.png)
fu2019:User intimacy model for question recommendation in community question answering
摘要:
在社区问答(CQA)中,我们解决了向合适的用户自动推荐新问题的问题。主要的挑战是准确地选择合适的用户来回答给定的问题。大多数方法通过评估用户的能力、兴趣或两者的混合来寻找合适的用户。然而,这忽略了用户和不同话题的提问者之间的亲密关系。问与答之间的亲密关系是问题推荐的一个重要因素。例如,如果用户对某个问题感兴趣,并且与提问者关系密切,那么他很可能会发布一个答案。在CQA中,我们提出了一种新的话题模型,利用社交互动对用户之间的话题亲密度进行建模和学习,用于问题推荐。我们认为,本文是第一个评估用户对不同话题的亲密度,并调查对CQA问题推荐性能的影响的研究。我们提出了一种用户亲密度模型(UIM),这是一种lda风格的模型,在问答(QA)对的生成过程中引入社会互动,以建模和学习用户之间的主题亲密度。使用堆栈溢出的真实数据进行的实验表明,我们基于uim的方法一致且显著地提高了问题推荐的性能,证明了我们的方法可以通过利用用户对主题的亲密度来提高CQA问题推荐的准确性,这是问题推荐中的一个重要因素。
简介:
在线问答(Q&A)社区,如Stack Overflow,Yahoo!Answers和Quora已经成为在线信息寻求和知识分享的流行平台。随着问题数量的增加,人们很难找到感兴趣的问题。结果,回答的耗时显著增加,CQA的参与率降低。例如,将近1600万个问题被发布,StackOverflow有超过100万个问题没有收到答案。自动推荐新问题给合适的用户将有助于尽快解决这些问题,这将提高CQA系统的性能。如我们所见,问题推荐很重要。
问题推荐的一个主要挑战是很难找到合适的用户来回答给定的问题。大多数方法都试图通过评估用户的能力、兴趣或两者的混合来为一个问题找到合适的用户。例如,基于扩展的概率潜在语义分析(PLSA)[1],将用户兴趣建模为多个主题的分布,同时考虑角色之间的区别,通过挖掘用户的问题及其分类[2]来提取兴趣,估计专家寻找[3]问题的评级矩阵中的缺失值,同时考虑被问者和被回答者[4]之间的链接结构和话题相似度。
上述模型没有考虑被问者和被回答者之间的亲密性,这是问题推荐的一个重要因素。例如,如果用户对某个问题感兴趣,并且与提问者关系密切,那么他可能会发布一个答案。社交搜索引擎Aardvark[5]根据询问者和回答者之间的亲密度来评估用户的兴趣,但它的缺点是两个用户之间的亲密度是独一无二的,可能不能正确反映话题之间亲密度的变化。例如,两个用户之间的亲密程度可能会因“Java”和“Matlab”的主题而不同。(两个用户之间的亲密度并不是一个确定的值,这个亲密度也和问题所属的主题的不同而不同)
我们如何评估用户之间不同话题的亲密度?在问题推荐中,用户对一个话题的亲密度是否比类别[6,7]和回答者[1,2]更重要?我们是否可以将不同的特征与用户之间的亲密度结合在一起,从而提高推荐系统的有效性?所有这些问题都值得我们关注。本文通过不同的方法估计了用户对不同话题的亲密度及其对问题推荐性能的影响。我们相信我们是第一个研究这些重要问题的。我们提出了一种lda风格的模型——用户亲密话题模型(user intimacy topic model, UIM),该模型在问答对(QA)的生成过程中引入了社交互动。
社交互动是表征CQA用户之间关系的一个重要特征。关于这个问题有大量的研究。基于竞争的排名模型[8-10]和基于图的模型[4,11]已经被提出用来估计用户的专家分数。我们的目标是通过在CQA中挖掘社交互动来评估用户之间的亲密度,以衡量用户回答问题的潜力,而不是回答问题的能力。我们只关注CQA中最常见的社交互动:回答问题。以Stack Overflow为例,最常见的两种社交活动是提问和回答问题。与这些活动相对应的两种社会角色是“提问者”和“回答者”,前者负责编写问题并等待答案,后者的答案可能会引起他们的兴趣。此外,由于回答问题可以被理解为参与分散对话的一种方式,这些角色之间可以产生社会互动。例如,A回答B的问题可以看作是A作为回答者和B作为提问者之间的互动。他们有共同的兴趣。这种关系也可以用来评估用户对某一话题的亲密程度。我们的方法假设了一个简单而直观的原则来评估用户之间对某一话题的亲密度。如果用户A相比用户C回答更多用户B的问题,那么A和B之间的亲密关系是可能要大于C和B之间的亲密度,A和B的出现在许多QA对表明用户B应该与用户A亲密。因此,我们可以使用生成模型来模拟QA对中用户的共现性,从而估计用户对某个话题的亲密度。这促使我们利用社交互动,在一个主题模型的基础上,在不同主题上模拟用户之间的亲密关系。
