CTFshow-Crypto(13-16)
13crypto12

跟字母替换有关
uozt{Zgyzhv_xlwv_uiln_xguhsld}
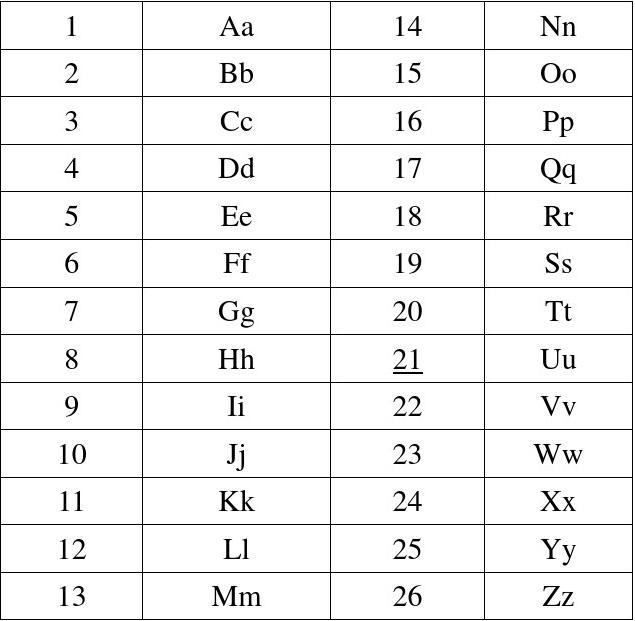
u-21 f-6
o-15 l-12
z-26 a-1
t-20 g-7
发现对应两个字母加起来为27
查资料发现这是埃特巴什码
埃特巴什码
最后一个字母替换第一个字母,倒数第二个字母替换第二个字母。
明文:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文替换明文
密文:Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
在线网站解码
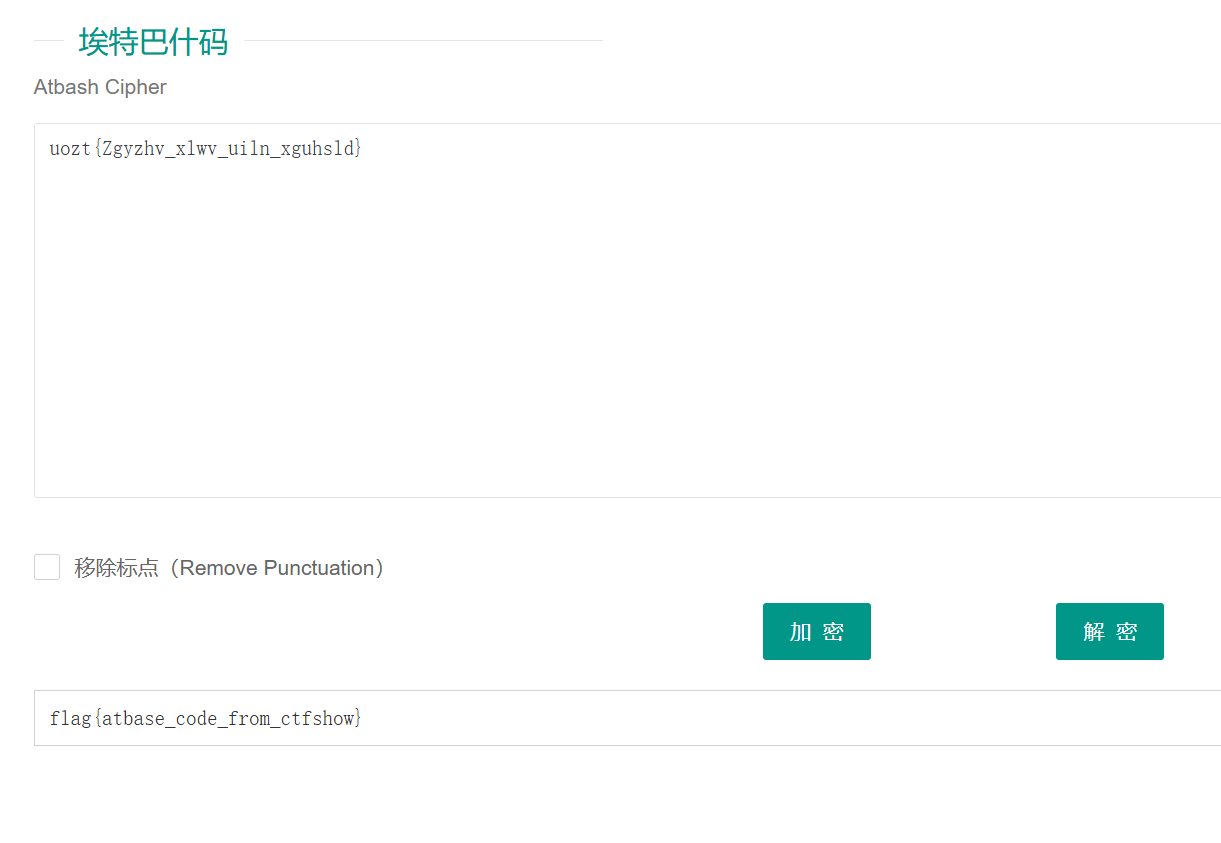
注意手动替换大小写
脚本解码
a = 'uozt{Zgyzhv_xlwv_uiln_xguhsld}'
b = ''
for i in a:
if i.islower():
b += chr((26- (ord(i) - 96)) + 97)
elif i.isupper():
b += chr((26- (ord(i) - 64)) + 65)
else :
b += i
print(b)
14crypto13
下载附件是两个文件,第一个是macOS操作系统的,选择适合自己系统的就行
打开base.txt发现有非常长的密文(千万级别),提示是base家族,肯定是base嵌套
脚本一
import base64
filename = r"C:\Users\86157\Desktop\base家族\base.txt"
with open(filename) as f:
s = f.read()
while True:
try:
s = base64.b16decode(s)
continue
except:
pass
try:
s = base64.b32decode(s)
continue
except:
pass
try:
