网站最为突出。 9、企业网站 企业网站是互联网网站数量最多的类型,现在几乎每一个企业都有自己的企业网站。企业网站内容包括企业的新闻动态、企业的产品信息、企业的简介、企业的联系方式等内容。企业网站是企业对外展示的窗口,也是企业销售产品的最主要方式。
同时由于现在大部分用户习惯使用搜索引擎,在表中增加一列,用来统计搜索引擎的使用情况。
| 时间 | 搜索引擎 | 大型门户网站 | 行业网站 | 交易类网站 | 分类信息网站 | 论坛 | 政府网站 | 功能性质网站 | 娱乐类型网站 | 企业网站 |
| 2018-09-01 00:00:00 | ||||||||||
| 2018-09-01 00:00:01 | ||||||||||
| 2018-09-01 00:00:02 | ||||||||||
| 2018-09-01 00:00:03 | ||||||||||
| ...... |
1 #!/usr/bin/env python3 2 #-*- coding:utf-8 -*- 3 ''' 4 Administrator 5 2018/10/19 6 ''' 7 import os,sqlite3,re,time 8 def filter_data(url): 9 try: 10 parsed_url_components = url.split('//') 11 sublevel_split = parsed_url_components[1].split('/', 1) 12 domain = sublevel_split[0].replace("www.", "") 13 14 data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',domain) 15 if data: 16 return data.group() 17 else: 18 address_count.add(sublevel_split[0]) 19 return "ok" 20 except IndexError: 21 print('URL format error!') 22 23 if __name__=="__main__": 24 address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 25 data_path = r"D:\360浏览器\360se6\User Data\Default" 26 files = os.listdir(data_path) 27 history_db = os.path.join(data_path, 'History') 28 conn = sqlite3.connect(history_db) 29 cursor = conn.cursor() 30 SQL = "SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" 31 cursor.execute(SQL) 32 data = cursor.fetchall() 33 cursor.close() 34 conn.close() 35 36 new_list=[] 37 38 web_dic={0:["360.cn","baidu.com","so.com","pypi.org","bing.com","stackoverflow.com","google.cn"],#搜索引擎 39 1: ["qihoo.com","eastday.com","toutiao.com","ufochn.com","timeacle.cn","bilibili.com","xfwed.com", 40 "docin.com","sohu.com","msn.cn","chouti.com","milkjpg.com","btime.com","51xuedu.com", 41 "joyme.com"],#大型门户网站 42 2: ["699pic.com","epub360.com","wix.com","crsky.com","runoob.com","scrapy.org","debugbar.com","linuxidc.com", 43 "911cha.com","tuke88.com","readthedocs.org","jb51.net","readthedocs.io","github.com","888pic.com", 44 "ibaotu.com","w3school.com","17sucai.com","mycodes.net","freemoban.com"],#行业网站 45 3: ["www.cc","b2b.cc","mall.cc","creditcard.cc","taobao.com","alipay.com", 46 "tmall.com","jd.com","dangdang.com","company1.cc","ebank.cc"],#交易类网站 47 4: ["qcloud.com","360doc.com","eol.cn","xiaohuar.com","exam8.com"],#分类信息网站 48 5: ["csdn.net","2cto.com","liaoxuefeng.com","w3cschool.cn","cnblogs.com","zol.com", 49 "python.org","douban.com","shidastudy.com","v2ex.com","i.cn","home.cn","passport.cn", 50 "testerhome.com","aosabook.org","ggdoc.com","biqukan.com"],#论坛 51 6: ["apply.cc","ccopyright.com","gov.cn","jzjyy.cn","jseea.cn","jszk.net"],#政府网站 52 7: ["ccb.com",'ok',"163.com","ibsbjstar.cc","app.com","maiziedu.com","browsershots.org","gerensuodeshui.cn", 53 "gitlab.com","youdao.com","alicdn.com","qmail.com"],#功能性质网站 54 8:["biqudao.com","biqudu.com","siluke.tw","biquge.cc","6mao.com","biqiuge.com","biquge.info", 