在UIM中,我们使用多项式分布来表示被询问者对某一话题的所有回答的亲密度。每个问题的答案都是根据提问者和问题的主题从分布中抽取的。我们采用吉布斯抽样法通过“反转”生成过程来评估亲密度。最后,我们对每个问题对所有用户进行排序,根据用户和提问者对候选用户和问题内容相关的话题的亲密度,将一个问题推荐给排名最高的用户。我们对工作有三个主要贡献。
首先,UIM考虑了请求者和应答者之间的依赖关系,为理解底层qa对内容生成过程提供了一个新颖的视角。具体来说,我们利用UIM对用户之间的亲密关系进行建模,以进行问题推荐。
接下来,我们在真实数据上进行了系统的实验,比较基于类别、回答者和问题内容的推荐方法的效果。结果表明,与基准方法相比,我们的基于UIM的方法一致且显著地提高了问题推荐的性能,并可以通过利用用户对主题的亲密度来提高问题推荐的准确性。我们表明这种亲密感是问题推荐中的一个重要因素。
最后,我们提出了一种基于UIM的问题推荐方法。这使得我们可以很自然地将候选用户和询问者之间关于某个主题的亲密关系以及候选用户和问题之间的内容相关性整合到一个统一的概率框架中,这更易于解释。大多数方法只考虑内容的相关性。
相关工作
本文综述了社区问答、问题推荐、专家发现和主题模型等方面的研究进展。
-
推荐系统
由于问题推荐是一种推荐系统,我们首先回顾了一些经典的推荐方法,包括基于内容的推荐(CB)、协同过滤(CF)和群组推荐。在基于内容的推荐中,用户将被推荐与用户过去偏好相似的项目。Son等人[12]提出了一种基于内容的过滤(CBF)方法,该方法在计算相关性时使用多属性网络来反映多个属性,从而向用户推荐项目。Lu[13]提出了基于内容的协同过滤(CCF)方法用于Bing的新闻话题推荐。在协同过滤中,用户会被具有相似品味和偏好的人推荐的项目,也就是说,用户会互相帮助,找到他们可能喜欢的东西。Jamali等人[14]利用矩阵分解技术探索了一种基于模型的社交网络推荐方法。Chen等人[15]提出了一种关注协同过滤(ACF)模型来解决多媒体推荐中的隐式反馈问题。群组推荐适用于需要向一组用户提供推荐的情况。Wang等人[16]提出了一种群体推荐方法,通过考虑所有成员对群体活动的贡献来建模群体概况。Wang et al.[17]提出了一种针对群体推荐(HVGR)系统的层次可视化方法,以提供可视化的展示和直观的解释。
-
社区问答
最近有大量关于挖掘CQA站点的工作。hanes等人[18]提出了一个通用的分类器层次结构框架来预测CQA中答案的质量。Wang等人[19]提出了一种被称为正则化竞争模型(regularized competition model, RCM)的问题难度估计方法,它自然形成了用户-问题比较和文本描述的统一框架。为了解决问题检索中被查询问题和过去问题之间的词汇间隙问题,Chen等人提出了[20],一种混合的问题检索方法,将经典的(查询似然)和基于翻译的语言模型与他们提出的基于语义的语言模型混合在一起。Zhang等人[21]提出了一种能够无缝集成关键概念及其释义的问题检索模型。Chen等人[22]采用了一种基于随机行走的学习方法,通过循环神经网络匹配提问者的问题和其他用户提出的历史问题之间的相似性。Zhou等人[23]提出利用CQA页面中的类别信息元数据对连续词嵌入进行建模和学习,并使用两种类别驱动模型进行问题检索。为了减少响应等待时间,Pedro等[8]提出了RankSLDA算法,扩展了有监督潜Dirichlet算法用于问题推荐。Mahmood等人[24]引入了未来专家发现的新问题。考虑到当前的专业知识证据,他们的目标是预测未来专家的最佳排名。