s = base64.b64decode(s)
continue
except:
pass
break
print(s)
前缀r或R用于定义一个原始字符串(raw string)。原始字符串不会处理反斜杠(\)为转义字符。
base64.b16decode()
获得二进制形式的解码字符串。
读取文件
Python文件读写详解(非常详细)_python 了解文件读写-CSDN博客
read方法
【Python】一文详细介绍 File对象的read()方法_python file.read(buffer)-CSDN博客
脚本二
import re, base64 //导入正则表达式模块re和Base64编码/解码模块base64
s = open("base.txt", "rb").read()
//使用二进制模式("rb")打开名为base.txt的文件,并读取其全部内容。读取的内容存储在字节串s中。
\# 正则表达式,用来尽可能多的匹配字符串
base16_dic = r'^[A-F0-9]*$'
base32_dic = r'^[A-Z2-7=]*$'
base64_dic = r'^[A-Za-z0-9/+=]*$'
\# 循环解码
while True:
t = s.decode() #将字节串s解码为字符串t
if '{' in t: #如果字符串t中包含字符'{',则打印t并退出循环
print(t)
break
# 否则,根据t的格式使用不同的解码方法
elif re.match(base16_dic, t):
s = base64.b16decode(s)
print(16)
elif re.match(base32_dic, t):
s = base64.b32decode(s)
print(32)
elif re.match(base64_dic, t):
s = base64.b64decode(s)
print(64)

在处理二进制文件时,打开文件时需要指定'rb'模式。
正则表达式(脚本中出现的)
正则表达式 – 语法 | 菜鸟教程 (runoob.com)
[A-Z] 表示一个区间,匹配所有大写字母