55 "dingdiann.com","qq.com","booktxt.net","biquge.com","xs.la","208xs.com","xxbiquge.com", 56 "xuexi111.com","ufochn.com","ahzww.net","555zw.com","biquge5200.com","bequge.com","bqg99.com", 57 "bqg99.cc","sbiquge.com","biquge5200.cc","166xs.com"],# 娱乐类型网站 58 9: ["microsoft.com","weaver.com","oa8000.com","goodwaysoft.com","lenosoft.net", 59 "lizheng.com","adobe.com","pexels.com","dingtalk.com","autodesk.com","qifeiye.com", 60 "lizhengyun.com","shuishandt.com","windows7en.com","coursera.org","smoson.com","gongboshi.com", 61 "huawei.com","spoon.net","jetbrains.com","sqlite.org","yesacc.com","sunlandzk.com", 62 "alibabagroup.com","turbo.net","cqttech.com","prezi.com","tradedoubler.com", 63 "renrendai.com","alizila.com","hongzhixx.cn","studyol.com","cnbim.com"],#企业网站 64 } 65 for row in data: 66 web_type=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 67 stime=(row[2] / 1000000) - 11644473600#这是时间戳 Unix 68 stime = time.strftime("%Y-%m-%d %X", time.localtime(stime)) 69 url=filter_data(row[0]) 70 for i in web_dic: 71 for j in web_dic[i]: 72 if url in j: 73 web_type[i]=1 74 data_old=row 75 new_list.append([stime,web_type,url,data_old]) 76 for row_new in new_list: 77 # if not 1 in row_new[1]: 78 # print(row_new) 79 print(row_new)
部分数据如上图所示,1代表该行URL地址的类型。
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/19 ''' import os,sqlite3,re,time import matplotlib.pyplot as plt def FormatToStamp(string): flag=True while flag: try: formatTime=input("请输入%s(格式:2018-06-24 11:50:00)"%string).strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) def per_seconds(start_time,end_time): time_dict={} start_time=int(start_time) end_time=int(end_time) for i in range(start_time,end_time): time_dict[i]=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] return time_dict def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',domain) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() new_list=[] web_dic={0:["360.cn","baidu.com","so.com","pypi.org","bing.com","stackoverflow.com","google.cn"],#搜索引擎 1: ["qihoo.com","eastday.com","toutiao.com","ufochn.com","timeacle.cn","bilibili.com","xfwed.com", "docin.com","sohu.com","msn.cn","chouti.com","milkjpg.com","btime.com","51xuedu.com", "joyme.com"],#大型门户网站 2: ["699pic.com","epub360.com","wix.com","crsky.com","runoob.com","scrapy.org","debugbar.com","linuxidc.com", "911cha.com","tuke88.com","readthedocs.org","jb51.net","readthedocs.io","github.com","888pic.com", "ibaotu.com","w3school.com","17sucai.com","mycodes.net","freemoban.com"],#行业网站 3: ["www.cc","b2b.cc","mall.cc","creditcard.cc","taobao.com","alipay.com", "tmall.com","jd.com","dangdang.com","company1.cc","ebank.cc"],#交易类网站 4: ["qcloud.com","360doc.com","eol.cn","xiaohuar.com","exam8.com"],#分类信息网站 5: ["csdn.net","2cto.com","liaoxuefeng.com","w3cschool.cn","cnblogs.com","zol.com", "python.org","douban.com","shidastudy.com","v2ex.com","i.cn","home.cn","passport.cn", "testerhome.com","aosabook.org","ggdoc.com","biqukan.com"],#论坛 6: ["apply.cc","ccopyright.com","gov.cn","jzjyy.cn","jseea.cn","jszk.net"],#政府网站 7: ["ccb.com",'ok',"163.com","ibsbjstar.cc","app.com","maiziedu.com","browsershots.org","gerensuodeshui.cn", "gitlab.com","youdao.com","alicdn.com","qmail.com"],#功能性质网站 8:["biqudao.com","biqudu.com","siluke.tw","biquge.cc","6mao.com","biqiuge.com","biquge.info", "dingdiann.com","qq.com","booktxt.net","biquge.com","xs.la","208xs.com","xxbiquge.com", "xuexi111.com","ufochn.com","ahzww.net","555zw.com","biquge5200.com","bequge.com","bqg99.com", "bqg99.cc","sbiquge.com","biquge5200.cc","166xs.com"],# 娱乐类型网站 9: ["microsoft.com","weaver.com","oa8000.com","goodwaysoft.com","lenosoft.net", "lizheng.com","adobe.com","pexels.com","dingtalk.com","autodesk.com","qifeiye.com", "lizhengyun.com","shuishandt.com","windows7en.com","coursera.org","smoson.com","gongboshi.com", "huawei.com","spoon.net","jetbrains.com","sqlite.org","yesacc.com","sunlandzk.com", "alibabagroup.com","turbo.net","cqttech.com","prezi.com","tradedoubler.com", "renrendai.com","alizila.com","hongzhixx.cn","studyol.com","cnbim.com"],#企业网站 } start_time=FormatToStamp("请输入开始时间:") end_time = FormatToStamp("请输入结束时间:") new_time_dic=per_seconds(start_time,end_time) for row in data: stime=int((row[2] / 1000000) - 11644473600)#这是时间戳 Unix url=filter_data(row[0]) data_old = row if stime in new_time_dic: for i in web_dic: for j in web_dic[i]: if url in j: new_time_dic[stime][i] = 1 # for row in data: # web_type=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # stime=(row[2] / 1000000) - 11644473600#这是时间戳 Unix # #stime = time.strftime("%Y-%m-%d %X", time.localtime(stime)) # url=filter_data(row[0]) # for i in web_dic: # for j in web_dic[i]: # if url in j: # web_type[i]=1 # data_old=row # if stime>start_time and stime<end_time: # new_list.append([stime,web_type,url,data_old]) for row_new in new_time_dic: if 1 in new_time_dic[row_new]: print(row_new,new_time_dic[row_new])
"D:\Program Files (x86)\python36\python.exe" F:/python从入门到放弃/10.17/用户行为分析.py 请输入请输入开始时间:(格式:2018-06-24 11:50:00)2018-10-17 00:00:00 请输入请输入结束时间:(格式:2018-06-24 11:50:00)2018-10-19 00:00:00 1539738611 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 1539747785 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 1539747789 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 1539747793 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 1539747795 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] ...........................
Python位运算符 按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下: 下表中变量 a 为 60,b 为 13二进制格式如下: a = 0011 1100 b = 0000 1101 ----------------- a&b = 0000 1100 a|b = 0011 1101 a^b = 0011 0001 ~a = 1100 0011