为了通过用户的搜索问题了解用户的信息需求,Cai等[25]提出了一种利用维基百科语义知识进行CQA问题分类的方法。tsurr等人[26]建议在查询内容的基础上建模查询的结构,以检测带有问题意图的查询。他们提出了一种有监督的分类方案,用于变长文本的词簇随机森林,以建模查询结构。Zhou等人[27]提出了一种用于CQA中答案选择的递归卷积神经网络(RCNN)。Vinay等人[28]为CQA服务提出了一种通过使用结构化确定性点过程(SDPPs)来解决“不完全答案问题”的答案总结方法。Zhang等人[29]提出了一种针对PCQA领域的方法,通过将检测建模为问题对上的分类问题来检测重复问题。Yao等人[30]提出了一系列算法来预测提问/回答帖子的投票分数。为了实现这一点,他们确定了影响帖子投票的三个关键方面:特性和输出之间的非线性关系,问题和回答耦合,以及数据到达的动态方式。
-
问题推荐
问题推荐是CQA研究中一个很有吸引力和挑战性的问题,它将一个新问题自动推荐给合适的用户来回答。已经提出了几种方法来解决这个问题。例如,Aardvark社交搜索引擎会将一个新问题发送给提问者扩展的社交网络中最有可能回答[5]的人。Guo等人[31]提出了一种生成模型UQA模型,用于推荐用户可能感兴趣的新问题的到来。Qu等人[32]采用概率潜在语义分析(probabilistic latent semantic analysis, PLSA)模型帮助用户定位感兴趣的问题。Ni等人[2]提出了一种生成式的基于主题的用户兴趣(TUI)模型,通过挖掘用户在用户交互问答(UIQA)系统中提出的问题、参与的类别和相关的答案提供者来捕获用户兴趣。Yang等人[7]提出了主题专家模型(topic expertise model, TEM),这是一种混合了高斯混合模型(Gaussian mixture model, GMM)的概率生成模型,将文本内容模型和链接结构分析相结合,对主题和专家进行联合建模。基于TEM的结果,他们提出了CQARank来测量不同情况下的用户兴趣和专业知识得分。
我们知道,以前没有关于用户和被询问者之间的亲密关系的工作来推荐答案。与以前的工作不同,我们的应答者推荐同时捕获了CQA中提问者、提问者和应答者之间的关系,并根据用户的兴趣以及提问者和应答者对某个主题的亲密程度来推荐应答者。
-
专家发现
CQA的专家发现是指寻找能够提供大量高质量、完整、可靠答案的用户[33],它在NLP和IR社区[11]中引起了广泛的兴趣。社区中应答者推荐问题主要涉及专家推荐[34]、专家发现[35 - 37,4,6,38,39]和权威发现[11]。这些模型利用不同的特征在CQA中寻找顶尖的k位潜在专家。例如,Zhou等人[34]提出了一个框架,利用论坛系统的内容和结构,将给定的问题高效、有效地路由到论坛中的顶级潜在专家(用户)。Li等人开发了两种类别敏感语言模型(LMs)来评估基于问题类别将问题路由到潜在回答者的应答者专业知识。Fatemeh等人[37]研究了两种统计主题模型在为新发布的问题寻找专家方面的适用性,并将它们与更传统的信息检索方法进行了比较。Zhou等人[4]提出了话题敏感概率模型,这是CQA中首次对专家发现进行广泛的实证研究,既考虑了被询问者与被回答者之间的链接结构,又考虑了话题相似度。Jurczyk等人[11]提出了一种改编自HITS算法的方法来预测诸如Yahoo!的答案。Liu et al.[36]提出了两种基于竞争的方法TS和SVM,在CQA中,通过对提问者和最佳答题者以及最佳答题者和非最佳答题者的两两比较来估计用户的相对专业知识得分。Zhu等人[6]提出了一种基于目标类别和相关类别的权威信息的专家发现框架。Zhao等人[39]提出将推断的用户对用户图和过去的问答活动无缝地集成到一个公共框架中,以解决CQA系统中的冷启动专家发现问题。Zhou等人[38]提出了一种用于专家发现问题的评估矩阵缺失值估计的图正则化矩阵补全方法。
与上述工作不同,CQA的用户对专业知识的关注较少。此外,专家发现的动机是寻找能够满足用户需求的专家。但是问题回答者推荐的目的是邀请许多可能的回答者来回答,从而提高用户的参与度。