[^ABC]匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字符。
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)
base32_dic = r'^[A-Z2-7=]*$
匹配一个字符串,该字符串完全由大写字母 A 到 Z、数字 2 到 7 和等号 = 组成,并且这个字符串没有其他任何字符。
r前缀:这是一个原始字符串前缀,它告诉Python不要解释反斜杠(\)为转义字符。这在正则表达式中特别有用,因为反斜杠在正则表达式中通常用作转义字符。^:匹配字符串的开始位置。[A-Z2-7=]:这是一个字符集,它匹配任何在括号内的字符。具体来说,它匹配以下字符:- 大写字母 A 到 Z
- 数字 2 到 7
- 等号
=
*:表示前面的字符集([A-Z2-7=])可以出现零次或多次。$:匹配字符串的结束位置。
工具
感兴趣的可以下载
mufeedvh/basecrack: Decode All Bases - Base Scheme Decoder (github.com)
15crypto14
题目:
00110011 00110011 00100000 00110100 00110101 00100000 00110101 00110000 00100000 00110010 01100110 00100000 00110011 00110011 00100000 00110101 00110110 00100000 00110100 01100101 00100000 00110100 00110110 00100000 00110100 00110110 00100000 00110110 01100100 00100000 00110100 01100101 00100000 00110100 00110101 00100000 00110100 00110001 00100000 00110110 01100101 00100000 00110110 