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/19 ''' import os,sqlite3,re,time import matplotlib.pyplot as plt def FormatToStamp(string): flag=True while flag: try: formatTime=input("请输入%s(格式:2018-06-24 11:50:00)"%string).strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) def per_seconds(start_time,end_time): time_dict={} start_time=int(start_time) end_time=int(end_time) for i in range(start_time,end_time): time_dict[i]=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] return time_dict def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',domain) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def scatter_plot(results): # 散点图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' keys = [] values = [] for items in results: keys.append(items[0]) state=0 for i in range(10): if 1 == items[1][i]: state=i+1 break values.append(state) # x = keys[:48] x = range(24000) # for i in values: # if i != 0: # print("ok",i) # print(">>",values) y = values[-24000:] #y_title=["搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站"] # print(x) # print(y) plt.scatter(x, y, label="登陆网站散点图") # plt.xlabel('当日时刻:秒') plt.ylabel('登陆网站类别') plt.title("用户登陆网站行为分析") plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() new_list=[] web_dic={0:["360.cn","baidu.com","so.com","pypi.org","bing.com","stackoverflow.com","google.cn"],#搜索引擎 1: ["qihoo.com","eastday.com","toutiao.com","ufochn.com","timeacle.cn","bilibili.com","xfwed.com", "docin.com","sohu.com","msn.cn","chouti.com","milkjpg.com","btime.com","51xuedu.com", "joyme.com"],#大型门户网站 2: ["699pic.com","epub360.com","wix.com","crsky.com","runoob.com","scrapy.org","debugbar.com","linuxidc.com", "911cha.com","tuke88.com","readthedocs.org","jb51.net","readthedocs.io","github.com","888pic.com", "ibaotu.com","w3school.com","17sucai.com","mycodes.net","freemoban.com"],#行业网站 3: ["www.cc","b2b.cc","mall.cc","creditcard.cc","taobao.com","alipay.com", "tmall.com","jd.com","dangdang.com","company1.cc","ebank.cc"],#交易类网站 4: ["qcloud.com","360doc.com","eol.cn","xiaohuar.com","exam8.com"],#分类信息网站 5: ["csdn.net","2cto.com","liaoxuefeng.com","w3cschool.cn","cnblogs.com","zol.com", "python.org","douban.com","shidastudy.com","v2ex.com","i.cn","home.cn","passport.cn", "testerhome.com","aosabook.org","ggdoc.com","biqukan.com"],#论坛 6: ["apply.cc","ccopyright.com","gov.cn","jzjyy.cn","jseea.cn","jszk.net"],#政府网站 7: ["ccb.com",'ok',"163.com","ibsbjstar.cc","app.com","maiziedu.com","browsershots.org","gerensuodeshui.cn", "gitlab.com","youdao.com","alicdn.com","qmail.com"],#功能性质网站 8:["biqudao.com","biqudu.com","siluke.tw","biquge.cc","6mao.com","biqiuge.com","biquge.info", "dingdiann.com","qq.com","booktxt.net","biquge.com","xs.la","208xs.com","xxbiquge.com", "xuexi111.com","ufochn.com","ahzww.net","555zw.com","biquge5200.com","bequge.com","bqg99.com", "bqg99.cc","sbiquge.com","biquge5200.cc","166xs.com"],# 