-
主题模型
主题模型包括概率潜在语义索引(PLSI)[40]和潜在Dirichlet分配(LDA)[41],广泛应用于文本挖掘和信息检索。为了充分利用文档中单词之间的语义,PLSI引入了潜在的主题来表示文档,同时减少了文档表示空间的维数,并将数据生成过程建模为贝叶斯网络。Blei等人[41]提出了LDA,通过在主题和单词上引入Dirichlet先验来解决PLSI的过拟合问题。主题模型位于一个更一般的框架中,称为概率图形模型,它为开发用于文本内容分析的方法提供了一种优雅的原则性方法。许多研究将标准的主题建模扩展到不同领域的内容生成建模,如在不同领域[42]中寻找聚类之间的匹配,识别主客观词[43],分析签到数据[44]的时空特征,检测情感[45-47],推荐好友[48],预测用户生成内容(UGC)[49]的长期热度。
对CQA提出了许多LDA扩展。Guo等人[31]提出了生成模型,用于发现问答内容中的潜在话题和用户的潜在兴趣,在QA社区中建立用户档案,并基于潜在话题和term-level模型为新问题推荐答案。Qu等人[32]使用基于PLSI的用户-词方面模型,通过调查用户之前提出的问题来分析用户的兴趣。Yang等人[7]提出了一种概率主题专业知识模型(TEM),该模型使用标记信息来帮助学习主题,使用高斯混合混合模型来建模投票信息,同时测量用户的主题专业知识和兴趣。Pedro等人[8]提出了RankSLDA,这是一种结合了监督排序和主题建模的贝叶斯框架。该方法可应用于问题推荐,即社区反馈和文本内容主题联合建模,根据用户与新问题的相关性对用户进行排名。Xu等人[1]提出了一种双角色模型(dual role model, DRM),对用户的两种角色进行建模,以推荐问题。Ni等人[2]提出了一个生成模型,基于主题的用户兴趣(topic-based user interest, TUI),用来推荐特定用户可能感兴趣的问题。
以前的方法主要集中在问题和回答之间的语义关系上。例如,为了学习问题的潜在主题,基于潜在Dirichlet Allocation (LDA)[41]的主题模型被广泛研究(Xu et al. [1], Ni et al.[2])。与以往的方法不同的是,该方法不仅关注问题的潜在主题(衡量问题与回答之间的语义关系),而且考虑了被问者与被问者、被问者与回答者之间的关系。此外,我们还应用LDA模型来同时捕捉提问者、提问者和回答者之间的关系。
问题的形式化:
对于用户 uq 提问的新问题 q, 这个问题的推荐是预测N个回答者谁能最可能能够回答该问题 q 。 这意味着我们应该对于每个候选回答者 a ,预测概率 p(a|q, uq) 。因此,问题 q 的N个最高得分回答者:
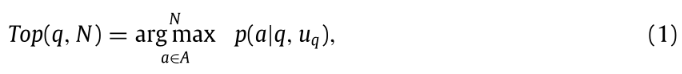
其中,上标 N 表示预计回答的人数。我们的目标是计算用户a 回答用户 uq 提问的问题 q 的概率, p(a|q,uq) 中, u 表示提问者, a 表示回答者, q 是问题的文本内容,包含问题标题和问题描述。如果我们假设单词是独立的,那么 W 可以表示为一个词袋: w1,…,w|W| ,其中 |W| 是 p 中的字数,


表示问题内容在主题上的一致性,这对回答者、提问者和问题之间的内容相关性进行了建模。
模型解释:
我们首先说明使用的符号,然后简要讨论UIM,并说明UIM的参数估计算法。
-
符号
我们分别用 NT、NW 、NU 和 NU 来表示话题、单词、提问者和回答者的数量。我们使用符号 z 来描述一个主题,而 z_pi 、 w_pi 、 u_pi 和 a_pi
来分别用来表示每个历史问答对 p 中第 i 个token的主题、单词、提问者和回答者。 T 用来表示所有的主题。 θ_p 用于表示特定于问答对 p 的主题的多项分布。 φ_z 用于表示特定于主题z的单词的多项分布, ϕ_z 用于表示特定于主题 z 的被询问者的多项分布。 w_zu 用于表示特定于主题z和被询问者 u 的回答的多项分布。这些符号列于表1。为了便于阅读和理解。

-
用户亲密关系模型
