Elasticsearch之-mapping 映射管理
目录
Elasticsearch之-mapping 映射管理
- 一个 Mapping 是针对一个索引中的 Type 定义的
- ES 中的文档都存储在索引的 Type 中
- 在 ES 7.0 之前,一个索引可以有多个 Type,所以一个索引可拥有多个 Mapping
- 在 ES 7.0 之后,一个索引只能包含一个特殊类型,即
_doc类型。,所以一个索引只对应一个 Mapping - 在5.x版本中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x版本中运行。从Elasticsearch 7.0版开始,类型(type)的使用已被弃用,并在Elasticsearch 8.0中完全移除。因此,在Elasticsearch 8.0及以上版本中,你不能创建一个新的type
一、映射介绍
-
一个mapping由一个或多个analyzer组成, 一个analyzer又由一个或多个filter组成的。当ES索引文档的时候,它把字段中的内容传递给相应的analyzer,analyzer再传递给各自的filters。
- filter的功能很容易理解:一个filter就是一个转换数据的方法, 输入一个字符串,这个方法返回另一个字符串,比如一个将字符串转为小写的方法就是一个filter很好的例子。
- 一个analyzer由一组顺序排列的filter组成,执行分析的过程就是按顺序一个filter一个filter依次调用, ES存储和索引最后得到的结果。
-
总结来说, mapping的作用就是执行一系列的指令将输入的数据转成可搜索的索引项
-
当你的查询没有返回相应的数据, 你的mapping很有可能有问题。当你拿不准的时候, 直接检查你的mapping
-
ES 动态 Mapping
- 文档中有一个之前没有出现过的字段被添加到ELasticsearch之后,文档的type mapping中会自动添加一个新的字段。这个可以通过dynamic属性去控制,dynamic属性为false会忽略新增的字段、dynamic属性为strict会抛出异常。如果dynamic为true的话,ELasticsearch会自动根据字段的值推测出来类型进而确定mapping
- 动态 Mapping 使得我们可以不定义 Mapping,ES 会自动根据文档信息,推断出字段的类型。
- 但有时候也会推断错误,不符合我们的预期,比如地理位置信息等
-
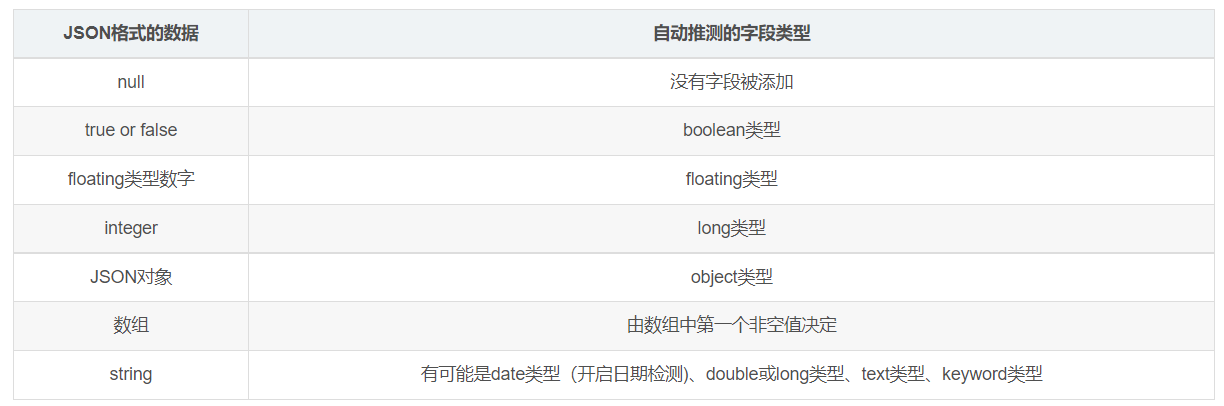
ES 类型的自动识别规则如下:
- ES 中的 Mapping 相当于传统数据库中的表定义,它有以下作用:
- 定义索引中的字段的名字。
- 定义索引中的字段的类型,比如字符串,数字等。
- 定义索引中的字段是否建立倒排索引
- 告诉es如何索引数据及是否可以被搜索
- 会让索引建立的更加细致和完善
1.1 查看mapping信息
# 查看books索引的mapping
GET books/_mapping
# 获取所有的mapping
GET _all/_mapping
1.2 type中的字段数据类型
- elasticsearch会对text类型字段的值分析,进行分词做倒排索引,keyword类型不会被分词,原样存储,原样匹配
string类型:text,keyword
数字类型:long,integer,short,byte,double,float
日期类型:date
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表),join数据类型(类似关系型数据库中的 Join 操作)为同一索引中的文档定义父/子关系
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
1. 对于数组类型 Arrays,ES 并没有提供专门的数组类型,但是任何字段都可以包含多个相同类型的数据,比如:
# 当在 Mapping 中查看这些数组的类型时,其实还是数组中的元素的类型,而不是一个数组类型
["one", "two"] # 一个字符串数组
[1, 2] # 一个整数数组
[1, [ 2, 3 ]] # 相当于 [ 1, 2, 3 ]
[{ "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }] # 一个对象数组
2. 为什么需要 Nested 类型
2.1 假如我们有如下结构的数据:
GET my_movies/_doc/1
{
"title":"Speed",
"actors":[ # actors 是一个数组类型,数组中的元素是对象类型
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
2.2 将数据插入 ES 之后,执行下面的查询:
GET my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}
"""