娱乐类型网站 9: ["microsoft.com","weaver.com","oa8000.com","goodwaysoft.com","lenosoft.net", "lizheng.com","adobe.com","pexels.com","dingtalk.com","autodesk.com","qifeiye.com", "lizhengyun.com","shuishandt.com","windows7en.com","coursera.org","smoson.com","gongboshi.com", "huawei.com","spoon.net","jetbrains.com","sqlite.org","yesacc.com","sunlandzk.com", "alibabagroup.com","turbo.net","cqttech.com","prezi.com","tradedoubler.com", "renrendai.com","alizila.com","hongzhixx.cn","studyol.com","cnbim.com"],#企业网站 } start_time=FormatToStamp("请输入开始时间:") end_time = FormatToStamp("请输入结束时间:") new_time_dic=per_seconds(start_time,end_time) for row in data: stime=int((row[2] / 1000000) - 11644473600)#这是时间戳 Unix url=filter_data(row[0]) data_old = row if stime in new_time_dic: for i in web_dic: for j in web_dic[i]: if url in j: new_time_dic[stime][i] = 1 sites_count_sorted = sorted(new_time_dic.items(), key=lambda item: item[0]) # print(sites_count_sorted) for row_new in new_time_dic: if 1 in new_time_dic[row_new]: print(row_new,new_time_dic[row_new]) scatter_plot(sites_count_sorted)
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/19 ''' import os,sqlite3,re,time import matplotlib.pyplot as plt def FormatToStamp(string): flag=True while flag: try: formatTime=input("请输入%s(格式:2018-06-24 11:50:00)"%string).strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) def per_seconds(start_time,end_time): time_dict={} start_time=int(start_time) end_time=int(end_time) for i in range(start_time,end_time): time_dict[i]=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] return time_dict def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',domain) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def fold_line_diagram(results): # 折线图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' keys = [] values = [] for items in results: ntime=time.strftime("%Y-%m-%d %X", time.localtime(items[0])) keys.append(ntime) state=0 for i in range(10): if 1 == items[1][i]: state=i+1 break values.append(state) x = keys[-500:] #x = range(500) y = values[-500:] y_title=["搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站"] #plt.xticks(y_title) plt.xticks(rotation=45,fontsize='small') plt.plot(x, y, label="登陆网站散点图") plt.xlabel('当日时刻:秒') plt.ylabel('登陆网站类别') plt.title("用户登陆网站行为分析") plt.show() def scatter_plot(results): # 散点图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' keys = [] values = [] for items in results: ntime=time.strftime("%Y-%m-%d %X", time.localtime(items[0])) keys.append(ntime) state=0 for i in range(10): if 1 == items[1][i]: state=i+1 break values.append(state) x = keys[-100:] #x = range(500) y = values[-100:] y_title=["搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站","搜索引擎","大型门户网站"] #plt.xticks(y_title) plt.xticks(rotation=45,fontsize='small') plt.scatter(x, y, label="1:搜索引擎,2:大型门户网站") plt.xlabel('当日时刻:秒') plt.ylabel('登陆网站类别') plt.title("用户登陆网站行为分析") plt.legend() plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() web_dic={0:["360.cn","baidu.com","so.com","pypi.org","bing.com","stackoverflow.com","google.cn"],#搜索引擎 1: ["qihoo.com","eastday.com","toutiao.com","ufochn.com","timeacle.cn","bilibili.com","xfwed.com", "docin.com","sohu.com","msn.cn","chouti.com","milkjpg.com","btime.com","51xuedu.com", "joyme.com"],#大型门户网站 2: ["699pic.com","epub360.com","wix.com","crsky.com","runoob.com","scrapy.org","debugbar.com","linuxidc.com", "911cha.com","tuke88.com","readthedocs.org","jb51.net","readthedocs.io","github.com","888pic.com", "ibaotu.com","w3school.com","17sucai.com","mycodes.net","freemoban.com"],#行业网站 3: ["www.cc","b2b.cc","mall.cc","creditcard.cc","taobao.com","alipay.com", "tmall.com","jd.com","dangdang.com","company1.cc","ebank.cc"],#交易类网站 4: ["qcloud.com","360doc.com","eol.cn","xiaohuar.com","exam8.com"],#分类信息网站 5: ["csdn.net","2cto.com","liaoxuefeng.com","w3cschool.cn","cnblogs.com","zol.com", "python.org","douban.com","shidastudy.com","v2ex.com","i.cn","home.cn","passport.cn", "testerhome.com","aosabook.org","ggdoc.com","biqukan.com"],#论坛 6: ["apply.cc","ccopyright.com","gov.cn","jzjyy.cn","jseea.cn","jszk.net"],#政府网站 7: ["ccb.com",'ok',"163.com","ibsbjstar.cc","app.com","maiziedu.com","browsershots.org","gerensuodeshui.cn", "gitlab.com","youdao.com","alicdn.com","qmail.com"],#功能性质网站 8:["biqudao.com","biqudu.com","siluke.tw","biquge.cc","6mao.com","biqiuge.com","biquge.info", "dingdiann.com","qq.com","booktxt.net","biquge.com","xs.la","208xs.com","xxbiquge.com", "xuexi111.com","ufochn.com","ahzww.net","555zw.com","biquge5200.com","bequge.com","bqg99.com", "bqg99.cc","sbiquge.com","biquge5200.cc","166xs.com"],# 娱乐类型网站 9: ["microsoft.com","weaver.com","oa8000.com","goodwaysoft.com","lenosoft.net", "lizheng.com","adobe.com","pexels.com","dingtalk.com","autodesk.com","qifeiye.com", "lizhengyun.com","shuishandt.com","windows7en.com","coursera.org","smoson.com","gongboshi.com", "huawei.com","spoon.net","jetbrains.com","sqlite.org","yesacc.com","sunlandzk.com", "alibabagroup.com","turbo.net","cqttech.com","prezi.com","tradedoubler.com", "renrendai.com","alizila.com","hongzhixx.cn","studyol.com","cnbim.com"],#企业网站 } start_time=FormatToStamp("请输入开始时间:") end_time = FormatToStamp("请输入结束时间:") new_time_list =[] for row in data: web_type=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] stime=(row[2] / 1000000) - 11644473600#这是时间戳 Unix url=filter_data(row[0]) data_old=row if stime>start_time and stime<end_time: for i in web_dic: for j in web_dic[i]: if url in j: web_type[i] = 1 new_time_list.append([stime,web_type]) for row_new in new_time_list: if 1 in row_new[1]: print(row_new,new_time_list[1]) scatter_plot(new_time_list)