在UIM中,话题发现不仅受到词语共现的影响,还受到社交互动的影响。其中一个目标是建立社交互动模型,以评估用户之间在某个话题上的亲密程度。特别是如果用户A回答了用户B大量关于话题C的问题,则说明用户A与用户B在话题C上的亲切度很高。我们可以将生成模型应用于QA对中用户的共现度,来评估用户对某个话题的亲密度。我们假设对于所有的QA对都有一个共同的T潜在主题集合。那么生成QA对的过程如下。对于问答对中的每个令牌:
(1)样本主题 z 根据于问答对 p 的主题分布 θ_p 。

在UIM中,历史问答对的集合P的生成过程如表2所示。对于每个QA对p∈P,我们可以通过重复步骤8-14,得到问题的提问者u、回答者a以及由用户u提出的问题和a提供的答案构造的文本内容。通过以相同的方式重复每个问答对p的生成过程,我们可以获得所有问题的所有问题内容和所有问题的提问者,以及我们的UIM中的所有回答者和回答内容。在UIM中估计的四个重要参数集是每个问答对p的θp、ϕz、φz(对于每个主题Z)、每个题目和提问者都有ωzu。
直观地说,θp代表问答对p的问题的主题分布。ϕz代表词在特定主题z的多项分布。φz表示特定于主题z的提问者的多项分布,并用于对每个提问者提出关于主题z的问题的偏好进行建模。参数ωzu代表特定于主题z和被问者u的答案的多项分布。它是根据回答者对用户u提出的问题主题z给出答案的概率,来对每个回答者和被问者对一个话题的亲密度进行建模。

与LDA模型[41]相比,UIM具有以下两个特点。一方面,LDA模型将单个问题作为文档进行主题抽取。然而,一个问题不仅仅包含单词的信息,问题还包含其他信息,如提问者或回答者等。因此,LDA模型可能无法提取可靠的主题层。
与LDA模型不同,UIM通过将问答对视为文档来丰富共现信息。另一方面,LDA模型不考虑问题的回答者、被询问者以及被询问者和被询问者之间的关系,这是UIM的一个特点,应该有助于提高问题推荐的准确性。Ni等人[2]提出的TUI模型与我们的工作相似。差是两倍。首先,TUI模型在应答者推荐任务中没有考虑应答者和被应答者之间的关系,而UIM将其作为一个重要的组成部分,因为被应答者和被应答者在不同的主题中通常有不同的亲密度。其次,TUI获取用户提出的所有问题作为文档,而我们的模型以QA对作为文档。Xu等人[1]提出的DRM模型可能是与我们最相似的工作。DRM模型在生成答问者时不考虑答问者与答问者之间的依赖关系,而UIM模型则根据答问者和问题主题对QA对答问者进行样本抽取。
-
UIM的参数估计
在UIM中,有8组参数:Dirichlet先验α, β, γ和η, QA对主题分布集θp,主题词分布集ϕz,亲密分布集ωzu和主题使用者分布集φz。我们可以直接从数据中估算α, β, γ和η。为了简化参数估计过程,我们在实验中使用固定的狄利克雷先验作为之前的工作[2]。因此,我们只估计了四组参数,即每个QA对p的QA对主题分布集θp,每个主题z的分布集ϕz,每个主题z的分布集φz,每个主题z和每个询问者u的分布集ωzu。
不幸的是,与LDA模型类似,这种分布很难计算。因此,不能在UIM中进行精确的推断。我们使用吉布斯抽样法进行参数估计[41],因为它可以避免得到局部极大值结果。运用吉布斯抽样,我们需要估计条件概率p (zpi | wpi, upi, api, z−π,α,β,γ,η)这表明概率,第i个令牌的主题的历史QA对p是zpi,观察这个词后,提问者和回答者的令牌,所有的词,主题,提问者和回答者分配给其他的令牌。此外,z−pi表示问答对p中除第i个token外的所有主题作业。这些主题概率可以计算为

实验:
我们评估了UIM在问题推荐应用上的性能。UIM被用来预测给定的回答者喜欢哪些用户,然后建议用户解决问题。我们考虑了在以前的工作中使用的两种基本事实。(1)我们将每个问题的所有回答者作为目标用户集,他们的回答次数作为ground-truth评分分数。较早的答案得分较高。排名高的人回答问题的可能性更大。(2)我们认为基本真理是对一个问题给出第一个答案的一组回答者。答案排名高的人更有可能对问题给出第一个答案。我们想通过实验来调查以下研究问题的答案:
1.对用户之间的话题亲密度的估计是否能够提高问题推荐的有效性?