分析:按照上面的查询语句,我们想查询的是 first_name=Keanu 且 last_name=Hopper 的数据,所以我们认为刚才插入的 id 为 1 的文档应该不符合这个查询条件。但实际情况是:在 ES 中执行上面的查询语句,却能查出 id 为 1 的文档。这是为什么呢
这是因为,ES 对于这种 actors 字段这样的结构的数据,ES 并没有考虑对象的边界。
实际上,在 ES 内部,id 为 1 的那个文档是这样存储的:
"title":"Speed"
"actors.first_name":["Keanu","Dennis"]
"actors.last_name":["Reeves","Hopper"]
所以这种存储方式,并不是我们之前想象的那样
那如何才能真正的表达一个对象类型呢?这就需要使用到 Nested 类型
"""
2.3 使用 Nested 类型
Nested 类型允许对象数组中的对象被独立(看作一个整体)索引。
我们对 my_movies 索引设置这样的 mappings:
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested", # 将 actors 设置为 nested 类型
"properties" : { # 这时 actors 数组中的每个对象就是一个整体了
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}
2.4 写入数据后,在进行这样的搜索,就不会搜索出数据了:
# 查询电影信息
GET my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}
2.5 但是这样的查询也查不出数据:
GET my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Reeves"}}
]
}
}
}
2.6 搜索 Nested 类型
这是因为,查询 Nested 类型的数据,要像下面这样查询:
GET my_movies/_search
{
"query": {
"bool": {
"must": [
{
"nested": { # nested 查询
"path": "actors", # 自定 actors 字段路径
"query": { # 查询语句
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
} # end nested
}
] # end must
} # end bool
}
}
2.7 聚合 Nested 类型
# 对 Nested 类型的数据进行聚合,示例:
GET my_movies/_search
{
"size": 0,
"aggs": {
"actors": { # 自定义聚合名称
"nested": { # 指定 nested 类型
"path": "actors" # 聚合的字段名称
},
"aggs": { # 子聚合
"actor_name": { # 自定义子聚合名称
"terms": { # terms 聚合
"field": "actors.first_name", # 子字段名称
"size": 10
}
}
}
}
}
}
2.8 使用普通的聚合方式则无法工作:
GET my_movies/_search
{
"size": 0,
"aggs": {
"actors": { # 自定义聚合名称
"terms": { # terms 聚合
"field": "actors.first_name",
"size": 10
}
}
}
}
1.3 mapping中的相关参数
| 属性 | 描述 | 适合类型 |
|---|---|---|
| enabled | ELasticseaech默认会索引所有的字段,如果设置成 false,es会跳过字段内容,表示数据仅做存储,不支持搜索和聚合分析(数据保存在 _source 中,只能从_source中获取)。默认值为 true |
all |
| store | 默认情况下,是被索引的也可以搜索,但是不存储,这也没关系,因为_source字段里面保存了一份原始文档。在某些情况下,store参数有意义,比如一个文档里面有title、date和超大的content字段,如果只想获取title和date给这俩字段的store设为true 。默认值为 false |
all |
| norms | 字段是否支持算分。 如果字段只用来过滤和聚合分析,而不需要被搜索(计算算分),那么可以设置为 false,可节省空间。默认值为 true |
all |
| index | 字段是否建立倒排索引。 如果设置成 false,表示不建立倒排索引(节省空间),同时数据也无法被搜索,但依然支持聚合分析,数据也会出现在 _source 中。默认值为 true |
text |
| index_options | 控制存储哪些信息到倒排索引中,有4个参数:docs、freqs、positions、offsets | |