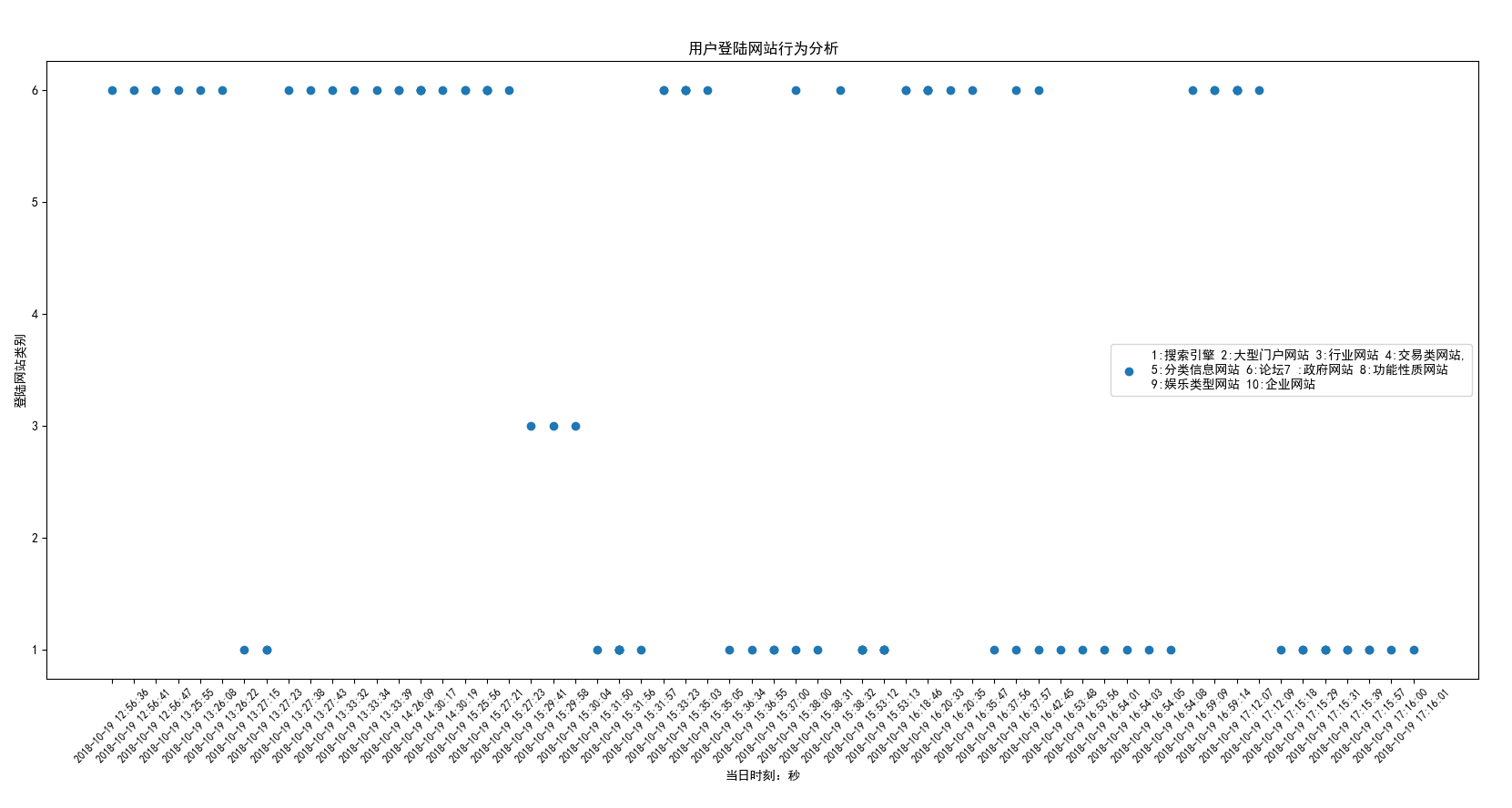
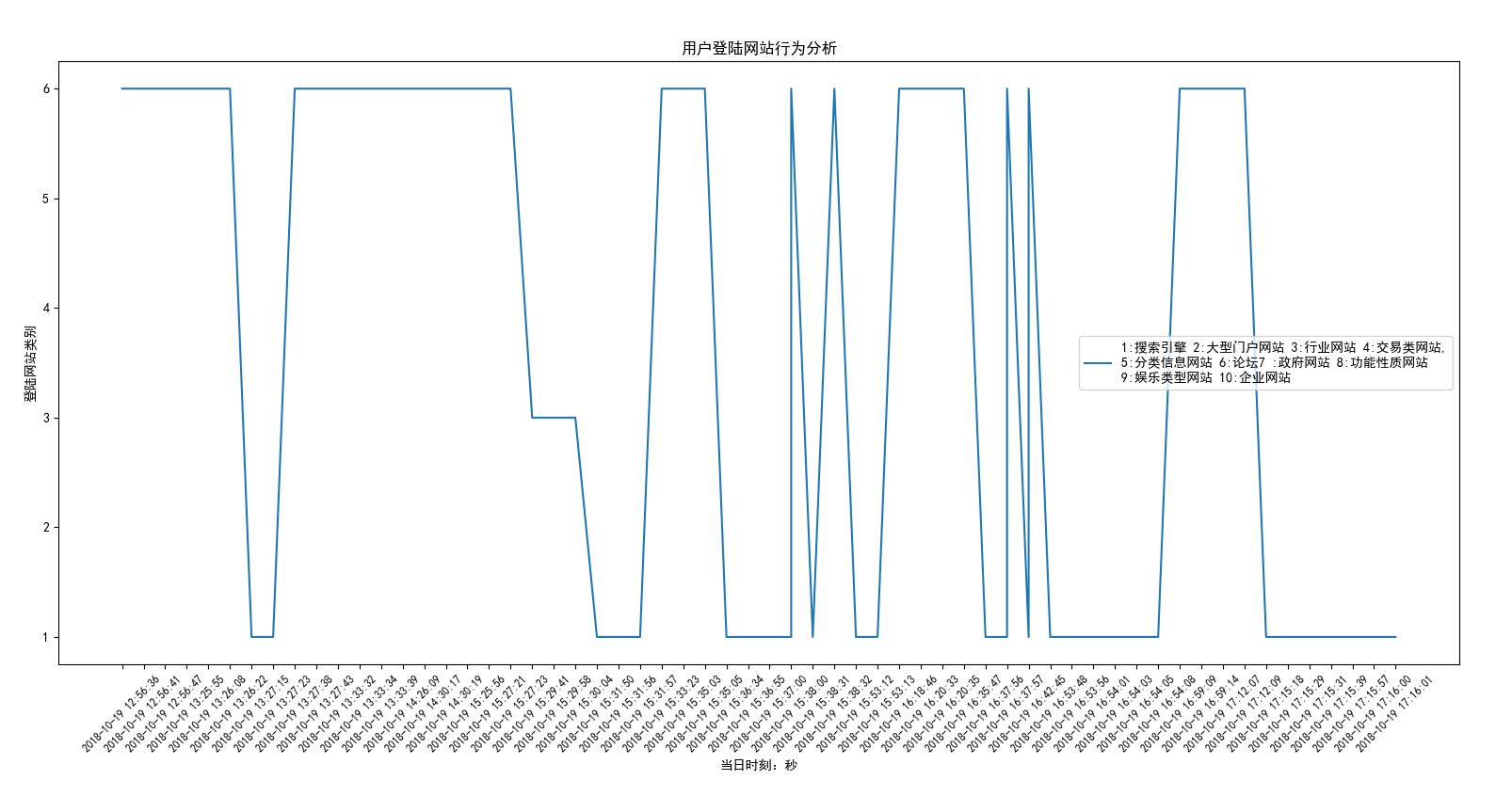
#!/usr/bin/env python3 #-*- coding:utf-8 -*- ''' Administrator 2018/10/19 ''' import os,sqlite3,re,time import matplotlib.pyplot as plt def FormatToStamp(string): flag=True while flag: try: formatTime=input("请输入%s(格式:2018-06-24 11:50:00)"%string).strip() formatTime=time.mktime(time.strptime(formatTime,'%Y-%m-%d %X')) return formatTime except Exception as e: print("转换失败,请重新输入。失败原因:%s"%e) def per_seconds(start_time,end_time): time_dict={} start_time=int(start_time) end_time=int(end_time) for i in range(start_time,end_time): time_dict[i]=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] return time_dict def filter_data(url): try: parsed_url_components = url.split('//') sublevel_split = parsed_url_components[1].split('/', 1) domain = sublevel_split[0].replace("www.", "") data=re.search('\w+\.(com|cn|net|tw|la|io|org|cc|info|cm|us|tv|club|co|in)',domain) if data: return data.group() else: address_count.add(sublevel_split[0]) return "ok" except IndexError: print('URL format error!') def fold_line_diagram(results): # 折线图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' keys = [] values = [] for items in results: ntime=time.strftime("%Y-%m-%d %X", time.localtime(items[0])) keys.append(ntime) state=0 for i in range(10): if 1 == items[1][i]: state=i+1 break values.append(state) x = keys[-100:] #x = range(500) y = values[-100:] #plt.xticks(y_title) plt.xticks(rotation=45,fontsize='small') plt.plot(x, y, label="1:搜索引擎 2:大型门户网站 3:行业网站 4:交易类网站,\n5:分类信息网站 6:论坛7 :政府网站 8:功能性质网站\n9:娱乐类型网站 10:企业网站") plt.xlabel('当日时刻:秒') plt.ylabel('登陆网站类别') plt.title("用户登陆网站行为分析") plt.legend() plt.show() def scatter_plot(results): # 散点图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 有中文出现的情况,需要u'内容' keys = [] values = [] for items in results: ntime=time.strftime("%Y-%m-%d %X", time.localtime(items[0])) keys.append(ntime) state=0 for i in range(10): if 1 == items[1][i]: state=i+1 break values.append(state) x = keys[-100:] #x = range(500) y = values[-100:] #plt.xticks(y_title) plt.xticks(rotation=45,fontsize='small') plt.scatter(x, y, label="1:搜索引擎 2:大型门户网站 3:行业网站 4:交易类网站,\n5:分类信息网站 6:论坛7 :政府网站 8:功能性质网站\n9:娱乐类型网站 10:企业网站") plt.xlabel('当日时刻:秒') plt.ylabel('登陆网站类别') plt.title("用户登陆网站行为分析") plt.legend() plt.show() if __name__=="__main__": address_count = set() # 创建一个空的集合,用来收集已经存在国际域名 data_path = r"D:\360浏览器\360se6\User Data\Default" files = os.listdir(data_path) history_db = os.path.join(data_path, 'History') conn = sqlite3.connect(history_db) cursor = conn.cursor() SQL = "SELECT urls.url,urls.title,visits.visit_time from visits LEFT JOIN urls on visits.url=urls.id" cursor.execute(SQL) data = cursor.fetchall() cursor.close() conn.close() web_dic={0:["360.cn","baidu.com","so.com","pypi.org","bing.com","stackoverflow.com","google.cn"],#搜索引擎 1: ["qihoo.com","eastday.com","toutiao.com","ufochn.com","timeacle.cn","bilibili.com","xfwed.com", "docin.com","sohu.com","msn.cn","chouti.com","milkjpg.com","btime.com","51xuedu.com", "joyme.com"],#大型门户网站 2: ["699pic.com","epub360.com","wix.com","crsky.com","runoob.com","scrapy.org","debugbar.com","linuxidc.com", "911cha.com","tuke88.com","readthedocs.org","jb51.net","readthedocs.io","github.com","888pic.com", "ibaotu.com","w3school.com","17sucai.com","mycodes.net","freemoban.com"],#行业网站 3: ["www.cc","b2b.cc","mall.cc","creditcard.cc","taobao.com","alipay.com", "tmall.com","jd.com","dangdang.com","company1.cc","ebank.cc"],#交易类网站 4: ["qcloud.com","360doc.com","eol.cn","xiaohuar.com","exam8.com"],#分类信息网站 5: ["csdn.net","2cto.com","liaoxuefeng.com","w3cschool.cn","cnblogs.com","zol.com", "python.org","douban.com","shidastudy.com","v2ex.com","i.cn","home.cn","passport.cn", "testerhome.com","aosabook.org","ggdoc.com","biqukan.com"],#论坛 6: ["apply.cc","ccopyright.com","gov.cn","jzjyy.cn","jseea.cn","jszk.net"],#政府网站 7: ["ccb.com",'ok',"163.com","ibsbjstar.cc","app.com","maiziedu.com","browsershots.org","gerensuodeshui.cn", "gitlab.com","youdao.com","alicdn.com","qmail.com"],#功能性质网站 8:["biqudao.com","biqudu.com","siluke.tw","biquge.cc","6mao.com","biqiuge.com","biquge.info", "dingdiann.com","qq.com","booktxt.net","biquge.com","xs.la","208xs.com","xxbiquge.com", "xuexi111.com","ufochn.com","ahzww.net","555zw.com","biquge5200.com","bequge.com","bqg99.com", "bqg99.cc","sbiquge.com","biquge5200.cc","166xs.com"],# 娱乐类型网站 9: ["microsoft.com","weaver.com","oa8000.com","goodwaysoft.com","lenosoft.net", "lizheng.com","adobe.com","pexels.com","dingtalk.com","autodesk.com","qifeiye.com", "lizhengyun.com","shuishandt.com","windows7en.com","coursera.org","smoson.com","gongboshi.com", "huawei.com","spoon.net","jetbrains.com","sqlite.org","yesacc.com","sunlandzk.com", "alibabagroup.com","turbo.net","cqttech.com","prezi.com","tradedoubler.com", "renrendai.com","alizila.com","hongzhixx.cn","studyol.com","cnbim.com"],#企业网站 } start_time=FormatToStamp("请输入开始时间:") end_time = FormatToStamp("请输入结束时间:") new_time_list =[] for row in data: web_type=[0 for x in range(10)]#生成一个记录单条数据的列表 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] stime=(row[2] / 1000000) - 11644473600#这是时间戳 Unix url=filter_data(row[0]) data_old=row if stime>start_time and stime<end_time: for i in web_dic: for j in web_dic[i]: if url in j: web_type[i] = 1 new_time_list.append([stime,web_type]) # for row_new in new_time_list: # if 1 in row_new[1]: # print(row_new,new_time_list[1]) fold_line_diagram(new_time_list)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端