2. 主题和迭代的数量如何影响我们方法的准确性?
-
Dataset--问答社区的数据集处理过程
我们使用Stack Overflow的真实数据进行实验。Stack Overflow是最流行的计算机编程问答社区。它的数据可以通过Brent Ozar unlimited公开获得。我们从这个数据集中选择了一些帖子来构建一个QA对池。每个问题包括:(1)一个问题和一个答案,这是所有相关的答案之一,与停止词和HTML标签排除,文本标记化,和代码片段丢弃。(2)问题的提问者的ID。(3)用户答案的ID,即所有问题的答案之一。训练数据包括来自269位提问者者的8133个问题和来自297位回答者的10450个答案。训练数据集中最常见的用户对及其计数如图2所示。我们观察到普通用户对的数量遵循幂律分布(power-law distribution),这意味着大多数普通用户对相对较小。
-
评价指标
我们基于CQA系统中问题推荐问题的5个常用评价标准:平均倒数秩(Mean Reciprocal Rank,MRR)[3,8]、SUCCESS[37]、精度(PRECISION)[8]、归一化累积增益(NDCG)[3,8]和平均精度(Mean Average Precision,MAP)[2,8],评估了我们提出的方法的性能。
-
基线的描述
为了评估我们所提出的UCM方法的有效性,我们与以前的一些相关工作进行了比较。
CRAR:在[6]中,Zhu等人提出了CRAR算法,基于目标问题类别及其相关类别的链接分析,对用户权限进行排序,利用主题模型进行专家发现。
CQARank:在[7]中,Liu等人提出了一种PageRank算法的扩展CQARank,该算法基于问答链接结构来聚合用户专题知识,结合文本内容模型结果和链接结构,同时度量用户专题知识和兴趣。
TSPR:在[4]中,Zhou等人提出了一个主题敏感的概率模型,该模型是PageRank算法在CQA中寻找专家的扩展。
UQA: User Question Answer Model (UQA)是[31]中提出的具有LDA风格的主题模型。该模型试图发现CQA中的潜在主题,该模型可以同时发现QA社区中单词、类别和用户的主题分布,并根据这些主题分布为新到达的问题推荐答题者。
TUI:在[2]中,Ni等人提出了生成模型,即基于主题的用户兴趣(Topicbased User Interest, TUI)模型,该模型通过挖掘用户提出的问题、参与的类别和相关的答案提供者,自动向用户推荐他可能感兴趣的适当问题。
IDRM:在[1]中,Xu等人提出了PLSA风格的问题推荐双角色模型(Dual Role Model, DRM),该模型将用户的双重角色有效地整合到问题生成过程中。
-
方法性能比较
我们将基于用户界面的问题推荐方法与其他方法进行了比较。基线和我们的UIM的推荐结果总结在表3中,其中突出显示了最好的结果。

我们基于uim的方法能否充分利用用户关系来提高推荐结果?从表3可以清楚地看出,uim模型表现出良好的性能,明显优于所有基线。与最佳基线结果相比,MRR UIM的相对改善为25.2%,S@10为15%,P@10为28%。
我们首先比较了TUI在每个指标上的表现。与其他基线方法相比,TUI在每个指标上最接近我们的方法。这可能是因为其他模型不考虑问题推荐任务的用户角色信息,而TUI和UIM则认为这是一个重要的特性。UIM比TUI好多了。这可能是因为TUI不考虑回答者和提问者之间关于回答者推荐任务的主题的亲密性,而UIM将其视为一个重要特性,提问者和回答者的亲密性通常随主题而变化。这表明用户之间关于话题的亲密关系可以成为问题推荐的一个重要指标。如表3所示,通过引入用户间的亲密度,可以提高问题推荐的准确性。