01100011 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110100 00100000 00110100 00110011 00100000 00110100 01100100 00100000 00110110 01100100 00100000 00110101 00110110 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110001 00100000 00110110 00110100 00100000 00110011 00111001 00100000 00110111 00110101 00100000 00110100 00110111 00100000 00110000 01100001
一串二进制数,先转成字符串
33 45 50 2f 33 56 4e 46 46 6d 4e 45 41 6e 6c 48 44 35 64 43 4d 6d 56 48 44 35 61 64 39 75 47 0a
baseX特征
base16:字母A-F、数字0-9
base32:字母A-Z、数字2-7、符号=
base64:字母A-Z、a-z、数字0-9、符号/+=
判断为base64进行解码
3EP/3VNFFmNEAnlHD5dCMmVHD5ad9uG
或者直接一步到位
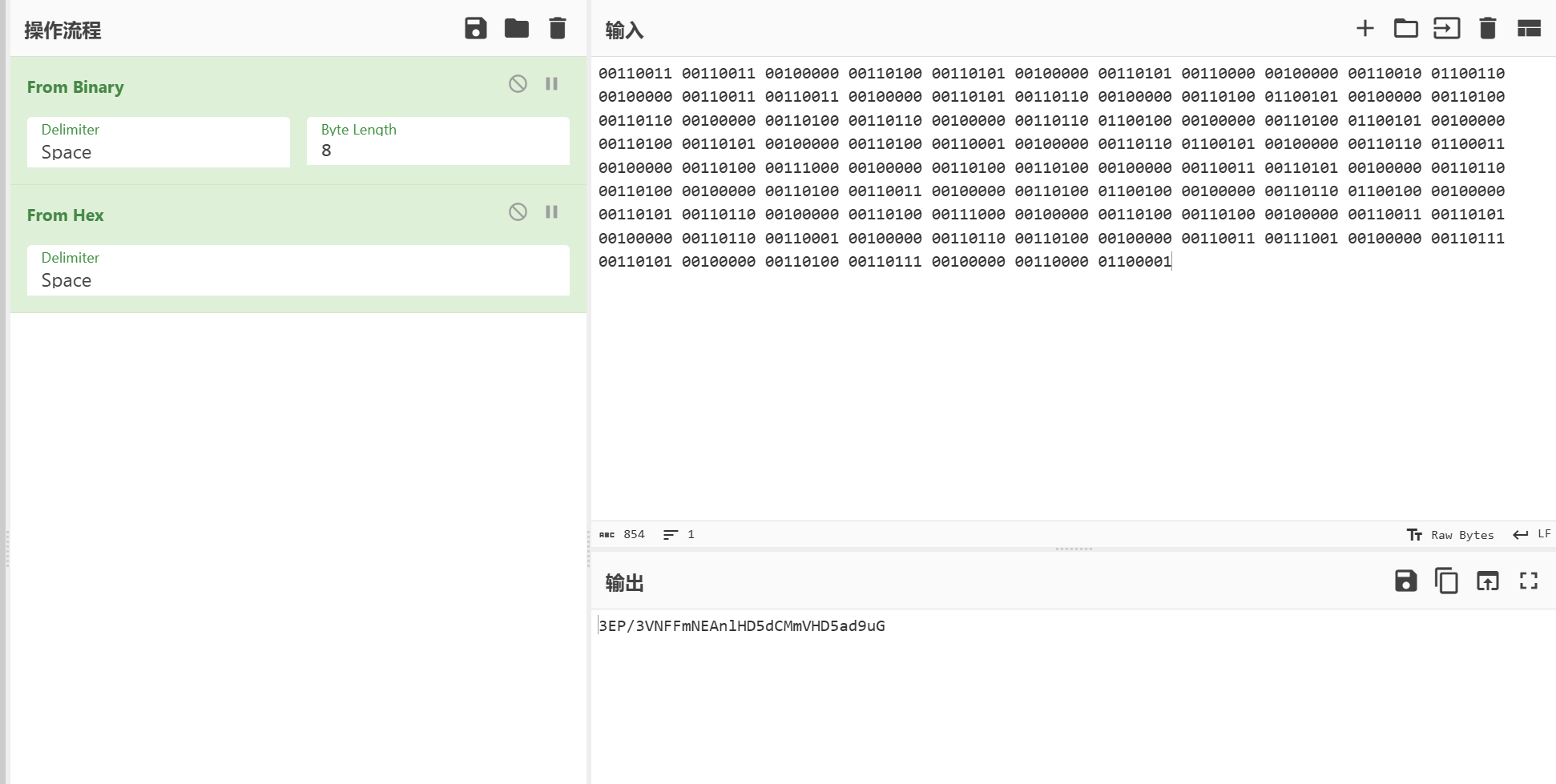
直接base64解码不行,需要根据base64编码表 对这串代码进行移位替换
base64编码表
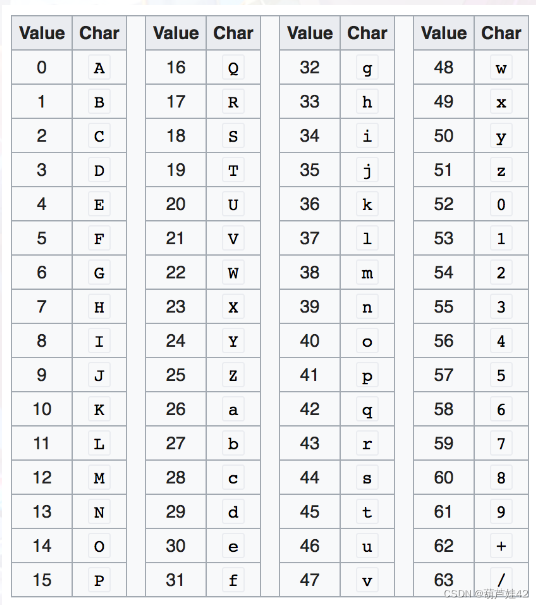
密文开头是 3EP/ 而flag的base64编码为:ZmxhZw==
3-55 Z-25 55-30=25
E-4 m-38 4-30+64=38
偏移量为30
脚本
import base64
s = '3EP/3VNFFmNEAnlHD5dCMmVHD5ad9uG'
a = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='
flag = ''
for i in s:
flag += a[(a.index(i) - 30) % 64]
if len(flag) % 4 != 0:
flag += '=' * (4 - len(flag) % 4)
print(flag)
print(base64.b64decode(flag).decode('UTF-8'))
index()
a.index(i) 会返回 i 第一次出现在 a 中的索引(从0开始计数)
python取模
在Python中,% 运算符用于取模,并且对于负数被除数,结果的符号与被除数相同。
使用Python的%运算符,-26 % 64 的结果是:38
16萌新_密码5

由田中 由田井 羊夫 由田人 由中人 羊羊 由由王 由田中 由由大 由田工 由由由 由由羊 由中大
工具梭哈
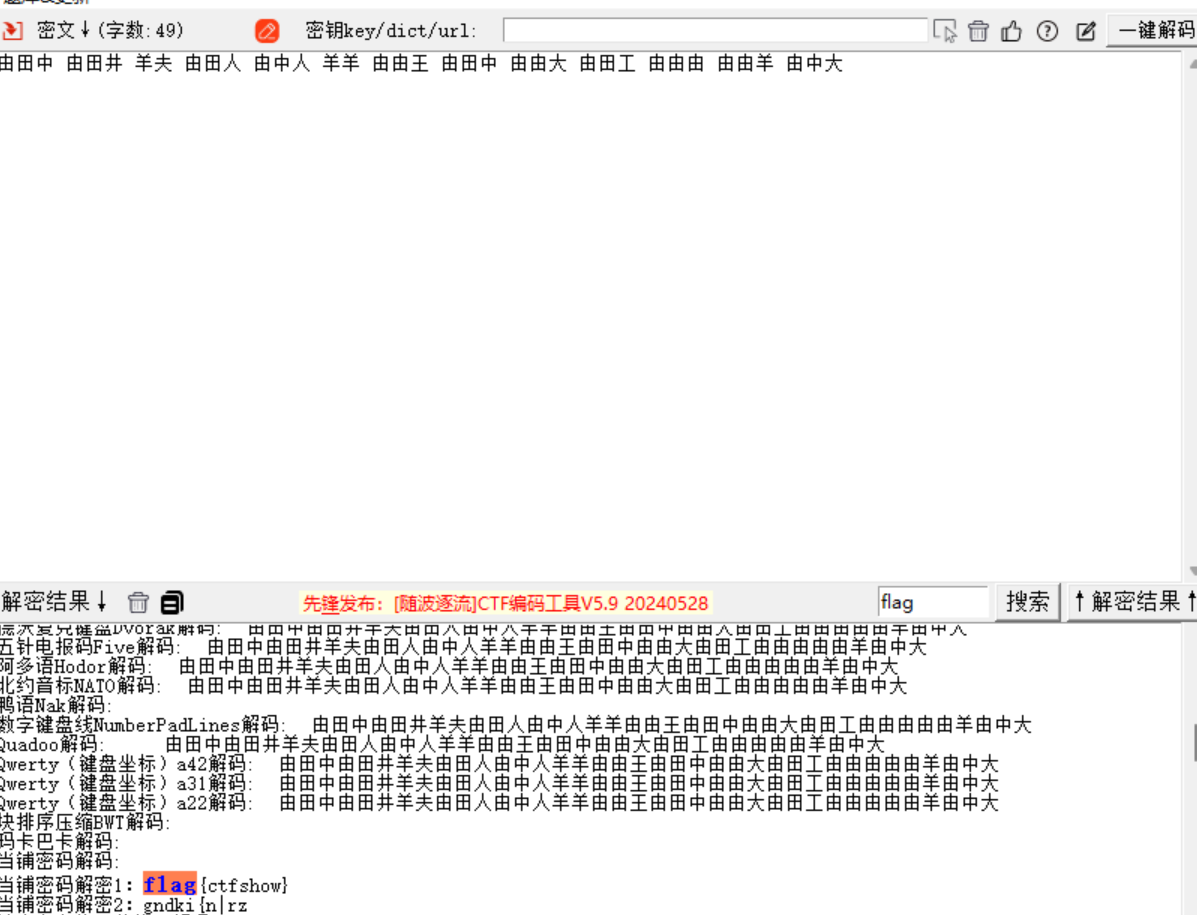
当铺密码
当前汉字有多少笔画出头,就是转化成数字几,再Ascii解码
例如:口 0 田 0 由 1 中 2 人 3 工 4 大 5 王 6 夫 7 井 8 羊 9
由田中 由田井 羊夫 由田人 由中人 羊羊 由由王 由田中 由由大 由田工 由由由 由由羊 由中大
102 108 97 ...
脚本
dh = '田口由中人工大土士王夫井羊壮'
ds = '00123455567899'
cip = '由田中 由田井 羊夫 由田人 由中人 羊羊 由由王 由田中 由由大 由田工 由由由 由由羊 由中大'
s = ''
for i in cip:
if i in dh:
s += ds[dh.index(i)]
else:
s += ' '
print(s)
ll = s.split(" ")
print(ll)
t = ''
for i in range(0,len(ll)):
t += chr(int(ll[i]))
print(t)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号