| null_value | 值为空的字段不索引也不可以搜索,null_value参数可以给空值字段设置一个默认值。让值为空的字段可索引、可搜索。 | all |
| analyzer | 指定分词器,只有 text 类型的数据支持。 默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 |
all |
| properties | Object或者nested类型,还有嵌套类型,可以通过properties参数指定 | |
| include_in_all | 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false | all |
| format | 时间格式字符串模式 | date |
| normalizer | 用于解析前的标准化配置,比如把所有的字符转化为小写等 | all |
| boost | 可增强字段的算分 | all |
| coerce | 是否开启数据类型的自动转换。 比如字符串转数字,默认值是true,会将输入的文档的该字段值类型进行自动转换后存储,为false则不转换直接存储,但是可能会因为输入的值的类型错误导致失败 |
string、数字类型 |
| copy_to | 用于字段合并。 换言之,就是多个字段可以合并成一个超级字段。比如,first_name和last_name两个字段可以合并为full_name字段,即full_name字段中包含了first_name 和 last_name的值 |
all |
| doc_values | 如果确定不需要对字段进行排序或聚合,也不需要从脚本访问字段值,则可以将其设置为 false,以节省磁盘空间。默认值为 true |
date、数字类型 |
| fielddata | 如果要对 text 类型的数据进行排序和聚合分析,则将其设置为 true。 默认为 false开启fielddata非常消耗内存。在你开启text字段以前,想清楚为什么要在text类型的字段上做聚合、排序操作。大多数情况下这么做是没有意义的 |
text |
| fields | 让一个字段拥有多个子字段类型,使得一个字段能够被多个不同的索引方式进行索引 比如一个String类型的字段,可以使用text类型做全文检索,使用keyword类型做聚合和排序 |
|
| dynamic | 控制 mapping 的自动更新,用于录入新数据时,检测新发现的字段,有三个取值取值有 true,false,strict。true :录入新数据时,新发现的字段添加到映射中。(默认)flase :录入新数据时,新检测的字段被忽略。必须显式添加新字段。strict :录入新数据时,如果检测到新字段,就会引发异常并拒绝文档 |
|
| ignore_above | 在ElasticSearch中keyword,text类型字段都可以设置ignore_above属性,表示最大的字段值长度,超出这个长度的字段将不会被索引,但是会存储,ignore_above一般设置为256 | |
| ignore_malformed | ignore_malformed可以忽略不规则数据。给一个字段索引不合适的数据类型会发生异常,导致整个文档索引失败。如果 ignore_malformed 参数设为true,异常会被忽略,出异常的字段不会被索引,其它字段正常索引 | |
| ...... | 其他和上面参数的用法请查看这里 |
二、创建索引时指定映射
- 注意:mapping类型一旦确定,以后就不能修改了,但
dynamic 为true时,可以新增其他字段
2.1 6.x的版本写法
PUT books
{
"mappings": {
"book":{
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
}
2.2 7.x版本以后
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
2.3 插入数据测试
# 测试数据1
PUT books/_doc/1
{
"title":"大头儿子小偷爸爸",
"price":100,
"addr":"北京天安门",
"company":{
"name":"我爱北京天安门",
"company_addr":"我的家在东北松花江傻姑娘",
"employee_count":10
},
"publish_date":"2019-08-19"
}
# 测试数据2
PUT books/_doc/2
{
"title":"白雪公主和十个小矮人",
"price":"99", # 写字符串会自动转换
"addr":"黑暗森里",
"company":{
"name":"我的家乡在上海",
"company_addr":"朋友一生一起走",
"employee_count":10
},
"publish_date":"2018-05-19"
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号