其次,我们比较了CQARank、CRAR和TSPR的性能,以评估用户专业知识是否改善了模型的性能,从而将问题路由到每个指标上的每个基线的潜在回答者。如表3所示,CQARank和CRAR在每个指标上都优于TSPR。这可能是因为CQARank和CRAR考虑了评估专业技能分数的类别。例如,CQARank使用标签信息和投票信息来帮助学习主题,共同评估用户的主题兴趣和专业知识。CRAR利用目标和相关知识类别中的信息来提高基于链接分析的权威排名的性能。引入类别因子可以提高问题推荐的准确性。正如我们所看到的,类别信息可以作为不同问题主题的指示器。UIM比CRAR和CQARank好得多。这可能是因为CRAR和CQARank在应答者推荐任务中没有考虑应答者和提问者之间的关系,而UIM将其视为一个重要特征,因为提问者和应答者的亲密度通常因话题而异。这表明,与问题推荐的类别相比,用户在话题上的亲密度可能是一个重要的指标。
我们还对数据集的NDCG、PRECISION和SUCC进行了详细的评估。结果如图3所示。结论与以前的实验相似。我们的方法总是在改变推荐用户数量时表现最好。
-
主题数量和UIM迭代的影响

为了调查我在UIM模型中使用的主题K和迭代的影响,我们使用K ={5,10,20,50}和迭代I ={50,100,150,200,250,300, 350,400,450,500}运行所提出的方法。图4为MAP@1的性能对比结果。从结果可以看出,对于MAP度量,UIM的性能在不同的迭代次数和主题数量下是稳定的,这说明了UIM对于这些变量的鲁棒性和稳定性。此外,我们可以发现,K、I与模型绩效之间不存在明显的关系。例如,MAP@1中K = 20、I = 400的方法优于其他方法,MAP@5中K = 5、I = 200的方法优于其他方法,MAP@10中K = 20、I = 200的方法优于其他方法。因此,我们建议用户在其他数据集上尝试一些参数,以获得最佳结果。根据我们的数据集和实验,我们推荐K = 20。(表现较好且更加稳定,)
-
结论与未来工作
我们提出用户亲密度模型,将社会互动纳入问答对的生成过程中,有效地模拟用户之间的话题亲密度。在此基础上,我们提出了一种问题推荐方法,将文本内容学习与用户对主题的亲密度相结合。在Stack Overflow数据集上的实验表明,与其他问题推荐方法相比,我们的模型是有效的。此外,基于ui的方法持续且显著地提高了问题推荐的性能,表明用户之间对主题的亲切感是问题推荐的一个重要因素。
本文的主要贡献如下。(1)我们提出了一种lda风格的模型UIM,该模型在QA对的生成过程中引入了社会交互,从而有效地建模和学习用户之间的话题亲密性。(2)提出了一种基于UIM的问题推荐方法。这使得我们能够在统一的概率框架中自然地集成候选用户和主题提问者之间的亲密关系,以及候选用户和问题之间的内容相关性,这样更容易解释。以往的方法大多只考虑内容相关性。(3)研究了几种问答推荐方法的性能。在真实CQA数据上的实验结果表明,我们的方法可以利用用户对主题的亲切感,提高CQA中问题推荐的准确性。
我们的方法的主要局限性是处理大规模的CQA论坛比较耗时,因为UIM在培训过程中必须处理更多的参数。未来有两个有趣的研究方向需要探索。最有趣的是进一步研究CQA中计算用户间话题亲密度的方法,比如通过语义web技术。另一个有希望的方向是研究在当前框架中纳入其他特征(如问题的地理区域)以提高CQA中问题推荐的性能的可行性。
